简介
本方案由大华DahuaKG团队提供,在本次竞赛中本方案获二等奖。DahuaKG团队由来自浙江大华技术股份有限公司大数据研究院知识图谱团队的成员组成,大华知识图谱团队专注于行业知识图谱构建和自然语言处理等技术的研究与应用,并致力于相关技术在语义检索、信息提取、文本理解、图挖掘、智能交互等任务上完成产业落地,为大华数据智能解决方案提供NLP和知识图谱相关领域的算法支撑。
整体上,我们基于预训练语言模型NeZha构建商品标题实体识别模型,通过继续预训练加微调的训练范式学习模型参数,并有效结合数据增强、损失函数优化、对抗训练等手段逐步提升模型性能。该方案简单有效,复现流程不超过36小时,线上推断1万条样本仅需254秒(NVIDIA T4,单卡)。
赛题介绍
赛题链接:https://www.heywhale.com/home/competition/620b34ed28270b0017b823ad
本赛题要求选手用模型抽取出商品标题文本中的关键信息,是典型的命名实体识别任务。要求准确抽取商品标题中的相关实体,有助于提升检索、推荐等业务场景下的用户体验和平台效率,是电商平台一项核心的基础任务。
赛题提供的数据来源于特定类目的商品标题短文本,包含训练数据和测试数据,具体文件目录如下。其中:
- 训练数据包含4W条有标注样本和100W条无标注样本,选手可自行设计合理的方案使用;
- 初赛A榜、B榜分别公开1W条测试集样本,可下载到本地用于模型训练(如,作为预训练语料、用作伪标签数据);
- 复赛阶段测试集同样也是1W条,但只能在线上推理时根据路径读取,无法下载到本地。
1 | contest_data |
训练样例如下,每行是一个字符(汉字、英文字母、数字、标点符号、特殊符号、空格)及其对应的BIO标签(“O”表示非实体,“B”表示实体开始,“I”表示实体的中间或结尾;共52类实体,脱敏后用数字1-54表示,不包含27和45),样本间以空行分隔。
1 | 彩 B-16 |
大赛官方要求只允许产出一个模型,不允许在推断过程中进行模型融合。用实体级别的micro F1计算评测指标,记是测试集真实标注的实体集合,是预测的实体集合:
大赛对模型的推理速度进行了限制:
-
模型在单卡(NVIDIA T4,或者同等算力的 GPU 卡)上单条数据的推理时间要小于360ms,如果超过360ms,会根据推理耗时进行惩罚:
- 如果模型在单卡上单条数据的平均推理时间小于360ms,不做惩罚;
- 反之,如果大于360ms,需要乘以一定的惩罚系数
具体如下:
- 若超过1.5小时,线上将自动停止评审,并反馈“超过最大运行时间”。
数据分析
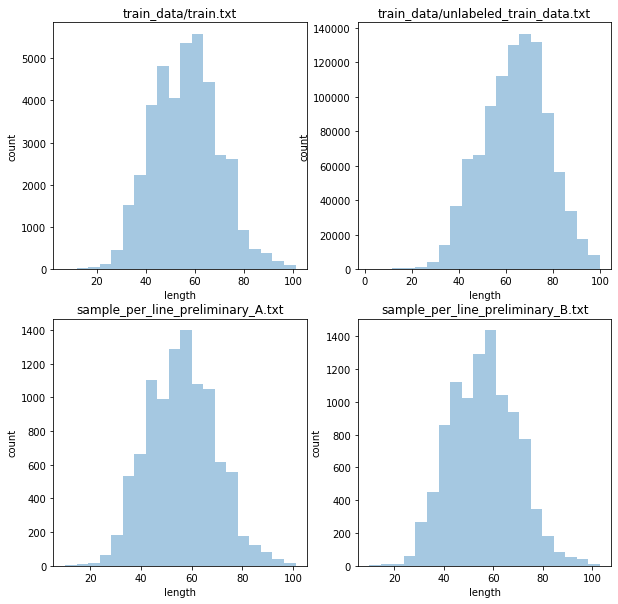
在对数据进行建模前,从文本和标签角度进行一些简单的数据分析。各文件内文本长度的统计结果如下图,横轴表示文本长度,纵轴是相应的文本数量。
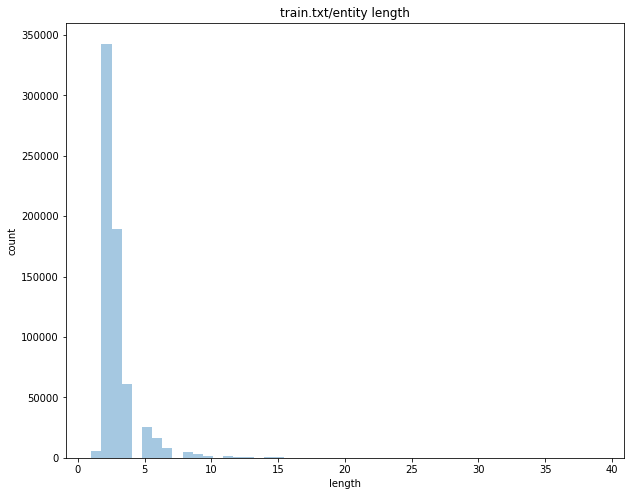
实体长度分布如下,横轴表示实体长度,纵轴是相应的实体数量。
实体标签分布如下,横轴是各类标签,纵轴是相应的实体数量
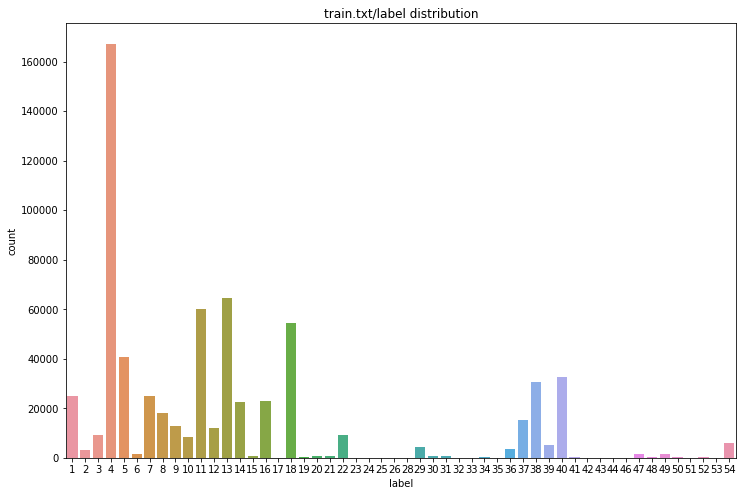
简单分析可以发现本赛题的数据存在以下特点:
- 文本以短句为主,最大长度不超过128,各数据集文本长度分布大致一致,长度主要集中在60左右;
- 除少部分实体长度过长外(217个实体长度超过20,约占总体0.03%),其余实体长度主要集中在10以内;
- 总计包含662,478个实体,存在明显的类别不均衡问题,最多的实体类别是
4,占全部实体的25.25%,而24、26、35、53等类型实体数量均少于10; - 商品标题一般由大量关键字组合而成,因此句中实体分布稠密,而且实体间没有重叠关系。
总体方案
本方案的总体算法架构图如下图所示,整体上包含预训练和微调两部分。
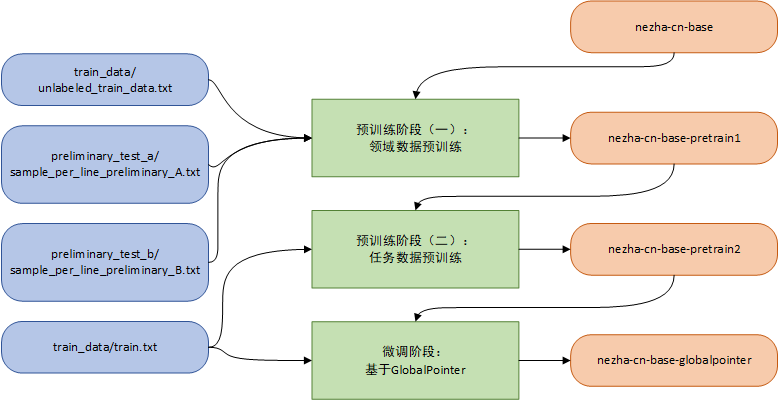
预训练阶段用领域相关、任务相关的数据进一步对通用语言模型预训练,能极大提高语言模型在下游任务上的表现。因此,我们总体技术方案可以分为预训练阶段(一)、预训练阶段(二)、微调阶段三个阶段,如上图所示,其中:
- 预训练阶段(一):该阶段称为 Domain-Adaptive Pre-training(DAPT),就是在所属领域的文本数据上继续预训练,目的是迁移通用预训练模型参数,使其适用于目标领域。本方案将无标注数据用于DAPT,包括100W条无标注训练集样本和2W条初赛A、B榜测试集样本,预训练任务只包含MLM,其中mask形式为n-gram,预训练模型主体为NeZha,并选用nezha-cn-base作为初始权重;
- 预训练阶段(二):该阶段称为 Task-Adaptive Pre-training(TAPT),将预训练阶段(一)训练得到的模型在具体任务数据上继续预训练,可以让模型进一步下游任务文本的特点。本方案选择用训练集的4W条标注样本用于TAPT,训练任务同预训练阶段(一)一致;
- 微调阶段:在预训练阶段(二)训练得到的模型基础上,用下游命名实体识别任务的标注数据微调。命名实体模型采用GlobalPointer,这是一种将文本片段头尾视作整体进行判别的命名实体识别方法,详情可参考GlobalPointer:用统一的方式处理嵌套和非嵌套NER - 科学空间。不同的是,我们采用多分类方式建模而不是多标签方式。
此外,我们尝试了很多优化方法改进模型效果,如数据增强、损失函数、对抗训练、R-Drop等,还针对性设计了后处理方法修正模型结果,将在下文详细介绍一些改进较大的技巧。
数据处理
从数据样例可以看到,标题文本中可能存在空格字符,这些空白字符带有标注O,这隐藏了一个容易被大家忽视的细节。具体地,目前业界在对中文文本进行分词时,都是在英文BERT词表中添加中文字符后,直接采用BERT分词器处理文本。但是transformers.models.bert.BertTokenizer为英文设计,分词过程首先会基于空白符对文本进行预分词,这一步简单地通过split实现,这就使文本中空白符被直接忽略,导致数据处理过程中发生文本序列、标签序列位置对应错误。因此,我们对BERT分词器进行了改进,使其可以正确划分出空白符,并可指定任意space_token进行替代。
BERT分词器和改进后的分词器对比效果如下,我们用[unused1]来代表文中的空白符:
1 | text = "彩色金属镂空鱼尾夹长尾夹 手帐设计绘图文具收纳 夹子 鱼尾夹炫彩大号" |
在本次比赛中,空格和部分低频异常字符(如’\x08’,'\x7f’等)被替换成“^”符号(相对其它符号而言出现频率较低)。
模型构建
整个方案分为预训练和微调阶段,各阶段都采用NeZha作为主体编码模型,只在任务建模层有所区别。
(1)预训练阶段
预训练模型大小采用Base,在NeZha主体结构后添加BertOnlyMLMHead层,该层将隐层编码表示映射到词向量空间中,从而预测被掩盖位置的token。
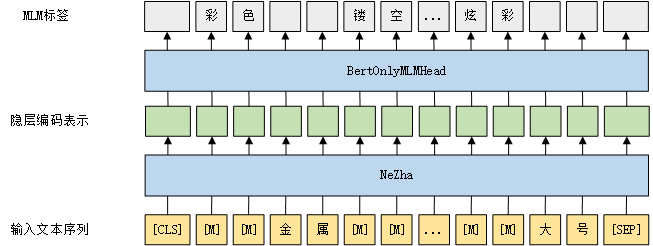
其中,预训练过程中学习任务只使用MLM任务,mask方式为n-gram,mask比率为15%,训练过程中动态生成样本,学习率为1e-4,最后微调的模型对应的预训练mlm损失约为1.0左右。
(2)微调阶段:
在经DAPT和TAPT训练后的NeZha基础上,添加BiLSTM、实体识别模型。实体识别基于GlobalPointer,用文本片段的头、尾位置对应的词向量计算类别评分,并加入旋转位置编码(RoPE)表达相对位置关系,具体技术细节参考GlobalPointer:用统一的方式处理嵌套和非嵌套NER - 科学空间。
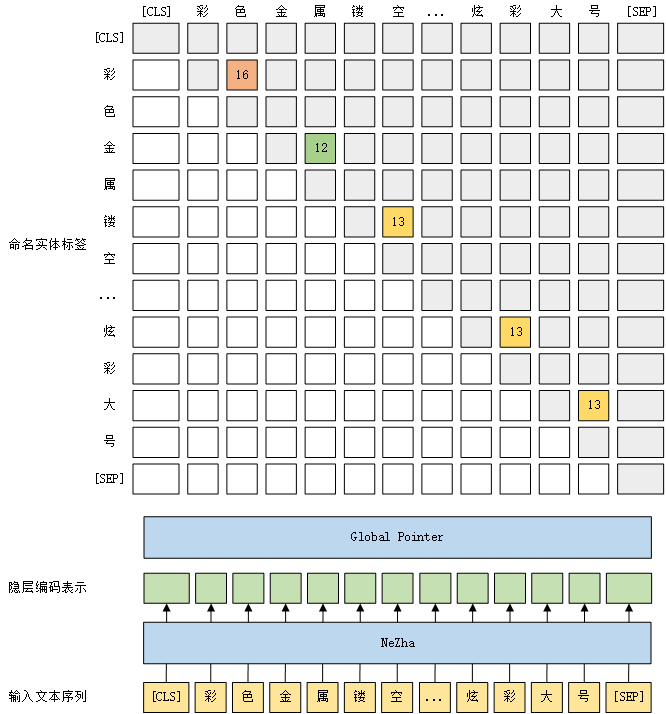
其中,训练过程采用多学习率 策略,BERT部分学习率为3e-5,其余部分为1e-3,dropout概率为0.5。
方案优化
数据增强
我们尝试了以下几种数据增强方案:
- 随机选择token并用
[MASK]替换:目的是加强模型的上下文建模能力,提高模型的泛化性; - 随机选择实体并用
[MASK]替换:方案1的改进版,不再随机选择token,而是选择完整的实体掩盖; - 随机选择实体并用同义词替换:方案2的改进版,不再用
[MASK]而是用实体的同义词,同义词由Word2Vec词向量确定; - 随机丢弃文本中的实体:随机选择完整的实体删除,由于降低了实体出现频率,过多丢弃实体可能导致模型欠拟合。
但实际效果都不是特别明显,因此并未在最终方案中采用。
损失函数
多分类任务一般采用交叉熵作为损失函数,POLYLOSS: A POLYNOMIAL EXPANSION PERSPECTIVE OF CLASSIFICATION LOSS FUNCTIONS提出将交叉熵泰勒展开,发现第项的系数固定为
文章认为,各多项式基的重要性是不同的,每项系数应随着任务、数据集的改变作相应的调整。为了减少参数、简化损失形式,提出只引入超参数调整项的系数:
在本次方案中,我们使用Poly-2方式,对应的参数值为2.5,1.5。
对抗训练
常用的提升模型鲁棒性和泛化性的方法,主要思想是针对模型求取特定扰动并混入到样本中,再在加噪样本下学习正确的标签,可以表述为
其中,是样本集中的样本,是在样本输入下针对模型参数求取的扰动,是允许的扰动空间。
常用方法有FGM、PGD、FreeLB等,我们使用了FGM、AWP两类对抗训练方法。具体地,每次训练迭代中分别求取FGM扰动和AWP扰动下的模型梯度,再将两者梯度共同累加到原始模型梯度上,最后更新模型参数。这样做可以使扰动多样化,有利于提升模型泛化性。
(1) FGM
即Fast Gradient Method,来自论文Adversarial Training Methods for Semi-Supervised Text Classification,扰动由下式求解
(2) AWP
AWP,即Adversarial Weight Perturbation,来自论文Adversarial Weight Perturbation HelpsRobust Generalization,与FGM只对输入施加扰动不同,AWP的思想是同时对输入和模型参数施加扰动。
其中,FGM采用默认参数,并参与整个训练流程,而由于AWP会对整个模型产生扰动,为防止模型在训练初期不稳定,仅当验证F1评分超过一定阈值(如0.810)后才加入AWP。
R-Drop
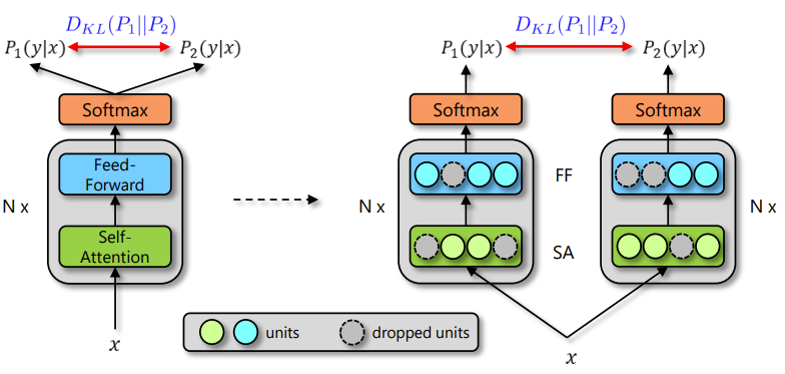
陈丹琦等人于四月份提出SimCSE,通过“Dropout两次”构造相似样本进行对比学习,提升句向量表征。后续R-Drop: Regularized Dropout for Neural Networks将 “Dropout两次”思想应用在有监督学习中,在多个任务取得明显提升。具体算法流程如下:
- 同一样本两次先后输入模型,由于Dropout的随机性,两次前向运算结果可以视作两个不同模型的输出,即输出分布与;
- 用对称形式的KL散度(Symmetric Kullback-Leibler Divergence)评估两个分布的相似性:
- 最终优化目标如下,为损失权重
其中,最终方案中取值为0.4。
后处理
本题数据中没有嵌套实体,而GlobalPointer输出结果可能存在嵌套,因此需设计合理的方案矫正模型输出。我们提出了一种结合规则和非极大抑制(non-maximum suppression, NMS)的后处理方法
- 规则:通过对比验证集标签和模型输出,我们设计了以下后处理规则:
- 若两个实体发生重叠,且实体类型相同,则从中保留一个较长或较短实体,这根据实体类型决定,如类型
4需要保留短实体,38则保留长实体; - 若三个实体发生重叠,且实体类型相同,则从中保留最长的实体;
- 若三个实体发生重叠,且实体类型不同,则从中保留最短的实体;
- ……
- 若两个实体发生重叠,且实体类型相同,则从中保留一个较长或较短实体,这根据实体类型决定,如类型
- NMS:上述设计的规则难免产生遗漏,因此最后会用NMS算法再处理一遍,确保结果中没有实体重叠。熟悉视觉任务的同学应该对NMS不陌生,这是一种基于贪婪的算法,作用是去除冗余的目标框。在本方案中用于去除实体嵌套时,将模型输出的类别概率作为实体片段评分,依次从剩余实体中选择评分最高的实体保留,如果当前选中实体与已保留实体重叠,那么舍弃该实体。
后续提升方向
- 从周星分享内容来看,伪标签有一定的提升效果,可以从伪标签方向进行提升。
- 本赛题官方规定只能产出一个模型,那么一定程度上可以采用知识蒸馏技术将多个模型蒸馏到单个模型。
- 简单的EDA方案可能破坏了数据的分布,可尝试其余数据增强方法,如AEDA等。
总结
本文介绍了我们参加2022年全球人工智能技术创新大赛商品标题识别赛题的获奖方案,整体上,我们基于预训练语言模型NeZha构建商品标题实体识别模型,通过继续预训练加微调的训练范式学习模型参数,并有效结合数据增强、损失函数优化、对抗训练等手段逐步提升模型性能,但还存在优化空间,如可采用伪标签、知识蒸馏、数据增强等技术进一步提升效果。