Transformer一作Ashish Vaswani所在的AI公司Adept,发布了Fuyu-8B,这是一个多模态模型的小版本,为其产品赋能。Fuyu-8B的特点包括:
(1)具有比其他多模态模型更简单的架构和训练程序;
(2)从头开始为数字助手设计,支持任意图像分辨率,能够回答关于图表和图形的问题,并在屏幕图像上进行精细的定位;
(3)响应速度快,对于大图像的响应时间不到100毫秒;
(4) 尽管针对特定用例进行了优化,但在标准的图像理解基准测试中表现良好。
方法
模型架构: Adept致力于为知识工作者构建一个普遍智能的助手。为了实现这一目标,模型需要能够理解用户的上下文并代表用户采取行动。Fuyu的架构是一个普通的Decoder-only变压器,没有图像编码器。图像块直接线性投影到变压器的第一层。

从Huggingface中可以看到如下:
1 | ....... |
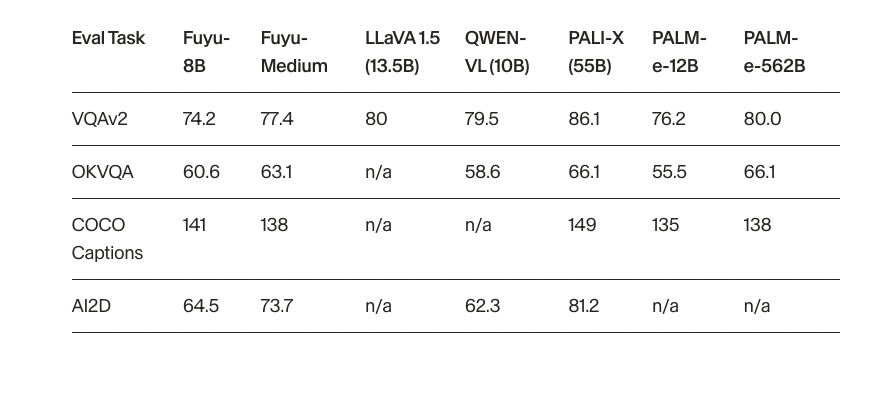
性能评估: 为了检查Fuyu-8B的架构变化,选择了四个最常用的图像理解数据集进行评估。Fuyu模型在这些指标上表现良好,不过这些数据集主要关注自然图像,和我们实际场景有所不同。
功能: Fuyu模型具有多种酷炫的功能,包括图表、图形和文档理解。它可以理解复杂的视觉关系,回答传统图表中的非平凡、多跳问题,理解文档和复杂的关系查询。
图表理解 (Chart Understanding)
Fuyu-8B模型对图表和图形的理解能力尤为出色,这对于帮助知识工作者尤为重要。
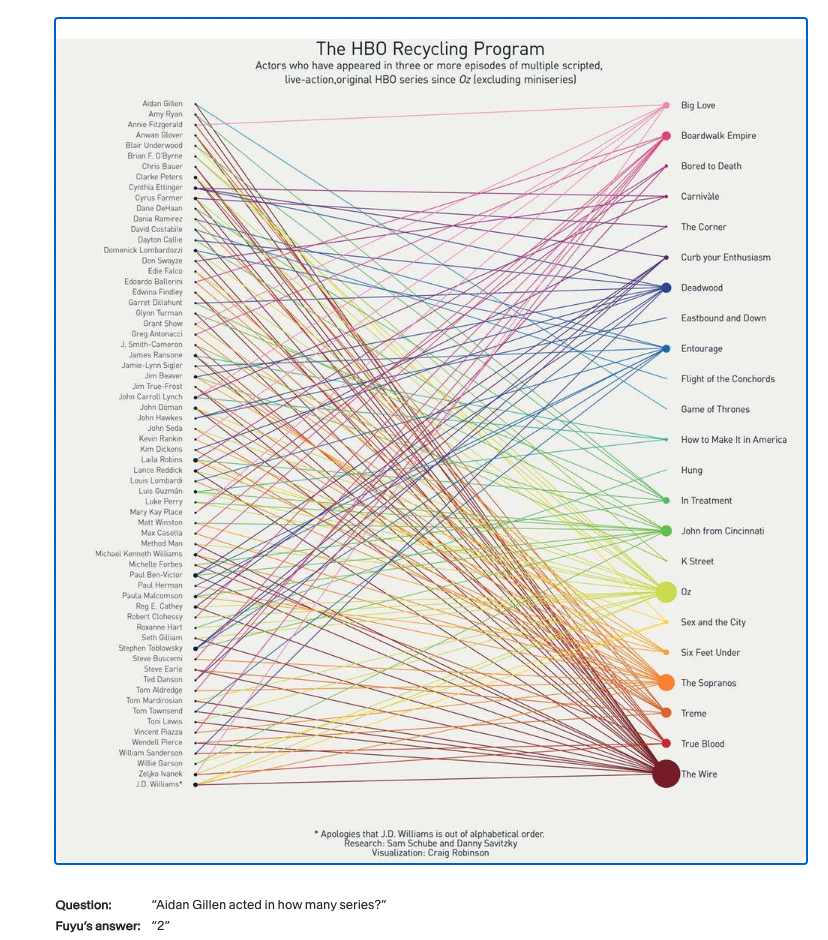
复杂视觉关系理解: 例如,模型可以追踪图表中演员和节目之间的连接并进行计数。
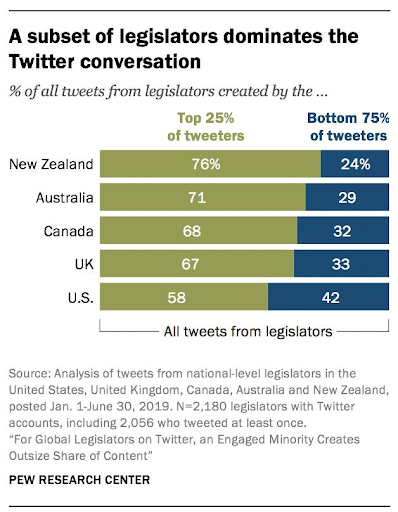
传统图表的多跳问题回答: 例如,模型可以回答诸如“查找序列24,_,32,33,42的缺失数据?”这样的问题。
更详细的功能介绍,可参考原文链接:https://www.adept.ai/blog/fuyu-8b
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 闲记算法!
相关推荐



评论

