CLIP 是由 OpenAI 提出的一种多模态神经网络,它能有效地借助自然语言的监督来学习视觉的概念。典型的视觉数据集是劳动密集型的,创建成本很高,且使用它们训练得到的标准视觉模型只擅长一项任务,导致适应新的任务并不容易。而 CLIP 在各种各样的图像上进行训练,同时依赖于互联网上大量自然语言的监督。CLIP 可以用自然语言指示进行大量的分类基准:我们只需要提供要识别的视觉类别的名称,无需再在目标基准上面进行专门的训练,这有点类似于 GPT-2 和 GPT-3 的 “Zero-Shot” 的能力。比如,CLIP 在 ImageNet-1K 上的性能与专门有监督训练的 ResNet-50 相当,但是却没有使用 1.28M 的 ImageNet-1K 训练数据集。事实上,CLIP 也可以 “Zero-Shot” 地有效转移到大多数任务上面,并且能获得与完全监督的基线相竞争的性能。
CLIP 的预训练方法
本文采取基于对比学习的高效预训练方法。作者的思路是这样的:一开始的方法是联合训练了一个处理图像的 CNN 和一个处理文本的 Transformer 模型,来预测图像的 caption。这个实验结果如下图1的蓝色曲线所示,可以看到其 Scalability 是很差的。橘红色曲线是预测文本的词袋,其效率是蓝色曲线的3倍。这两种方法都有一个关键的相似性,即试图去预测每幅图片对应的word是什么。但我们知道这可不是一件容易的事,因为与同一幅图像对应的描述、注释和相关文本种类繁多。
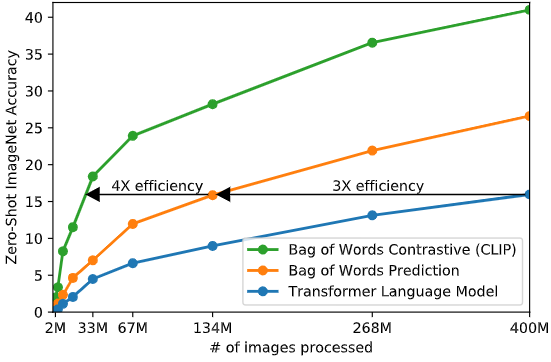
基于最近的图像对比表征学习方面的研究,可以仅预测整个文本与哪个图像配对,而不是该文本的token,实验结果如下图1的绿色曲线所示,其效率是橘红色曲线的4倍。具体的做法是:
对比学习阶段: 如下图2所示, 给定一个 Batch 的 个 (图片, 文本) 对, 图片输入给 Image Encoder 得到表征 ,文本输入给 Text Encoder 得到表征 ,作者认为 属于是正样本, 属于负样本。最大化 个正样本的 Cosine 相似度, 最小化 个负样本的 Cosine 相似度。
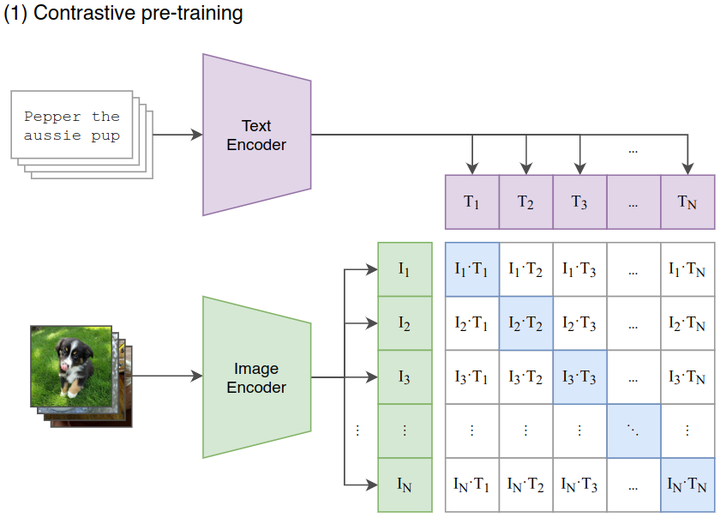
如果听起来还是觉得抽象,我们再来看代码实现(大家详细看下注释):
1 | # image_encoder - ResNet or Vision Transformer |
很多朋友可能对最后一步计算Loss有迷惑,搞不懂为什么要算两个Loss再取平均,这里解释一下:
- CLIP分为按行计算Loss和按列计算Loss
- 按行计算Loss,在每一行范围内做softmax,然后计算cross_entropy(蓝色格子部分是真值)。这样计算Loss的意义是:对于每一张图片,我们都希望找到和它最相似的文字。
- 按列计算Loss,在每一列的范围内做softmax,然后计算cross_entropy(蓝色格子部分是真值)。这样计算Loss的意义是:对于每一段文字,我们都希望找到和它最相似的图片。
- 最后将这两个Loss相加取平均,代表我们在模型优化过程中考虑了“图片->文字”和“文字->图片”的双向关系。
作者从头开始训练 CLIP,不使用 ImageNet-1K 权重初始化 Image Encoder,也不使用预先训练的权重初始化 Text Encoder。同时使用线性投影 (权重为) 将每个编码器的表征映射到多模态的嵌入空间。数据增强只使用随机裁剪,温度系数 的对数形式随整个模型一起训练。
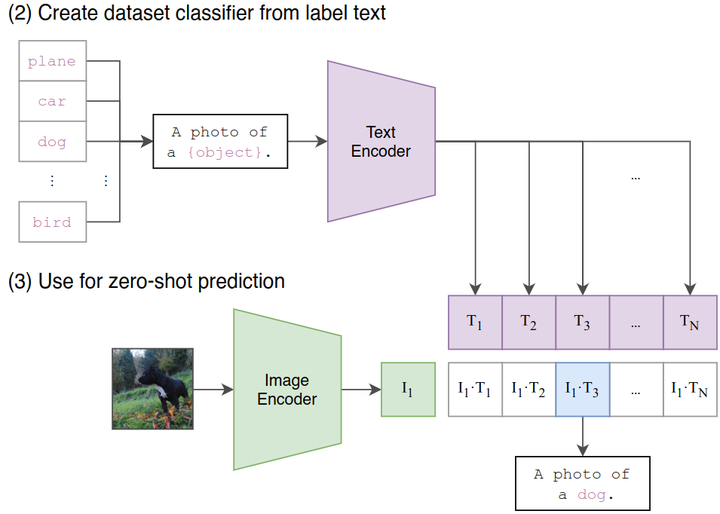
Zero-Shot Transfer: 如下图4所示,这个阶段是使用 CLIP 的预训练好的 Image Encoder 和 Text Encoder 来做 Zero-Shot Transfer。比如来一张 ImageNet-1K 验证集的图片,我们希望 CLIP 预训练好的模型能完成这个分类的任务。但是你想想看,这个 Image Encoder 是没有分类头 (最后的 Classifier) 的,也就是说它没法直接去做分类任务,所以说呢 CLIP 采用了下面的 Prompt Template 模式:
比如来一张 ImageNet-1K 验证集的图片, 作者把它喂入 CLIP 预训练好的 Image Encoder, 得到特征 ,接下来把所有类别的词汇 “cat”, “dog” 等, 做成一个 prompt: “A photo of a {object}”, 并将这个 prompt 喂入 CLIP 预训练好的 Text Encoder, 依次得到特征 , 最后看哪个的余弦相似度和 最高, 就代表该图片是哪个类别的。
那我们就可以注意到貌似这个 prompt 的加入很关键,正好弥补了 Image Encoder 没有分类头的问题,又正好用上了 CLIP 训练好的 Text Encoder。
而且重要的是,CLIP 的这种推理的方法摆脱了类别的限制,比如一张 “三轮车” 的图片,假设 ImageNet 里面没有 “三轮车” 这个类,那么基于 ImageNet 所训练的任何模型都无法正确地讲这个图片分类为 “三轮车” ,但是 CLIP 的范式是可以做到的,只需要去做成一个 prompt:“A photo of a {tricycle}”。
那么我们不禁要问:其他任务可以像这样使用 prompt 吗?或者什么样的 prompt 可以带来 Zero-Shot 的性能提升? 作者做了实验发现:
- 对于细粒度图像分类任务,比如 Oxford-IIIT Pets 数据集,prompt 就可以设置为:“A photo of a {label}, a type of pet.”。比如 Food101 数据集,prompt 就可以设置为:“A photo of a {label}, a type of food.”。比如 FGVC Aircraft 数据集,prompt 就可以设置为:“A photo of a {label}, a type of aircraft.”
- 对于 OCR 任务,加上一些文本或者数字的引号可以提升性能。
- 对于卫星图像分类数据集,prompt 就可以设置为:“a satellite photo of a {label}.”。
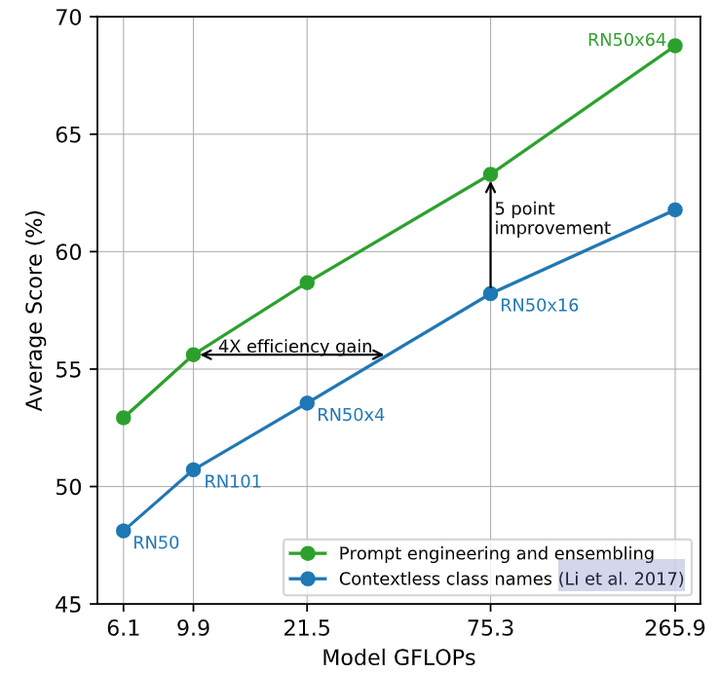
作者还开脑洞尝试了通过使用多个上下文的 prompt 来 Ensemble 多个 Zero-Shot 分类器,比如一个 prompt 是 'A photo of a big {label}“,另一个 prompt 是 'A photo of a small {label}”。作者观察到这样可以可靠地提高性能。在 ImageNet 上,作者集成了 80 个不同的上下文提示,这比上面讨论的单个默认提示提高了 3.5% 的性能。当一起考虑时,如下图5所示是 Prompt 工程和 Ensemble 策略如何改变一组 CLIP 模型的性能,可以看到 Prompt 工程和 Ensemble 策略将 ImageNet 精度提高了近 5%,其中蓝色的线代表直接嵌入类名的结果。