大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。近日,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。即,大模型对输入中不同位置的文本信息利用能力是不同的,对召回的若干条文档片段进行合理的位置安排,能有效提高模型的回答效果。 本文将简单介绍一下这个现象。
假设我们检索出来的相关文档为doc1,doc2,doc3,如下所示

存在一个问题是:这里doc1、doc2、doc3应该怎么排序合适?
作者做了一系列的实验,这里直接给出结论:把关键信息位于输入上下文的开始或结尾时,模型表现最佳。而关键信息位于长上下文的中部,性能可能会大幅下滑。
那么如果在做RAG检索的时候,可以将相似度高的放到前后,而相似度低的放在中间。我们在实际项目中实验也有类似的结论。
实验场景
在论文中,作者以以下两种场景进行实验:
(1)wiki问答场景:大模型输入中包含一个问题和k个与问题相关的wiki文档片段,但是只有其中1个文档片段包含正确答案(数据集大部分都是who/where类型的,有精确答案,比较好评估)。做多次试验,每次分别将包含正确答案的文档片段放在不同的输入位置,并看模型模型回答问题的正确率。
(2)大模型输入为一个字典,包含若干对key和value,key和value都是无意义的id编号。问大模型某个key,看其能否提取到对应的value。和文档问答相比,该任务更简单的任务,也和实际使用场景偏离,本文不关心这部分数据的实验结果,感兴趣的可以看下原文,结论也差不多。下文的内容都是wiki问答场景的。
核心观点
大模型对上下文中中间部分的知识点提取较差。下图展示了,在大模型输入中放入20个文档片段,分别把包含正确答案的文档片段放到输入的不同位置上(1~20),chatgpt能回答正确的概率。可以看到,如果包含正确答案的文本片段在中间位置,回答效果还不如不给他提供任何的文本片段(红色虚线,chatgpt不借任何外部知识,在wiki问答场景下回答正确率也有56.1%)。也就是说,在模型知道一些对应知识的场景下,如果输入过长,并且正确答案在输入的中间部分,甚至会给模型效果带来负面影响。并不是说外挂了知识库一定能促进模型回答效果。

实验现象
上文提到,wiki问答场景下,在输入里不给chatgpt提供任何额外知识,回答正确率都有56.1%,相当于可接受的使用外挂知识库的准确率下限(如果低于这个值,那就还不如不外挂知识库了)。作者也尝试了输入里只放1个包含正确的答案的文档片段,回答正确率为88%,相当于使用外挂知识库准确率的上限。
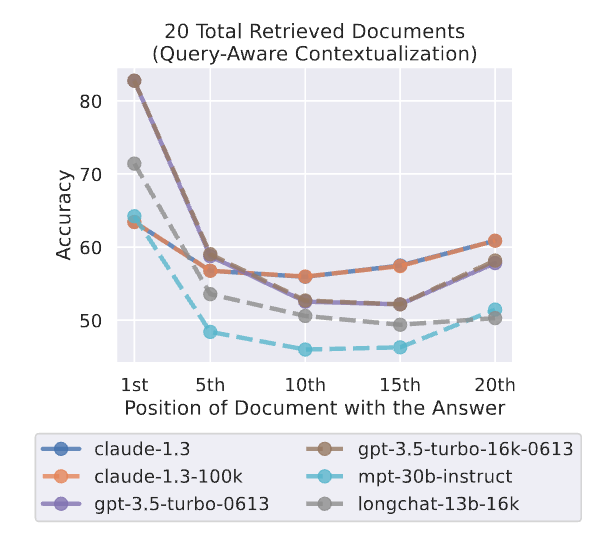
下图分别展示了不同模型在输入中分别放10/20/30个文档片段的实验结果(依然只有1个文档片段包含正确答案)。横坐标表示把包含正确答案的文档片段放到不同位置,纵坐标为准确率。从整体上来看,可以发现包含文档片段越多(上下文越长),模型性能越差。当文档片段数大于20时,如果把正确的文档片段放到中间位置,准确率还不如不加入任何文档片段(低于56.1%)。普通chatgpt和声称支持更长上下文的chatgpt-16k效果差不多。

下边两张图展示了输入中包含20个文档片段的情况下,分别把query放到context尾部和context头部的实验效果。将query放到context头部效果更好。这非常符合直觉,实验的用的都是decoder架构的模型,只能看到上文的信息,带着问题去找答案更简单。

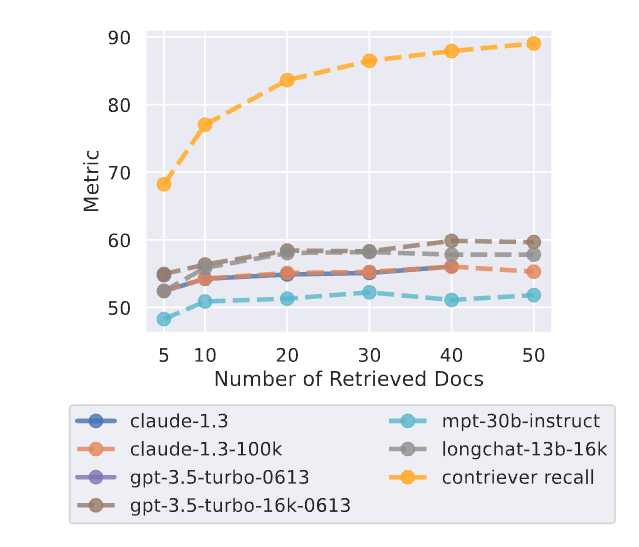
在实际应用场景下(该部分实验加入向量召回阶段,之前的实验没有召回阶段,都是把包含正确答案的文档片段直接塞到不同位置),向量召回可能是不准确的,召回的文档片段数量越多,漏掉正确答案的概率越小。但是如果召回的文档片段过多的话,导致输入到LLM的context过长,并不一定能有很好的效果。文中实验显示,随着召回的文档片段越来越多,召回率越高,召回阶段漏掉的正确文档越少(黄色曲线),但是模型回答的正确率并没有很大的提升,在召回20个文档片段的情况下基本就达到性能上线了。作者实验挑选的模型都是能支持比较长的文本的,大部分人使用的chatglm和llama估计能提取10个文档片段信息就不错了。。。当然,LLM能提取多少个文档片段的内容也和每个文档片段的长度有关。文档片段长度最好别超过100,不然会影响embedding模型向量化效果,进而使得召回精度降低。
总结
当我们召回若干个文档片段当作大模型的输入,应该怎么对这些文档片段进行排列,提高大模型回答效果呢?遵循两个原则:
- query放到头部。
2.根据相似度(cos相似度,点积等)召回的文档,相似度越大的文档放到context的两端。
具体来说,比如我们召回、排序后按相关程度从高到低为:
1 | doc1, doc2, doc3 |
实际prompt中的doc位置采用
1 | doc1, doc3, doc2 |
可能效果更佳。
重要信息位置为什么会影响大模型的效果
在大语言模型的输入上下文中改变相关信息的位置(即回答输入问题的段落的位置)会导致一个U形性能曲线——模型更擅长使用出现在输入上下文的开头或结尾的相关信息,而当模型需要访问和使用位于输入上下文中部的信息时,性能显著下降。例如,当将相关信息放置在输入上下文的中间时,GPT-3.5-Turbo在多文档问答任务上的开放式表现低于在没有任何文档的情况下的预测性能!也就是说,如果输入数据的重要信息没有出现在开始或者结尾位置,大模型可能会出现找不到答案的情况!
这篇论文的发现在推特上引起了非常多的关注和讨论,因为这个结论真的很有意思。尽管这篇论文给了这样一个非常重要且有意思的结论,但是并没有回答为什么大模型会出现这种问题。Lightning AI的首席AI教育家, UW-Madison大学前统计学教授Sebastian Raschka也讨论了这个问题,给了他的一个观点。
Sebastian Raschka认为,基于transformer的大语言模型架构本身应该不会出现这种偏差。反而是基于RNN的模型可能会因为序列过长出现这种问题(因为RNN是按照序列处理的,早先处理的内容可能会被遗忘。而transformer是按照位置编码,一次性输入,没有先后概念)。因此,他怀疑可能是大多数人类写的文章内容习惯把重要的信息放在文章的开头和结尾,影响了大模型的训练结果。
这也是猜测,也有人认为,设计另一个类似论文的实验,但是测试代码类的问题可能就会看出是不是这样。因为,代码的执行是有逻辑的,不会出现把重要的信息放在文本的开头和结尾这种逻辑。emmmm~非常有意思的想法,的确是可以验证的。
参考
Paper:https://arxiv.org/abs/2307.03172
知乎:https://zhuanlan.zhihu.com/p/651932402