为什么Text-to-SQL技术始终"差临门一脚"?
想象一下这个场景:你是一位市场分析师,老板走过来说:"帮我查一下上个季度华东地区销售额超过100万的客户,按成交金额倒序排列。"如果你懂SQL,可能几分钟就搞定了。但如果你不懂呢?
这正是"Text-to-SQL"技术想解决的问题——让普通人用自然语言就能和数据库对话,就像跟Siri聊天一样简单。
过去几年,这个领域的学术论文如雨后春笋般涌现。DIN-SQL、CHESS、MAC-SQL……一个个方法在学术评测榜单上你追我赶,准确率不断刷新。但奇怪的是,当企业真的想把这些"学术明星"部署到实际系统中时,却常常遭遇水土不服。
问题出在哪儿?来自中国人民大学、对外经贸大学和浙江工业大学的研究团队,最近发布了一个名为Squrve的框架,不仅指出了症结所在,还提供了一个极具实用价值的解决方案。
学术研究的"碎片化困境"
让我们先理解问题的根源。
学术界喜欢"专精"——每篇论文往往聚焦于Text-to-SQL流程中的某一个环节。比如:
- 有人专攻**“schema linking”**(在庞大的数据库表结构中,精准找到查询相关的表和字段)
- 有人研究**“decoding strategy”**(如何让模型生成多样化的SQL候选,从中选出最优解)
- 还有人致力于**“data augmentation”**(通过合成数据提升模型泛化能力)
这些研究本身都很有价值,但带来了一个尴尬的副作用:每个方法都自成体系,有自己独特的数据格式、输入输出接口和依赖环境。
就像你有一套乐高积木、一套万代模型、一套七巧板,每套玩具单独玩都很有趣,但你却没法把它们拼在一起搭出一个更复杂的建筑——因为接口根本对不上。
论文作者把这称为"缺乏统一的集成机制"(lack of unified integration mechanism)。这是第一个挑战。
真实世界的"多重Boss战"
第二个挑战更加致命:真实世界的查询,往往同时包含多个难点。
举个例子:一个跨国零售企业的数据分析师可能会问:“在过去三个月内,哪些北美地区的店铺,其VIP客户复购率超过平均值?”
这个看似简单的问题,实际上同时涉及:
- 多表关联推理(店铺表、客户表、订单表需要联合查询)
- 时间范围过滤(“过去三个月”)
- 聚合计算(计算"复购率"和"平均值")
- 领域知识理解(什么是"VIP客户"?这可能在数据库schema的注释里,也可能需要外部文档定义)
没有任何单一模型能完美应对所有这些挑战。这就像打游戏时同时遇到了火龙、冰巨人和毒蛇——你需要不同的武器和策略组合才能通关。
但现有的Text-to-SQL系统,大多是"单兵作战"模式。即使某个模型在某个单项能力上很强(比如schema linking做得很好),它在其他方面(比如复杂逻辑推理)可能就力不从心。而且,你很难把两个不同模型的优势"合并"起来——因为它们的接口不兼容(还是那个乐高和七巧板的问题)。
Squrve的"搭积木"哲学
Squrve框架的核心思路,可以用一个词概括:模块化协作。
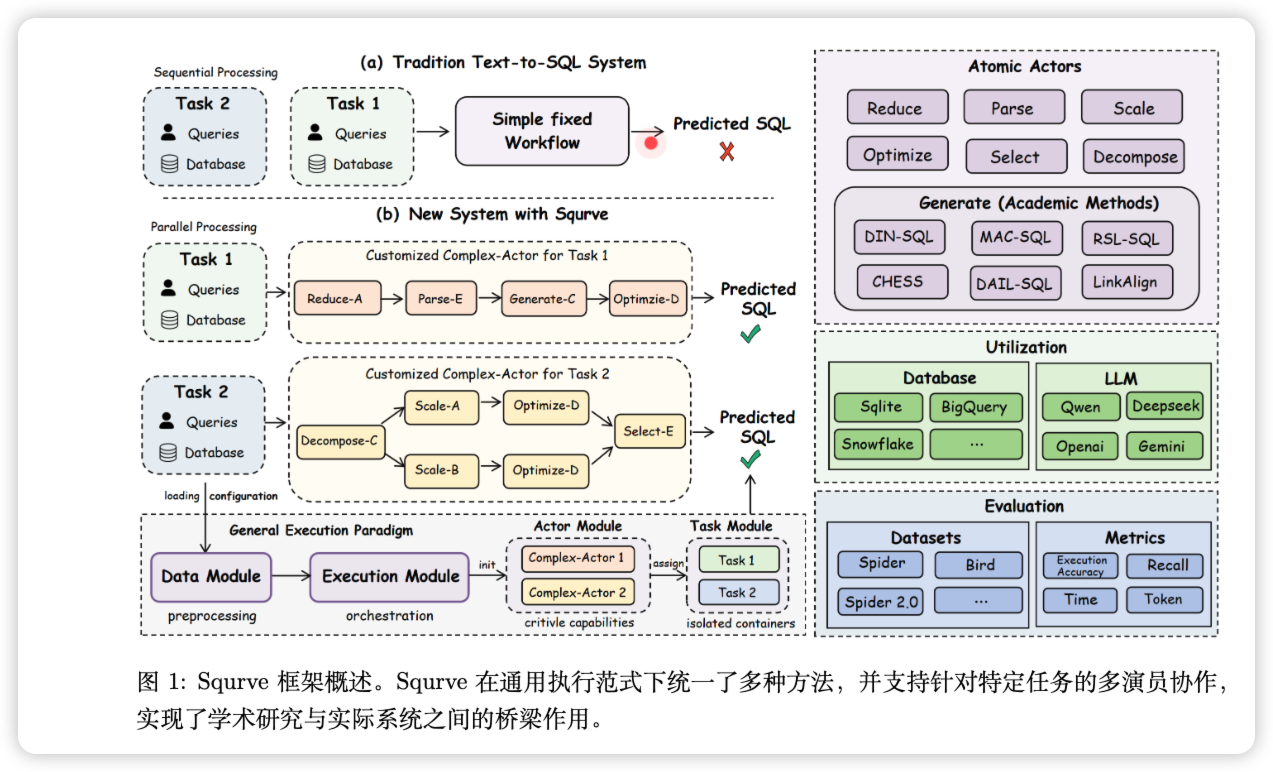
第一步:建立"通用语言"
就像联合国需要同声传译才能让各国代表无障碍交流,Squrve首先做的事情是:为所有Text-to-SQL方法建立一套统一的"执行范式"(universal execution paradigm)。
具体来说,它把整个Text-to-SQL流程标准化为几个模块:
- 数据模块(Data Module):把不同数据集的格式(Spider、BIRD、用户自定义数据库等)统一成标准结构
- 任务模块(Task Module):提供隔离的运行环境,让不同任务可以并发执行
- 执行模块(Execution Module):统一协调整个工作流,从初始化到最终评估
这就像给所有积木都装上了标准化的卡扣接口——现在不管你是哪个品牌的积木,都能互相拼接了。
第二步:拆解"原子能力"
Squrve做的第二件事,是把Text-to-SQL任务拆解成七种"原子Actor"(atomic actors),每一种代表一个经过学术界验证的核心能力:
- Reduce Actor:从庞大的数据库schema中剔除无关部分,只保留相关的表和字段(解决"信息过载")
- Parse Actor:精准定位查询需要的表和列(schema linking的核心)
- Generate Actor:生成完整的SQL语句(封装现有的端到端方法)
- Decompose Actor:把复杂查询拆解成多个子问题,逐步求解(模拟"思维链"推理)
- Scale Actor:生成多个高质量的SQL候选(提升覆盖率)
- Optimize Actor:根据数据库的执行反馈(如报错信息)修正SQL(自我纠错)
- Select Actor:从多个候选中挑选最优的SQL(集成学习)
这些Actor就像乐高的"基础砖块"——单独使用时各有功能,但真正的魔法在于它们的组合。
第三步:编排"多角色协作"
Squrve提供了两种组合策略:
- Pipeline(流水线):把多个Actor串联起来,前一个的输出作为后一个的输入(比如先Reduce精简schema,再Parse提取关键字段,最后Generate生成SQL)
- Tree(树形):把输入同时分发给多个Actor并行处理,然后合并结果(比如同时用三个不同的Generator生成SQL候选,再用Selector选出最优解)
更妙的是,这两种策略可以递归嵌套——你可以把一个Pipeline包装成一个"复合Actor",然后再把它和其他Actor组成更大的Tree结构。
就像搭乐高城堡:你先用小砖块搭出一个塔楼(Pipeline),再用小砖块搭出一个城墙(Pipeline),最后把塔楼、城墙、护城河组合成完整的城堡(Tree)。
实验结果:1+1 > 2的协作效应
论文在Spider和BIRD两个权威Text-to-SQL评测集上做了实验。结果令人振奋:
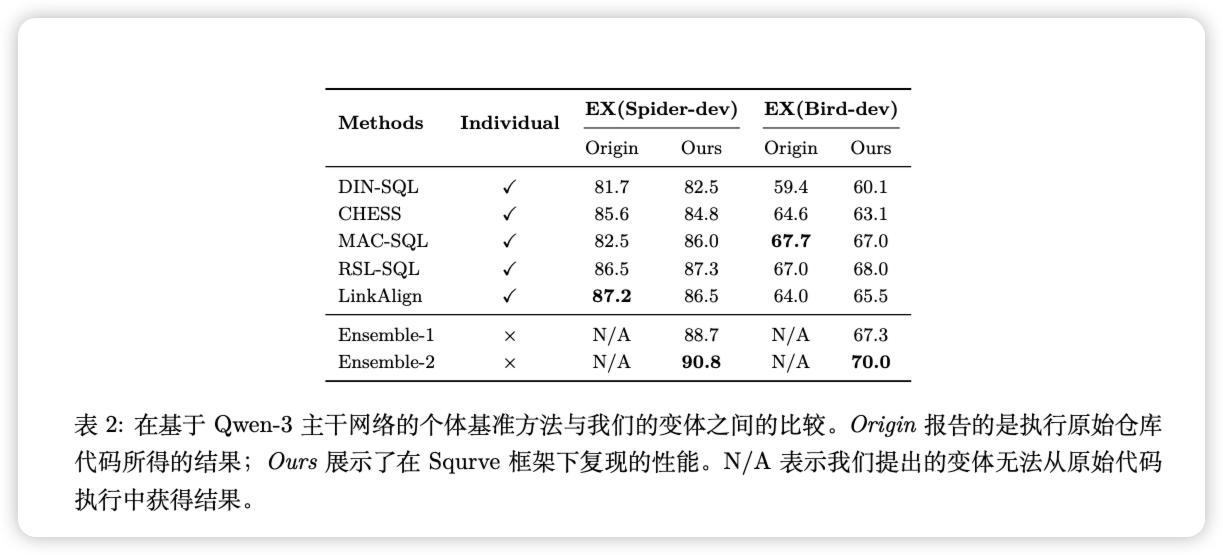
单一方法的复现表现: Squrve首先忠实地复现了五个经典方法(DIN-SQL、CHESS、MAC-SQL、RSL-SQL、LinkAlign),性能与原论文报告的结果持平甚至略有超越。这证明了框架本身没有引入性能损耗。
组合方法的突破:
- Ensemble-1(LinkAlign解析器 + RSL-SQL扩展器 + CHESS选择器 + MAC-SQL优化器)在Spider-dev上达到88.7%准确率,比最强单一方法高出1.5%
- Ensemble-2(RSL-SQL双向解析器 + MAC-SQL分解器 + CHESS扩展器 + CHESS选择器 + LinkAlign优化器)更是达到90.8%(Spider)和70.0%(BIRD),分别比最强单一方法提升了4.0%和2.9%
这个提升看似不大,但要知道在Text-to-SQL这种成熟任务上,每提升1个百分点都需要巨大的技术创新。而Squrve通过"协作"而非"发明新算法",就达到了这样的效果。
更有意思的发现:在schema linking环节,并行组合两个Actor(比如LinkAlign + RSL-SQL)的召回率,远超任何单一方法。但当你组合三个或更多Actor时,收益开始递减,还会增加计算开销。这个"边际效应递减"的发现,为实践者提供了重要的设计指引。
这对行业意味着什么?
Squrve的价值,远不止于"又刷了几个点的榜单"。它真正的意义在于:
1. 降低了技术集成门槛 以前,如果你想在生产系统中尝试最新的学术方法,可能需要花几周时间研究论文代码、解决依赖冲突、统一数据格式。现在,通过Squrve的标准化接口,切换方法可能只需要改几行配置(论文附录展示的代码示例,简洁得令人惊讶)。
2. 让"能力组合"成为可能 就像手机从"单摄"进化到"多摄"(广角+长焦+微距),Text-to-SQL系统也可以通过组合不同专精能力的Actor,应对更复杂的真实场景。Squrve提供的不是"更强的单一模型",而是"让不同模型协同工作的基础设施"。
3. 加速研究迭代 对研究者来说,Squrve提供了一个"开箱即用"的实验平台。你可以快速测试自己的新方法,也可以轻松地和多个baseline对比。更重要的是,你的工作能更容易地被其他研究者集成和复用——这将大大加速整个领域的进步。
未来的可能性
当然,Squrve也不是银弹。论文的局限性在于:
- 目前集成的方法主要基于开源模型(Qwen-3等),尚未深度集成GPT-4、Claude这类闭源模型
- 多Actor协作虽然提升了准确率,但也增加了计算成本和延迟(这在生产环境中是需要权衡的)
- 框架本身的易用性还有提升空间(团队表示未来会进一步优化配置系统)
但这些都不妨碍Squrve成为一个里程碑式的工作。它做的事情,就像当年Docker对软件部署、Hugging Face对NLP模型的贡献——不是发明新技术,而是让现有技术更容易被使用和组合。
从更宏观的角度看,Squrve代表了AI应用工程化的一个重要方向:当单一模型的性能趋于饱和时,"协作"和"编排"可能是下一个突破口。就像人类社会中,团队协作往往比个人英雄主义更高效。
如果你是:
- 企业开发者,Squrve可能是你把Text-to-SQL技术落地的最快路径
- 研究者,这个框架能让你更专注于创新本身,而非重复造轮子
- 技术爱好者,这篇论文展示了"好的软件架构"如何放大学术研究的价值
最后,附上项目的GitHub地址:https://github.com/Satissss/Squrve —— 如果你对Text-to-SQL感兴趣,不妨去玩玩看。也许下一个刷榜的ensemble组合,就是你发现的。