预训练的语言模型在这俩年取得了巨大的突破,但是如何比较各预训练模型的优劣显然是一个很有挑战的问题,主要是太烧钱了。本文研究了一些预训练参数和训练批大小对BERT模型的影响。发现,BERT远远没有被充分训练,用不同的预训练参数,都会对最后的结果产生不同的影响,并且最好的模型达到了SOTA。
介绍
预训练模型,例如 ELMo、GPT、BERT、XLM、XLNet 已经取得了重要进展,但要确定方法的哪些方面贡献最大是存在挑战的。训练在计算上是昂贵的,很难去做大量的实验,并且预训练过程中使用的数据量也不一致。
本文对 BERT 预训练过程进行了大量重复实验研究,其中包括对超参数调整效果和训练集大小的仔细评估。 发现 BERT 的训练不足,并提出了一种改进的方法来训练BERT模型(称之为RoBERTa),该模型可以匹敌或超过所有后 BERT 方法的性能。模型的修改很简单,它们包括:
- 训练模型更大,具有更大的训练批次,更多的数据
- 删除下一句预测的目标
- 对更长的序列进行训练
- 动态改变应用于训练数据的masking形式
总的来说,本文贡献如下
- 提出了一组重要的 BERT 设计选择和训练策略,并介绍了可带来更好下游任务性能的替代方案。
- 使用新提出的数据集 CCNews,并确认使用更多数据进行预训练可以进一步提高下游任务的性能
- 训练改进表明,在正确的设计选择下,MLM预训练与最近发布的所有其他方法具有竞争力。
训练过程分析
静态和动态mask
BERT中是准备训练数据时,每个样本只会进行一次随机mask(因此每个epoch都是重复),后续的每个训练步都采用相同的mask,这叫静态mask。而Roberta在预处理的时候将数据集生成 10 份,每次生成采用不同的 mask(总共40 epochs,所以每一个mask对应的数据被训练4个epoch)。这等价于原始的数据集采用10种静态 mask 来训练 40个 epoch。不同模式的实验效果如下表所示:
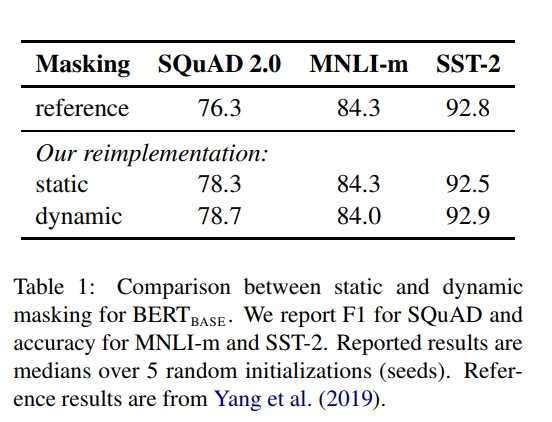
从结果来看,动态masking形式训练的BERT整体上优于或者接近静态maskin形式训练的BERT。
去掉下一句预测(NSP)任务
原始的BERT包含2个任务,预测被mask掉的单词和下一句预测。最近一些论文的研究(Lample and Conneau,2019; Yang et al., 2019; Joshi et al., 2019)可以发现下一句预测(NSP)任务似乎没那么必要,本文设计了以下4种训练方式:
SEGMENT-PAIR + NSP
输入包含两部分,每个部分是来自同一文档或者不同文档的 segment (segment 是连续的多个句子),这两个segment 的token总数少于 512 。预训练包含 MLM 任务和 NSP 任务。这是原始 BERT 的做法。
SENTENCE-PAIR + NSP
输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的token 总数少于 512 。由于这些输入明显少于512 个tokens,因此增加batch size的大小,以使 tokens 总数保持与SEGMENT-PAIR + NSP 相似。预训练包含 MLM 任务和 NSP 任务。
FULL-SENTENCES
输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token 总数不超过 512 。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界token 。预训练不包含 NSP 任务。
DOC-SENTENCES
输入只有一部分(而不是两部分),输入的构造类似于FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token 总数不超过 512 。在文档末尾附近采样的输入可以短于 512个tokens, 因此在这些情况下动态增加batch size大小以达到与 FULL-SENTENCES 相同的tokens总数。预训练不包含 NSP 任务。
4中训练形式结果如下:
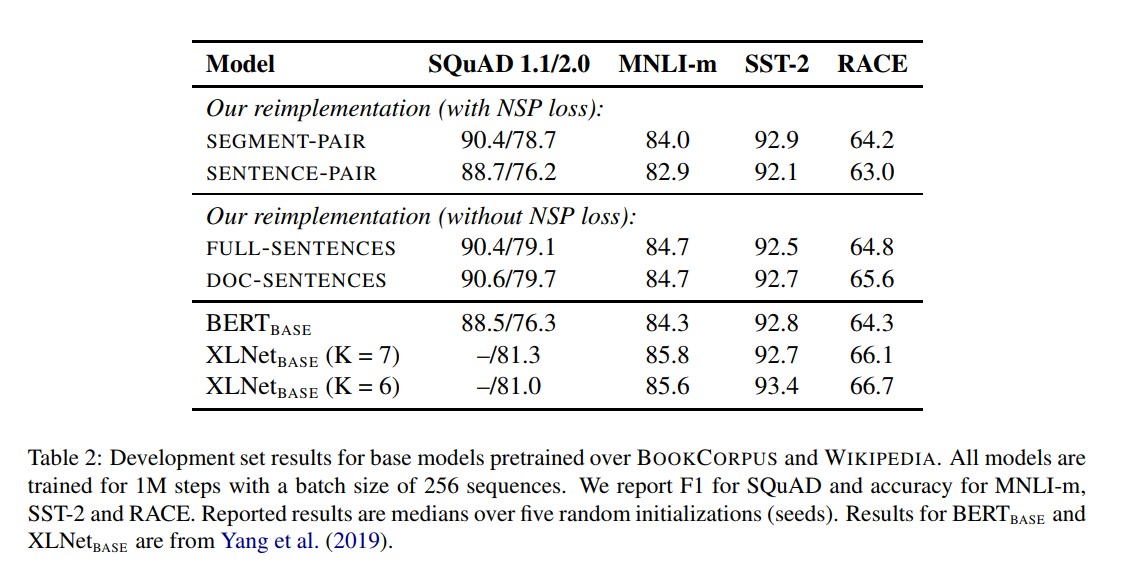
BERT采用的是SEGMENT-PAIR(可包含多句话)的输入格式,从实验结果来看,如果在采用NSP loss的情况下,SEGMENT-PAIR 是优于SENTENCE-PAIR(两句话)的。发现单个句子会损害下游任务的性能,可能是如此模型无法学习远程依赖。接下来对比的是,将无NSP损失的训练与来自单个文档(doc-sentence)的文本块的训练进行比较。可以发现,与Devlin等人(2019)相比,该设置的性能优于最初发布的BERT-base结果:去掉NSP损失在下游任务的性能上能够与原始BERT持平或略微升高。可能的原因:原始 BERT 实现采用仅仅是去掉NSP的损失项,但是仍然保持 SEGMENT-PARI的输入形式。
最后,实验还发现将序列限制为来自单个文档(doc-sentence)的性能略好于序列来自多个文档(FULL-SENTENCES)。但是 DOC-SENTENCES 策略中,位于文档末尾的样本可能小于 512 个 token。为了保证每个 batch 的 token 总数维持在一个较高水平,需要动态调整 batch-size 。出于处理方便,后面采用DOC-SENTENCES输入格式。
大的batches
以往的神经机器翻译研究表明,采用非常大的mini-batches进行训练时候,搭配适当提高学习率既可以提高优化速度,又可以提高最终任务性能。最近的研究表明,BERT也可以接受 large batch训练。Devlin等人(2019)最初训练BERT-base只有100万步,batch size为256个序列。通过梯度累积,训练batch size=2K序列的125K步,或batch size=8K的31K步,这两者在计算成本上大约是是等价的。
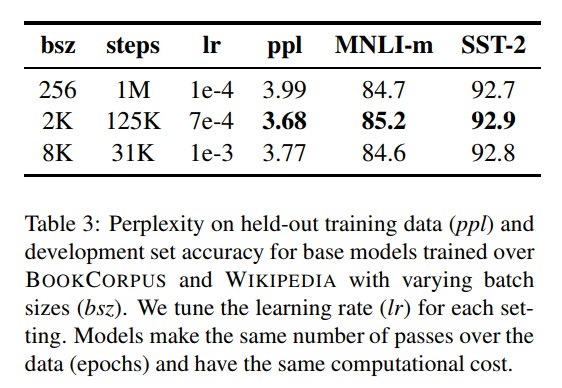
上图比较了BERT-baseE在增大 batch size时的perplexity(困惑度,语言模型的一个指标)和最终任务性能。可以看到,large batches训练提高了masked language modeling 目标的困惑度,以及最终任务的准确性。large batches也更容易分布式数据并行训练, 在后续实验中,文本使用bacth size=8K进行并行训练。
Text Encoding
字节对编码(BPE)(Sennrich et al.,2016)是字符级和单词级表示的混合,该编码方案可以处理自然语言语料库中常见的大量词汇。BPE不依赖于完整的单词,而是依赖于子词(sub-word)单元,这些子词单元是通过对训练语料库进行统计分析而提取的,其词表大小通常在 1万到 10万之间。当对海量多样语料建模时,unicode characters占据了该词表的大部分。Radford et al.(2019)的工作中介绍了一个简单但高效的BPE, 该BPE使用字节对而非unicode characters作为子词单元。总结下两种BPE实现方式:
-
基于 char-level :原始 BERT 的方式,它通过对输入文本进行启发式的词干化之后处理得到。
-
基于 bytes-level:与 char-level 的区别在于bytes-level 使用 bytes 而不是 unicode 字符作为sub-word 的基本单位,因此可以编码任何输入文本而不会引入 UNKOWN 标记。
当采用 bytes-level 的 BPE 之后,词表大小从3万(原始 BERT 的 char-level )增加到5万。这分别为 BERT-base和 BERT-large增加了1500万和2000万额外的参数。
之前有研究表明,这样的做法在有些下游任务上会导致轻微的性能下降。但是本文作者相信:这种统一编码的优势会超过性能的轻微下降。且作者在未来工作中将进一步对比不同的encoding方案。
实验结果
RoBERTa使用dynamic masking,FULL-SENTENCES without NSP loss,larger mini-batches和larger byte-level BPE(这个文本编码方法GPT-2也用过,BERT之前用的是character粒度的)进行训练。除此之外还包括一些细节,包括:更大的预训练数据、更多的训练步数。
为了将这些因素与其他建模选择(例如,预训练目标)的重要性区分开来,首先按照BERT-Large架构(L=24,H=1024,A=16355m)对RoBERTa进行训练。正如在Devlin et al.中使用的一样,本文用BOOKCORPUS和WIKIPEDIA数据集进行了100K步预训练。我们使用1024块V100 GPU对模型进行了大约一天的预训练。
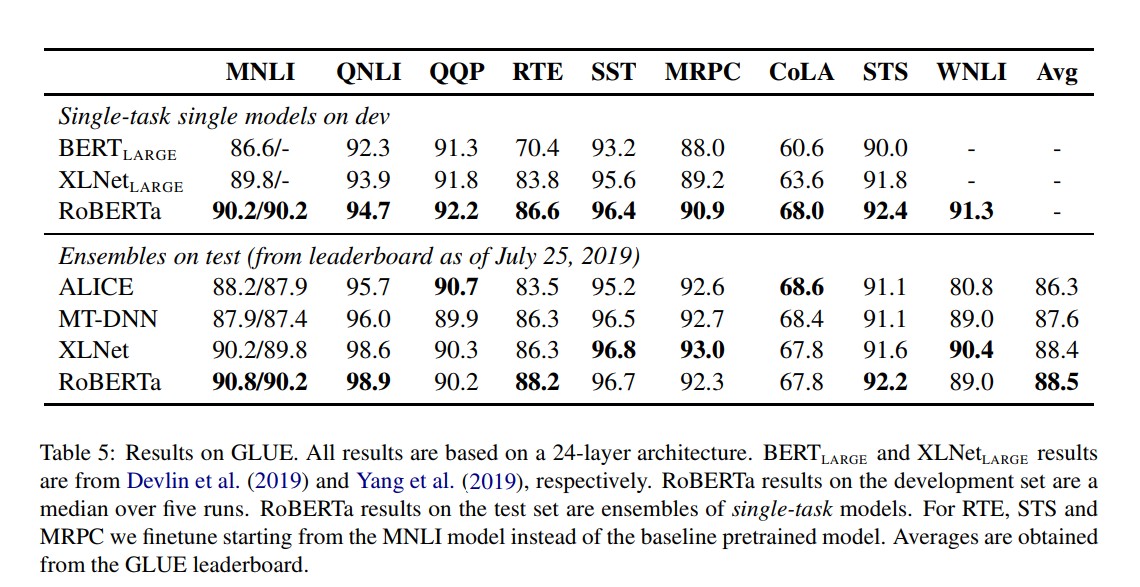
总结
在预训练BERT模型时,本文仔细评估一些设计决策。发现通过更长时间地训练模型,处理更多数据,可以显著提高模型性能;删除下一句预测目标(NSP); 在更长的序列上训练;并动态地改变应用于训练数据的遮蔽模式。上述预训练改进方案,即为本文所提出的RoBERTa,该方案在GLUE,RACE和SQuAD上实现了目前最好的结果。备注:在GLUE上没有进行多任务微调,在SQuAD上没有使用附加数据。这些结果说明这些先前被忽视的设计决策的重要性,并表明BERT的预训练目标与最近提出的替代方案相比仍然具有竞争性。