这篇来自伊利诺伊大学香槟分校(UIUC)顶级数据与自然语言处理实验室的论文,《TEXT2DB: Integration-Aware Information Extraction with Large Language Model Agents》,表面上看是在谈论一个技术问题,但实际上,它揭示了我们在与AI协作时一个长期被忽视却至关重要的瓶颈。
现在,让我们一起为这篇“硬核”的学术论文,搭建一座通往大众理解的“阶梯”。
AI不仅要会“读书”,更要会“归档”:一项研究正在教会AI如何成为你真正的数据库助理
想象一下,你刚雇佣了一位绝顶聪明的实习生。他阅读速度惊人,过目不忘,你让他去阅读成堆的行业报告、新闻稿和客户邮件,他总能精准地抓取出所有关键信息——新产品的发布日期、竞争对手的最新动态、重要人物的履历……
然而,当你让他把这些信息更新到公司的数据库里时,灾难发生了。他直接把一堆杂乱无章的笔记丢了过来:有的日期是“2025年11月2日”,有的则是“Nov. 2, 2025”;他把“CEO”的名字放进了“联系人”一栏;更糟糕的是,他为一个已经存在的客户创建了一条全新的记录,导致数据完全重复。
这位实习生才华横溢,但他不懂**“规矩”**——数据库的规矩。
这个场景,精准地描绘了当前人工智能(AI)在信息处理上面临的一个巨大挑战。我们惊叹于大型语言模型(LLM)强大的阅读理解和信息提取(IE)能力,但我们很少问一个更关键的问题:提取出来的信息,然后呢?
来自UIUC的一组顶尖研究者,正是数据挖掘和自然语言处理领域的“老兵”,他们早已意识到,将信息从非结构化的文本中“拿出来”只是第一步。真正让这些信息产生价值的,是如何精准、合规地“放进去”——放进那个支撑着我们整个商业世界、井然有序的结构化数据库里。
他们将这个挑战定义为一个全新的任务:TEXT2DB。这不仅仅是一个技术术语,它代表着一个更宏大的目标:我们能教会AI,让它从一个只会“阅读和摘抄”的书童,进化成一个懂得“整理和归档”的数据库管理员吗?
“我知道”和“我能存”之间,隔着一道鸿沟
论文提到的三大挑战:
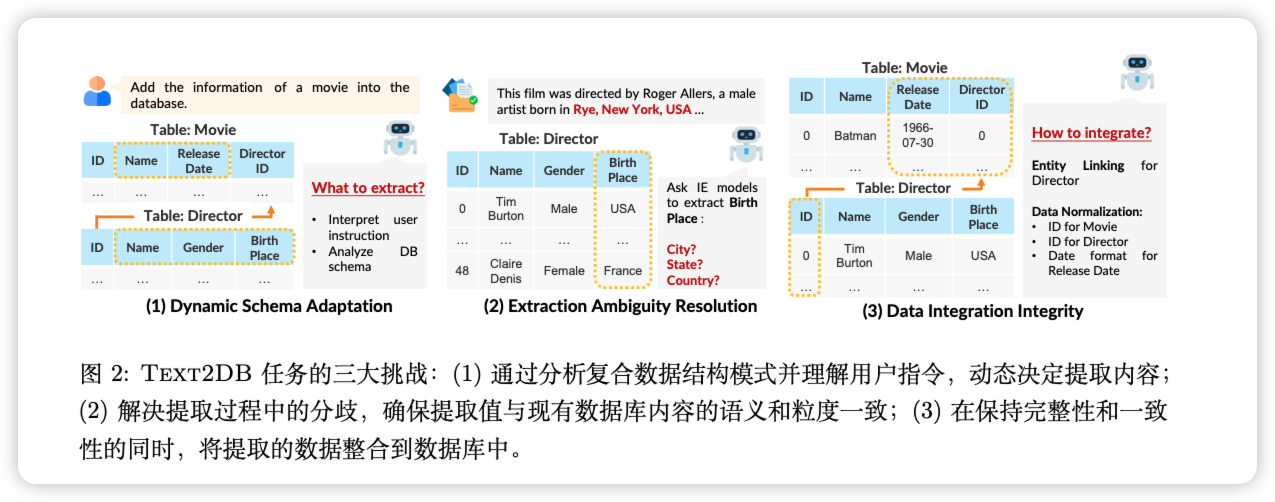
让我们来看一个论文中简单却经典的例子。
用户指令: “把这部新电影的信息加到数据库里。”
文本资料: “《狮子王》是一部由华特迪士尼制作的动画电影,导演是罗杰·艾勒斯,他是一位出生于美国纽约州的男性艺术家……”
对今天的大模型来说,从这段话里提取出“电影名:狮子王”、“导演:罗杰·艾勒斯”等信息,简直易如反掌。
但如果你的数据库长这样呢?
- 表1:电影 (Movie)
- 字段:电影ID, 电影名, 上映日期, 导演ID
- 表2:导演 (Director)
- 字段:导演ID, 姓名, 性别, 出生地
看到问题了吗?AI提取出的“罗杰·艾勒斯”是一个名字,但“电影”表需要的是一个**“导演ID”**。这意味着,AI必须先去“导演”表里检查一下“罗杰·艾勒斯”是否存在。如果不存在,就要先在“导演”表里为他创建一个新条目,获取一个新生成的“导演ID”(比如49),然后再回到“电影”表,将电影《狮子王》和这个ID(49)关联起来。
这还没完。文本里的“美国纽约州”该如何填进“出生地”?数据库里已有的数据是只写国家(“USA”),还是州(“New York”),还是城市(“Rye”)?如果格式不统一,未来的数据分析将是一场噩梦。
这个过程,充满了对数据库内在逻辑、格式规范和数据依赖的理解。它要求的不是“提取”,而是**“整合”**。而这,恰恰是通用大模型能力的盲区。
OPAL:一个由“侦察兵、规划师、质检员”组成的AI工作流
整体技术架构如下图:
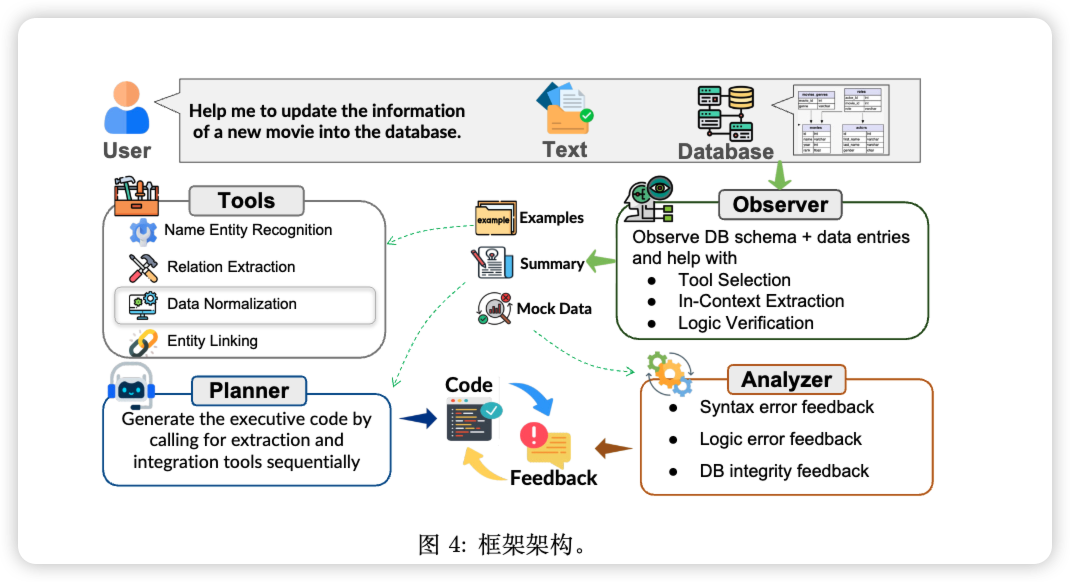
为了跨越这道鸿沟,UIUC的研究团队没有试图去训练一个更大、更强的单一模型,而是设计了一套名为 OPAL (Observe-Plan-Analyze LLM) 的智能体框架。你可以把它理解为一个高效的“AI数据处理团队”,团队里有三个核心角色:
-
侦察兵 (Observer): 在动手之前,它会先对目标数据库进行一次全面的“侦察”。它会仔细研究数据库的“地图”——也就是表的结构、有哪些字段、字段是什么类型(是文本还是数字?)、字段之间有什么关联(比如电影表的“导演ID”必须对应导演表里的一个真实ID)。它还会查看已有的数据,摸清“惯例”,比如日期格式是不是“年-月-日”,地名是写到城市还是国家。“侦察兵”的工作,就是彻底搞懂数据库的“规矩”。
-
规划师 (Planner): 在接收到用户指令和“侦察兵”的情报后,“规划师”开始制定一份详细的行动计划。这份计划不是模糊的指令,而是一步步清晰的、可执行的代码。比如,它会规划:
- 第一步:从文本中提取电影名和导演名。
- 第二步:调用“数据标准化”工具,把提取出的日期统一成“YYYY-MM-DD”格式。
- 第三步:去“导演”表里为“罗杰·艾勒斯”创建记录,并获取他的新ID。
- 第四步:最后,在“电影”表里创建《狮子王》的记录,并填入刚刚获得的导演ID。 “规划师”的核心任务,是将模糊的用户意图,转化为严谨的操作蓝图。
-
质检员 (Analyzer): 这是OPAL框架的点睛之笔。在“规划师”制定的代码计划付诸实施之前,“质检员”会对其进行严格的审查。它会检查代码有没有语法错误,逻辑上有没有硬伤(比如,是不是忘了处理导演不存在的情况?),以及最终结果是否会违反数据库的完整性约束(比如,试图插入一个重复的主键)。
如果发现问题,“质检员”会立刻“驳回”计划,并附上具体的反馈意见。然后,“规划师”会根据这些反馈,进行自我修正,迭代出一份更好的计划。这个“计划-反馈-修正”的闭环,像极了一位经验丰富的人类程序员在编码前反复推敲、在提交前进行代码审查的过程,极大地提升了最终操作的准确率。
所以呢?这到底意味着什么?
这项研究最激动人心的地方,在于它为我们描绘了一幅AI能力进化的新蓝图。
过去,我们把AI当成一个可以对话的“信息检索器”或“内容生成器”。而TEXT2DB和OPAL框架的提出,则预示着AI正在成为一个可以被深度整合进业务流程的**“任务执行器”**。
这不仅仅是关于自动更新电影数据库。想象一下:
- 在金融领域, AI可以实时阅读全球财经新闻和公司财报,自动更新你的股票分析数据库,调整估值模型中的关键参数。
- 在医疗科研领域, AI可以消化海量的最新医学论文,将其中关于基因、蛋白质和药物相互作用的发现,精准地更新到庞大的生物信息知识库中。
- 在电商运营中, AI可以分析成千上万条用户评论,提取出关于产品的新特性、新用途或缺陷,并将其结构化地补充到你的产品信息管理系统中。
这些在过去需要耗费大量人力进行阅读、理解、复制和粘贴的工作,都有望被一个懂得“规矩”、会“三思而后行”的AI助理所接管。
OPAL的成功证明,实现这一切的关键,可能不在于无尽地堆叠模型参数,而在于设计一个更智能、更严谨的工作流程。教会AI不仅要“知道答案”,更要懂得如何遵循规则、检查错误、修正自我,这或许才是我们解锁AI在真实世界中更大潜能的钥匙。
下一次,当你惊叹于AI能“读懂”万物时,不妨多问一句:“那它会‘归档’吗?” 这个问题,或许将是区分“玩具”和“生产力工具”的关键。