2025-03|高质量中文预训练模型集合
在自然语言处理领域中,预训练语言模型(Pretrained Language Models)已成为非常重要的基础技术,本仓库主要收集目前网上公开的一些高质量中文预训练模型(感谢分享资源的大佬),并将持续更新…
最新的模型汇总地址github: https://github.com/lonePatient/awesome-pretrained-chinese-nlp-models
Expand Table of Contents
更新日志
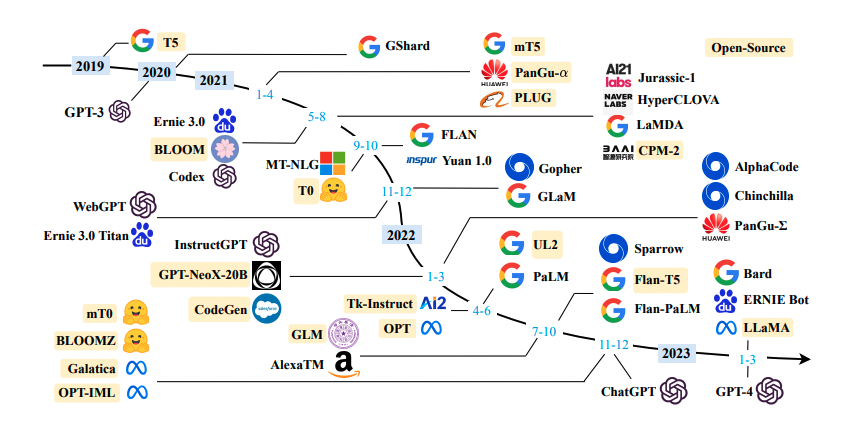
基础大模型
对话大模型
多模态对话大模型
大模型评估基准
在线体验大模型
开源模型库平台
开源数据集库
开源中文指令数据集
Other-Awesome
NLU系列
BERT
RoBERTa
ALBERT
NEZHA
XLNET
MacBERT
WoBERT
ELECTRA
ZEN
ERNIE
ERNIE3
RoFormer
StructBERT
Lattice-BERT
Mengzi-BERT
ChineseBERT
TaCL
MC-BERT
二郎神
PERT
MobileBERT
GAU-α
DeBE ...

Arxiv今日论文 | 2026-07-31
本篇博文主要内容为 2026-07-31 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR、MA六个大方向区分。
说明:每日论文数据从Arxiv.org获取,每天早上12:30左右定时自动更新。
提示: 当天未及时更新,有可能是Arxiv当日未有新的论文发布,也有可能是脚本出错。尽可能会在当天修复。
目录
概览
自然语言处理CL
多智能体系统MA
信息检索IR
人机交互HC
人工智能AI
机器学习LG
计算机视觉CV
概览 (2026-07-31)
今日共更新715篇论文,其中:
自然语言处理共99篇(Computation and Language (cs.CL))
人工智能共246篇(Artificial Intelligence (cs.AI))
计算机视觉共131篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共196篇(Machine Learning (cs.LG))
多智能体系统共19篇(Multiagent Systems (cs.MA))
信息检索共27 ...
Arxiv今日论文 | 2026-07-30
本篇博文主要内容为 2026-07-30 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR、MA六个大方向区分。
说明:每日论文数据从Arxiv.org获取,每天早上12:30左右定时自动更新。
提示: 当天未及时更新,有可能是Arxiv当日未有新的论文发布,也有可能是脚本出错。尽可能会在当天修复。
目录
概览
自然语言处理CL
多智能体系统MA
信息检索IR
人机交互HC
人工智能AI
机器学习LG
计算机视觉CV
概览 (2026-07-30)
今日共更新575篇论文,其中:
自然语言处理共76篇(Computation and Language (cs.CL))
人工智能共157篇(Artificial Intelligence (cs.AI))
计算机视觉共97篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共153篇(Machine Learning (cs.LG))
多智能体系统共8篇(Multiagent Systems (cs.MA))
信息检索共29篇( ...
Arxiv今日论文 | 2026-07-29
本篇博文主要内容为 2026-07-29 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR、MA六个大方向区分。
说明:每日论文数据从Arxiv.org获取,每天早上12:30左右定时自动更新。
提示: 当天未及时更新,有可能是Arxiv当日未有新的论文发布,也有可能是脚本出错。尽可能会在当天修复。
目录
概览
自然语言处理CL
多智能体系统MA
信息检索IR
人机交互HC
人工智能AI
机器学习LG
计算机视觉CV
概览 (2026-07-29)
今日共更新670篇论文,其中:
自然语言处理共83篇(Computation and Language (cs.CL))
人工智能共261篇(Artificial Intelligence (cs.AI))
计算机视觉共104篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共153篇(Machine Learning (cs.LG))
多智能体系统共15篇(Multiagent Systems (cs.MA))
信息检索共58 ...
Arxiv今日论文 | 2026-07-28
本篇博文主要内容为 2026-07-28 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR、MA六个大方向区分。
说明:每日论文数据从Arxiv.org获取,每天早上12:30左右定时自动更新。
提示: 当天未及时更新,有可能是Arxiv当日未有新的论文发布,也有可能是脚本出错。尽可能会在当天修复。
目录
概览
自然语言处理CL
多智能体系统MA
信息检索IR
人机交互HC
人工智能AI
机器学习LG
计算机视觉CV
概览 (2026-07-28)
今日共更新1242篇论文,其中:
自然语言处理共141篇(Computation and Language (cs.CL))
人工智能共406篇(Artificial Intelligence (cs.AI))
计算机视觉共244篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共326篇(Machine Learning (cs.LG))
多智能体系统共21篇(Multiagent Systems (cs.MA))
信息检索共 ...
Arxiv今日论文 | 2026-07-27
本篇博文主要内容为 2026-07-27 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR、MA六个大方向区分。
说明:每日论文数据从Arxiv.org获取,每天早上12:30左右定时自动更新。
提示: 当天未及时更新,有可能是Arxiv当日未有新的论文发布,也有可能是脚本出错。尽可能会在当天修复。
目录
概览
自然语言处理CL
多智能体系统MA
信息检索IR
人机交互HC
人工智能AI
机器学习LG
计算机视觉CV
概览 (2026-07-27)
今日共更新466篇论文,其中:
自然语言处理共47篇(Computation and Language (cs.CL))
人工智能共146篇(Artificial Intelligence (cs.AI))
计算机视觉共68篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共138篇(Machine Learning (cs.LG))
多智能体系统共7篇(Multiagent Systems (cs.MA))
信息检索共8篇(I ...
Arxiv今日论文 | 2026-07-24
本篇博文主要内容为 2026-07-24 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR、MA六个大方向区分。
说明:每日论文数据从Arxiv.org获取,每天早上12:30左右定时自动更新。
提示: 当天未及时更新,有可能是Arxiv当日未有新的论文发布,也有可能是脚本出错。尽可能会在当天修复。
目录
概览
自然语言处理CL
多智能体系统MA
信息检索IR
人机交互HC
人工智能AI
机器学习LG
计算机视觉CV
概览 (2026-07-24)
今日共更新626篇论文,其中:
自然语言处理共112篇(Computation and Language (cs.CL))
人工智能共261篇(Artificial Intelligence (cs.AI))
计算机视觉共109篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共169篇(Machine Learning (cs.LG))
多智能体系统共16篇(Multiagent Systems (cs.MA))
信息检索共1 ...
Arxiv今日论文 | 2026-07-23
本篇博文主要内容为 2026-07-23 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR、MA六个大方向区分。
说明:每日论文数据从Arxiv.org获取,每天早上12:30左右定时自动更新。
提示: 当天未及时更新,有可能是Arxiv当日未有新的论文发布,也有可能是脚本出错。尽可能会在当天修复。
目录
概览
自然语言处理CL
多智能体系统MA
信息检索IR
人机交互HC
人工智能AI
机器学习LG
计算机视觉CV
概览 (2026-07-23)
今日共更新554篇论文,其中:
自然语言处理共70篇(Computation and Language (cs.CL))
人工智能共156篇(Artificial Intelligence (cs.AI))
计算机视觉共88篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共160篇(Machine Learning (cs.LG))
多智能体系统共11篇(Multiagent Systems (cs.MA))
信息检索共8篇( ...
Arxiv今日论文 | 2026-07-22
本篇博文主要内容为 2026-07-22 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR、MA六个大方向区分。
说明:每日论文数据从Arxiv.org获取,每天早上12:30左右定时自动更新。
提示: 当天未及时更新,有可能是Arxiv当日未有新的论文发布,也有可能是脚本出错。尽可能会在当天修复。
目录
概览
自然语言处理CL
多智能体系统MA
信息检索IR
人机交互HC
人工智能AI
机器学习LG
计算机视觉CV
概览 (2026-07-22)
今日共更新584篇论文,其中:
自然语言处理共78篇(Computation and Language (cs.CL))
人工智能共209篇(Artificial Intelligence (cs.AI))
计算机视觉共93篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共177篇(Machine Learning (cs.LG))
多智能体系统共12篇(Multiagent Systems (cs.MA))
信息检索共15篇 ...
Arxiv今日论文 | 2026-07-21
本篇博文主要内容为 2026-07-21 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR、MA六个大方向区分。
说明:每日论文数据从Arxiv.org获取,每天早上12:30左右定时自动更新。
提示: 当天未及时更新,有可能是Arxiv当日未有新的论文发布,也有可能是脚本出错。尽可能会在当天修复。
目录
概览
自然语言处理CL
多智能体系统MA
信息检索IR
人机交互HC
人工智能AI
机器学习LG
计算机视觉CV
概览 (2026-07-21)
今日共更新1082篇论文,其中:
自然语言处理共103篇(Computation and Language (cs.CL))
人工智能共342篇(Artificial Intelligence (cs.AI))
计算机视觉共219篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共302篇(Machine Learning (cs.LG))
多智能体系统共28篇(Multiagent Systems (cs.MA))
信息检索共 ...
