这次想要和大家分享的内容主要包括以下几个方面。首先,我会介绍下多模态学习的基础知识,包括相关概念、应用场景、意义等。然后,我将探讨一些多模态学习中的核心技术以及代表性的模型。最后,我们还会一起看看多模态学习面临的挑战以及未来可能的发展方向。不管你是对人工智能有浓厚兴趣的新手,还是已经在这个领域摸爬滚打了一段时间的老兵,相信你都能从这次分享中找到自己需要的。
多模态学习相关概念介绍
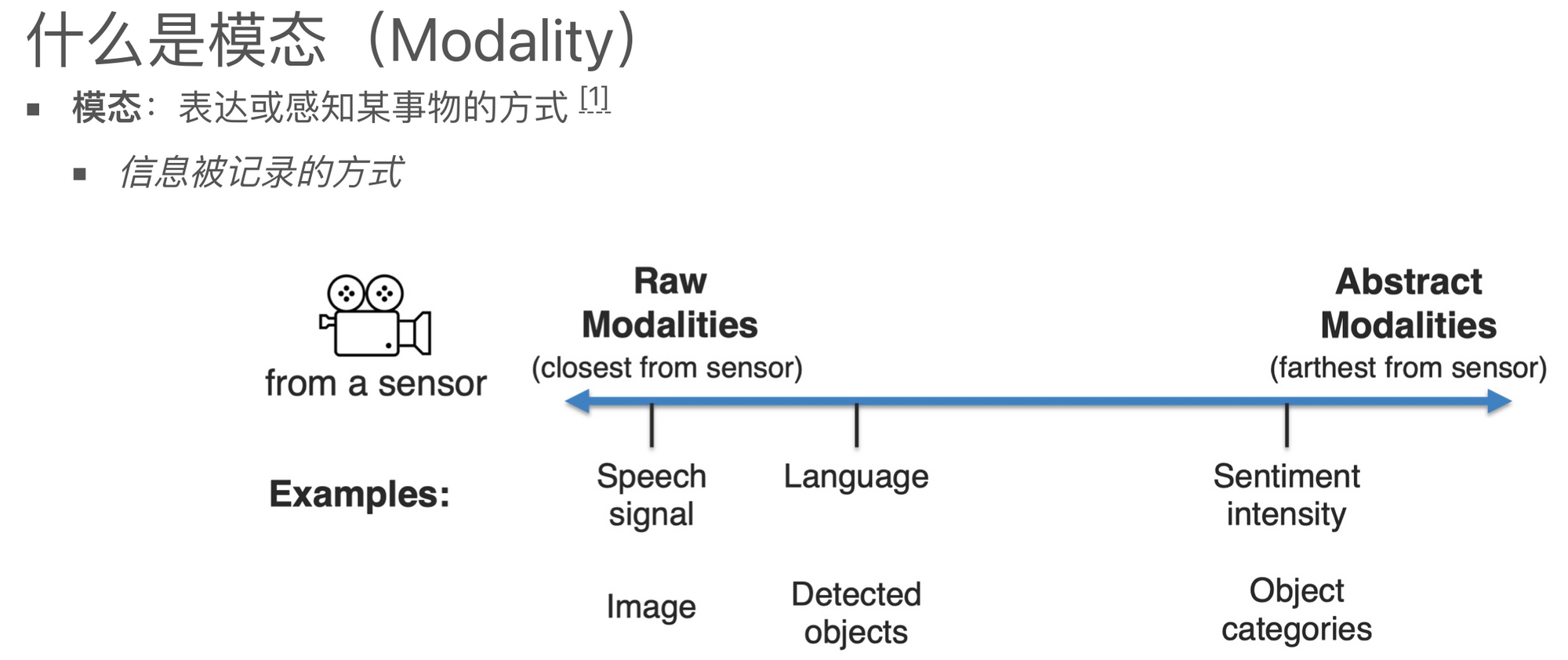
那么,我们先来聊聊什么是多模态学习。模态(Modality)可能是大家比较陌生的词汇,但实际上,在我们日常生活中,经常会接触到不同的模态的数据,例如文字、语音、图片等等。这些都是明显的不同模态的数据。如果我们进一步拓宽视野,会发现模态其实可以理解成一个表达、记录或感知某个事物的方式,或者说这种信息被记录或数据被存储的一种方式。每种不同的存储方式都可以被认为是一种不同的模态。
比如,有的模态可能更接近传感器的原始数据,比如语音、图像等;而有的模态则可能涉及更抽象的概念,比如情绪、物体分类等。在过去,我们可能更倾向于处理单一模态的数据,比如仅处理文字或者仅处理图片。但现在,随着科技的发展,我们不仅需要处理更多的模态,而且需要处理这些模态之间的关联。多模态学习,就是要从这些具有异构性但又相互关联的数据中去学习和理解信息。
让我们深入研究一下多模态学习的具体内容。从下面的图片中,你会看到两种不同颜色的数据,它们代表两种不同的模态的数据。每个图标都代表数据中的一个基本单元。例如,在文本中,基本单元可能是字符,在视频中,基本单元可能是每一帧的图像。因此,三角形可能代表一个字符,而圆形可能代表一帧的图像。
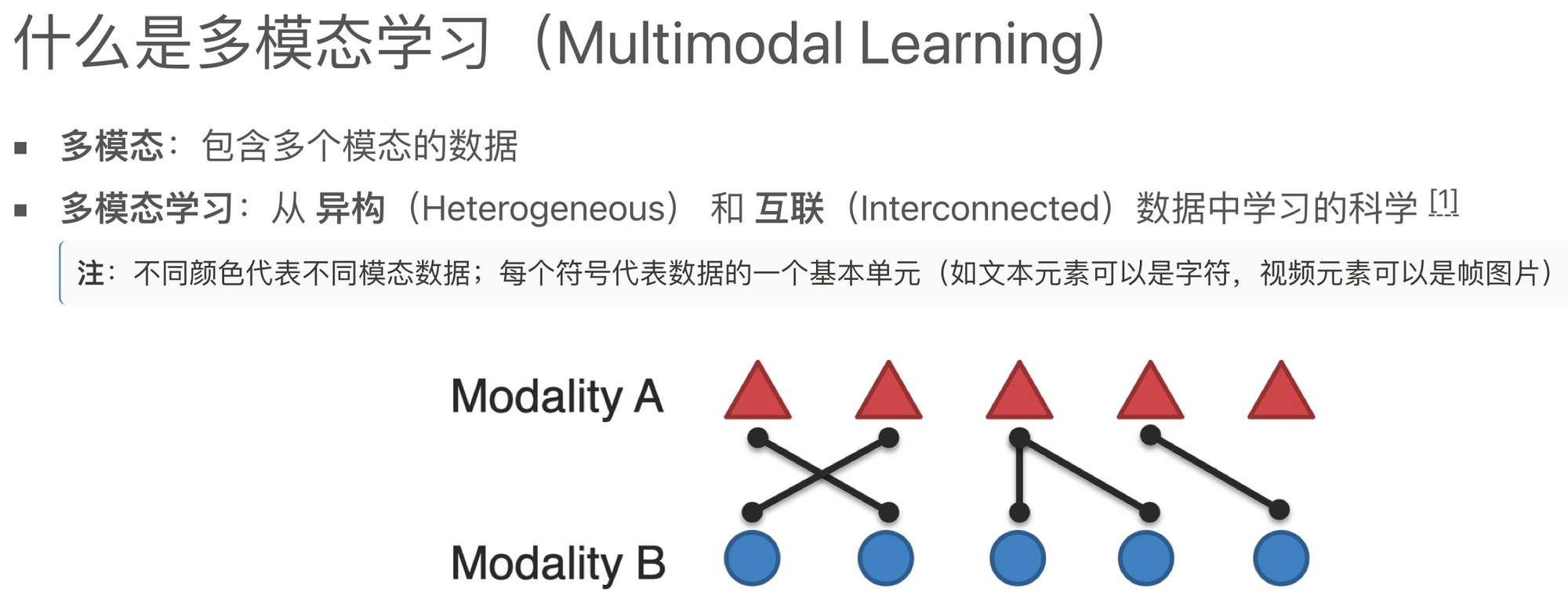
当我们讨论不同模态的数据时,必须注意,虽然它们各自具有独特的特性(例如,文本数据是离散的,而图像和视频数据是连续的),但它们之间也存在某种关联性。比如说,视频中的字幕和视频内容是相互关联的,文本和图像也容易构成自然的多模态数据。然而,我们需要注意的是,这种关联性不一定在数据的基本单元上就能体现出来。很多时候,我们在学习的过程中,是需要通过更深层次的方式去发现并学习这种关联性。
所以,多模态学习(Multimodal Learning),简单来讲,就是在深度学习的框架下,将各种不同类型的数据整合在一个模型中进行建模。这是我们在过去的几年里在机器学习和深度学习领域看到的主流方法。与此相对的,就是单模态学习(Unimodal Learning)。在单模态学习中,我们通常在单一模态的数据上进行建模,比如文本。例如,在文本数据上进行情感分析、分类、生成摘要或者翻译等等,这些任务基本上只会用到单一模态的文本数据。我们通过这种方式构建模型,然后将模型应用到相应的任务或应用中。图像处理也是类似的。事实上,在近几年之前,文本处理和图像处理这两个领域的发展基本上是独立的,它们的关联度并不高,尤其是在Transformer模型出现之前。
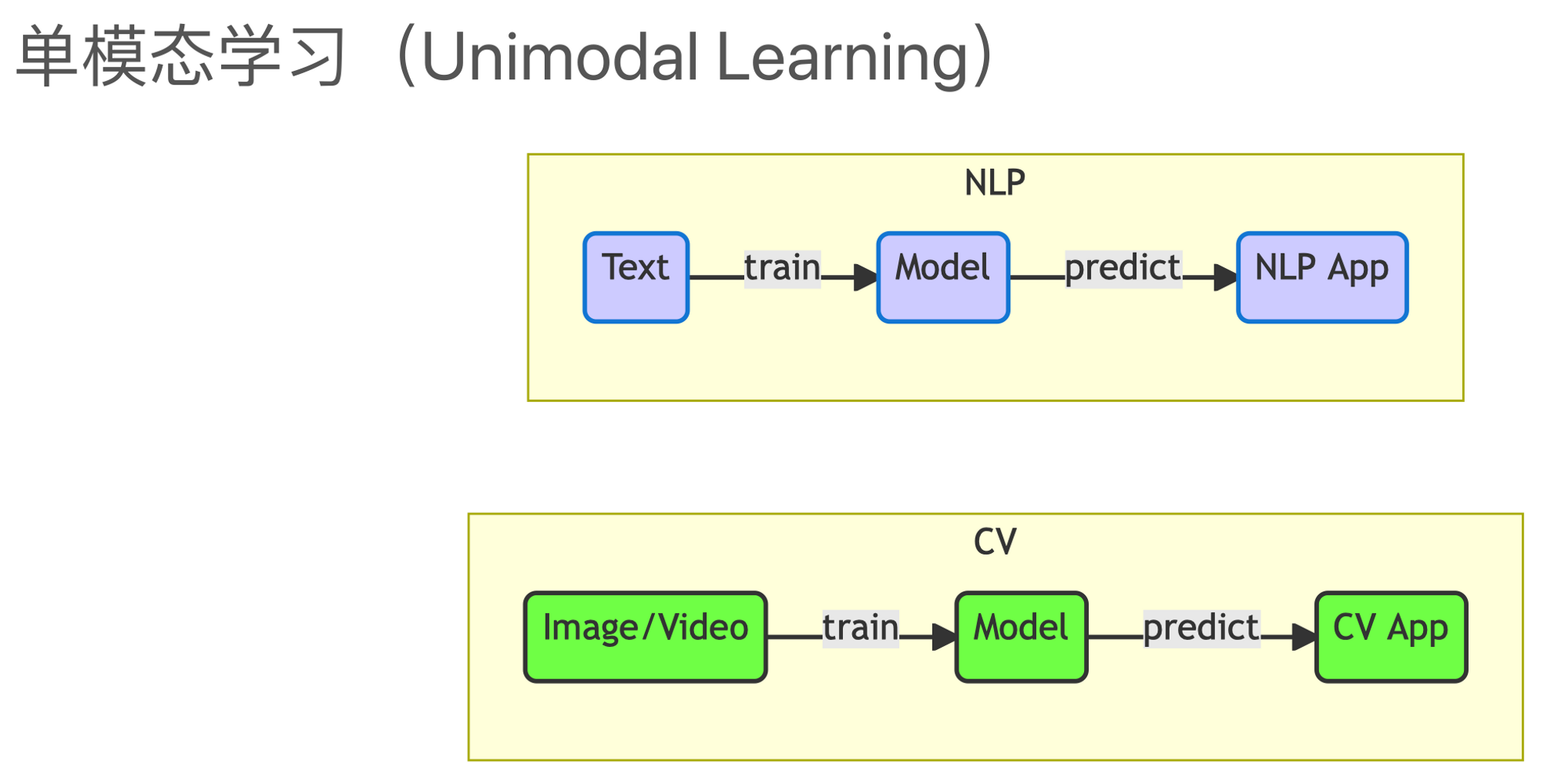
大约在2017年,这种模态之间的耦合度开始发生显著变化。这主要归功于Transformer模型的出现,这是一个跨模态应用的强大框架。由于Transformer模型的出现,各种不同的行业或模态的数据开始向通用单一框架靠拢。
因此,我们可以把多模态学习理解为一个过程,即将不同模态的数据都作为模型的输入,然后通过深度学习的方法构建一个AI模型。这种模型不仅能完成原来单模态模型所能完成的任务,例如在文本处理中进行摘要生成或对话生成,或在图像处理中进行目标检测、目标识别或分类等,而且还需要有跨模态的能力。这种能力可以让模型进行诸如图像描述生成(Image Captioning)、基于图像的问题回答(Visual Question Answering,VQA)或者基于图像的推理等任务。
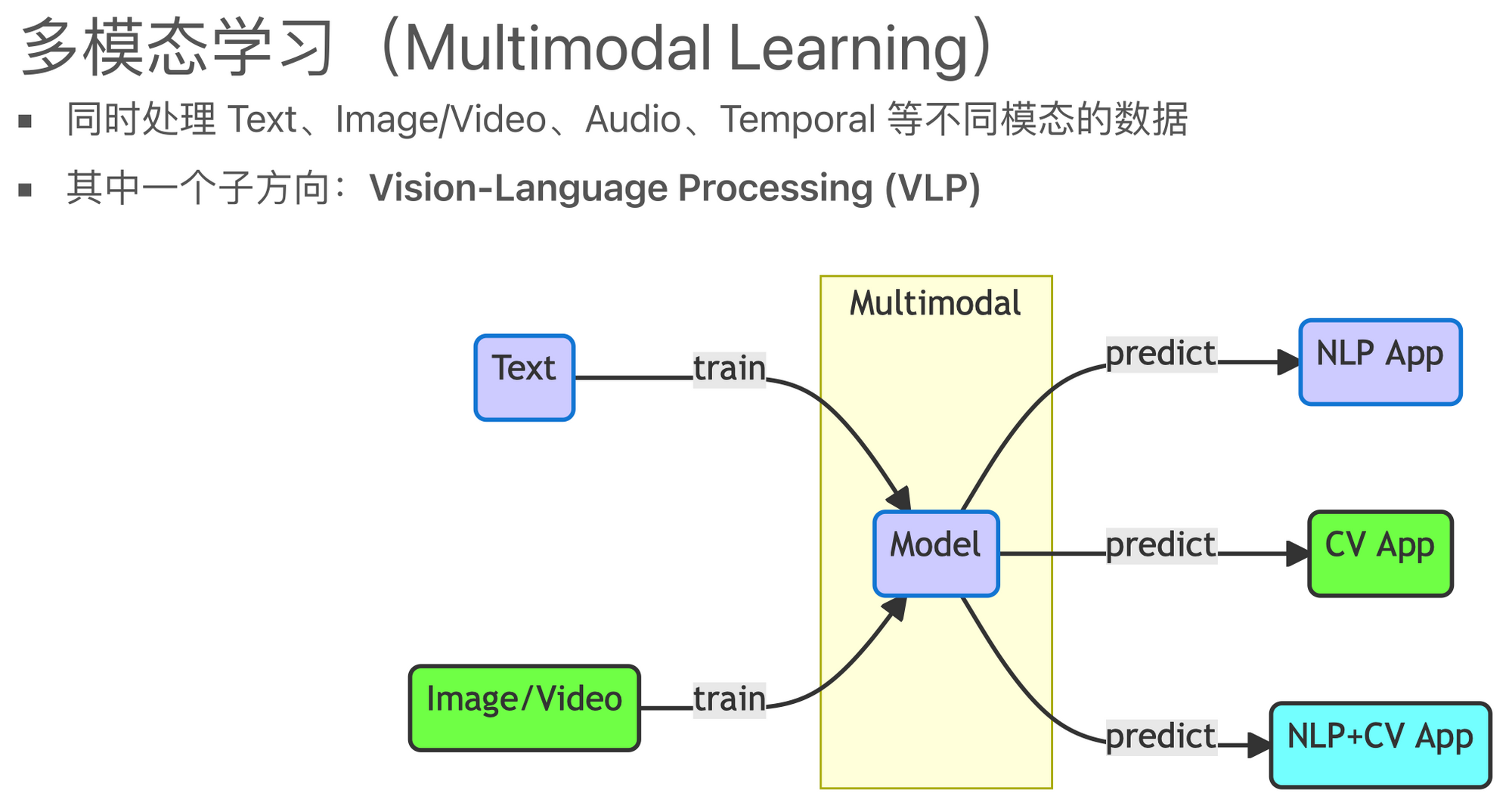
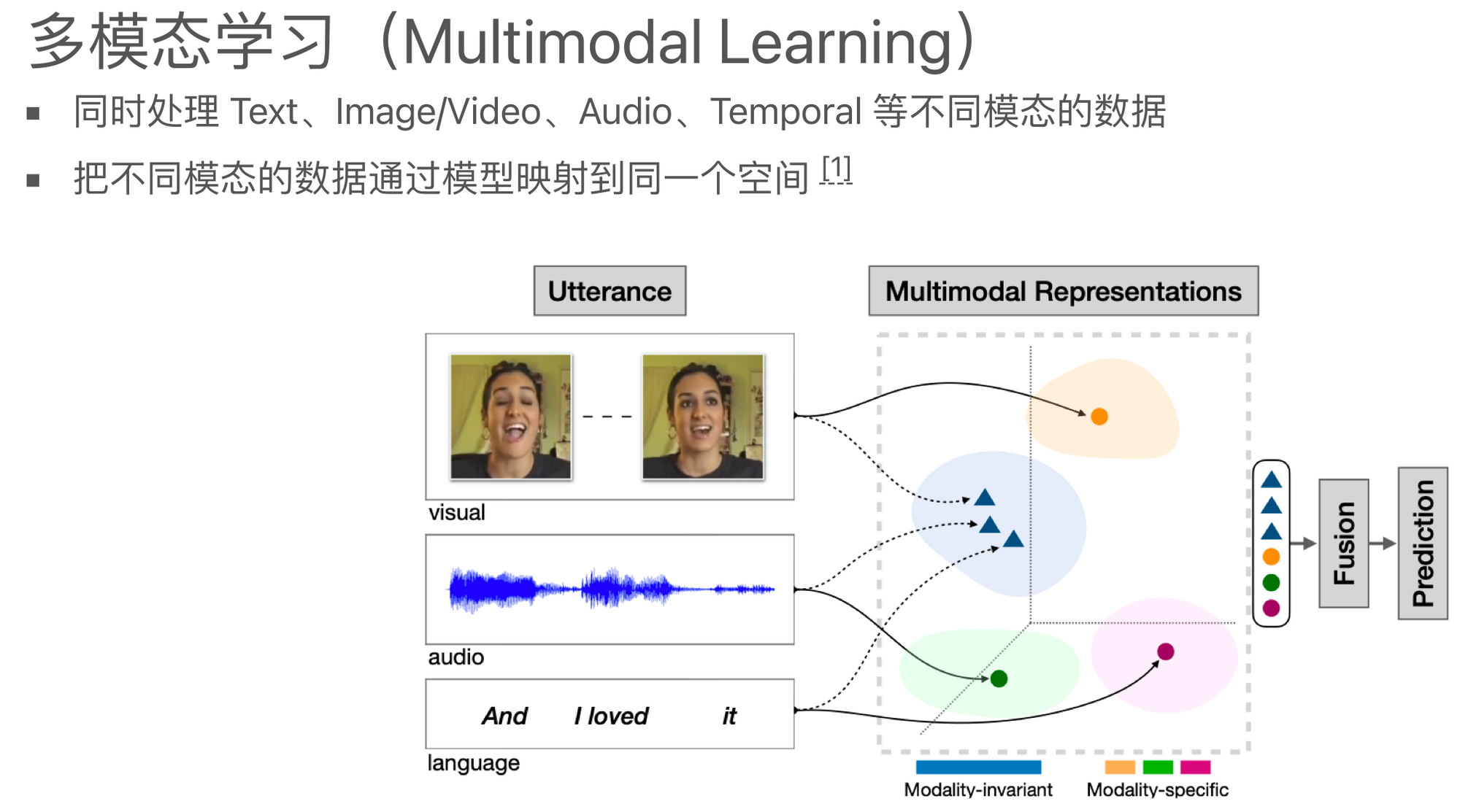
总的来说,多模态学习期望在任务执行上,不仅能比原来的单模态数据训练出的模型效果更好,同时还要具备跨模态的能力,这是其价值所在。具体来说,现在的多模态模型的基本思路就是把不同模态的数据通过模型映射到一个共享的空间中。
多模态学习的目标是要将语音、图片、文本等不同模态的数据映射到一个统一的空间中。如果我们针对单一模态进行训练,那么得到的模型最终会将每一段文本或每一张图片等转化为一个稠密的向量来表示。然而,由单一模态训练出的模型,它们得出的这些向量表示在空间中的差异往往很大,缺乏可比性。而多模态学习则是希望通过同时建模这些不同模态的数据,让模型生成的这些向量有可比性,即在空间中具有对齐关系。
例如,文本中的"猫"与图片中的猫应该有对应关系。多模态学习希望通过学习得到统一的表示空间。一旦有了这个表示空间,接下来的应用就会比较简单。比如说,你把所有的信息都建模到同一个空间后,在数学上或者模型上,就没有了模态差异的概念。在模型或数学视角看来,它们都是完全同质化的。这就是把信息统一到同一空间后的一个重大好处。
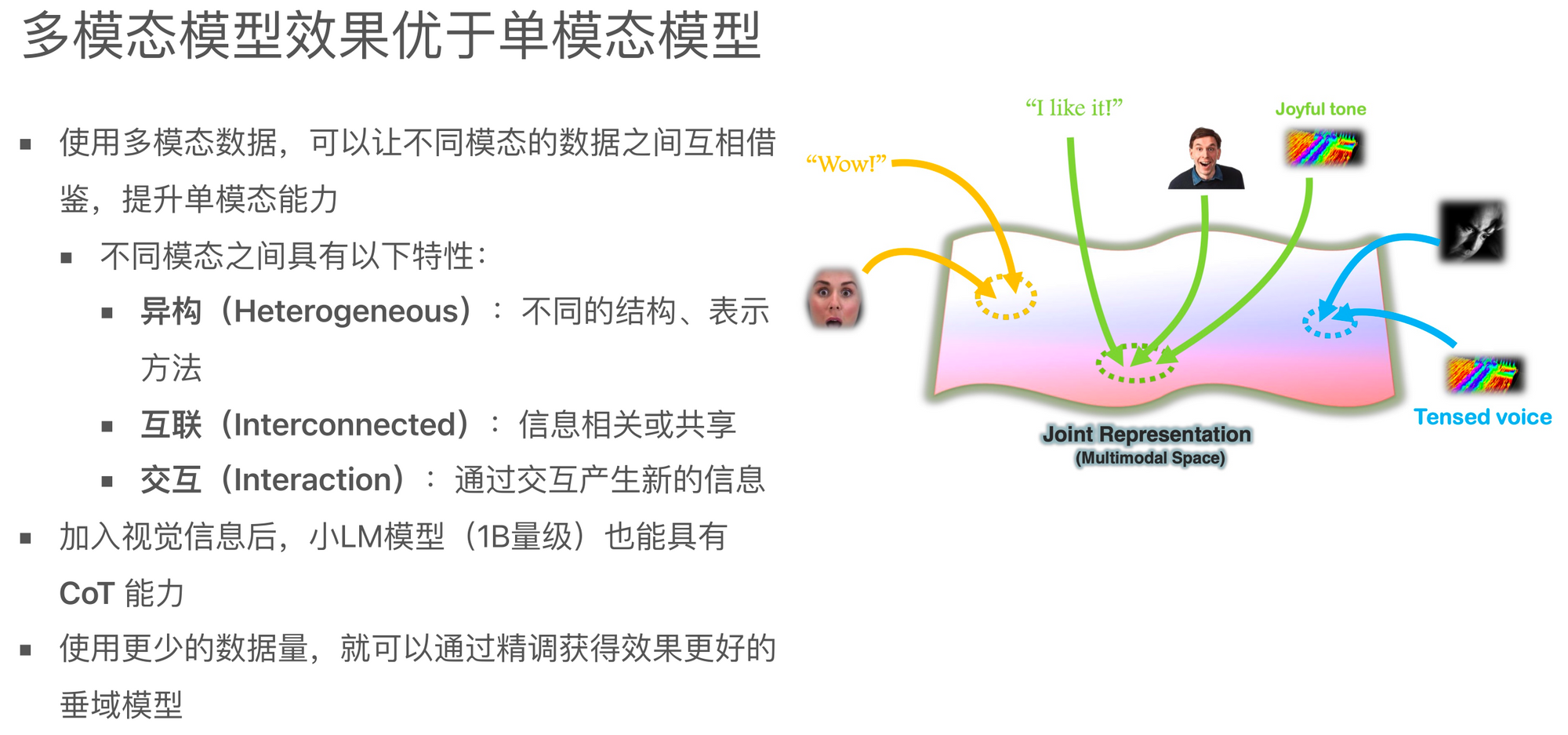
刚才我们也提到,多模态学习本身存在一些特性,其中包括异构的数据之间的信息表达方式会有所不同,或者说数据中包含的信息不会完全相同。同时,他们之间存在关联性,而且当它们被放在一起建模时,它们应该能够产生一些交互,通过这些交互能够带来一些单模态无法提供的信息,这是交互带来的价值。
下图右侧提供了一个模态交互的例子来说明多模态学习的价值。假设有两个模态的数据,A和B,每个模态的数据可能都能产生一个输出,其中包含某种信息。多模态学习可以看作是对这两个模态的信息进行处理,而处理结果可能会因情况而变化。

如果A和B的信息是冗余的,那么将他们一起输入到模型中可能会得到跟单一模态相同的结果,或者可能会得到一个加强版的结果,即原来的信息会被加强或完善。
如果A和B中包含的信息是非冗余的,比如A包含一个方形,B包含一个圆形,那么将他们合并作为模型的输入可能会依据它们之间不同的关系而产生不同的结果。比如,它们的输出可能会保持各自的形状(方形或圆形);或者其中一个模态的信息可能会调节另一个模态的信息,比如B模态的圆形可能会强化或减弱A模态的方形信息;还有一种可能是,他们的交互可能会产生一个全新的信息,比如一个三角形。
所以,通过不同模态之间的数据关联和交互,我们可以学到一些在单模态情况下很难学到的信息,或者需要更多数据才能学到的信息。这就是多模态学习的价值所在,也是为什么这个领域的热度一直在提升。
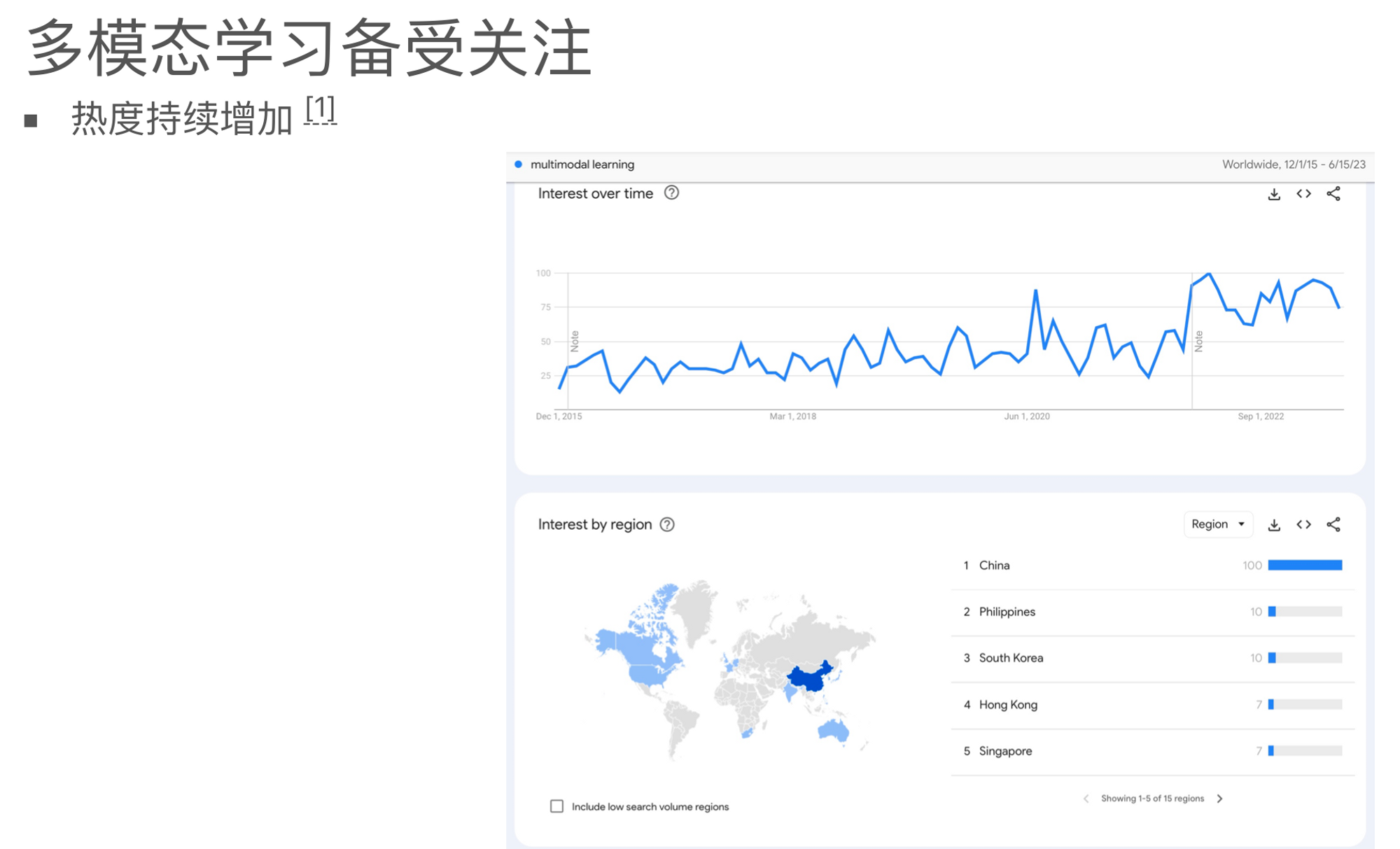
从Google Trend看,多模态学习的热度在过去的几年中不断提升。近几年一种叫做**对比学习(Contrastive Learning)**的深度学习方法正在被广泛研究,而且这种方法经常用于训练多模态模型。通过对比学习技术,研究人员现在能够比较有效地训练多模态模型。
为什么需要多模态学习
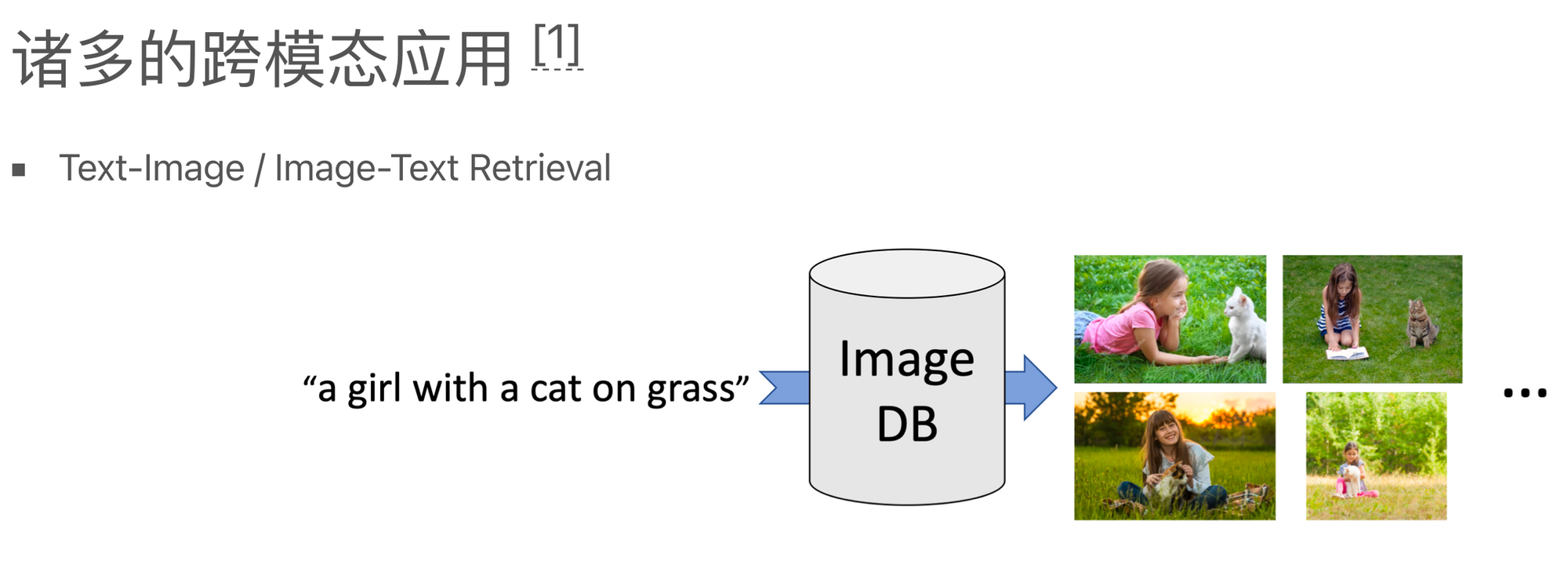
接下来,介绍下为什么我们需要多模态学习。很多现代应用实际上是跨模态的,例如使用文本检索图片库中的图片,或者使用图片在文本库中检索相关的文本。尽管现在使用Google或百度进行这样的检索看起来非常正常且效果良好,但在十年前,这种问题的解决方案并不理想。如果互联网上有一张图片,旁边通常会有一些描述该图片的文本,而之前的以文搜图就是基于这些文本进行的。这种方法会导致搜出来的结果中噪音比较大,可能会出现一些奇怪的内容。
然而,现在我们已经可以通过跨模态的能力和语义搜索来实现这种功能,而不再完全依赖于互联网上原始图片对应的附近的文本。现在这种搜索已经变得非常简单,而在五到十年前,它仍然是一个非常困难的任务。
还有很多其他跨模态任务,比如如何使用文本和图片进行视觉问答(VQA)、推理和文本生成等任务。这些任务在最近一两年中,因为多模态生成模型的发展,取得了显著的进步。
文本到图片生成的Stable Diffusion和MidJourney等模型,它们也都利用了(生成式)多模态学习。

从模型效果方面看,多模态学习在不同模态之间进行能力借鉴,特别是存在在数据较少或者学习能力差的模态情况下,可以通过从较强的模态中迁移能力来优化弱模态的学习结果。
以往的结论是,只有在LLM达到巨大的规模(约1000亿参数)时,才可能表现出**思维链(CoT)**的能力。亚马逊最新的研究发现,当语言模型接入视觉信息后,即使在参数数量达到10亿级别的情况下,它也可以展现出强大的CoT能力。
多模态模型还有一个好处。首先,从零开始训练大型模型需要大量的资源,尤其是当其中一个模态为图片或视频时,资源消耗会更大。因此,小公司通常选择在公开的大模型基础上进行微调。从我的经验来看,如果要微调的模型是多模态的,那么在相同的资源情况下,其效果往往比单模态模型更好。对于垂直领域或小公司,微调多模态模型所需要的数据量会比单模态模型(如语言模型)小得多。在这种情况下,使用多模态模型的性价比会更高。
前几天Hinton在智源大会的分享,引发了大佬们(LeCun、Andrew等人)关于LLM能否通向AGI的热议。杨老师(Yann LeCun)的观点是,单靠语言模型是无法实现AGI的,人类自身是多模态学习的生物,而且很多信息在单纯的语言中难以体现。当GPT3.5或GPT-4刚出现时,很多人觉得离AGI似乎越来越近了,但现在看来,LLM仍存在很多难以解决的问题。在模型参数达到1000亿级别之后,增加更多的参数只能带来越来越小的收益。

有一种观点认为,要真正向AGI进军,仅仅依赖LLM是不够的,需要让模型接触到更多的模态数据。这也是为什么像Meta这样的公司在推动多模态学习方面投入了大量的精力,他们不仅在图像处理方面具有传统优势,而且在多模态学习领域也开源了许多模型。尽管这一观点并非所有人都认可,但确实也有人相信多模态模型更有可能推动AGI的发展。
多模态学习的几个发展阶段
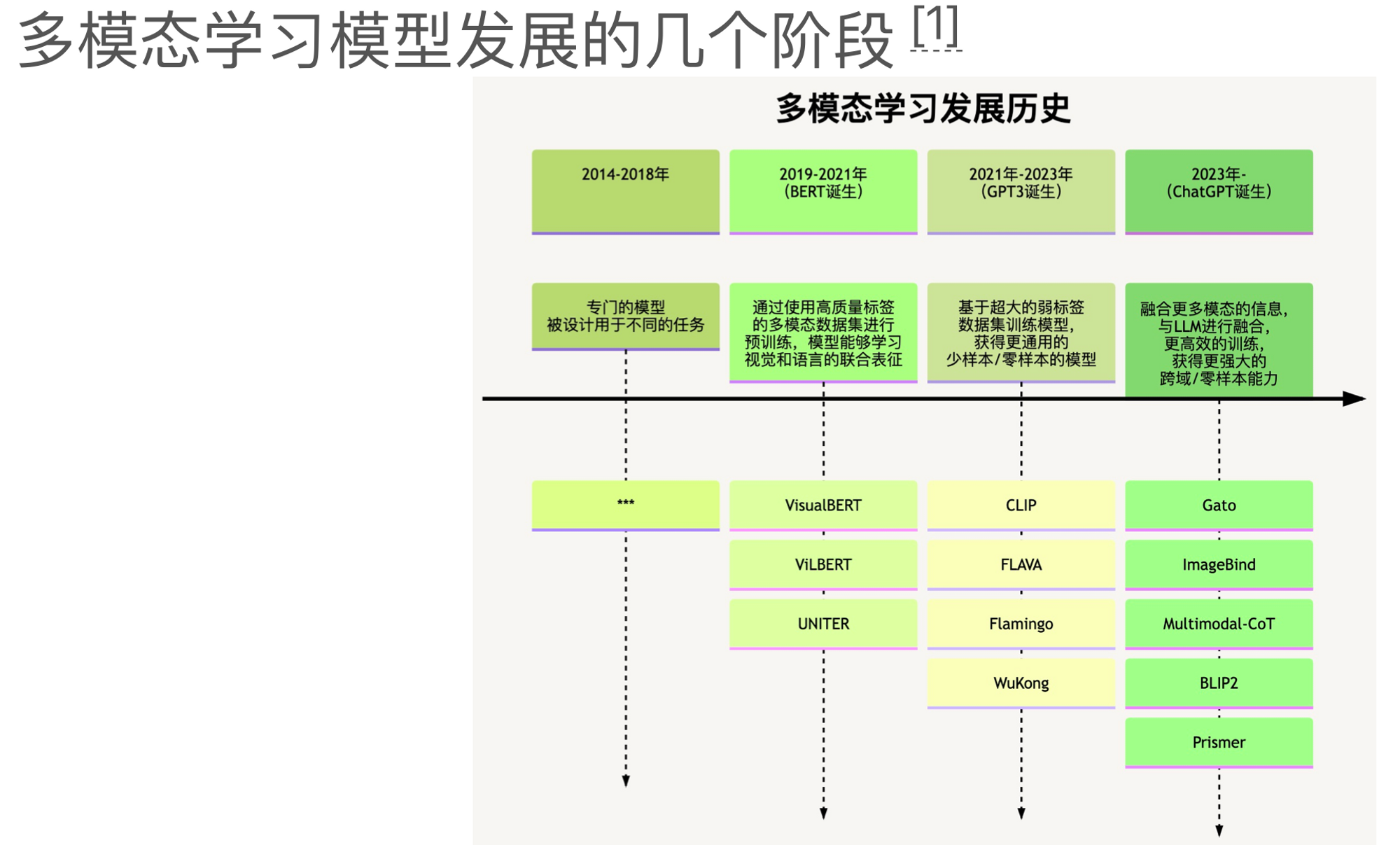
接下来对(深度学习时代)多模态学习发展历史做个简单的介绍。首先回顾下2014年至2018年期间深度学习的发展。这个阶段,大家逐渐意识到深度学习在许多任务中的优势,其效果超过传统的机器学习方法,所以大量的研究开始专注于改造和优化各种具体任务和应用的模型。
2019年到2021年,对应BERT的诞生以及黄金发展期,深度学习在文本领域的应用尤其引人注目。在这个阶段,人们开始广泛使用高质量的人工标注数据进行多模态模型的预训练,并验证了这种方式训练出的模型可以有效地在同一向量空间内表示不同模态的数据。
这是一种重要的进步,因为只有在同一空间内,才能对不同模态的数据进行有效的比较和操作(比如加法和减法)。这种在同一表示空间中表达多模态数据的方法是通用多模态模型的一个重要目标。
深度学习模型进一步发展的一个重要里程碑,即 2021 年 GPT-3 的出现。GPT-3 带来的最大影响是让人们意识到,如果模型足够大,即使在非常少的样本或零样本情况下,它也能做得很好。GPT-3 的“零样本”或“少样本”学习能力给业界带来了很大的冲击。
在早期的深度学习或 Transformer 模型中,虽然预训练-微调(pre-training and fine-tuning)范式已经大大减少了标注数据的需求,但对于特定任务仍需要一定量级的标注数据。GPT-3 的出现,进一步减少了这个需求,可能只需要标准几个甚至不需要标注的数据,也可以达到很好的效果。这一发现挑战了以往的认知。
这期间有一个重要的多模态模型不得不提:CLIP。CLIP使用了海量的有噪声的文本-图片对多模态数据进行训练,结果发现其效果比使用人工标注的高质量数据更好。CLIP是开源的,也来自OpenAI,即ChatGPT的创造者。
CLIP让大家意识到,使用海量有噪声的数据进行模型训练也是可以的,只要要求数据的规模远大于人工标注的高质量数据。自从CLIP模型的出现,多模态学习领域的发展速度持续加快。其他公司也放出了很多其他的模型,包括 Meta 的 FLAVA,DeepMind 的 Flamingo 和华为诺亚方舟的悟空等。
ChatGPT发布后,各个方向都在思考如何将其应用到自己的任务中,进而引发了新的趋势:尝试合并或融合不同模型(如ChatGPT等LLM)的能力。多模态学习中有两个大趋势,一是把LLM的语言理解和推理能力融合到多模态模型中,二是增加更多模态的融合,从而提升模型在训练模态上的效果,同时也使其能够迁移到未训练过的模态上。
多模态模型整体架构
简单描述下多模态模型的总体架构思路:首先,对输入数据(如文本、图像等)进行编码,得到表示向量;其次,将这些向量进行融合,可能还包括融合一些外部知识,如知识图谱、语言模型、计算机视觉模型等;最后,模型可以基于单模态数据和融合数据输出表示向量。整体思路其实也适用于许多深度学习模型的训练。

模型最后一部分是损失函数(或目标函数)。损失函数(或目标函数)对于模型的训练至关重要。损失函数决定了模型的学习目标,以及如何对模型的表现进行量化。
在特征编码阶段,文本通常使用Transformer架构进行编码,而图像则可以通过卷积神经网络(CNN),或基于目标检测的方法,或直接对Patch进行编码。
在多模态信息融合的过程中,有两种主要的框架:一种是将所有模态的编码放在一个大的框架下进行处理,称为"单流模型";另一种则是让各个模态各自建模,然后使用简单的连接或者轻量级的层进行集成,称为"双流模型"。
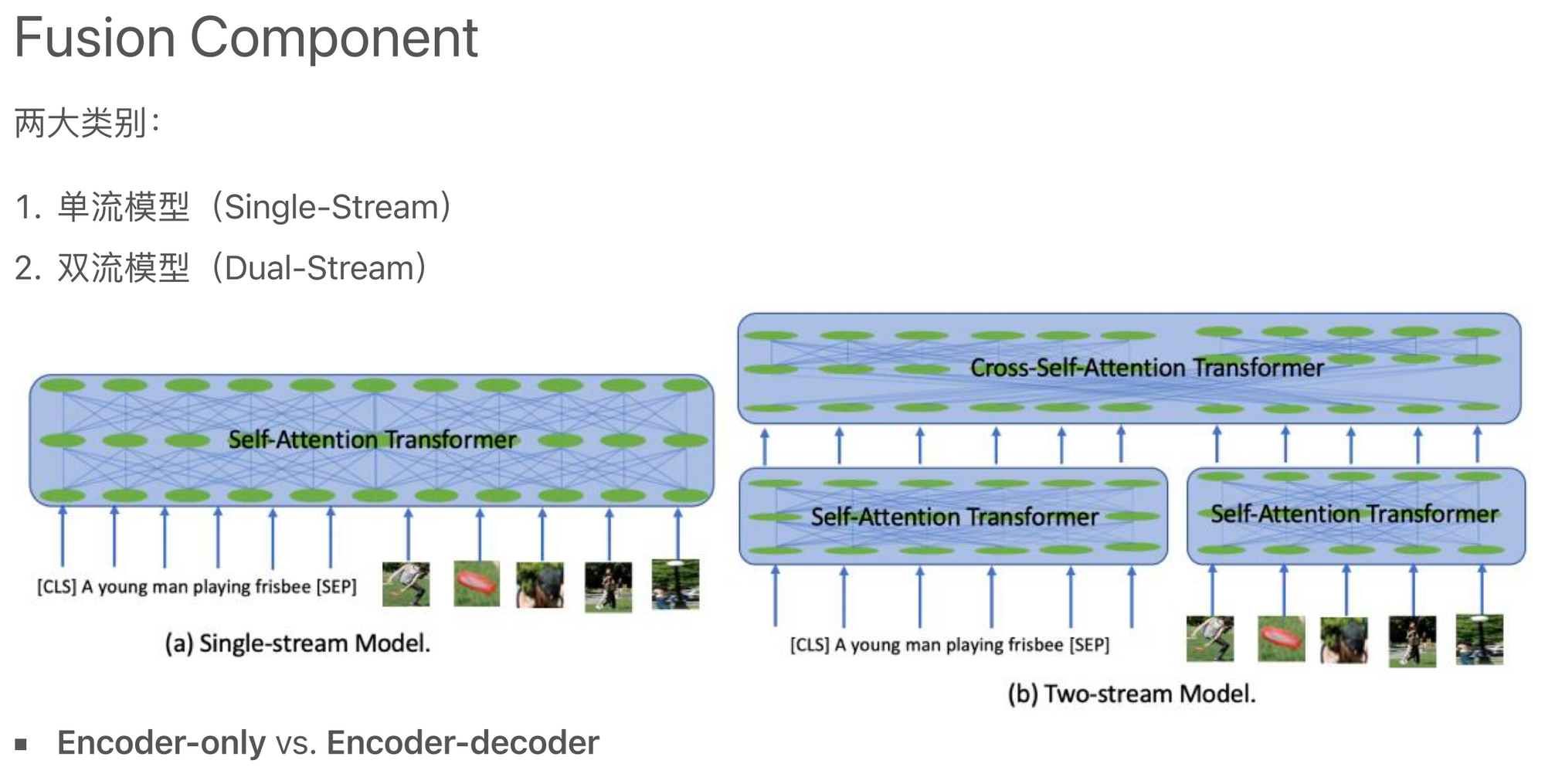
在损失函数的部分,有一些常用的方法,比如文本中的Masked Language Modeling (MLM),它会遮盖一些词语并让模型去预测它们。在图像中,也可以使用相似的方法,通过掩蔽一部分图像并让模型去预测被掩蔽的部分(MRM)。还有,是让模型学习图像和文本之间的全局表示,并通过匹配或对比的方式去判断它们是否匹配(ITM、ITC)。这些都是让模型学习如何处理和理解多模态数据的常用损失函数。

多模态学习中的代表性模型
下面介绍一具有代表性的多模态模型。
ViLBERT
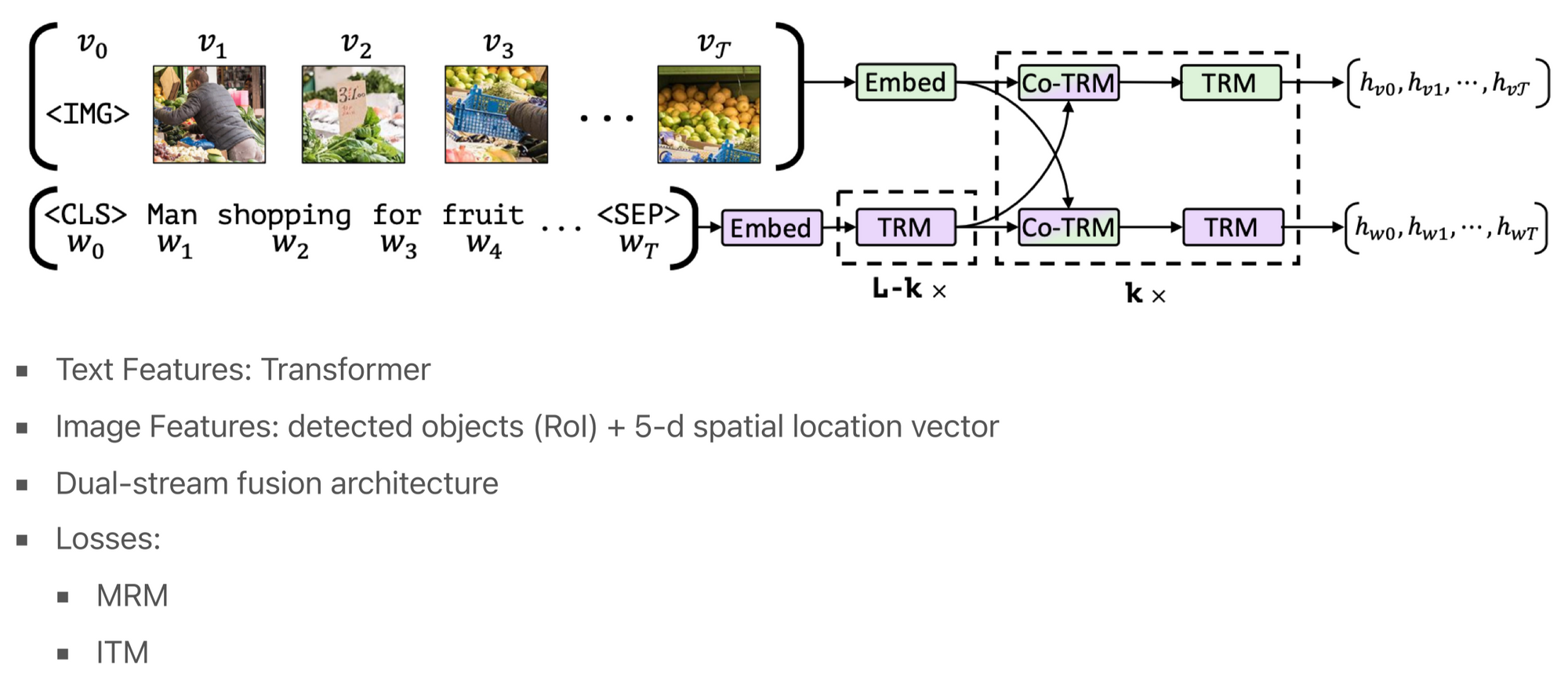
ViLBERT 这个模型在文本和图像编码方面分别使用了Transformer和目标检测结果。将文本和图像转化为向量形式后,通过一种名为”Co-Transformer"的方式来将二者融合。
CLIP
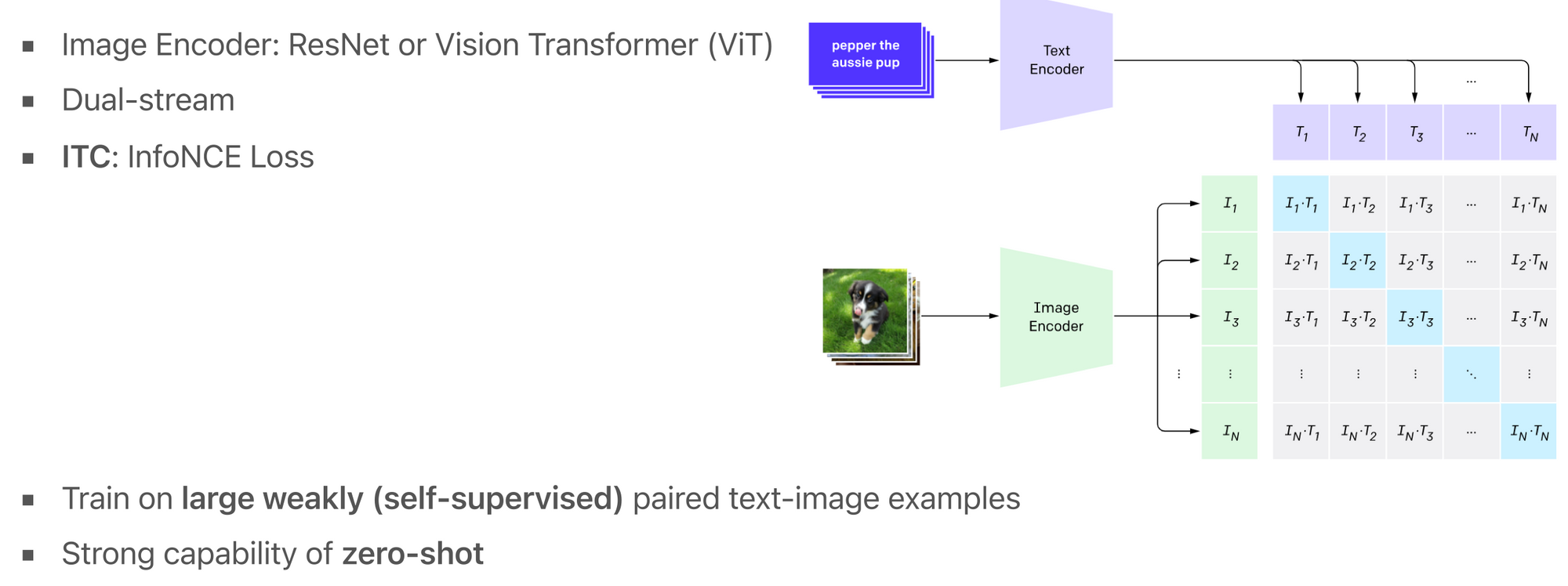
CLIP 模型的思路非常简单,它将图片和文本利用Transformer分别编码为向量,然后使用对比学习(ITC)的方式进行训练。ITC使来自同一对的图片和文本的向量在向量空间中尽可能地靠近,而来自不同对的图片和文本的向量在向量空间中尽可能地远离。CLIP模型使用了大量的弱对齐的图片-文本对,这些数据是从网上收集的,不需要专门的人工标注。
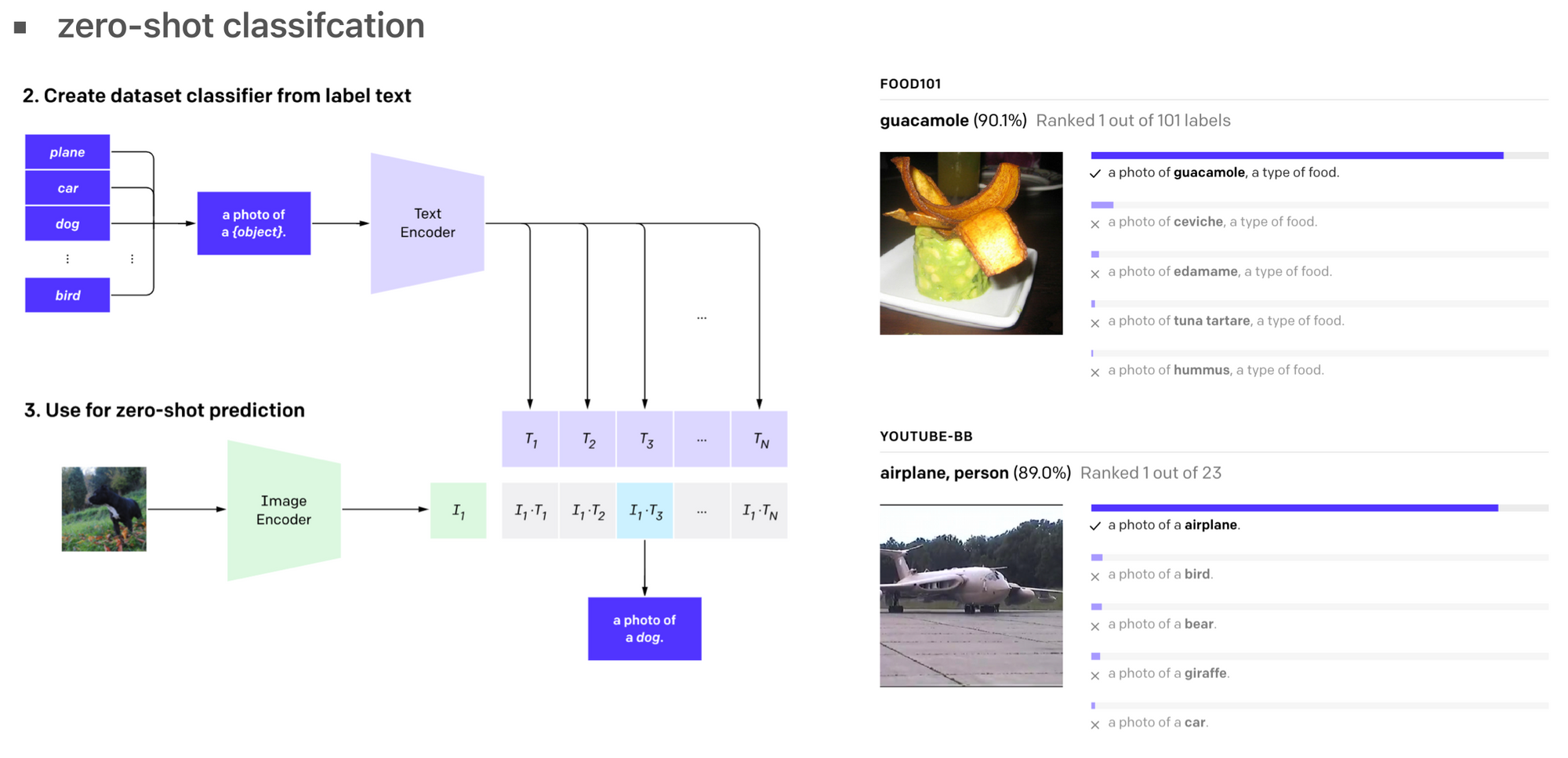
CLIP 可以用来做**零样本分类(zero-shot classifcation)**任务。相比传统的分类模型,多模态模型可以处理未见过的类别。例如,如果训练数据中只有猫和狗的图片,但在测试时出现了熊猫的图片,多模态模型依然有可能正确识别出熊猫。
CLIP的一些其他应用案例:
-
图像生成:多模态模型可以与生成模型结合,根据文本生成对应的图像。比如,模型可以根据“棕色头发的埃隆马斯克”这样的文本描述生成对应的人物图像。
-
目标追踪:在视频处理中,可以利用多模态模型进行目标追踪。例如,模型可以识别每一帧中的目标(如鲨鱼),然后比较不同帧中的目标,找出最相似的一对,从而确定目标在视频中的移动轨迹。

在这段对话中,Jinlong讨论了多模态学习的进一步发展——多模态学习的拓展,以及对六个模态的整合和训练的探索。他首先提到国内一些多模态模型的工作,主要是使用中文互联网数据,并指出这些模型与原始的CLIP模型在结构上的差异并不大。
ImageBind
今年的一个新趋势是,是融合更多模态数据的多模态模型。以前,大部分的工作都关注在两个或最多三个模态,比如文本和图像,或者文本和语音。最近,Meta开源的模型 ImageBind,该模型利用了6个模态的数据进行训练,包括视觉、文本、声音、深度图、热力图以及运动向量图。
这个模型的训练过程相当于训练了五个双模态模型,每一个都是其他五个模态与视觉模态的结合。通过这样的方式,所有的模态都被对齐到图像模态的表示空间,从而可以把所有的模态统一到一个共享的表示空间。
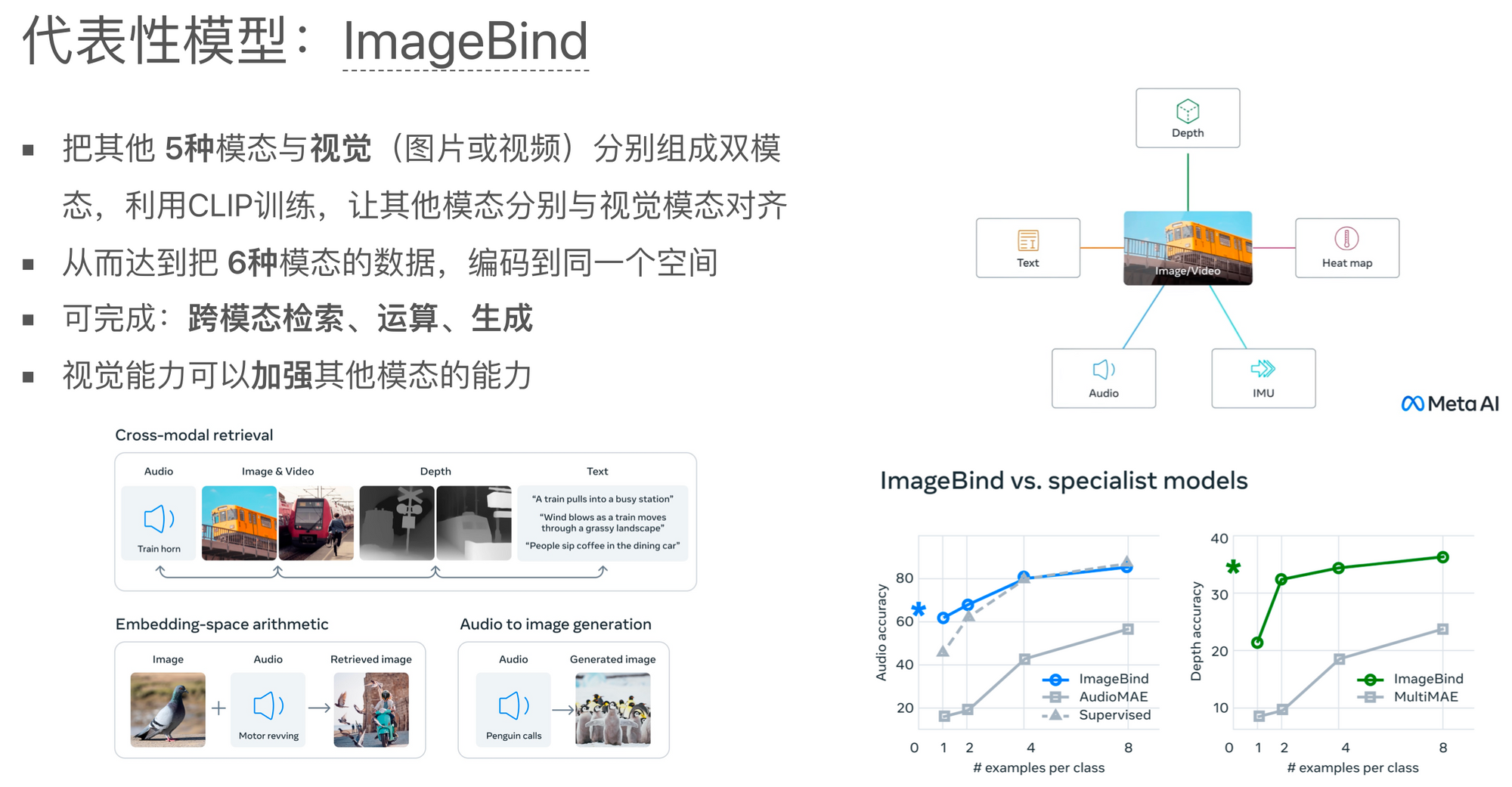
这种方式训练出来的模型有很强的跨模态检索能力,例如,可以通过一个声音去检索图片、视频、深度图和文本等。这样的跨模态模型可以被应用在很多场景中。
ImageBind还可以做跨模态的计算。例如,给出一张鸽子的图片和摩托车引擎的声音,这两种模态可以相加形成一个新的向量,然后用这个新的向量去检索相应的图片,可以得到一个人正在骑摩托车、旁边有鸽子被吓飞的情景。这就好像是将图片向量和声音向量相加,得到了一个具有内在含义的新向量。
同样,可以在不同模态上执行跨模态的生成。比如说,通过企鹅的声音,可以生成与企鹅相关的图片。
这些都展示了通过多模态联合训练,模型可以实现一些有趣且具有实用价值的功能。
ImageBind论文中还展示了"强模态"(例如视觉)对"弱模态"(例如声音或深度图)的提升作用。通过多模态联合训练,强模态的性能可以迁移到弱模态上,从而提升弱模态的性能。比如,在声音或深度图上的任务效果,经过与视觉模态的联合训练后,会比原先单独训练的结果要好。这种迁移能力进一步增强了多模态模型的应用价值。
在这段对话中,Jinlong详细讨论了在多模态(包括视觉和文本等)训练中使用已经训练好的模型的可能性。
Multimodal-CoT
Multimodal-CoT是近期亚马逊李沐团队的工作。该工作的目标是探索通过添加视觉信息,是否可以使小型语言模型也具有推理能力。作者的结论是,通过引入视觉信息,小型语言模型确实能够实现某种程度的推理能力。如果没有视觉信息,只有文本信息,那么语言模型的参数规模大约需要达到1000亿。因此,通过引入多模态信息,语言模型的能力确实可以得到提升。

BLIP-2
BLIP-2 是 Saleforce 的工作。该工作的主要目标是在多模态模型中引入已训练好的模型,通过只训练少量的模型参数来获得好的效果。这种方式有点像使用胶水将已经训练好的,功能强大的单模态模型粘连在一起。在他们的例子中,他们使用了在CLIP中训练好的图像编码器,并在此基础上添加了一个语言模型(OPT 或者 FlanT5)。这样生成的模型可以用来执行视觉问答(VQA)任务,即给定一张图片,模型需要回答关于该图片的问题。
这种方法的优点是它能够复用已经训练好的模型,并且只需要训练相对较少的参数。这在某种程度上减轻了训练的压力,降低了训练资源的消耗,并且还能保持相当不错的效果。BLIP-2的可训练参数量是 DeepMind Flamingo 的 1/50,在VQA任务上的效果还更好。

今年的一个趋势,是使用大型预训练模型(如7B或33B的LLM)来增强多模态模型的性能。这是因为在大部分情况下,研究者没有足够的资源从零开始训练一个大型模型。所以,一个可能的解决方案就是使用已经存在的公开模型,并用少量的数据和参数来训练一个具有类似能力的模型。
多模态学习面临的挑战和未来发展方向
数据的采集和对齐
接下来,讨论下在多模态研究中面临的挑战和未来的发展方向。
首先的一个问题是数据采集的问题。数据越干净、越多,模型的性能就越好。但是,某些类型的数据可能很难采集,尤其是需要与其他模态数据进行对齐的数据。训练时为了更好地利用数据,可以考虑同时使用对齐数据和单模态数据,因为收集对齐的训练数据是非常困难的。图片与文本的对齐数据在互联网上比较容易获得,但是其他类型的对齐数据可能就比较难收集了。
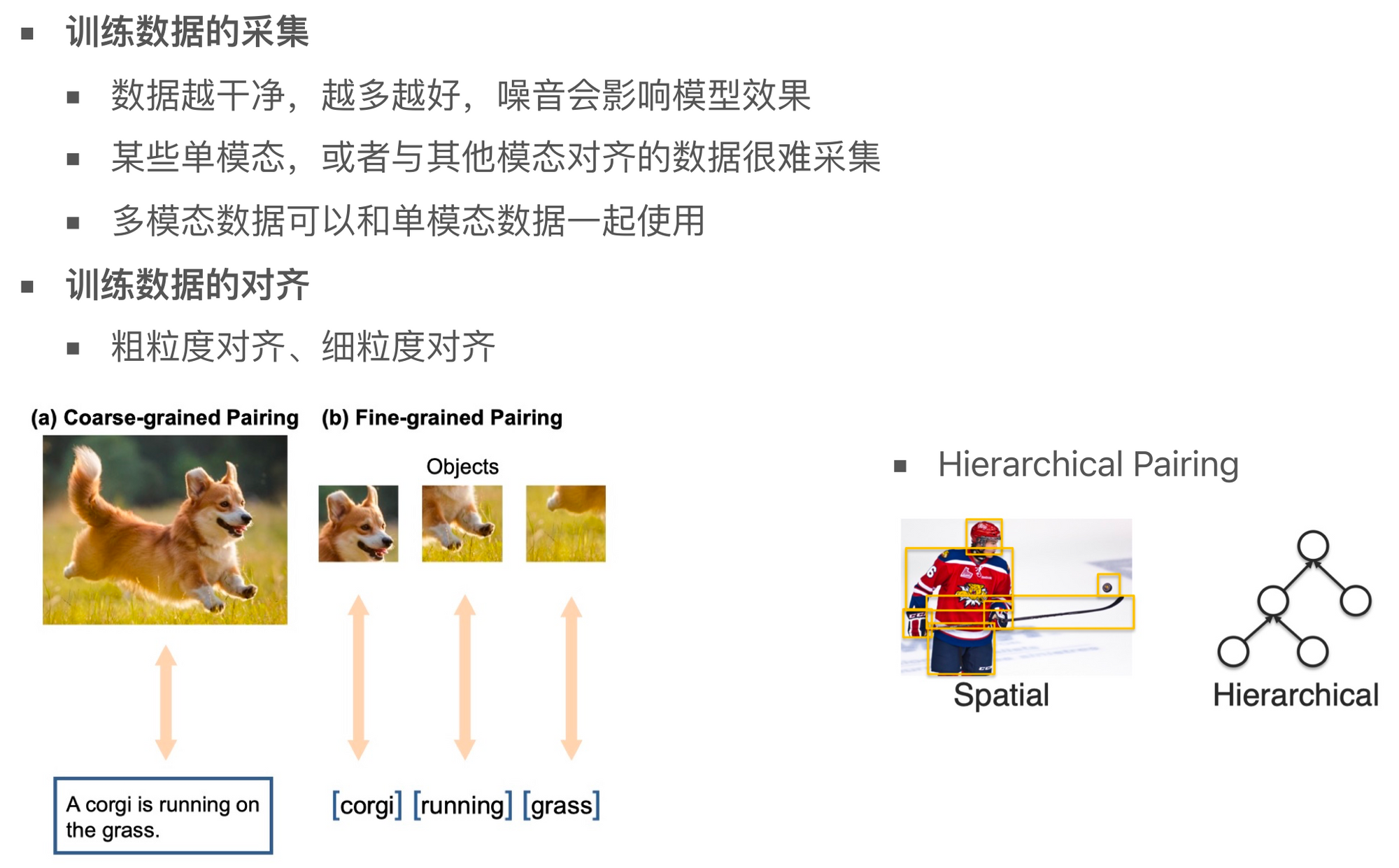
数据对齐还可以分为粗粒度对齐和细粒度对齐。手机细粒度对齐数据是非常困难的。例如,将一个名词准确地对齐到图片中的特定部分,或者将动词与具体的动作对齐,这都是非常复杂且困难的任务。此外,如果需要对齐的数据具有层级关系,那么这个任务就更加困难了。
模型面对的挑战
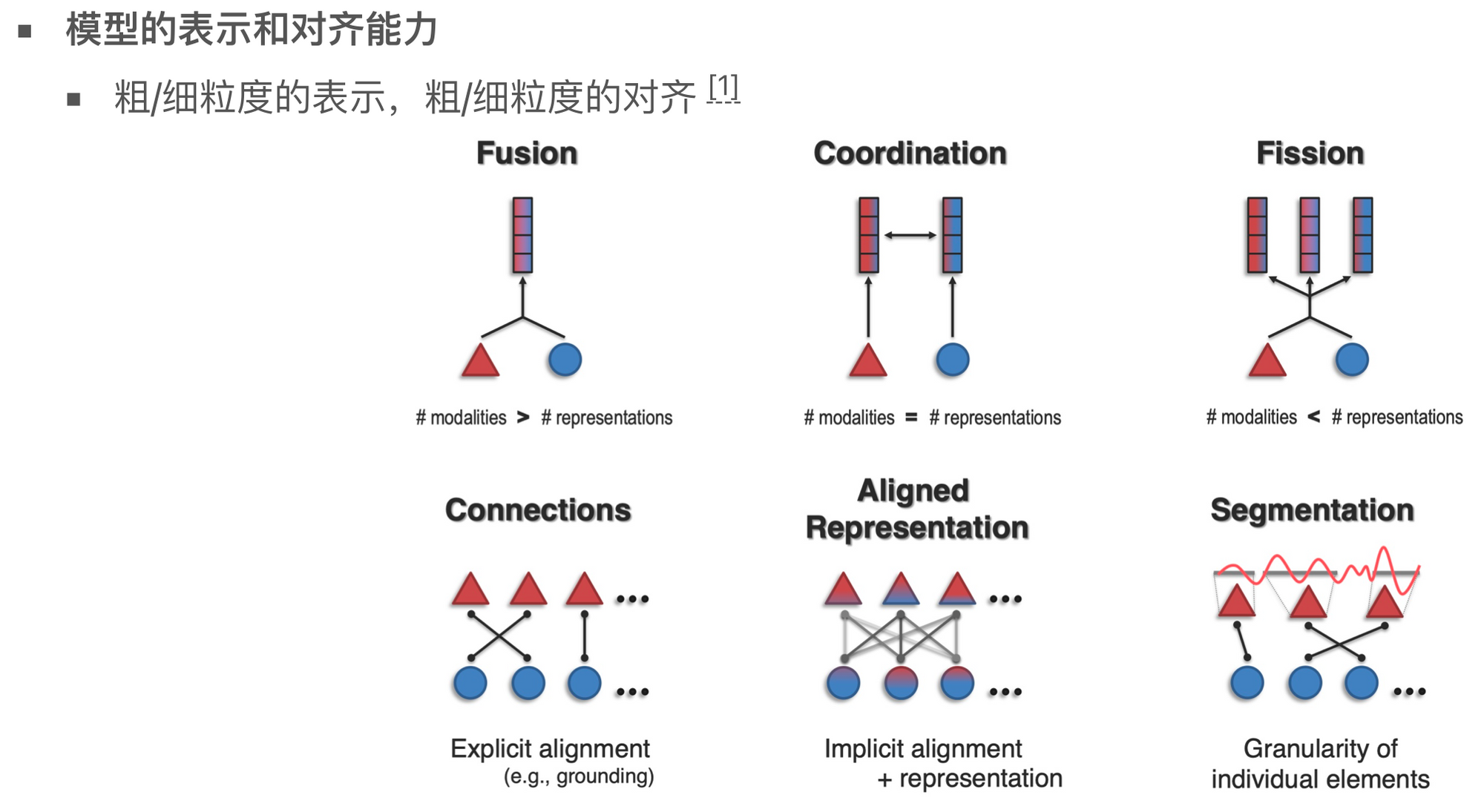
模型的表示和对齐也存在很大挑战。不同模态的数据在表示上可能需要进行融合,因为它们可能代表相同的概念。同时,某些模态之间的数据可能需要相互协同工作。对齐过程也很复杂,模型可以做显式对齐,或者隐式对齐,对序列数据困难还涉及到对数据切分后进行对齐。
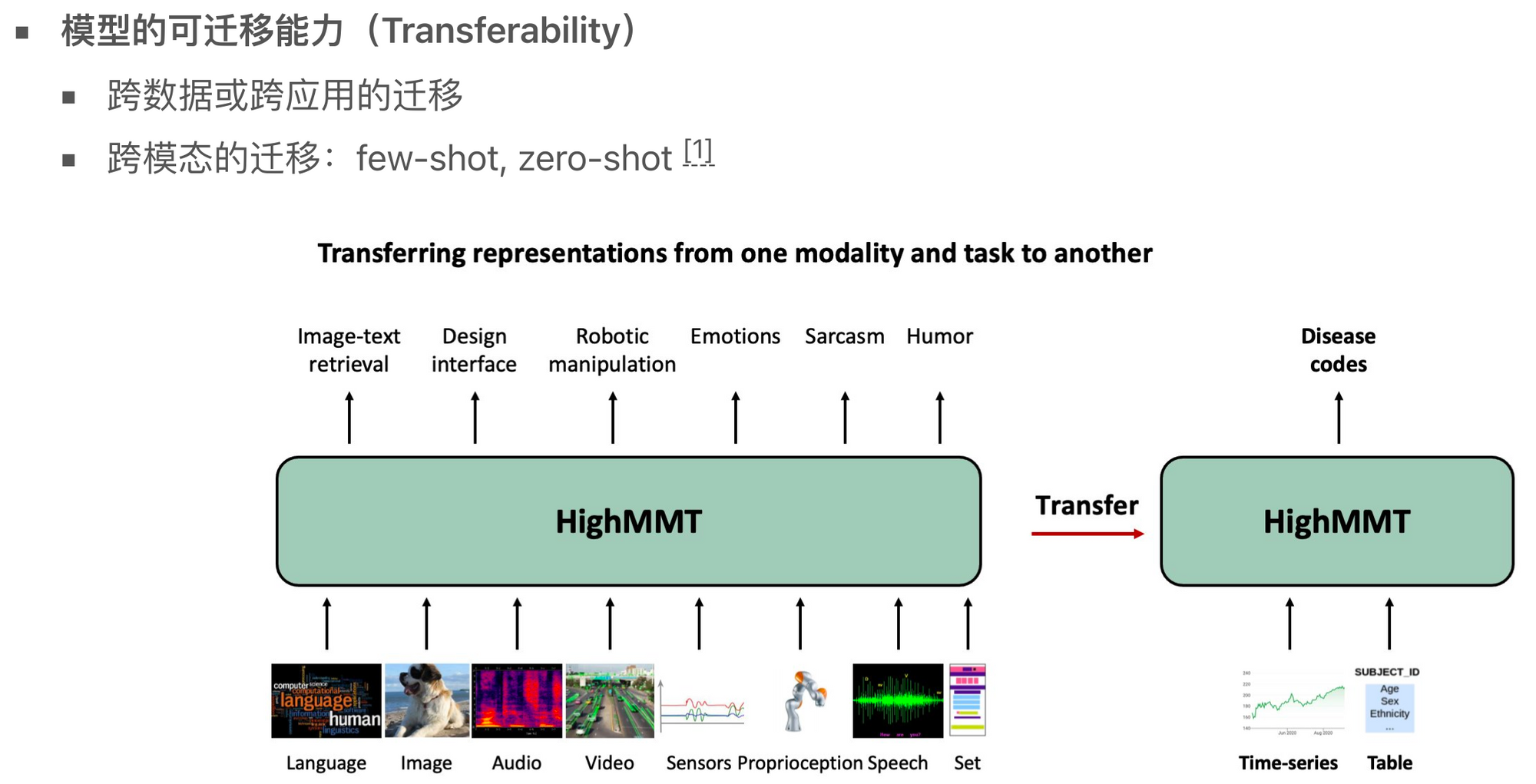
另一个大的挑战是模型的可迁移能力。一个数据集上训练的多模态模型能不能在其他的数据集上表现良好?如何利用在一个强模态上训练的模型来增强弱模态的能力,以及如何将这些模型推广到其他模态的数据上。这些都是当前多模态学习领域正在探索的问题和发展方向。
模型方面的一些其他挑战:
-
合并越来越多的模态以增强跨模态能力:目前已经有些工作在探索如何在一个模型中整合更多的模态,以增强其跨模态学习能力。
-
模型与外部知识的融合:如何更好地将模型与外部知识(如闭源的LLM,例如ChatGPT)融合在一起,是一个具有挑战性的问题。
-
向统一模型框架的发展:尽可能地让不同模态的数据使用同一种模型框架进行编码和表示。这不仅包括使用统一的模型框架,甚至还包括共享模型参数。
-
涌现能力(Emergent Ability):在处理多模态数据时,有可能会出现一些类似于LLM中的涌现能力。

更高效地训练模型
如何高效地训练多模态模型,是另一个非常具有挑战性的问题,特别是当训练数据量级达到十亿到百亿量级时,从头训练需要大量的计算资源,这对于小公司来说难以承受。
现在一些优化训练效率的方法:
-
训练更少的参数:融合其他预训练模型,只训练部分参数,如BLIP-2、Prismer等;对已有模型加个patch小模块,只训练这个patch小模块,如Lora、QLora等。
-
更高效地利用样本:由于多模态数据的收集挑战较大,所以更高效地利用样本是一个重要的主题。这可能涉及到更好地定义模型的目标函数,以及更高效的模型结构,以提升样本利用率。比如现在发现单流模型的样本利用率会高于双流模型。

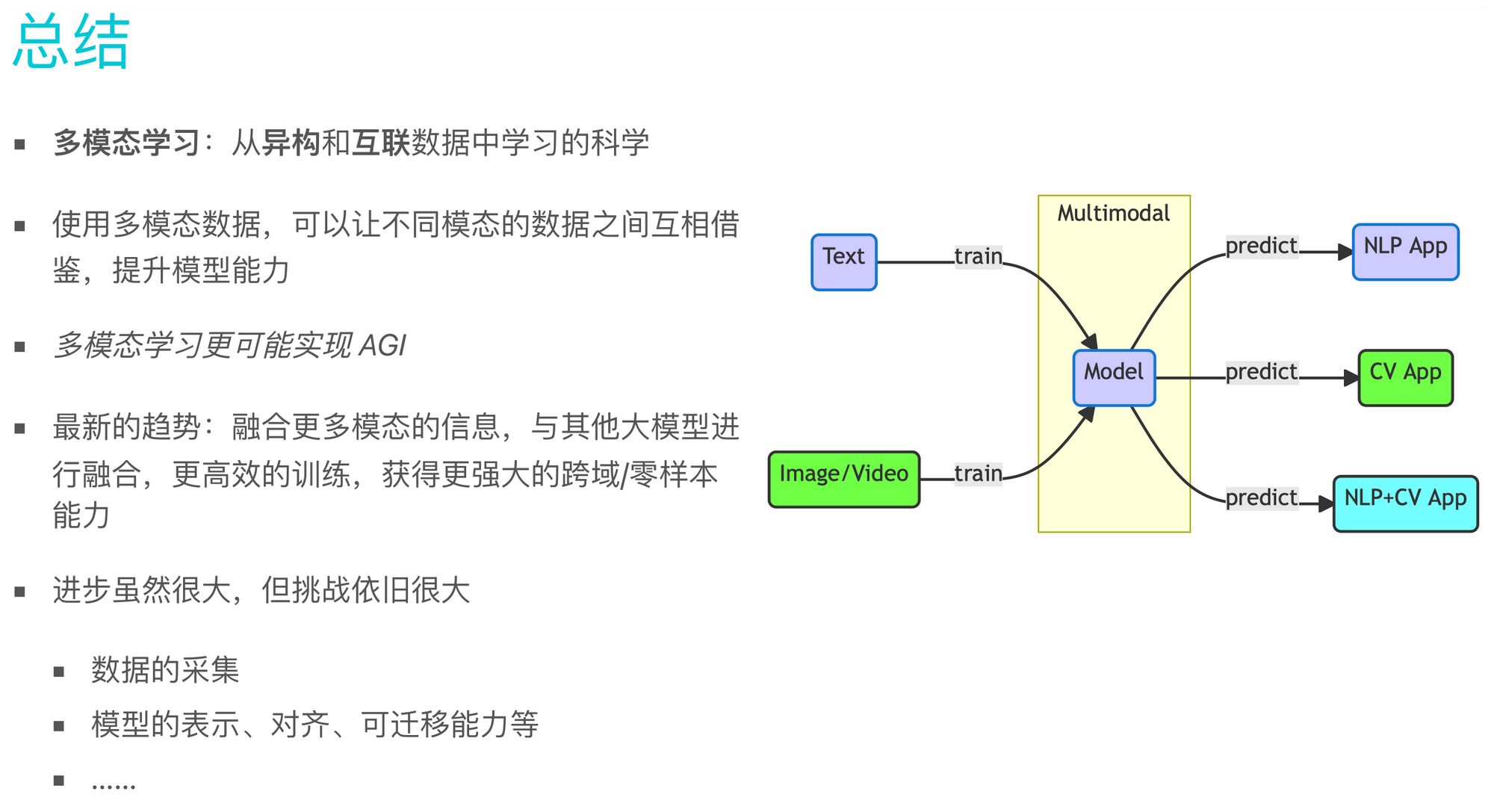
总结
最后,做个简单的总结。多模态学习是指从多个有差异但相关联的模态数据中学习知识的技术。这种学习方式可以使模型在单模态上的性能提升,同时实现跨模态应用。目前已经发现多模态具备某些单模态模型不具备的能力。例如,一些大型的多模态模型本身自带 OCR(光学字符识别)的能力。这是一个令人惊讶的发现,因为在训练这些模型的数据中,并没有显式地进行这项任务的训练。
从 OpenAI 的 ChatGPT 发布以来,多模态学习领域发生了很大的变化,例如如何与现有的大模型进行融合、如何使用更少的参数实现类似的效果、如何融合更多的模态,以及如何更高效地利用数据和资源来训练模型。总体目标是开发出具有更通用能力、跨模态和跨应用能力的模型。
有些观点认为多模态学习可能是实现 AGI 的一个重要方向。
尽管多模态当前已经取得很大进展,但面临的挑战依旧很大。例如,如何采集噪音小的多模态对齐数据?如何让模型更好地学习到不同粒度的对齐能力,可迁移能力等?