
Arxiv今日论文 | 2026-05-29
本篇博文主要内容为 2026-05-29 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR、MA六个大方向区分。
说明:每日论文数据从Arxiv.org获取,每天早上12:30左右定时自动更新。
提示: 当天未及时更新,有可能是Arxiv当日未有新的论文发布,也有可能是脚本出错。尽可能会在当天修复。
目录
概览
自然语言处理CL
多智能体系统MA
信息检索IR
人机交互HC
人工智能AI
机器学习LG
计算机视觉CV
概览 (2026-05-29)
今日共更新902篇论文,其中:
自然语言处理共200篇(Computation and Language (cs.CL))
人工智能共354篇(Artificial Intelligence (cs.AI))
计算机视觉共170篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共289篇(Machine Learning (cs.LG))
多智能体系统共21篇(Multiagent Systems (cs.MA))
信息检索共2 ...
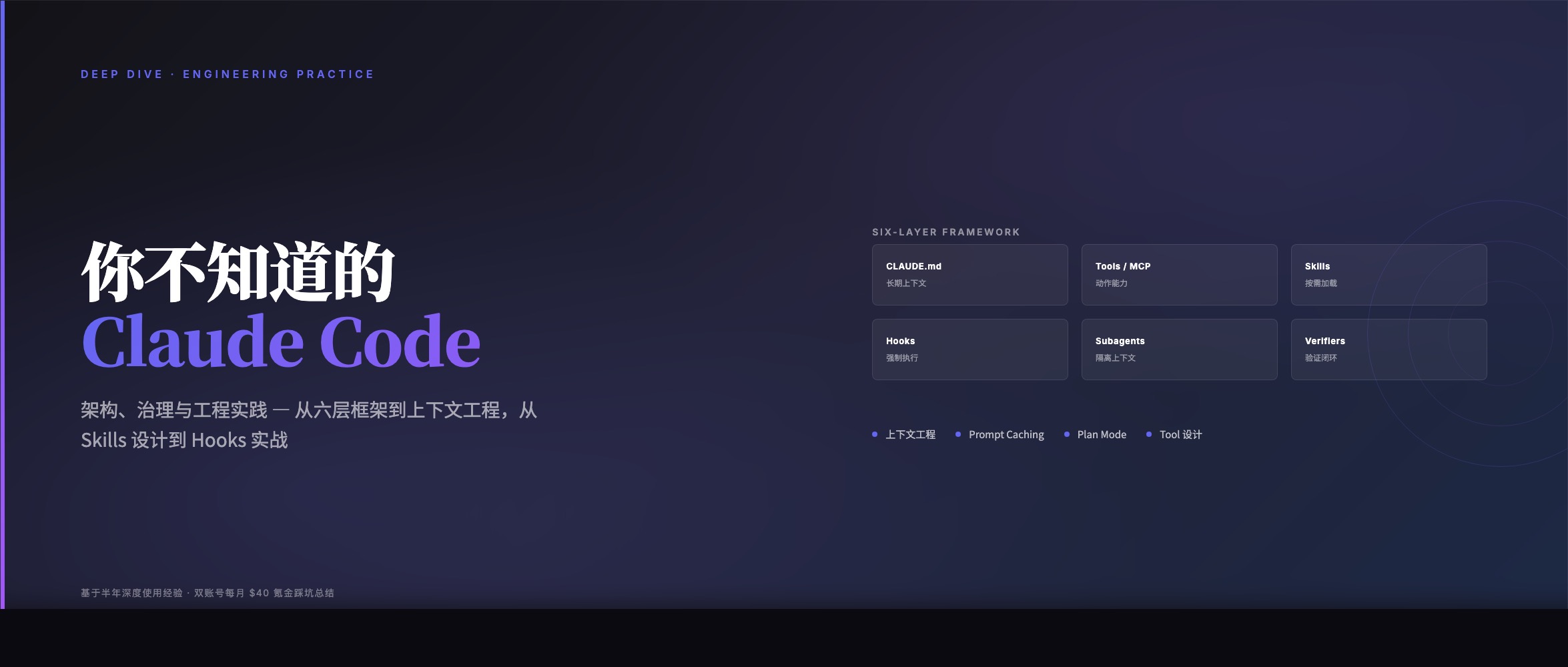
你不知道的 Claude Code:架构、治理与工程实践
0. 太长不读
今天这篇文章源于最近半年深度使用 Claude Code、两个账号每月 40 刀氪金换来的一些踩坑经验,希望能给大伙一些输入。
刚开始我也把它当 ChatBot 用,后来很快发现不对劲:上下文越来越乱、工具越来越多但效果越来越差、规则越写越长却越不遵守,折腾了一段时间,研究了 Claude Code 本身之后才意识到,这不是 Prompt 问题,而是这套系统的设计就是这样的。
这篇文章想和大伙聊聊这几个事:Claude Code 底层怎么运作、上下文为什么会乱以及怎么治理、Skills 和 Hooks 应该怎么设计、Subagents 的正确用法、Prompt Caching 的架构影响,以及怎么写一个真正有用的 CLAUDE.md。
我觉得最直接的理解方式,是把 Claude Code 拆成六层来看:
层
职责
CLAUDE.md / rules / memory
长期上下文,告诉 Claude “是什么”
Tools / MCP
动作能力,告诉 Claude “能做什么”
Skills
按需加载的方法论,告诉 Claude “怎么做”
Ho ...
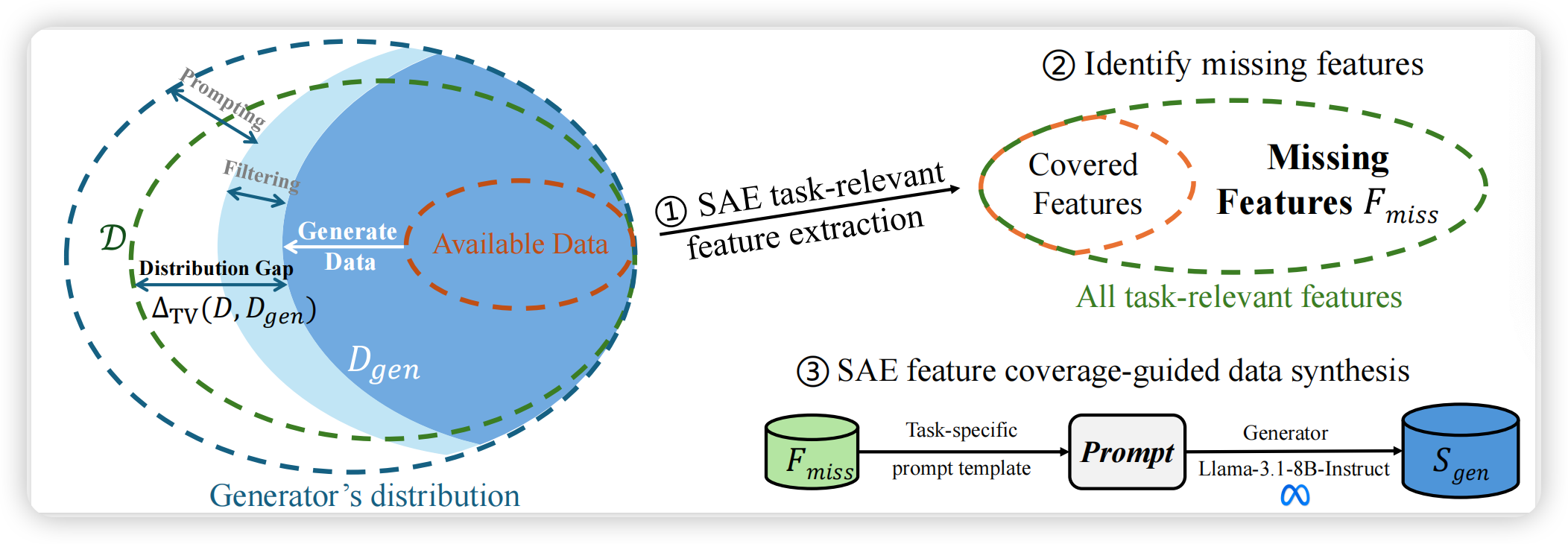
大模型数据合成新范式:2K样本打败30万,从特征空间精准狙击任务短板
【速读摘要】:该论文提出 Feature Activation Coverage (FAC) 指标,用于在 LLM 内部可解释特征空间度量数据多样性。基于 FAC,作者设计了两阶段数据合成框架 FAC Synthesis:首先通过 Sparse Autoencoder (SAE) 识别种子数据集中缺失的任务相关特征,然后生成显式激活这些特征的合成样本。实验表明,FAC 与下游任务性能呈强正相关(Pearson r=0.95r=0.95r=0.95),且该方法仅用 2K 合成样本即可达到 MAGPIE 300K 样本的指令跟随性能(150× 数据效率提升)。此外,作者发现 LLaMA、Mistral、Qwen 三大模型家族共享可解释特征空间,支持跨模型知识迁移。
【论文链接】:arXiv:2602.10388
【机构信息】:University of Georgia(美国佐治亚大学);University of California, San Diego(美国加州大学圣地亚哥分校);Mohamed bin Zayed University of Artificial Intellige ...
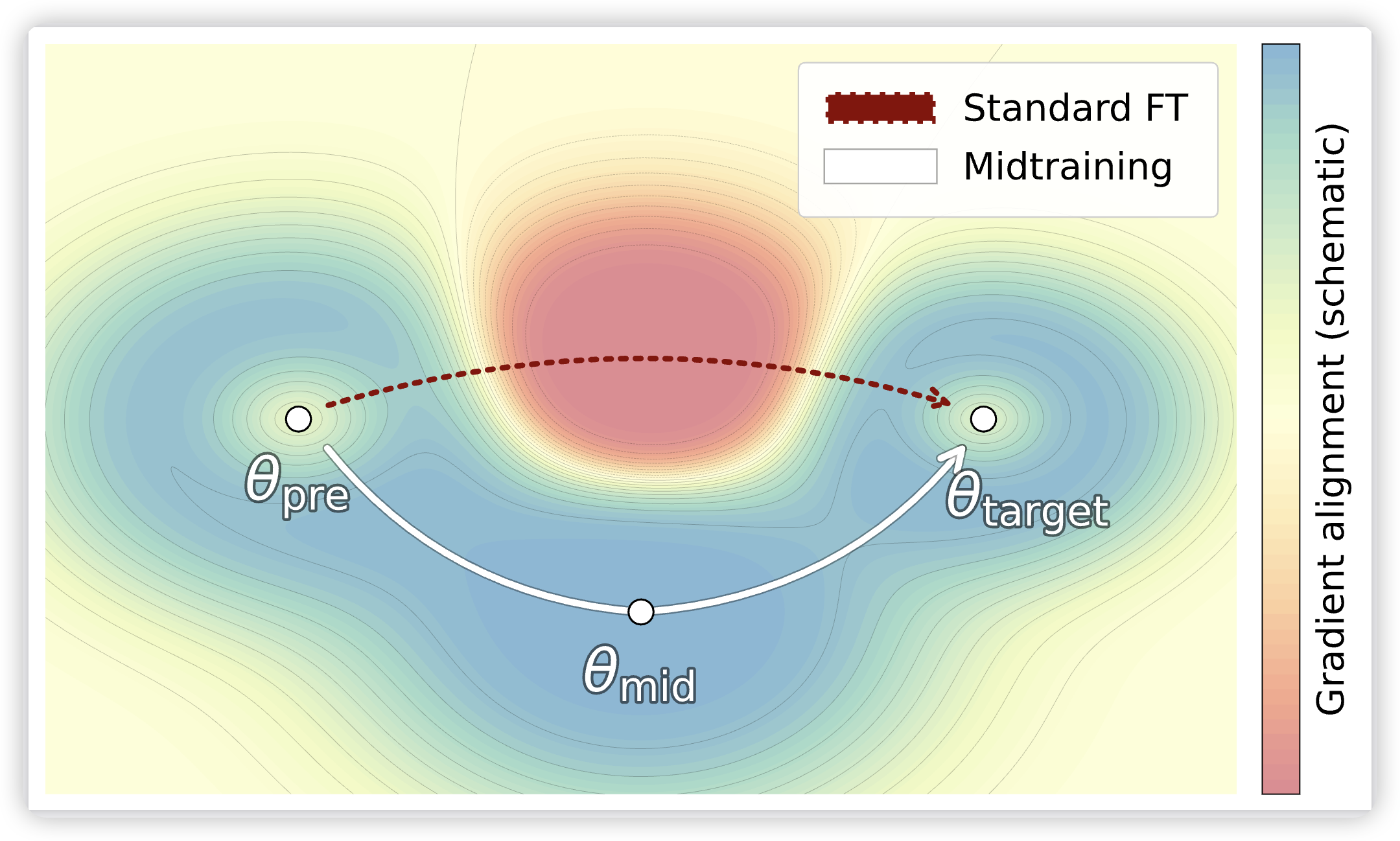
mid-training:构建预训练与后训练之间的分布式桥梁
【速读摘要】:本文系统研究了语言模型训练中"中训练"(Midtraining)阶段的作用——即在预训练和后训练之间插入一个混合专业数据的中间阶段。研究发现:1)Midtraining对代码、数学等与通用预训练数据差异较大的领域效果最显著;2)Midtraining能有效减少后训练阶段的灾难性遗忘;3)专业数据引入的时机和混合比例存在强交互作用——早期引入支持高混合比例,晚期引入则需保守混合;4)在减少遗忘方面,Midtraining始终优于纯持续预训练。
【论文链接】:arXiv:2510.14865 (ICML 2026)
【机构信息】:Carnegie Mellon University - Language Technologies Institute
【开源链接】:https://anonymous.4open.science/r/midtraining-E5D8/
【关键词】:midtraining, pretraining, finetuning, domain adaptation, catastrophic forgetting, distri ...
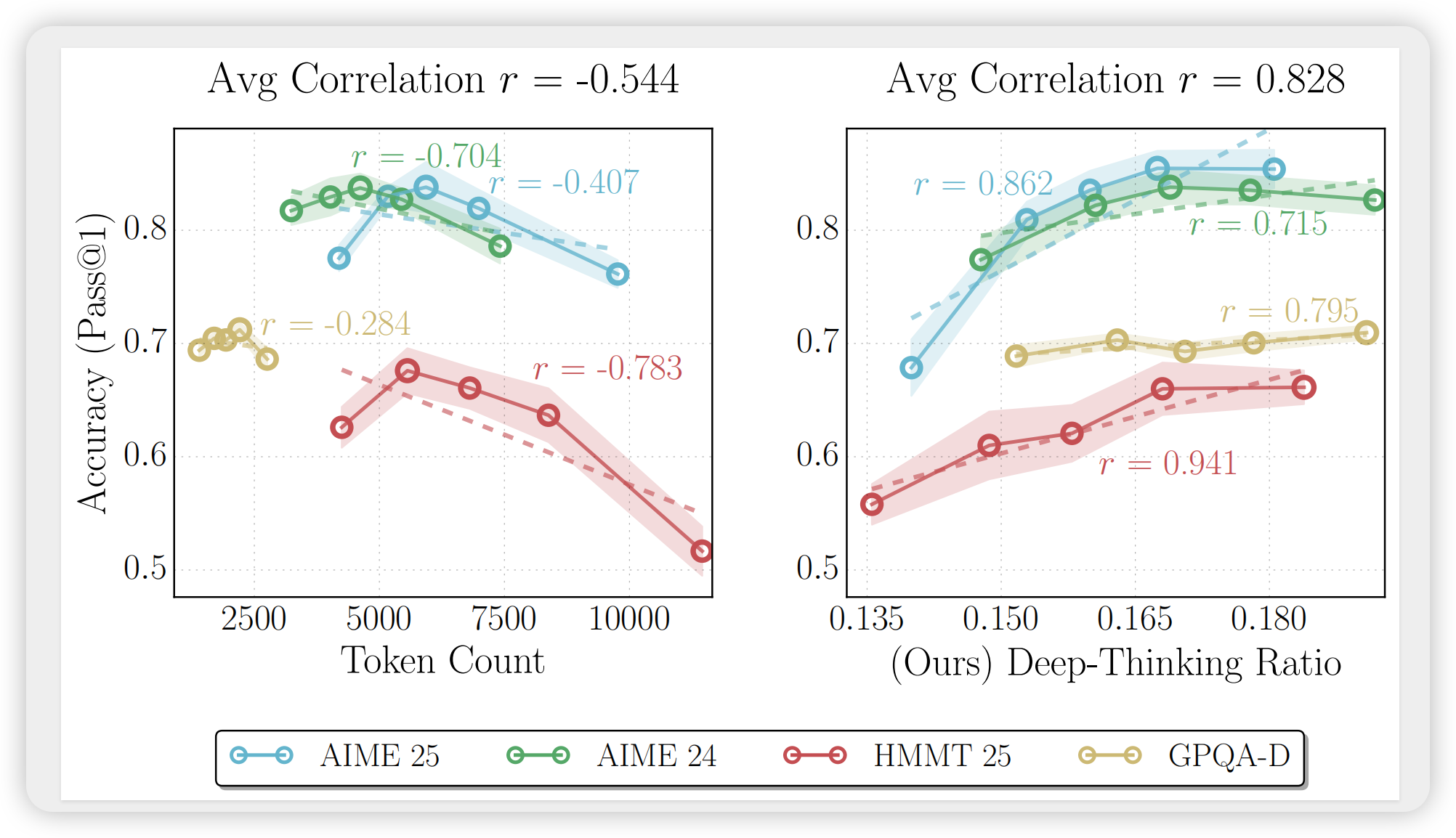
用"深度思考率"精准度量LLM推理质量
【速读】:该论文提出了一种新的推理质量度量指标——深度思考率(Deep-Thinking Ratio, DTR),通过分析模型内部各层预测分布的收敛行为来量化推理努力程度。研究发现,DTR与任务准确率呈现稳定正相关(平均r=0.683),显著优于基于token长度(r=-0.594)或置信度(r=0.605)的基线方法。基于此,作者设计了Think@n采样策略,在保持或超越标准自一致性性能的同时,将推理成本降低约50%。
【论文链接】:arXiv:2602.13517
【机构信息】:University of Virginia(弗吉尼亚大学);Google(谷歌)
【开源链接】:未开源
1. 背景与核心洞察 (The Core Insight)
当前大语言模型(LLM)的推理能力主要通过生成显式的思维链(Chain-of-Thought, CoT)来实现,业界普遍采用"测试时计算扩展"(test-time compute scaling)策略——即通过生成更长的推理轨迹来提升任务性能。然而,一个日益凸显的问题是:token数量并非推理质量的可靠代理指标。
近期多项 ...
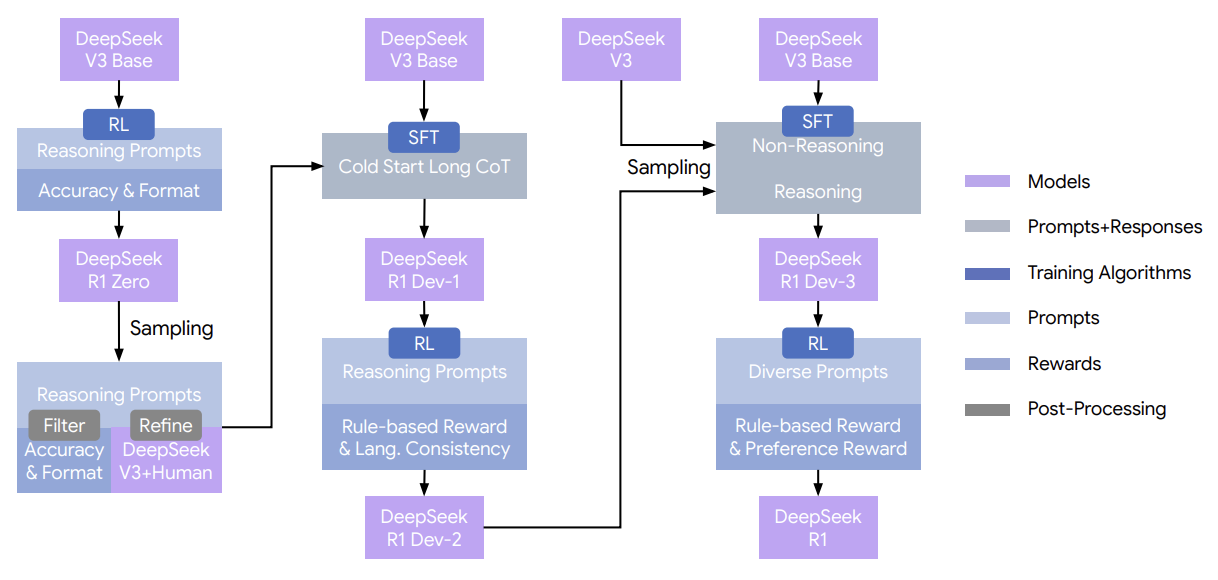
前沿大模型训练方法:深度解析与实践指南
前言
实验室如何训练一个拥有数百亿参数的前沿大模型?本文深入剖析七个开源权重的前沿模型:Hugging Face的 SmolLM3、Prime Intellect的 Intellect 3、Nous Research的 Hermes 4、OpenAI的 gpt-oss-120b、Moonshot的 Kimi K2、DeepSeek的 DeepSeek-R1 以及 Arcee的[Trinity series](https://github.com/arcee-ai/trinity-large-tech-report/blob/main/Arcee Trinity Large.pdf)。本文旨在提炼这些模型训练中使用的技术、动机和考量因素,重点关注训练方法而非基础设施。
本文的结构主要参考 Hugging Face 详尽的 SmolLM3 技术报告,因其内容最为详尽,并补充了 Intellect-3、gpt-oss-120b、Hermes 4、DeepSeek 和 Kimi的相关笔记。Hugging Face 在这里 详细介绍了 gpt-oss-120b 的基础设施。
概述
核心要点
...

AI Skills 生态系统深度解析:从 Prompt Engineering 到 Agentic 基础设施的范式跃迁
TL;DR: 本文系统梳理了当前 GitHub 上 10 个主流 AI Skills 仓库(累计超过 5,000+ Stars),揭示了一个正在形成的去中心化 Agent 能力市场。Anthropic 主导的 Agent Skills 开放标准正在获得 OpenAI、Google、Microsoft、Cursor 等主流厂商的广泛采纳,这标志着 AI 辅助开发从"一次性 Prompt 工程"向"可复用、可组合、可交易的技能单元"的根本性转变。
一、核心洞察:为什么 AI Skills 正在重塑开发范式
1.1 从 Prompt 到 Skill:抽象层级的跃升
传统的大模型交互模式是命令式的——开发者每次都需要精心构造 Prompt。而 AI Skills 引入了一种声明式的抽象:
12345Prompt Engineering (v1.0) ↓ 抽象封装Skill-as-Code (v2.0) ↓ 标准化Agent Skills Standard (v3.0)
这种抽象层级的跃升带来了三个关键收益:
可复用性: 一个 Skil ...
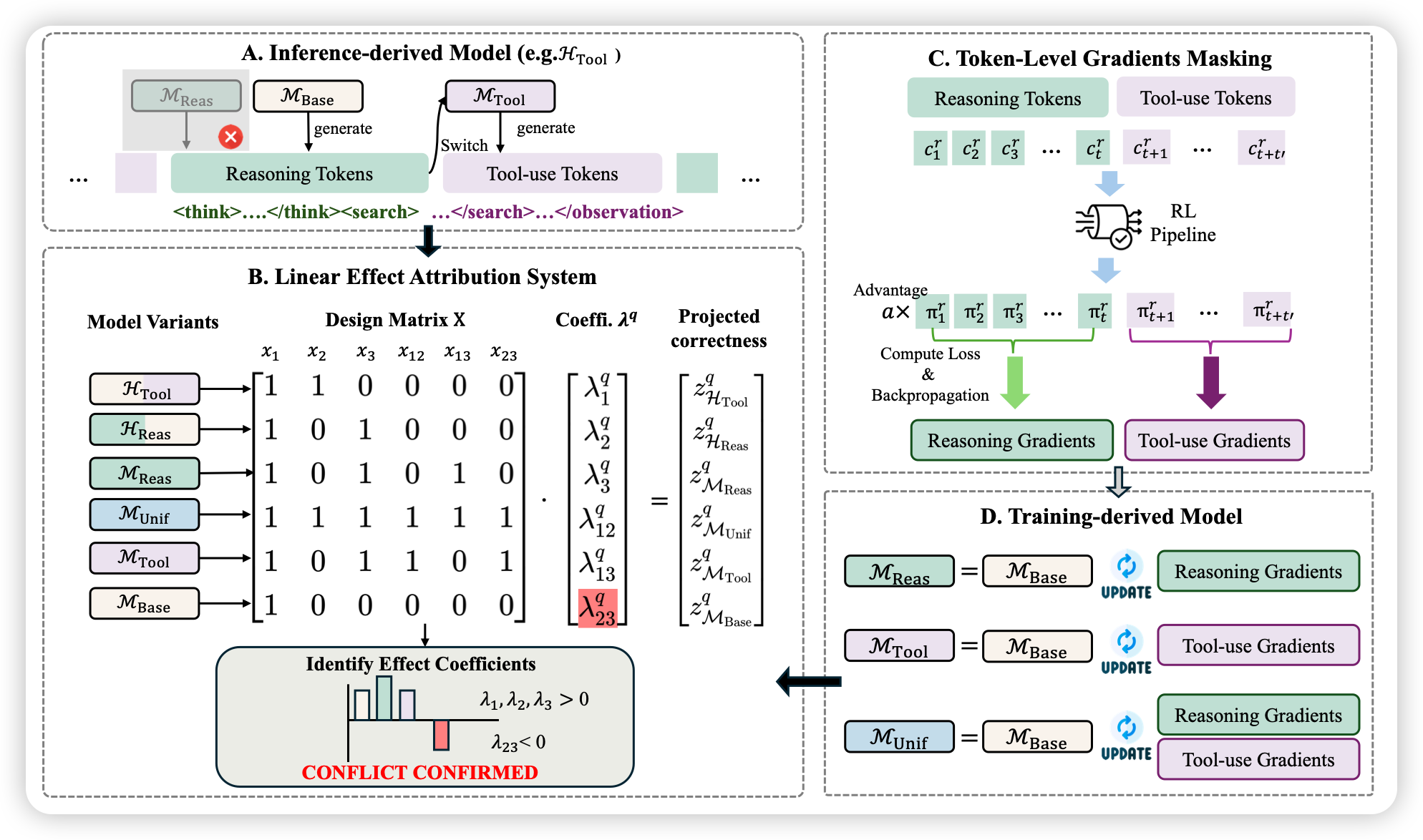
DART:通过梯度隔离解决Agentic RL中推理与工具使用的干扰问题
【速读】:本文揭示了Agentic RL中一个被长期忽视的核心问题——推理(Reasoning)与工具使用(Tool-use)能力在共享参数空间下的联合优化会产生严重的梯度冲突,导致"跷跷板"现象(提升一个能力会损害另一个)。作者提出LEAS(线性效应归因系统)定量验证了这一干扰的存在,并设计了DART框架:通过为两种能力分配独立的LoRA适配器,在token级别进行梯度隔离,从而在单模型内实现与双模型系统相当的性能,同时避免了多Agent系统的存储与推理开销。
【机构】:Renmin University of China(中国人民大学);Bytedance Inc.(字节跳动)
【开源】:未开源
1. 背景与核心洞察 (The Core Insight)
Agentic Reinforcement Learning(ARL)旨在训练能够交错执行复杂推理与外部工具调用的大语言模型。当前主流范式(如Search-R1、ToolRL等)普遍采用单一共享参数空间来联合优化这两种能力,其隐含的假设是:推理与工具使用可以和谐共存于同一参数子空间,且联合训练能够带来协同增益 ...
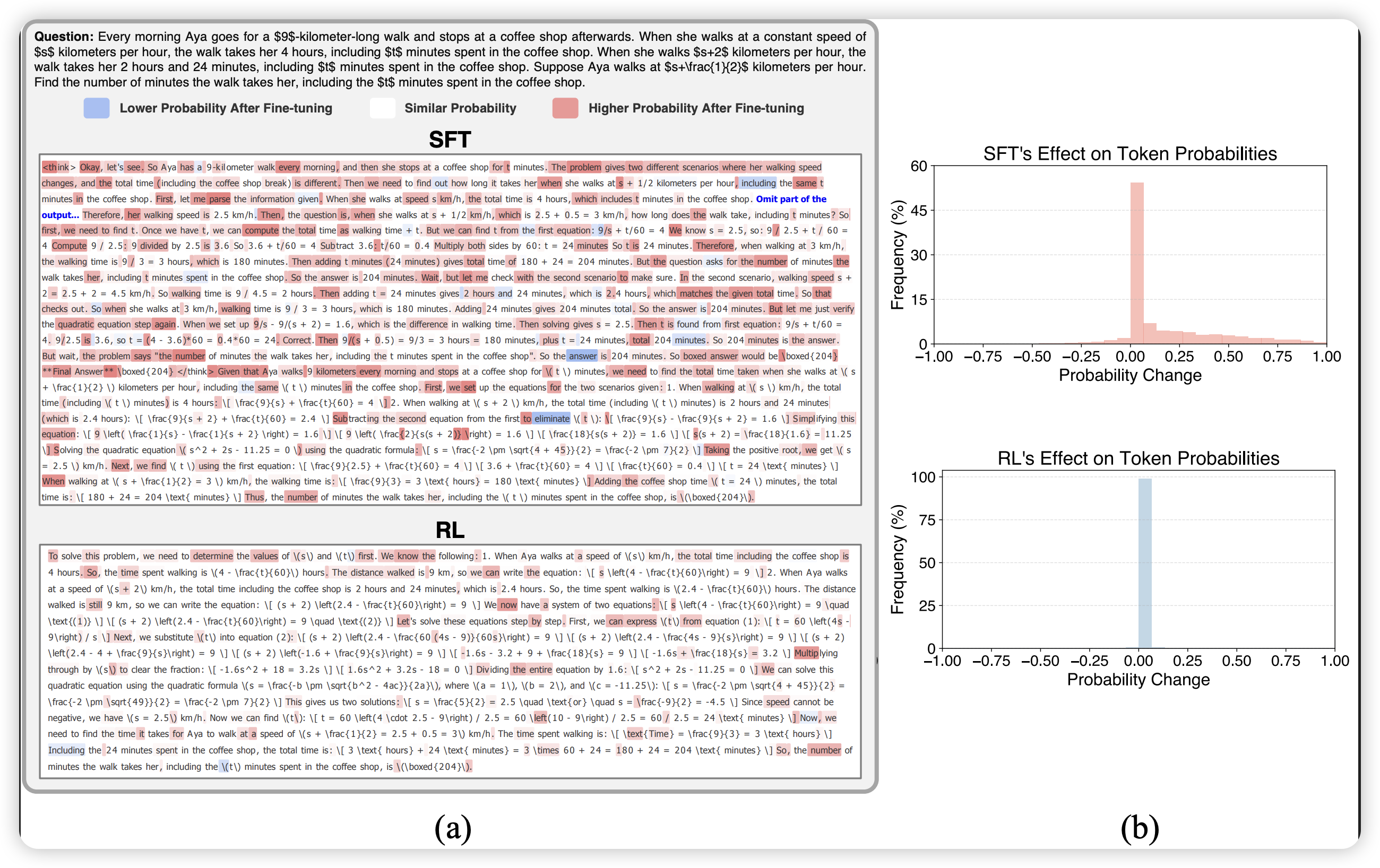
SRFT:基于熵感知的单阶段SFT-RL统一微调方法
【速读】:该论文试图解决SFT与RL在LLM推理任务中的最优整合问题。核心洞察是:SFT对策略分布进行粗粒度全局调整,而RL进行细粒度选择性优化;熵可作为训练有效性的关键指标。解决方案是SRFT——一种单阶段方法,通过熵感知权重机制统一SFT和RL,同时利用演示数据和自探索rollout直接优化LLM。
【机构】:中国科学院自动化研究所(Institute of Automation, Chinese Academy of Sciences);中国科学院大学人工智能学院(School of Artificial Intelligence, University of Chinese Academy of Sciences);美团(Meituan);上海交通大学(Shanghai Jiao Tong University)
【开源】:模型已开源至 https://huggingface.co/Yuqian-Fu/SRFT
1. 背景与核心洞察 (The Core Insight)
大语言模型在推理任务上的进展令人瞩目,但如何最优地整合监督微调(SFT)与强化学习(RL)仍是一个根本性的 ...
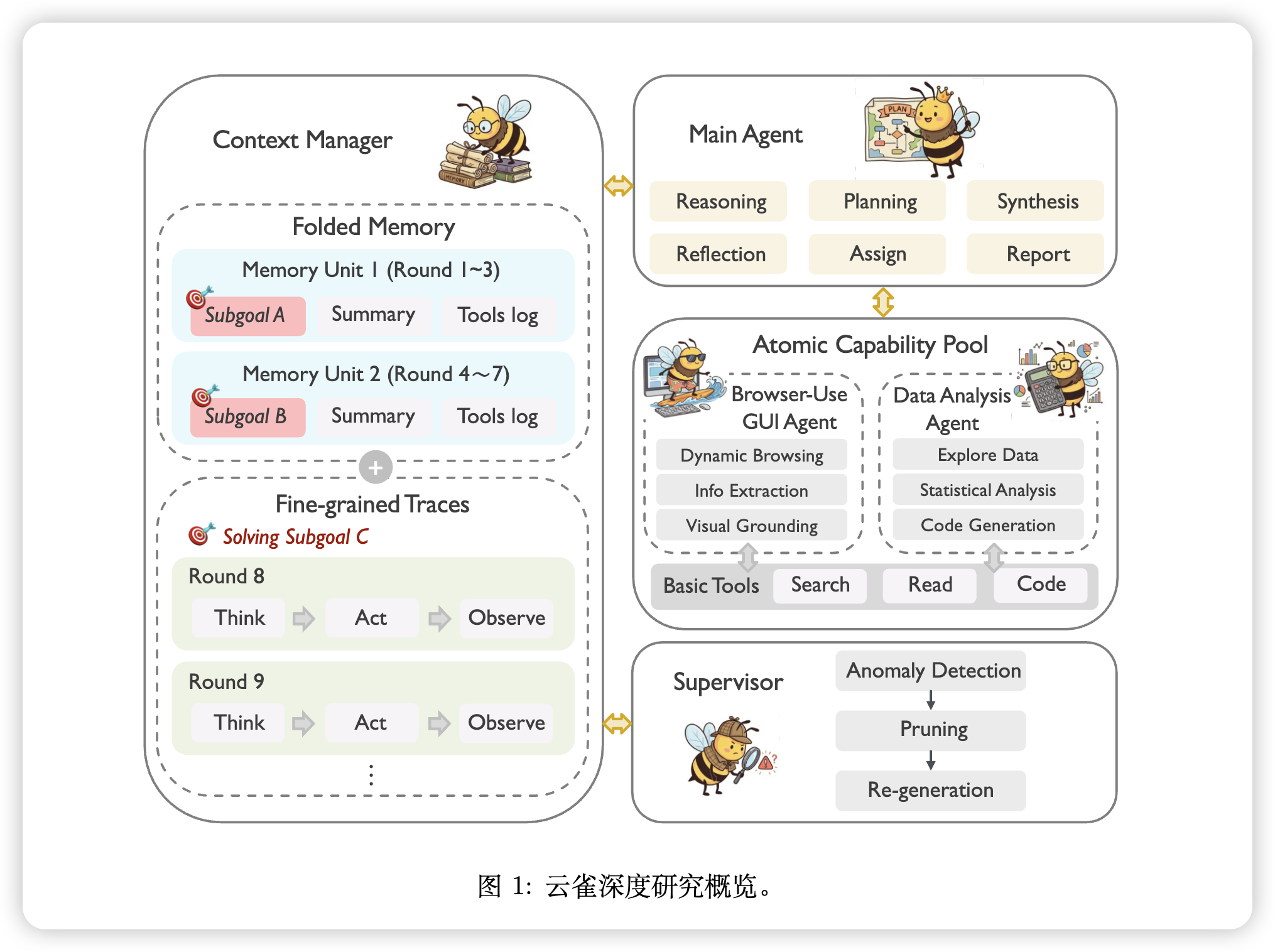
Yunque DeepResearch:层次化多智能体深度研究框架
【速读】:该论文试图解决深度研究(Deep Research)智能体在长程任务中面临的三大核心问题:(1) 上下文噪声累积导致的认知过载;(2) 执行脆弱性引发的级联错误;(3) 架构僵化带来的扩展性缺失。解决方案的核心在于构建一个层次化多智能体框架,通过子目标驱动的结构化记忆机制将上下文复杂度从 O(t)\mathcal{O}(t)O(t) 降至 O(n)\mathcal{O}(n)O(n),并引入 Supervisor 模块实现主动异常检测与上下文修剪,从而在 GAIA、BrowseComp、Humanity’s Last Exam 等基准上取得 SOTA 表现。
【机构】:腾讯 BAC(商业广告中心);清华大学;复旦大学
【开源】:https://github.com/Tencent-BAC/YunqueAgent
1. 背景与核心洞察 (The Core Insight)
深度研究(Deep Research)作为大语言模型向自主智能体演进的关键能力,旨在让模型能够主动发现、验证并综合来自动态真实环境的信息。OpenAI、Google、Kimi 等机构近期相继推出 Deep ...
