InstructBLIP 是 BLIP 作者团队在多模态领域的又一续作。现代的大语言模型在无监督预训练之后会经过进一步的指令微调 (Instruction-Tuning) 过程,但是这种范式在视觉语言模型上面探索得还比较少。InstructBLIP 这个工作介绍了如何把指令微调的范式做在 BLIP-2 模型上面。用指令微调方法的时候会额外有一条 instruction,如何借助这个 instruction 提取更有用的视觉特征是本文的亮点之一。InstructBLIP 的架构和 BLIP-2 相似,从预训练好的 BLIP-2 模型初始化,由图像编码器、LLM 和 Q-Former 组成。在指令微调期间只训练 Q-Former,冻结图像编码器和 LLM 的参数。作者将26个数据集转化成指令微调的格式,把它们分成13个 held-in 数据集用于指令微调,和13个 held-out 数据集用于 Zero-Shot 能力的评估。
指令微调
在 NLP 领域,指令微调技术 (Instruction-Tuning) 帮助大语言模型 (Large Language Model, LLM) 推广到各种各样的任务上面。做法其实就是对预训练好的大语言模型进行有监督微调,只是这个微调的数据集中包含了很多自然语言指令,指令微调技术使得模型能够处理并遵循人类的指令。
指令微调得到的 LLM 其实已经在多模态模型里面使用了,比如 BLIP-2 就曾经借助了指令微调训练得到的 LLM 完成很多多模态任务。但是以上都是 LLM 领域的指令微调,只被证明了在 NLP 领域的泛化性能不错,对于视觉-语言任务的泛化性还没有得到验证。因此,本文提出的 InstructBLIP 就是研究如何在视觉语言任务上进行指令微调,使得训练出的模型可以解决一系列的视觉任务。
数据集构造
为了确保指令微调数据的多样性,作者收集了来自11种不同任务的26个数据集,并将它们转换为指令调优格式,如下图所示。
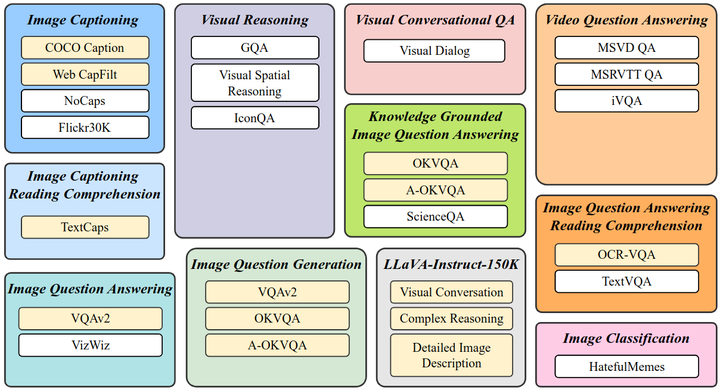
指令微调数据集,黄色表示 held-in data,白色表示 held-out data
对于每个任务,作者精心制作了10-15个自然语言指令模板,如下图所示。这些模板阐明了任务并描述了目标。对于一些偏爱简短响应的数据集,作者刻意地在 instruction 中添加了 “short answer”, “as short as possible” 字样来减小模型过拟合的风险,防止其始终生成很短的输出。
训练和测试流程
作者收集了来自11种不同任务的26个数据集,把它们分成13个 held-in 数据集用于指令微调,和13个 held-out 数据集用于 Zero-Shot 能力的评估。held-in 数据集的训练集用于训练,其他像验证集和测试集用于 held-in 的评估;held-out 数据集全部用来进行 held-out 的评估。
held-out 数据集有两种类型:1) 这些数据在训练期间没有被模型看过,但是同类型的任务有被模型学过。2) 这些数据不仅在训练期间没有被模型看过,而且同类型的任务也没被模型学过,符合这条的有4个任务:Visual Reasoning, Video Question Answering, Visual Conversational QA, 和 Image Classification,可以看到图1中它们的数据集都是白色的 held-out data,而且没有黄色的 held-in data。
在训练期间,把所有的 held-in 数据集的训练集混合之后,并在不同任务中均匀采样 instruction templates,使用语言建模损失函数训练模型:给模型输入图片和 instruction templates,希望它输出回答。
由于训练数据集数量太大, 而且每个数据集的大小存在显着差异, 均匀混合它们可能会导致模型过拟合较小的数据集, 并欠拟合更大的数据集。因此, 作者改了一下采样数据的概率, 从某个数据集里面采样数据的概率是: , 其中 代表每个数据集大小。
模型架构和训练策略
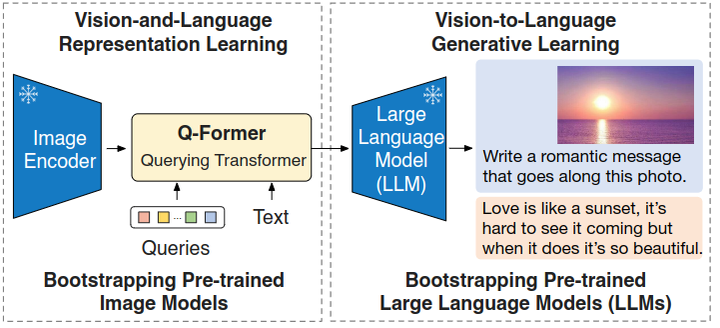
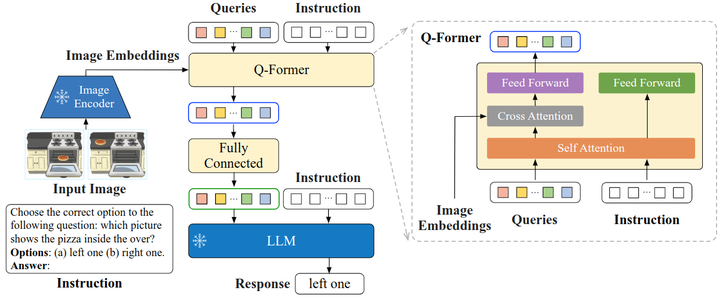
如下图所示是 InstructBLIP 的模型架构,和 BLIP-2 保持一致,依然由视觉编码器,Q-Former 和 LLM 组成。视觉编码器提取输入图片的特征,并喂入 Q-Former 中。此外,Q-Former 的输入还包括可学习的 Queries (BLIP-2 的做法) 和 Instruction。Q-Former 的内部结构如图3黄色部分所示,其中可学习的 Queries 通过 Self-Attention 和 Instruction 交互,可学习的 Queries 通过 Cross-Attention 和输入图片的特征交互,鼓励提取与任务相关的图像特征。
Q-Former 的输出通过一个 FC 层送入 LLM,Q-Former 的预训练过程遵循 BLIP-2 的两步:1) 不用 LLM,固定视觉编码器的参数预训练 Q-Former 的参数,训练目标是视觉语言建模。2) 固定 LLM 的参数,训练 Q-Former 的参数,训练目标是文本生成。
在推理的时候,对于大部分数据集,如 image captioning,open-ended VQA 等,InstructBLIP 可以直接使用 LLM 生成的文本作为输出;对于 classification 和 multi-choice VQA 这样的任务,InstructBLIP 遵循 ALBEF 的做法生成固定的几种答案,根据概率选择最后的结果作为输出。这种做法的数据集包括有 ScienceQA、IconQA、A-OKVQA (多项选择)、HatefulMemes、Visual Dialog、MSVD 和 MSRVTT 数据集。
InstructBLIP 的 LLM 作者使用了 FlanT5-XL (3B), FlanT5-XXL (11B), Vicuna-7B 和 Vicuna-13B 这四种,视觉编码器使用的是 ViT-g/14。FlanT5[1] 是一个基于 Encoder-Decoder Transformer T5 的指令微调模型,Vicuna[2] 是一个基于 Decoder LLaMa 的微调模型。
在视觉语言 Instruction tuning 的过程中,初始化的权重是 BLIP-2 的权重,只微调 Q-Former 的参数,同时保持图像编码器和 LLM 冻结。由于原始的 BLIP-2 模型不包括 Vicuna 的检查点,作者使用与 BLIP-2 相同的策略 来预训练 Vicuna。
InstructBLIP 一共微调 60K steps,3B, 7B, 11/13B 模型的 Batch Size 分别是 192,128,64,优化器使用 AdamW,weight decay 设为 0.05,在前 1000 steps 使用线性的学习率 warm-up,从 10^{-8}10^{-8} 到 10^{-5}10^{-5} ,随后余弦衰减到0,使用 16 A100 GPU 训练 1.5 天。
实验结果
Zero-Shot 推理的指令使用下面的模板:
GQA, VizWiz, iVQA, MSVD, MSRVTT
Question: {} Short answer:
NoCaps, Flickr30kA short image description:
TextVQAOCR tokens: {}. Question: {} Short answer:
IconQAQuestion: {} Options: {}. Short answer:
ScienceQAContext: {} Question: {} Options: {}. Answer:HatefulMemes This is an image with: “{}” written on it. Is it hateful? Answer:
VSRBased on the image, is this statement true or false? “{}” Answer:
Visual DialogDialog history: {}\n Question: {} Short answer:
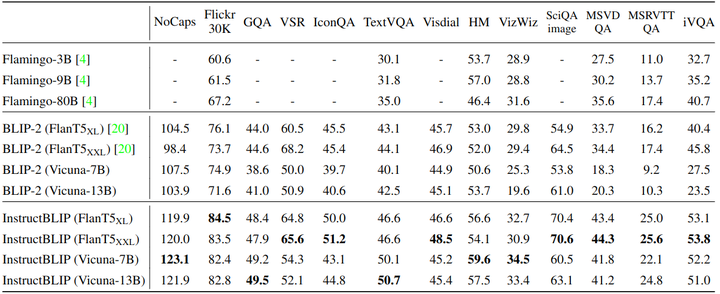
Zero-Shot 实验结果如图所示。InstructBLIP 在所有数据集上都超过了 BLIP-2 和 Flamingo,比如 InstructBLIP FlanT5XL 相比于 BLIP-2 FlanT5XL 取得了 15.0% 的相对提升。只有 4B 参数的最小的 InstructBLIP FlanT5XL 模型在6个公共数据集上的性能超过了 Flamingo-80B 24.8%。
定性评估结果
如下图所示是 InstructBLIP 的定性评估结果。InstructBLIP 展示了它对复杂视觉推理的能力。例如,它可以合理地从视觉场景中推断出可能发生的灾难类型,并从场景的位置推断出灾难类型。此外,InstructBLIP 还能够生成一些有信息量的回答,比如描述一幅名画。InstructBLIP 还可以参与多轮对话,在做出新响应时有效地考虑对话历史。

而且,如下图所示,InstructBLIP 生成的回复更加准确到位,可以通过自适应调整响应长度来直接解决用户意图,不像其他几个模型 LLaVa 等容易生成一些很长但不太相关的,冗长的话,有很重的语言模型的痕迹。

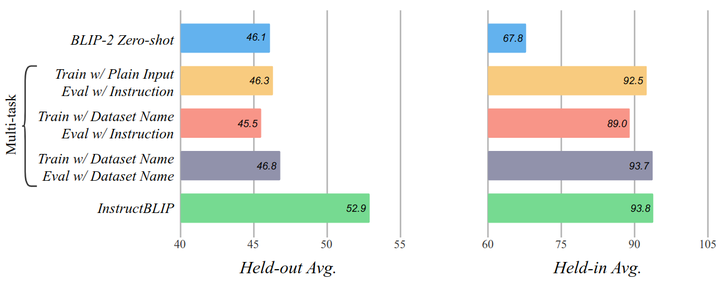
指令微调 vs. 多任务学习
指令微调和多任务学习有点类似,为了确定指令微调技术对模型性能的提升到底帮助有多大,作者还将其与多任务学习进行对比,结果如下图所示。一种多任务学习的做法是使用原始的输入 (不包含 Instruction),然后在有 Instruction 的情况下做评估;一种多任务学习的做法是在训练的时候加一个前缀 [Task:Dataset] ,比如对于 VQAv2 数据集添加 [Visual question answering:VQAv2]。结果显示都不如直接做 Instruction Tuning。