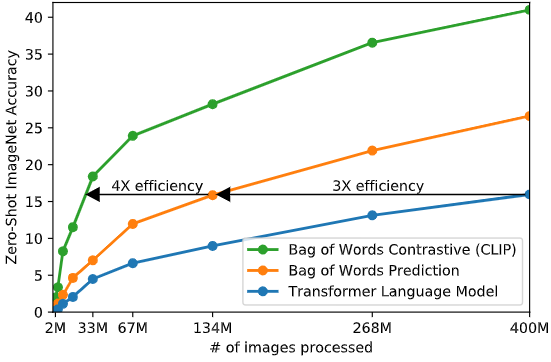
本篇博文我们主要关注prompt在视觉语言模型中的一个应用。我们知道一个好的prompt需要专业的领域知识以及大量实验进行优化,并且prompt的轻微变化可能会对性能产生巨大的影响。因此在实际应用时主要的挑战是如何对不同的下游任务构建特定的prompt。本文作者提出了一种context optimization(CoOP)的方法,通过构造soft prompt方式,即prompt参数化可学习,结合离散标签使用continuous representation建模上下文,并在保持预训练学习的参数固定的同时从数据中进行端到端学习优化,让网络学习更好的prompt。这样,与任务相关的prompt设计就可以完全自动化了。实验结果表明,CoOP在11个数据集上有效地将预训练的视觉语言模型转化为数据高效的视觉任务学习模型,只需少量样本微调就能击败手工设计的提示符,并且在使用更多样本微调时能够获得显著的性能提升。
方法
对于预训练的视觉语言模型,prompt在下游数据集中起着关键作用。设计合适的prompt是一项重要并且不简单的任务,这通常需要大量的实验来进行微调(因为prompt的轻微变化可能会在性能上产生巨大的影响)。例如:
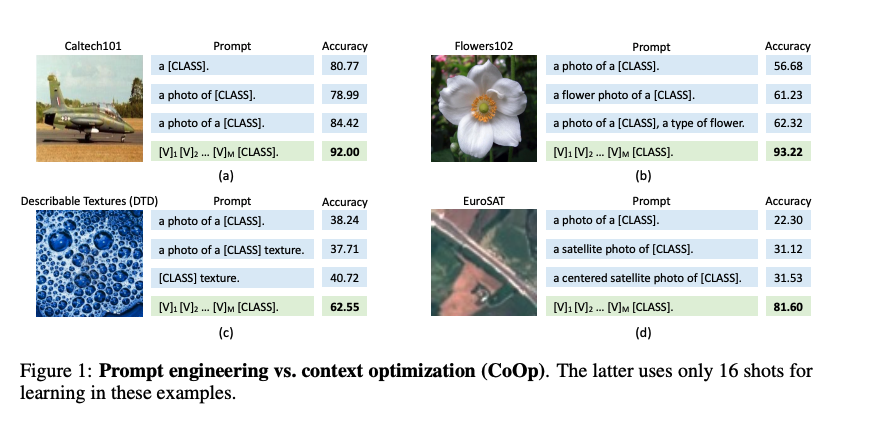
- 从上图a中,对于Caltech101数据的第2个和第3个prompt,在class token之前添加一个 “a” token,准确率提高了超过5%。
- 从上图b-d,可以看出添加任务相关的上下文可以带来性能的显著提升,如上图b的“flower”、上图c的“texture”和上图d的“satellite”。
- 从上图b中,在prompt的后面加上 “a type of flower”就能提升性能,说明调整句子结构可以带来进一步的性能改进。
- 上图c只保留“texture”就能提升性能。
- 上图d加上一个单词“centered”就能提升性能。
可见下游不同任务有不同的最优prompt,即使有大量的调优,最终的prompt也不能保证是下游任务的最佳选择。
从上图最佳prompt设计也可以看出,CoOp明显是受到了AutoPrompt的启发,作者提出了context optimization(CoOp)来实现自动化构建prompt,从而可以使得预训练的视觉语言模型更高效进行下游任务的迁移。
本文作者提出的CoOp模型结构如下所示:
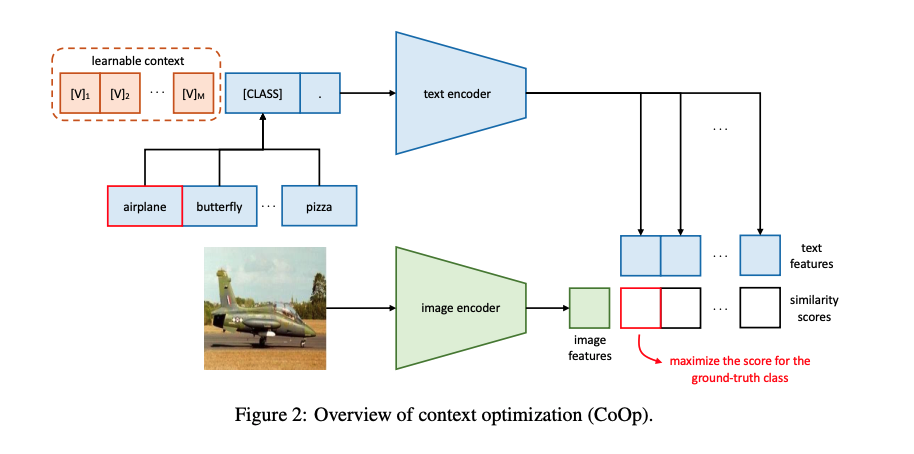
具体来说,对于每个训练样本,给定文本编码器,作者采用以下形式设计了prompt:
其中,每个表示与每一个token的embedding维度相同的向量,M是一个prompt中包含token数量的超参数,也就是文中提到的上下文token的数量。这里的所有是可学习,参数可以在所有类别之间共享的,也可以对特定的类别采用不同的。
通过将prompt 输入到文本编码器,就可以得到一个代表视觉概念的分类权重向量,即:
每个prompt 对应的class token对应为第i个class的向量。
除了把class token放在prompt序列的末尾之处,也可以把class token放在中间:
上面的设计中的参数都是在所有类别之间共享的。另一种选择是对特定类别设定class-specific context(CSC),即参数不共享:
其中,作者发现CSC对于一些细粒度的分类任务特别有用。
实验
数据集
为了证明CoOp的有效性,作者在11个基准数据集上进行了测试,这些数据集涵盖了一系列不同的视觉识别任务,包括对一般对象、场景、动作和细粒度类别的分类,以及识别纹理和卫星图像等特殊任务。
训练细节
本文作者进行四种不同CoOp实验:
- 将class token放在prompt序列末尾。
- 将class token放在prompt序列中间。
- 使用统一的prompt,即参数在所有类别之间共享。
- 特定类别不同prompt,即CSC。
实验结果
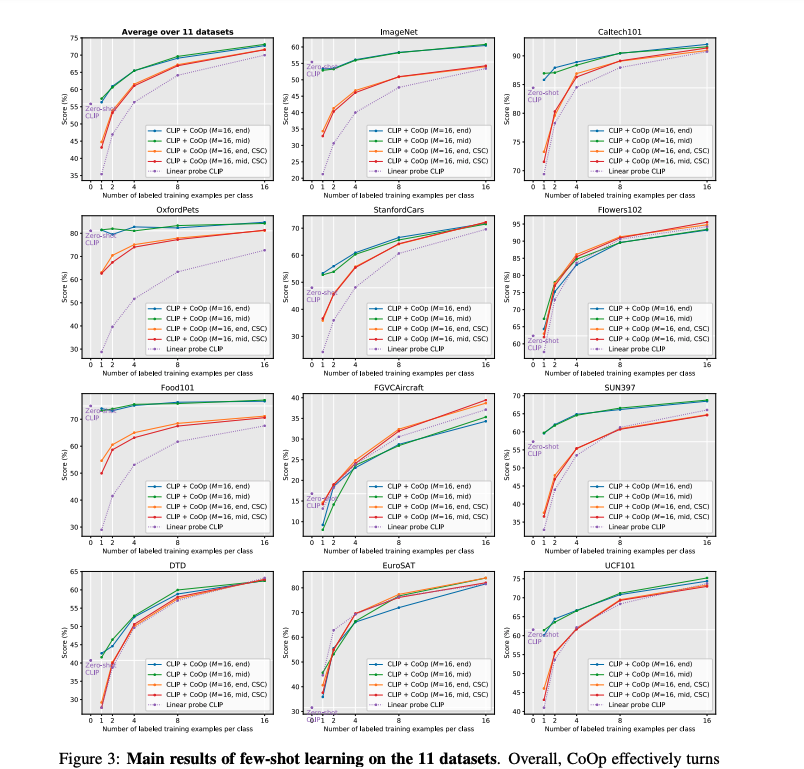
在few-shot 实验中,从11个数据集的实验中可以看出,CoOp均超过了CLIP,并且在一些数据集上,大幅度超过CLIP。证明了可学习的prompt优于人为设计的prompt。并且CoOp提出的两种变体,在一些数据集中效果更好。
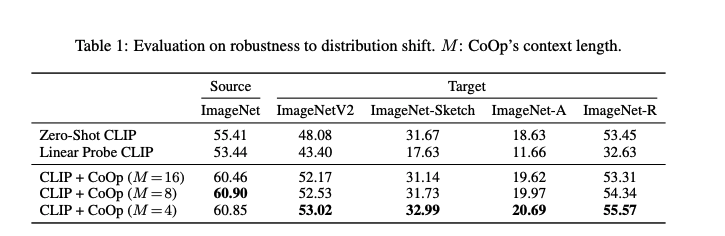
在分布偏移的实验中,从上图可以看出CLIP+CoOp比zero-shot CLIP对分布偏移表现出更强的鲁棒性,这表明学习到的提示也是可迁移的。

在prompt初始化以及比较实验中,可以看出对于单个的prompt、prompt集成和CoOp的结果,证实了CoOp仍然是性能最好的方法。并且使用特定的手工prompt初始化比随机初始化效果好。
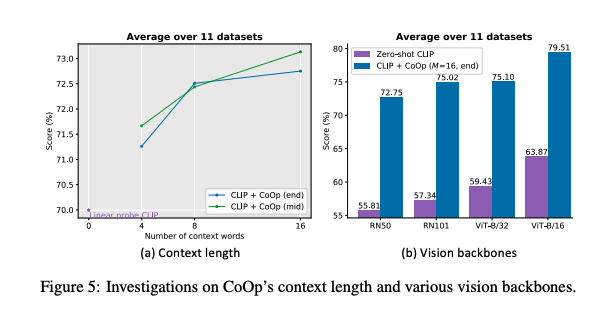
在token个数M的实验中,上图表明拥有更多的上下文token会产生更好的性能,并且将class token在中间会随着更长的上下文长度,获得更多的性能增长;上图右表明了Backbone越先进,性能就越好。
小结
本文作者提出了一种context optimization(CoOP)的方法,通过构造soft prompt方式,即prompt是参数化,结合离散标签使用continuous representation建模上下文,并在保持预训练学习的参数固定的同时从数据中进行端到端学习优化,让网络学习更好的prompt。这样,与任务相关的prompt设计就可以完全自动化了。实验结果表明,CoOP在11个数据集上有效地将预训练的视觉语言模型转化为数据高效的视觉任务学习模型,只需少量样本微调就能击败手工设计的提示符,并且在使用更多样本微调时能够获得显著的性能提升。