BLIP2是BLIP的续作,是一种多模态 Transformer 模型,主要针对以往的视觉-语言预训练 (Vision-Language Pre-training, VLP) 模型端到端训练导致计算代价过高的问题,在多模态模型中,参数量和计算成本比较高的分别是image encoder和text encoder。
所以,如果能够使用预训练好的视觉模型和语言模型,把参数冻结,能够节约不少的计算代价。
BLIP-2提出了一种借助预训练好的参数的预训练视觉模型和大型语言模型(冻结住参数),高效的视觉语言预训练方法。
但是,简单的冻结预训练好的视觉模型的参数或者语言模型的参数会带来一个问题:就是视觉特征的空间和文本特征的空间,它不容易对齐。那么为了解决这个问题,BLIP-2 提出了一个轻量级的 Querying Transformer,该 Transformer 分两个阶段进行预训练。第一阶段从冻结的视觉编码器中引导多模态学习,第二阶段从冻结的文本编码器中引导多模态学习。
经过这样的流程,BLIP-2 在各种视觉语言任务上实现了最先进的性能,同时需要训练的参数也大大减少。
背景
视觉语言训练 (Vision-Language Pre-training, VLP) 的研究在过去几年中取得了快速的发展,研究者们开发了规模越来越大的预训练模型,不断推动各种下游任务的发展。但是,因为使用了大模型。大数据集,而且采取了端到端的训练,大多数最先进的视觉语言模型在预训练过程中会产生很高的计算代价和经济成本。
多模态的研究属于是视觉和语言研究领域的交叉,因此大家很自然地期望视觉和语言模型可以从现成的视觉,语言的预训练模型中获得。为了节约视觉语言模型在预训练过程的计算代价,本文提出的 BLIP-2 希望借助现成的预训练好的单模态视觉模型和单模态文本模型。
这样做的好处是:预训练的视觉模型能够提供高质量的视觉表征。预训练的语言模型,尤其是大型语言模型 (LLM),提供了强大的语言生成和零样本迁移能力。为了减少计算成本并抵消灾难性遗忘的问题,单模态预训练模型在预训练期间保持冻结。
但是,简单的冻结预训练好的视觉模型的参数或者语言模型的参数会带来一个问题:就是视觉特征的空间和文本特征的空间不容易对齐。出现这个问题的原因是:文本模型 LLM 在单模态预训练期间没有看过对应的图片,视觉模型在单模态预训练期间没有看过对应的文本,所以这个对齐特别具有挑战性。
为了解决这个问题,BLIP-2 提出了一个轻量级的 Querying Transformer,如下图所示。该 Transformer 分两个阶段进行预训练。Q-Former 是一个轻量级 Transformer,它使用一组可学习的 Query 向量从冻结的视觉编码器中提取视觉特征,并充当视觉编码器和文本编码器之间的瓶颈。Q-Former 把关键的视觉信息传递给 LLM,第一个预训练阶段,强制 Q-Former 学习与文本最相关的视觉表征。第二个预训练阶段,通过将 Q-Former 的输出连接到冻结的 LLM 来执行视觉语言生成学习,使其输出的视觉表征可以直接由 LLM 解释。这样一来,Q-Former 就可以有效地利用冻结的预训练图像模型和语言模型。
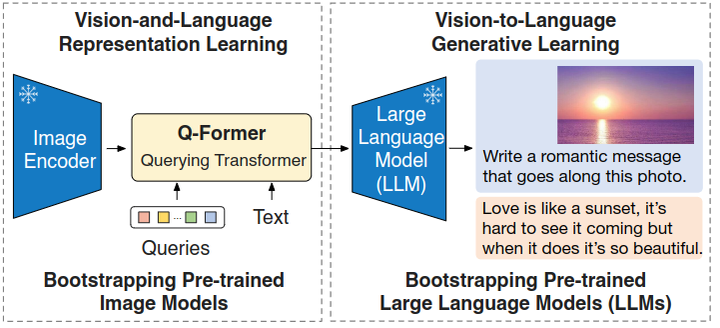
BLIP-2 架构
BLIP-2 由预训练好的,冻结参数的视觉模型和文本模型,外加所提出的可训练的 Q-Former 构成。固定的图像编码器从输入图片中提取视觉特征,Q-Former 架构是由2个 Transformer 子模块构成,其中注意 Self-Attention 是共享的,可以理解为 Self-Attention 的输入有2个,即:Queries 和 Text。
第1个 Transformer 子模块: 是 Image Transformer,它与图像编码器交互,用于视觉特征提取。它的输入是可学习的 Queries,它们先通过 Self-Attention 建模互相之间的依赖关系,再通过 Cross-Attention 建模 Queries 和图片特征的依赖关系。因为两个 Transformer 的子模块是共享参数的,所以 Queries 也可以与文本输入做交互。
第2个 Transformer 子模块: 是 Text Transformer,它既可以作为文本编码器,也可以充当文本解码器。
Q-Former 一共包含了 188M 参数,其权重使用 BERT-Base 做初始化,Cross-Attention 的参数做随机初始化。作者使用 32 个 Queries,其中每个 Queries 的维度为 768。Queries 随着预训练目标一起训练,迫使它们提取到与文本最相关的视觉信息。
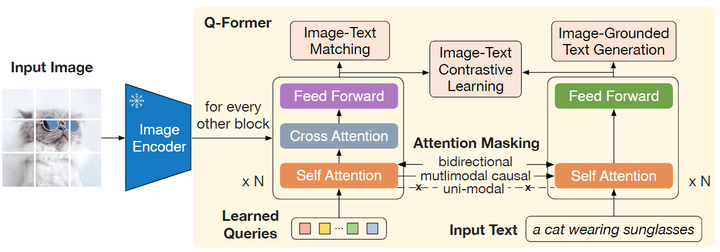
Q-Former 训练的第1步,架构是由2个 Transformer 子模块构成,其中注意 Self-Attention 是共享的,可以理解为 Self-Attention 的输入有2个,即:Queries 和 Text
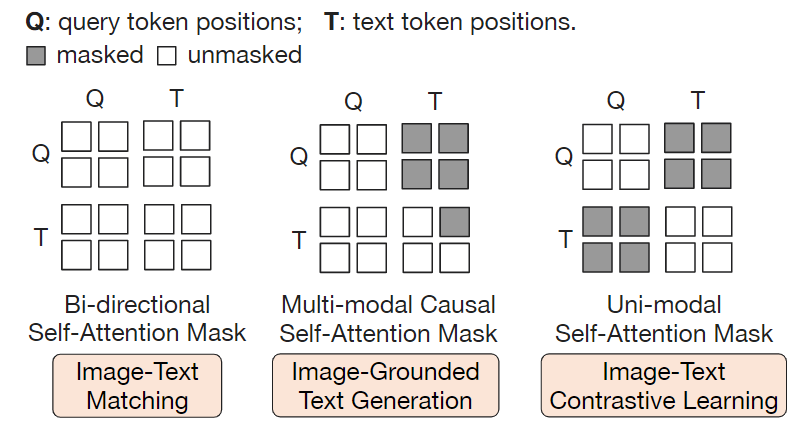
3个目标函数对应的 Attention 的 Mask
训练第1步:联合视觉编码器训练
Q-Former 训练的第一步,作者将 Q-Former 连接到冻结参数的图像编码器,并使用图像-文本对进行预训练,那么这一步的目标是训练好 Q-Former,以便 Queries 可以学习到如何更好地结合文本提取图片信息。
训练的目标函数,作者遵循 BLIP 的做法,联合优化3个具有相同输入格式和模型参数的预训练目标,每个目标函数使用不同的 mask Attention 来控制注意力的交互。
1 图文对比学习 (Image-Text Contrastive Learning, ITC)
这是多模态预训练中的经典目标函数,旨在对齐图像和文本的表征,使其互信息最大化。
ITC 实现的方式是:让正样本 (配对的图片文本对) 的相似度尽量高,同时让负样本 (不配对的图片文本对) 的相似度尽量低。那么对于 Q-Former 作者实现 ITC 的方法是计算 Queries 的输出 ZZ 和 Text Transformer 的 [CLS] token 输出 tt 的对比学习损失。因为 ZZ 包含了多个 Queries 的输出,因此作者首先计算每个 Queries 的输出和 tt 之间的成对相似度,然后选择最高的一个作为最终的图文相似度。ITC 的 Attention Mask 方法如图3的最右侧所示,属于 Uni-modal Self-Attention Mask,不允许 Queries 和 Text 相互看到 (相互之间的注意力值为0)。
2 基于图像的文本生成 (Image-Grounded Text Generation, ITG)
ITG 给定一张输入图片,旨在训练 Q-Former 生成对应的文本描述。
要实现这一目的,视觉编码器和文本解码器之间应该有交互。而 Q-Former 恰恰阻止了这种直接交互,因此 Queries 在这里就扮演了提取出来生成文本所需要的信息,然后通过 Self-Attention 层传递给 Text token。简而言之,Queries 应该具备这样一种能力:提取捕获了所有文本信息的视觉特征。因此,ITG 的 Attention Mask 方法如图3中间所示,属于 Multi-modal Causal Self-Attention Mask,允许 Text 看到 Queries (Queries 里面有视觉信息),同时每个 Text token 只能看到它之前的 Text token (生成式任务的基本做法)。但是不允许 Queries 看到 Text 的信息,只能看到自己的信息。此外作者还将 [CLS] token 替换为一个新的 [DEC] token 作为第一个 Text token 来指示解码任务。
3 图文匹配任务 (Image-Text Matching, ITM)
这是多模态预训练中的经典目标函数,旨在更加细粒度地对齐图像和文本的表征,使其互信息最大化。ITM 是个二分类任务,要求模型预测图像-文本对是正样本 (匹配) 还是负样本 (不匹配)。ITM 的 Attention Mask 方法如图3的最左侧所示,属于 Bi-directional Self-Attention Mask,允许 Queries 和 Text 相互看到。
Queries 的输出 ZZ 捕获了多模态信息,把每个输出的 Queries Embedding 通过一个二类线性分类器中以获得 logit,并将 logit 的输出做平均作为最终的分数。
BLIP-2 的 ITM 目标函数同样使用了 ALBEF 中的 hard negative mining 策略。
训练第2步:联合视觉编码器和大型语言模型训练
在生成预训练的阶段,作者把 Q-Former 和冻结参数的 LLM 连接起来,以利用 LLM 的文本生成能力。首先输入图片还是直接输入冻结参数的 Image Encoder,得到图像的表征。然后图像的表征和 Queries 一起送入 Q-Former,得到 Queries 的输出 ZZ ,经过一个全连接层与 Text token 的维度对齐之后输入给 LLM Decoder。这个 Queries 的输出就蕴含了视觉信息,在输入给 LLM 的时候就充当了 Soft Visual Prompt 的作用。
Queries 在经过了第1阶段的训练之后,已经学习到了如何更好地结合文本提取图片信息,因此它可以有效地将最有用的图片信息提供给 LLM,同时删除不相关的视觉信息。这减少了 LLM 学习视觉语言对齐的负担。
作者尝试了2种大型语言模型,分别是基于纯 Decoder 架构的和基于 Encoder-Decoder 架构的。对于基于纯 Decoder 架构的模型,使用语言建模目标函数进行训练。冻结参数的 LLM 的任务是根据 Q-Former 提供的视觉表征来生成文本。对于基于 Encoder-Decoder 架构的模型,把文本分成两段,前缀随着 Queries 的输出喂给 LLM 的 Encoder,希望 Decoder 输出后缀。
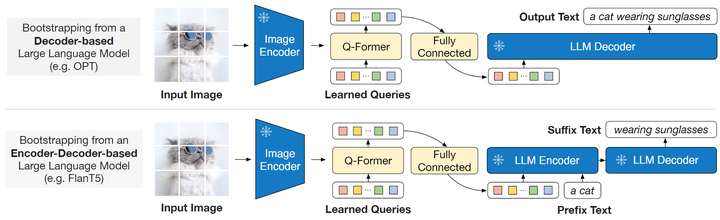
Q-Former 训练的第2步
预训练方法
预训练数据集
和 BLIP 一样使用下面6个数据集,图片数加起来大概是 129M。
- Conceptual Captions
- SBU Captions
- COCO
- Visual Genome
- 噪声更大的 Conceptual 12M 数据集 (有的数据失效了)
- 额外的 web 数据集 LAION400M 的一部分,该数据集包含 115M 图像,具有更多的噪声文本
采用了 BLIP 里面提出的 CapFilt 方法为网络图像创建合成标题。
预训练好的视觉模型和 LLM
视觉模型使用:
- CLIP[1] 训练的 ViT-L/14
- EVA-CLIP[2] 训练的 ViT-g/14
LLM 模型使用:
- OPT[3]
- FlanT5[4]
实验结果
先来看几张 Zero-shot 指令控制图文生成任务的实验结果,包括视觉知识推理、视觉常识推理、视觉对话、个性化图像到文本生成如下图所示。只需在视觉提示之后附加文本提示作为 LLM 的输入。

Zero-shot 指令控制图文生成任务的实验结果

Zero-shot 指令控制图文生成任务的实验结果
Zero-Shot 视觉语言任务
下图概述了 BLIP-2 在各种 Zero-Shot 视觉语言任务上的性能。与之前最先进的模型相比,BLIP-2 在视觉语言预训练期间实现了更好的性能,同时需要更少的可训练参数数量。
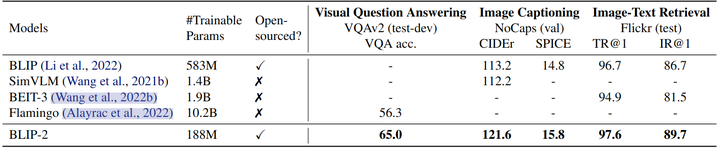
BLIP-2 在各种 Zero-Shot 视觉语言任务上的性能
Zero-shot VQA 任务
作者对 Zero-Shot VQA 任务进行了定量的评估,对于 OPT 的语言模型,Prompt 设置为 “Question: {} Answer:”。对于 FlanT5 模型,Prompt 设置为 “Question: {} Short answer:”。BLIP-2 在 VQAv2 和 GQA 数据集上取得了最先进的结果。它在可训练参数减少 54 倍的情况下,VQAv2 上的表现优于 Flamingo80B。在 OK-VQA 数据集上,BLIP-2 没打败 Flamingo80B。下图还说明了更大的视觉模型或者文本模型都有助于性能的提升。
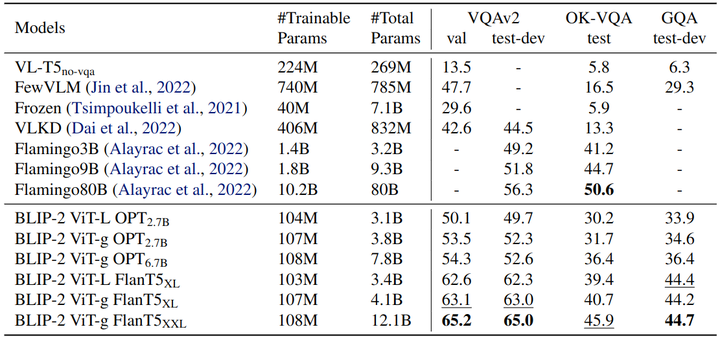
Zero-shot VQA 任务实验结果
视觉语言表征学习的影响
BLIP-2 第一阶段的表征学习预训练 Q-Former 来学习与文本相关的视觉特征,这减少了 LLM 学习视觉语言的负担。如下图所示是第一阶段的表征学习对生成学习的影响。在没有表征学习的情况下,这两种类型的 LLM 在 Zero-Shot VQA 上的性能都要低得多。而且,OPT 会有灾难性遗忘的问题,即随着训练的进行,性能会急剧下降。

视觉语言表征学习的影响
图像字幕实验结果
图像字幕任务要求模型为图像的视觉内容生成文本描述,实验结果如下图所示。作者使用提示 “a photo of” 作为 LLM 的初始输入,并使用语言建模损失函数来训练模型生成字幕。作者在微调期间保持 LLM 冻结,并将 Q-Former 的参数与图像编码器一起更新。微调数据集使用 COCO,同时在 COCO 测试集和 NoCaps 验证集上评测。BLIP-2 在 NoCaps 上比现有方法取得了显着的改进实现了最先进的性能,显示出对域外图像的强大泛化能力。
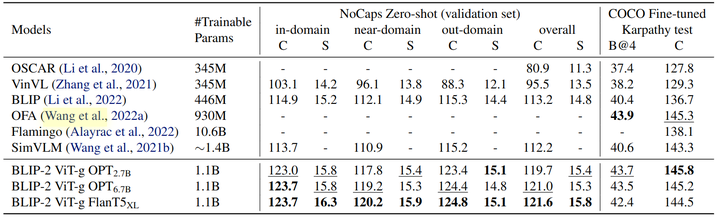
图像字幕实验结果
视觉问答实验结果
给定带注释的 VQA 数据,作者在保持 LLM 冻结的同时微调 Q-Former 和图像编码器的参数。VQA 微调的模型架构如下图所示,LLM 接收 Q-Former 的输出和问题作为输入,并希望生成答案。为了提取与问题更相关的图像特征,作者还给 Q-Former 额外输入问题,使其借助 Self-Attention 与可学习的 Queries 交互。
=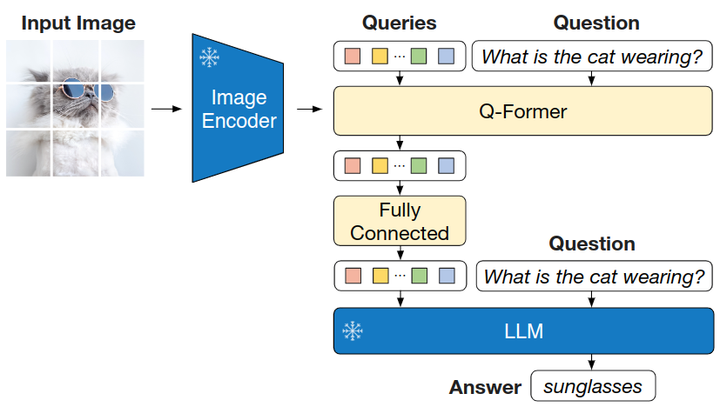
VQA 微调的模型架构
实验结果如下图所示,BLIP-2 属于开放式生成模型,并取得了最佳的性能。
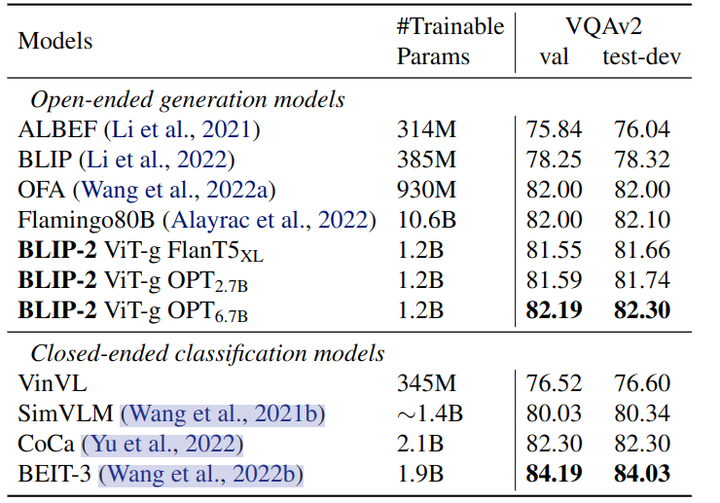
视觉问答实验结果
图文检索实验结果
图像文本检索不涉及语言生成,所以作者直接微调第1阶段预训练模型。作者使用与预训练相同的目标函数,即 ITC、ITM 和 ITG。数据集使用 COCO,微调 Q-Former 和图像编码器。评测数据使用 COCO 和 Flickr30K,任务是 image-to-text retrieval 和 text-to-image retrieval。实验结果如图所示,BLIP-2 在 Zero-Shot 的图像文本检索方面实现了最先进的性能,与现有方法相比有了显着改进。
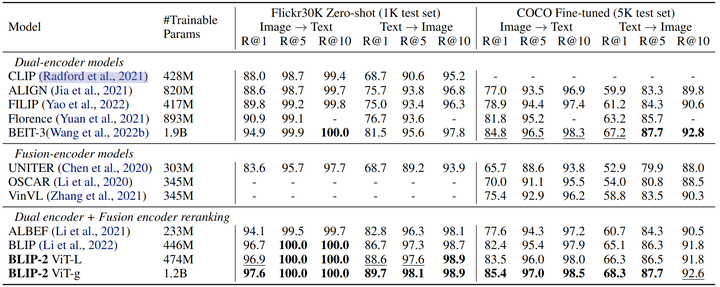
图文检索实验结果
局限性
LLM 一般具备 In-Contet Learning 的能力,但是在 In-Context VQA 的场景下,BLIP-2 没观察到好的结果。对于这种上下文学习能力的缺失,作者把原因归结为预训练数据集中的每个数据只包含一个图像-文本对,导致 LLM 无法从中学习单个序列中多个图像-文本对之间的相关性。
BLIP-2 的图文生成能力不够令人满意,可能是 LLM 知识不准确带来的。同时 BLIP-2 继承了冻结参数的 LLM 的风险,比如输出攻击性语言,传播社会偏见。解决的办法是指令微调,或者过滤掉有害的数据集。