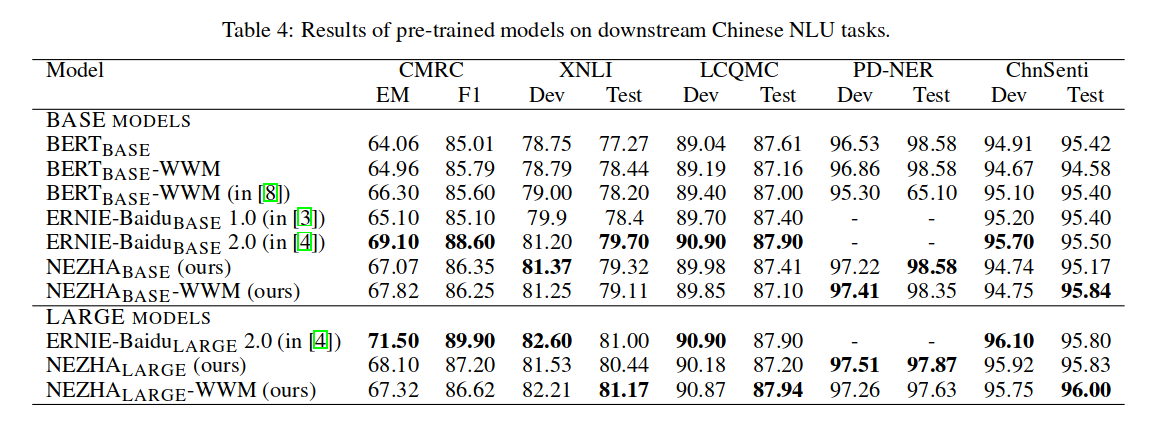
对于预训练模型来说,提升模型的大小能够提高下游任务的效果,然而如果进一步提升模型规模,势必会导致显存或者内存出现OOM的问题,长时间的训练也可能导致模型出现退化的情况。这次的新模型不再是简单的的升级,而是采用了全新的权重共享机制,反观其他升级版BERT模型,基本都是添加了更多的预训练任务,增大数据量等轻微的改动。ALBERT模型提出了两种减少内存的方法,同时提升了训练速度,其次改进了BERT中的NSP的预训练任务。
从ResNet论文可知,当模型的层次加深到一定程度后继续加深层深度会带来模型的效果下降,与之类似,如下图所示;
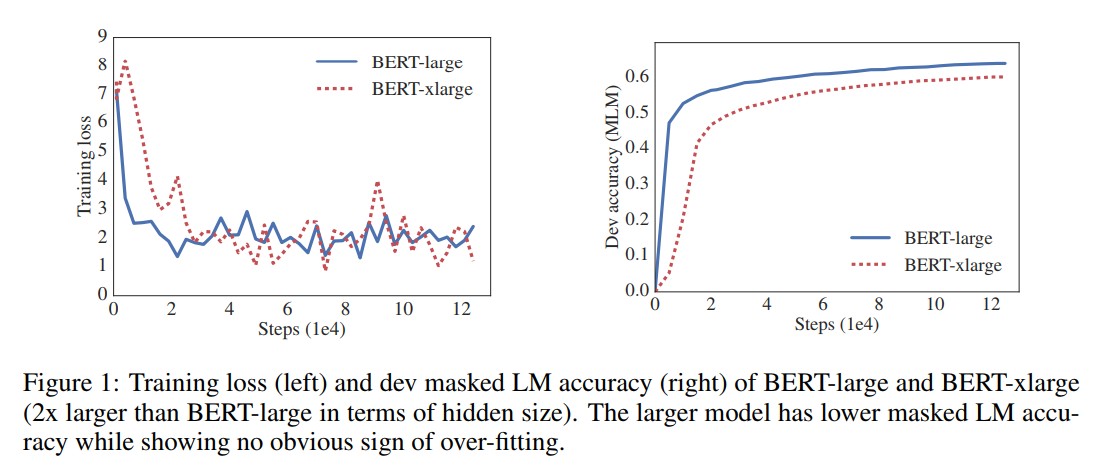
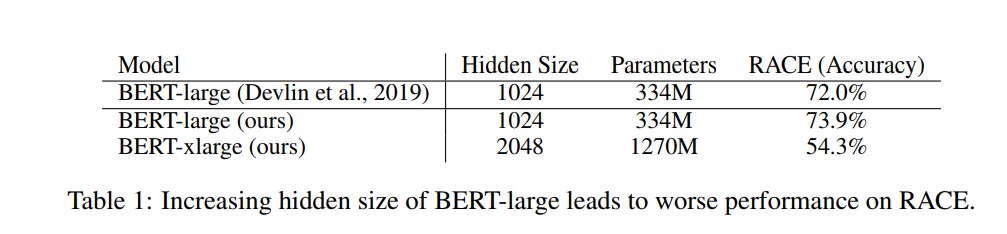
将BERT的hidden size增加,结果效果变差。因此,ALBERT模型三种手段来提升效果,又能降低模型参数量大小。
Embedding因式分解
从模型的角度来说,WordPiece embedding的参数学习的表示是上下文无关的,而隐藏层则学习的表示是上下文相关的。在之前的研究成果中表明,BERT及其类似的模型的好效果更多的来源于上下文信息的捕捉,因而,理论上来说隐藏层的表述包含的信息应该更多一些,隐藏层的大小应比embedding大,若让embedding大小等于隐藏层大小,embedding占据这么多的参数,会导致最终的参数非常稀疏。
因而,我们不用这么大的embedding size,而是用一个较小的size,但是这样就没法在第一层去做残差了。没有关系,我们可以用另一个参数矩阵来把embedding size投射到hidden size上来。即假设V是vocab size,E是embedding size,H是hidden size,那么原始的BERT中E=H, 参数数目为VxH,而做了分解之后参数数据为VxE+ExH, 因为E远小于H,所以做了分解后这一部分的参数变少了很多。

上图是E选择不同值的一个实验结果,可以看到当E从768降到128时,模型参数大小从108M降到89M,也就是说E的因式分解大概降低了19M左右,但是在最一列可以看出使用E的因式分解之后,模型性能降低了,约0.6%。
简要实现方式:
1 | self.word_embeddings = nn.Embedding(config.vocab_size, config.embedding_size, padding_idx=0) |
跨层的权重共享(Cross-layer parameter sharing)
Transformer中共享权重有多种方案,只共享全连接层,只共享attention层,ALBERT结合了上述两种方案,全连接层与attention层都进行权重共享,也就是说共享encoder内的所有权重。
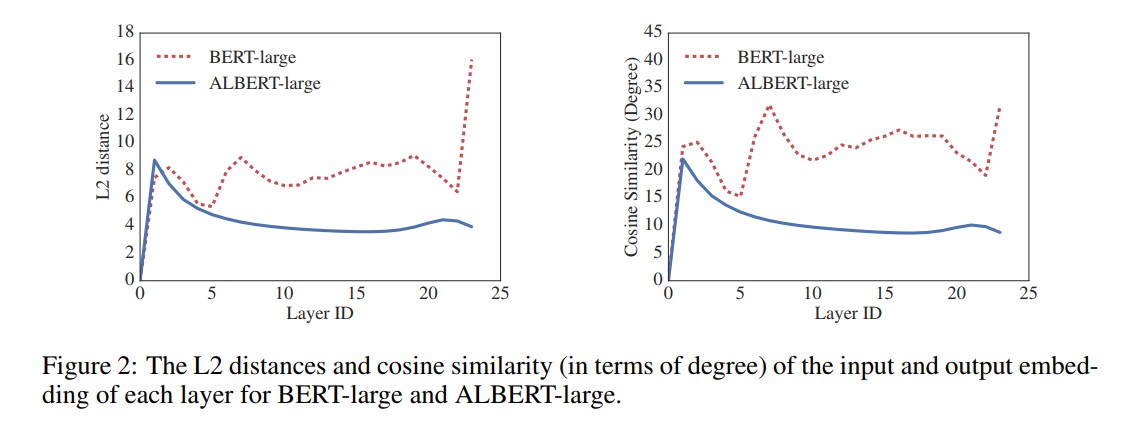
上图展示了BERT-large与ALBERT-large每一层输入嵌入与输出嵌入间的L2距离与余弦相似性。从图可以发现ALBERT从一层到另一层的转换要比BERT平滑得多。这说明权重共享有效地提升了神经网络参数的鲁棒性。

上图是ALBERT不同类型权重共享的一个对比,以base为例,当E=768时,类比BERT,也就是BERT的参数是108M,而ALBERT仅有31M,足足降低了77M左右,可见模型大小降低主要来自于权重共享,embedding的因式分解只降低一小部分。虽然权重共享显著地降低了模型大小,使得训练时使用更小的显存以及更快的训练,但是从最后的一列avg可以看到权重共享降低了模型的效果,整体上约下降1.5%。仔细一看,好像只共享attention层,模型整体上效果保持不变。
all-shared的简要实现方式:
1 | self.layer_shared = BertLayer(config) |
而BERT中的实现方式为:
1 | self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)]) |
句间连贯(Inter-sentence coherence loss)
BERT的NSP任务实际上是一个二分类,训练数据的正样本是通过采样同一个文档中的两个连续的句子,而负样本是通过采用两个不同的文档的句子。该任务主要是希望能提高下游任务的效果,例如NLI自然语言推理任务。但是后续的研究发现该任务效果并不好,比如Roberta直接去除了NSP,主要原因是因为其任务过于简单。NSP其实包含了两个子任务,主题预测与关系一致性预测,但是主题预测相比于关系一致性预测简单太多了,并且在MLM任务中其实也有类型的效果。
这里提一下为啥包含了主题预测,因为正样本是在同一个文档中选取的,负样本是在不同的文档选取的,假如我们有2个文档,一个是娱乐相关的,一个是新中国成立70周年相关的,那么负样本选择的内容就是不同的主题,而正样都在娱乐文档中选择的话预测出来的主题就是娱乐,在新中国成立70周年的文档中选择的话就是后者这个主题了。
在ALBERT中,为了只保留一致性任务去除主题识别的影响,提出了一个新的任务 sentence-order prediction(SOP),SOP的正样本和NSP的获取方式是一样的,负样本把正样本的顺序反转即可。SOP因为实在同一个文档中选的,其只关注句子的顺序并没有主题方面的影响。并且SOP能解决NSP的任务,但是NSP并不能解决SOP的任务,该任务的添加给最终的结果提升了一个点。(同个文档两个连续的段落,正样本,负样本就是两个段落的反向)
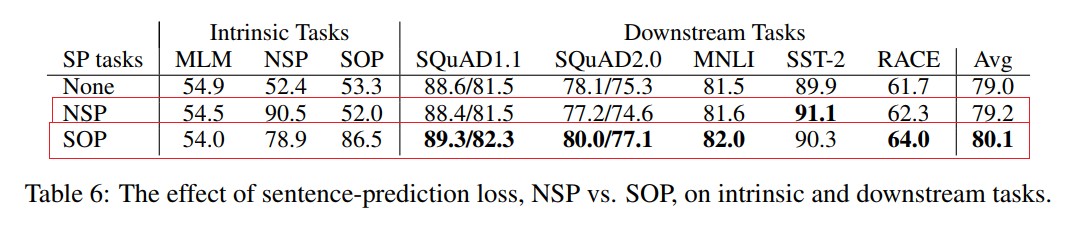
embedding因式分解和模型的权重共享两种技术虽然减小模型的大小,但是带来了性能的损失,而从上图可以看出,SOP技术补偿了一部分损失的性能,SOP大体上上提高了0.9%。
SOP目标构造方式:
1 | # NSP:是否下一句预测, true = 上下相邻的2个句子,false=随机2个句子 |
其他
增加数据
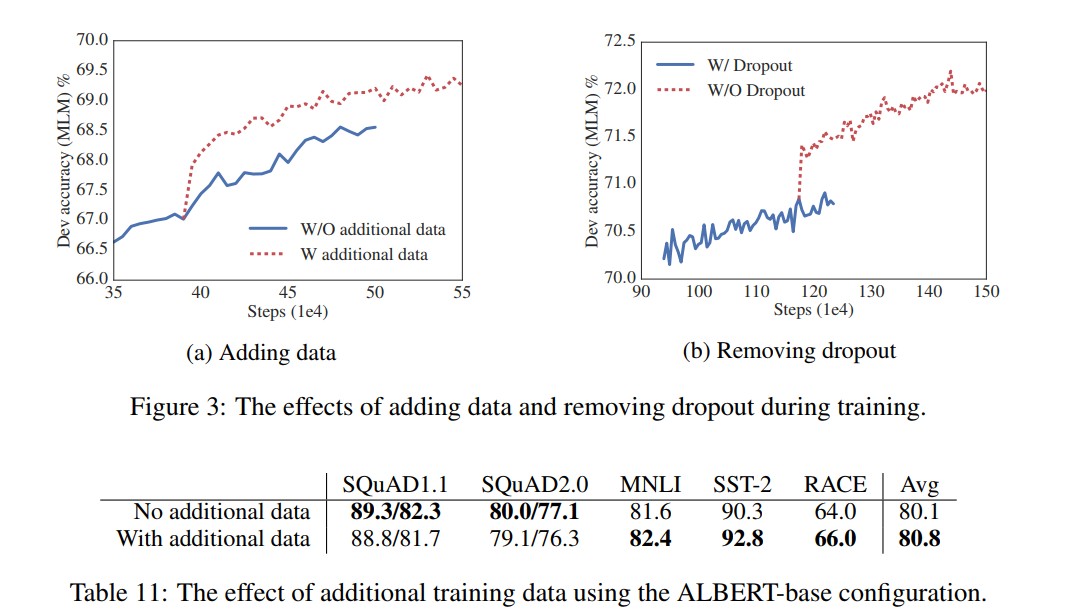
从上图可以看出,增加额外的数据很明显可以对训练和下游任务的效果有一定的提升。
移除dropout

ALBERT在训练了100w步之后,模型依旧没有过拟合,从训练结果和下游任务结果来看,移除dropout提升了训练和下游任务的效果。
n-gram mask
在训练构造数据部分,作者使用的n-gram mask形式(应该是借鉴了spanBERT),概率计算公式如下:
作者设置的n-gram最大长度为3,即MLM目标最多由3个全词组成。 按照公式,比如取1-gram、2-gram、3-gram的概率分别为6/11 3/11 2/11.越长概率越小
具体实现代码为;
1 | ngrams = np.arange(1, max_ngram + 1, dtype=np.int64) |
** segments-pair**
BERT为了加速训练,前90%的steps使用了128个token的短句,最后10%才使用512个词的长句来训练position embedding。
1 | Longer sequences are disproportionately expensive because attention is quadratic to the sequence length. |
而ALBERT对数据格式是90%的情况下,输入的是segment满足512个词,其输入序列要比BERT长接近一半。
1 | We always limit the maximum input length to 512, |
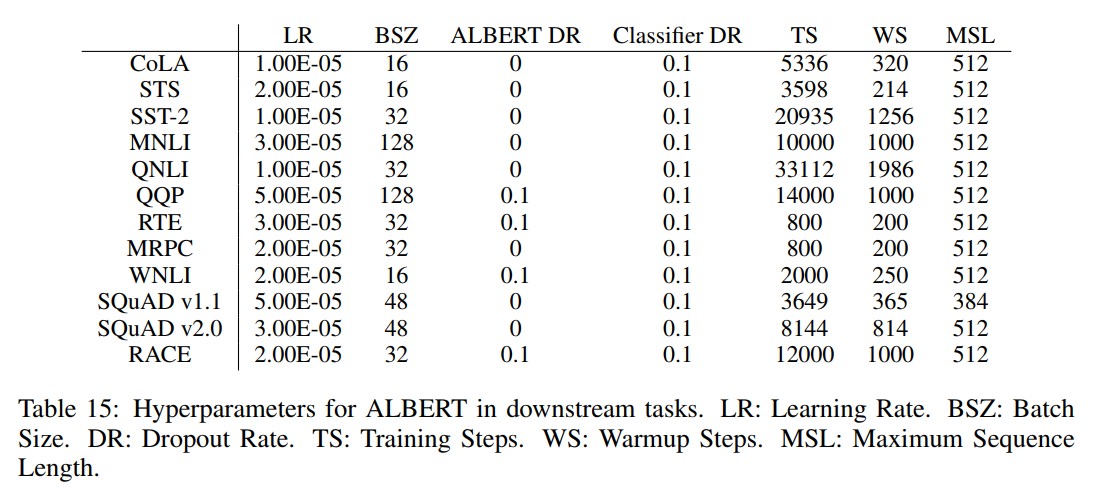
超参数
以下是作者提供的下游任务fine-tuning ALBERT的参数,对于个人fine-tuning其他任务可以参考。
总结
ALBERT通过参数共享、embedding因式分解的方式降低了内存消耗,并且加快了训练速度,但是预测阶段还是需要和BERT一样的时间,如果采用了xxlarge版本的ALBERT,那实际上预测速度会更慢。不过话说回来,ALBERT也更加适合采用feature base或者模型蒸馏等方式来提升最终效果。另外,ALBERT作者最后也简单提了下后续可能的优化方案,例如采用sparse attention或者block attention,这些方案的确是能真正降低运算量。其次,作者认为还有更多维度的特征需要去采用其他的自监督任务来捕获。
论文地址: https://arxiv.org/pdf/1909.11942.pdf
google官方源码: https://github.com/google-research/ALBERT
bright提供的tensorflow版本中文模型权重:https://github.com/brightmart/albert_zh
个人转化为Pytorch版本权重:https://github.com/lonePatient/albert_pytorch