ALBEF 是一种大规模视觉和语言表征学习的方法,可以完成多种视觉-语言的下游任务。现有的很多 Vision-and-Language Pre-training (VLP) 方法使用一个多模态 Transformer 联合建模视觉和文本的 token,但是因为视觉特征和文本特征在输入给 Transformer 时是没对齐的,导致这个多模态 Transformer 准确地学习到图文的关联关系不是很容易。本文提出将视觉和文本的特征在喂入多模态 Transformer 之前,先做对齐,对齐的方法是通过一个对比学习的损失函数。
ALBEF 的另一个优点是也不需要目标检测的框架,同时为了从嘈杂的网络数据中进行高效的学习,ALBEF 作者还提出了一套动量蒸馏的方法辅助 ALBEF 模型的训练。ALBEF 是一种算力上比较亲民的多模态学习的框架。
背景
视觉-语言预训练 (Vision-and-Language Pre-training, VLP) 旨在从大规模图像-文本对中学习多模态表征,可以改善下游视觉和语言 (V+L) 任务。大多数现有的 VLP 方法 (如 LXMERT、UNITER、OSCAR) 会先训练一个目标检测器来提取基于区域的图像特征,并使用一个多模态的 Transformer 编码器将图像 token 与文本 token 融合。多模态的 Transformer 编码器一般会使用两个目标函数去训练:Masked Language Modeling (MLM) 和 Image-Text Matching (ITM)。
但是,这套 VLP 方法有几个关键问题没解决好:
- 图片的嵌入特征和单词的嵌入特征各自在各自的空间中,使得多模态编码器难以学习建模它们的交互
- 目标检测器计算代价较高且延时较大,这在 ViLT这个工作里面也有讨论过。
- 预训练所使用的图像文本数据集是从网络上收集的,内容上比较嘈杂。现有的预训练目标,例如 MLM 可能会过拟合噪声文本,降低模型的泛化能力。
本文提出的 ALBEF 方法目的就是针对这3个问题:
- 针对 “图片的嵌入特征和单词的嵌入特征各自在各自的空间,难以交互” 的问题,ALBEF 提出:图文对齐后再融合。具体而言就是对于图片的 Embedding 和文本的 Embedding 引入一个对比学习的损失函数 image-text contrastive loss,在融合之前提前把图片和文本的表征对齐。这样做就使得后续的多模态 Transformer 更容易执行跨模态学习。
- 针对 “目标检测器计算代价较高” 的问题,ALBEF 的视觉编码器和文本编码器均不使用目标检测器。
- 针对 “图像文本数据集有噪声” 的问题,ALBEF 提出:动量蒸馏 (MoD) 的方法使模型能够利用更大的带噪声数据集。在训练期间,作者维持一个动量模型,其参数就是之前模型参数的移动平均。然后使用这个动量模型生成伪目标作为额外的监督。MoD 技术的作用是:当数据中有噪声导致监督信号不合理时,动量模型就可以给出额外的监督信号,改善模型的预训练。作者表明 MoD 不仅适用于预训练数据集有噪声的情况,还适用于预训练数据集很干净的情况。
ALBEF模型
如下图所示是ALBEF 的模型架构

ALBEF 包含一个图像编码器, 一个文本编码器和一个多模态编码器。图像编码器是12层 ViT-B/16, 权重初始化来自于在 ImageNet-1K 上面预训练的 DeiT 模型, 把输入图片编码成 Image token 。文本编码器和多模态编码器都是6层的 Transformer 模型, 文本编码器的权重初始化自 BERT-Base 模型, 把输入文本编码成 Text token 。图像特征通过多模态编码器的每一层交叉注意力与文本特征融合。
ALBEF 模型的特点:
- 视觉编码器就是 ViT,初始化权重也是来自它。
- 文本编码器是 BERT 的一半,前6层做文本编码,初始化权重也是来自它。
- 视觉编码器的体量大于文本,经验发现这样做效果好。
- 多模态编码器是 BERT 的另一半,后6层做多模态编码。
ALBEF 预训练目标函数
ALBEF 预训练目标函数有三个:
- 图文融合之前对齐的损失函数 Image-Text Contrastive Learning (ITC)
- 多模态预训练标配的完形填空目标函数 masked language modeling (MLM)
- 用于多模态预训练的图文匹配损失函数 image-text matching (ITM)。
Image-Text Contrastive Learning
ITC Loss 的计算方式是:先把视觉编码器得到的 (1×768 维的向量) 和文本编码器得到的 (1×768 维的向量) 分别通过投影层得到 维的向量, 再计算相似度: , 其中 是线性投影层。
作者这里采用和 MoCo 一样的做法存储了两个队列的负样本, 定义图文相似度为:
和
对于每个图像和文本,计算 Softmax 归一化的图像到文本和文本到图像相似度为:
式中, 是可学习的温度系数。定义 和 为对应的 标签, 则 ITC 目标函数是 和 之间的 Cross-Entropy Loss:
Masked Language Modeling (MLM)
完形填空利用图像和上下文文本来预测被 mask 掉的单词。ALBEF 以 15% 的 mask ratio 随机屏蔽输入标记,并用特殊标记 [MASK] 替换它们。定义 为 mask 之后的文本,为模型对 mask 掉的 token 的预测概率,完形填空目标函数可以写成:
式中, 是 one-hot 词汇分布,其中 GT 标记的概率为 1。
Image-Text Matching Loss
图文匹配损失函数预测一对图像和文本是正样本还是负样本。作者使用多模态编码器的输出嵌入 [CLS] token 作为图像-文本对的联合表示,并通过一个 FC 层和一个 Softmax 来预测二类概率,图文匹配损失是:
式中, 是一个2维的 one-hot 标签,代表 GT。对于一个 Batch 中每个图像,ALBEF 会采样最难的那个文本样本作为负样本。对于一个 Batch 中每个文本,ALBEF 会采样最难的那个图像样本作为负样本,然后和正样本一起构成图文匹配损失。
设 B 为 Batch Size,从代码中可以看出最终的预测维度是 [3B, 2],标签维度是 3B,前 B 个样本都是正样本,其余 2B 都是负样本。
最终的预训练目标函数是:
动量蒸馏
动量蒸馏这个技术想要解决的问题是:用于预训练的图像-文本对大多是从网络上收集的,往往是有噪声的。即使是正的样本对,样本对里面的文本很可能包含与图像无关的单词,或者样本对里面的图像可能包含文本中未描述的物体。
比如图像-文本对比学习里面,图像的负样本文本也可能与图像的内容相匹配。再比如完形填空任务中,可能存在与不同与正样本的其他词汇也满足 mask 位置的要求。
针对这个问题,本文提出动量蒸馏的技术,从动量模型生成的伪目标中学习。动量模型是另一套参数的 ALBEF,它的参数是单模态和多模态编码器的指数移动平均版本 (Exponential-Moving-Average)。这样训练时的目标就不仅仅是 GT 标签,还有这个动量教师模型了。而这个动量教师模型的参数又随着 ALBEF 模型的训练而缓慢地更新。
$ITC_{MoD} $Loss 的表达式为:
其中, 和 为动量教师模型生成的伪标签。
同理对于完形填空任务,定义 为动量教师模型对于 Masked token 的预测结果,则 Loss 可以写成:
接下来作者给了一个下图2,上面一行是 ITC 的前5名伪目标,下面一行是 MLM 的前5名伪目标。可以看到对于有的图,伪目标甚至比 GT 概括得还像样,甚至是能概括出 GT 里面没有描述出来的物体。比如左下角的图,GT 说的是 “路上的车抛锚了”,但是 top-5 的伪标签不仅能够描述这个意思,还额外地描述了 “年轻女士” 这一信息。这说明一个问题,就是使用这些伪标签训练模型是很管用的。

ALBEF 预训练数据集和配置
使用下面4个数据集,图片数加起来大概是 4M。
- Conceptual Captions
- SBU Captions
- COCO
- Visual Genome
其实作者为了证明 ALBEF 可以使用更大规模的 Web 数据进行扩展,最终还引入了噪声更大的 12M 数据集,最终将图像总数增加到 14.1M (有的数据集失效了)。
ALBEF 的模型部分包括:BERT-Base,为 123.7M 参数,ViT-B/16,为 85.8M 参数。
实验设置很亲民:使用8张 A100,以 512 的 Batch Size 训练 30 Epochs。
优化器:AdamW,weight decay:0.02,图像数据增强使用 RandAugment,预训练阶段的图像分辨率是 256×256,在微调过程中,将图像分辨率提高到 384×384,momentum 参数为0.995,队列的大小 为65536。
1.6 下游多模态任务
ALBEF 一共在5种下游多模态任务上验证。
图文检索任务 (Image-Text Retrieval) 包括两个子任务:图像到文本检索 (TR) 和文本到图像检索 (IR)。作者在 Flickr30K 和 COCO 这两个数据集上做了验证。作者使用每个数据集的训练样本对预训练模型进行微调,对于 Flickr30K 上的零样本检索,作者使用在 COCO 上微调的模型进行评估。在微调阶段使用 ITC 和 ITM 损失函数。
在推理阶段, 首先计算所有图像-文本对的特征相似度得分情景, 然后取前k 个候选并计算它们的 ITM 分数 进行排名。
视觉蕴含任务 (Visual Entailment, SNLI-VE) 是一个细粒度的视觉推理任务,用于预测图像和文本之间的关系是蕴涵、中性或矛盾的。作者遵循 UNITER 的做法,并将 VE 视为三分类问题,并在多模态编码器的 [CLS] token 的输出结果加上分类头得到每个类的概率。
视觉问答任务 (Visual Question Answering, VQA) 要求模型预测给定图像和问题的答案。与现有的将 VQA 制定为多答案分类问题的方法不同,ALBEF 将 VQA 视为答案生成问题。具体来说,作者使用6层的 Transformer Decoder 来生成答案。如下图3所示,Decoder 通过交叉注意力机制接收多模态的输入,并使用 [CLS] token 作为解码器的初始输入标记。序列结束标记 ([SEP]) 附加到解码器输出的末尾,表明生成完成。答案解码器使用来自多模态编码器的预训练权重进行初始化,并使用条件语言建模损失进行微调。为了与现有方法进行公平比较,作者强制约束解码器在推理过程中仅从3,192个候选答案中生成。

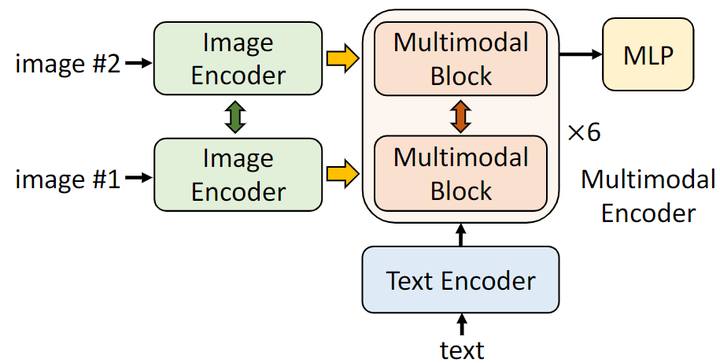
自然语言视觉推理任务 (Natural Language for Visual Reasoning, NLVR2) 要求模型预测文本是否描述了一对图像。作者扩展了多模态编码器,以实现对两幅图像的推理,如下图4所示。
多模态编码器的每一层都被复制为两个连续的变压器块,每个块包含一个 Self-attention 层、一个 Cross-attention 层和一个前馈层。每层中的两个块使用相同的预训练权重初始化,两个 Cross-attention 层的 Key 和 Value 共享相同的线性投影权重。在训练期间,这两个多模态 Block 接收两组图像输入,最终在多模态编码器的 [CLS] token 上附加 MLP 分类器进行预测。
对于 NLVR 任务,作者还设计了一个额外的预训练步骤来准备新的多模态编码器来编码图像对,详细的可以看看论文。
视觉定位 (Visual Grounding) 任务旨在定位图像中与特定文本描述相对应的区域。
实验结果
消融实验结果
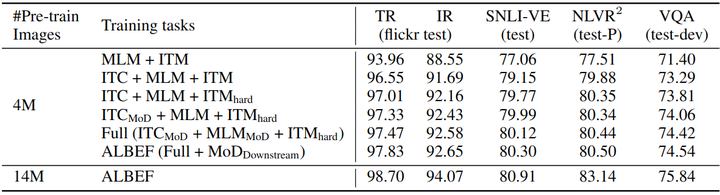
如下图5所示是消融研究各个模块的作用,作者在 4M 数据集的设置下进行的消融实验。对于文本检索任务 (TR) 和图像检索任务 (IR),作者报告的是召回率 R@1, R@5 和 R@10 的平均值。
可以看到 ITC Loss 对于各种下游任务都是有作用的,而且 hard negative sample 也对各种下游任务有用的。然后发现对于 ITC Loss 或者 MLM Loss 加上动量蒸馏技术都可以进一步地提升性能,证明了本文所提出的几种方法的有效性。
图文检索任务实验结果
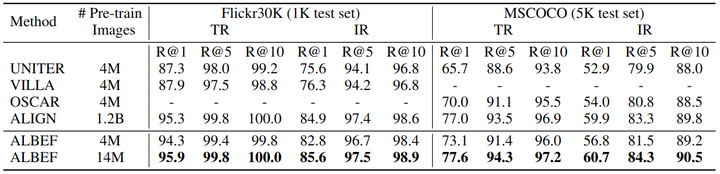
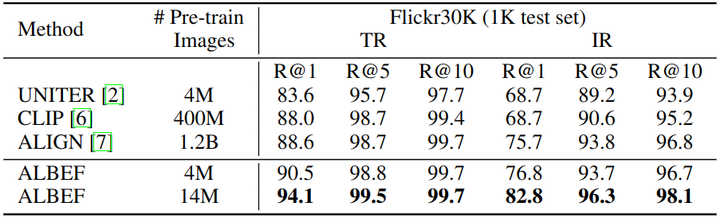
如下图6和7所示是 Fine-tuning 和 Zero-Shot 的图像文本检索的结果。可以看到 ALBEF 实现了最先进的性能,优于在更大几个数量级上训练的 CLIP 和 ALIGN 。
视觉问答 (VQA),自然语言视觉推理 (NLVR),和视觉蕴含 (VE) 任务实验结果
如下图8所示是视觉问答 (VQA),自然语言视觉推理 (NLVR),和视觉蕴含 (VE) 任务的实验结果。使用 4M 的预训练图像,ALBEF 已经实现了最先进的性能。使用 14M 的预训练图像,ALBEF 大大优于现有方法。与 VILLA 相比,ALBEF 在 VQA test-std 上实现了 2.37% 的绝对改进,在 NLVR2 test-P 上实现了 3.84%,在 SNLI-VE 测试中实现了 1.88% 的绝对改进。此外 ALBEF 是无目标检测器的,因此与大多数现有方法相比,它也有更快的推理速度。