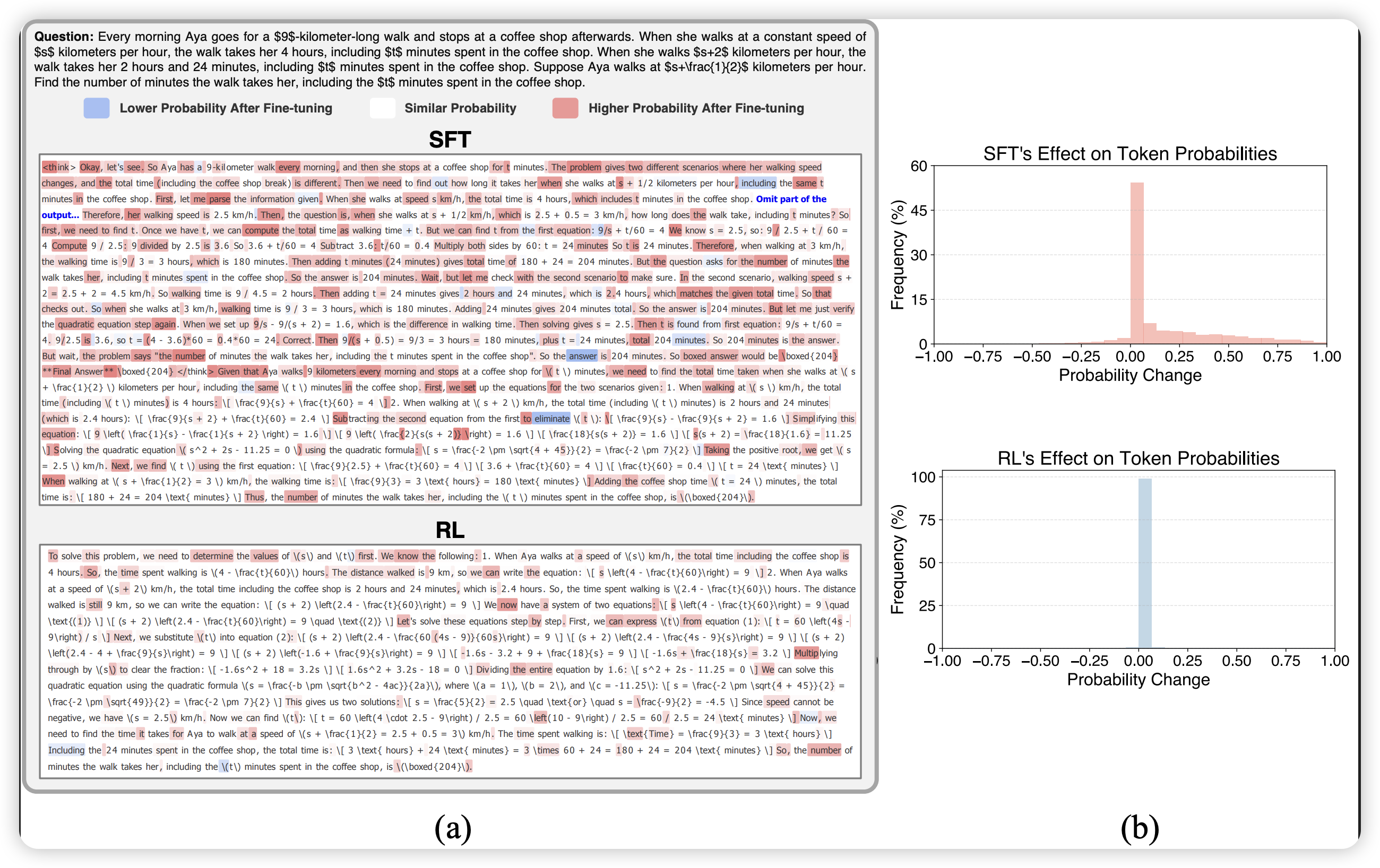
【速读摘要】:本文系统研究了语言模型训练中"中训练"(Midtraining)阶段的作用——即在预训练和后训练之间插入一个混合专业数据的中间阶段。研究发现:1)Midtraining对代码、数学等与通用预训练数据差异较大的领域效果最显著;2)Midtraining能有效减少后训练阶段的灾难性遗忘;3)专业数据引入的时机和混合比例存在强交互作用——早期引入支持高混合比例,晚期引入则需保守混合;4)在减少遗忘方面,Midtraining始终优于纯持续预训练。
【论文链接】:arXiv:2510.14865 (ICML 2026)
【机构信息】:Carnegie Mellon University - Language Technologies Institute
【开源链接】:https://anonymous.4open.science/r/midtraining-E5D8/
【关键词】:midtraining, pretraining, finetuning, domain adaptation, catastrophic forgetting, distributional bridging, curriculum learning
1. 背景与核心洞察 (The Core Insight)
当前大语言模型的训练流程通常包含多个阶段:大规模通用数据预训练 → 后训练(监督微调/指令微调)→ 强化学习对齐。然而,业界广泛采用了一种介于预训练和后训练之间的**中间训练(Midtraining)**策略:在预训练中后期引入专业化数据(代码、数学、指令格式化数据等),与通用数据混合训练数B tokens,再进行后训练。该策略被LLaMA 3、Olmo、MiniCPM、Chameleon等模型采用,但一直缺乏系统性的机制研究。
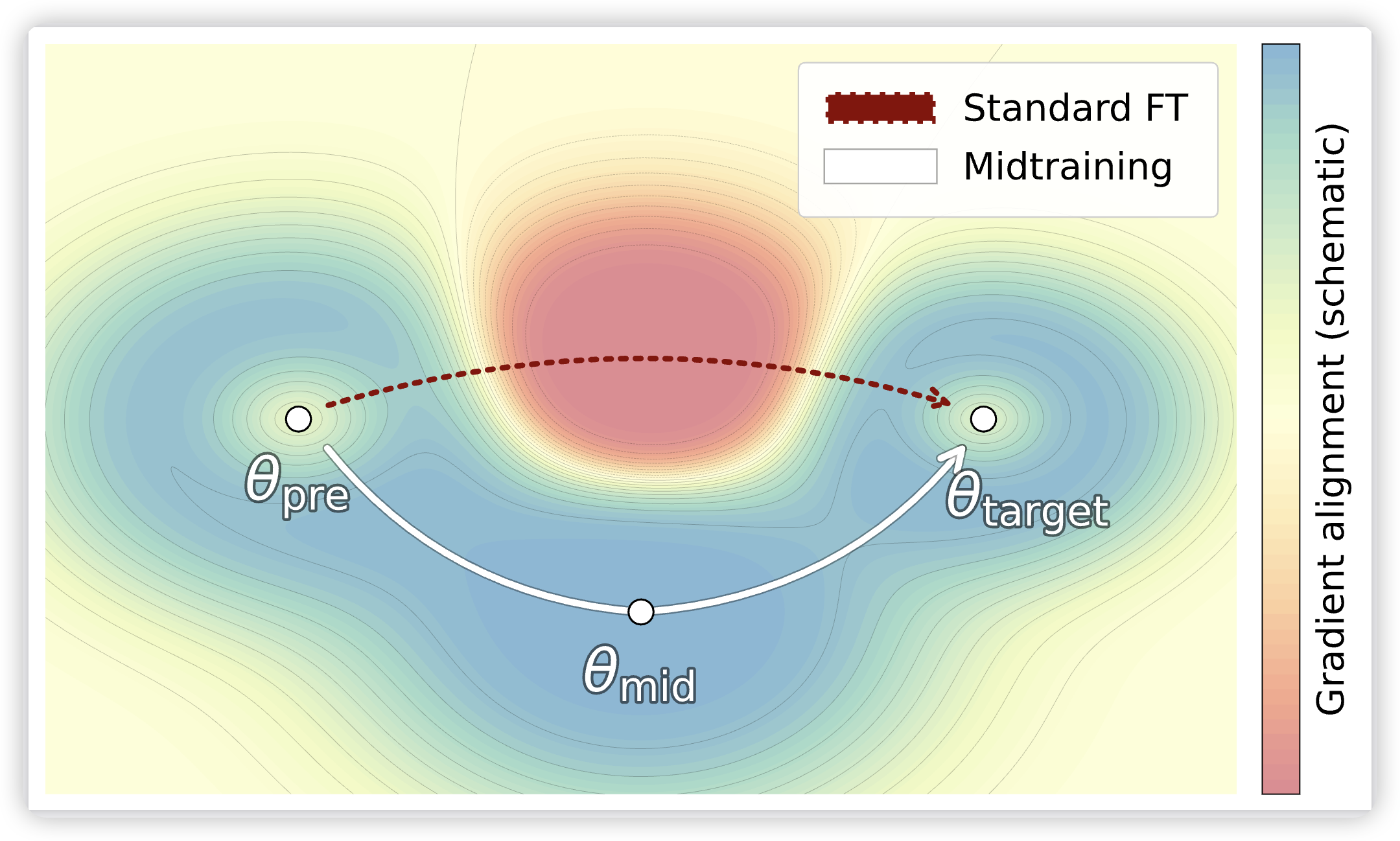
本文的核心洞察是:Midtraining的本质是"分布式桥接"(Distributional Bridging)——它不是简单地让模型"记住"目标领域的数据,而是通过在预训练和后训练之间插入一个过渡分布,降低两个阶段之间的梯度冲突,使模型能够以更平滑的优化路径从通用分布迁移到专业分布。
作者从优化几何的角度给出了直观解释:如图1所示,预训练阶段的梯度场与后训练目标存在冲突区域,标准的预训练→SFT路径(红色)会穿过高冲突区域;而加入Midtraining后(白色路径),模型参数被引导到更靠近目标分布的区域,从而在后续后训练中能更高效地适应目标,同时减少对预训练知识的遗忘。
2. 技术方案深度拆解 (The “How”)
2.1 训练流程定义
作者将语言模型训练定义为一系列阶段的序列 ,其中:
- 预训练(Pretraining):使用大规模通用语料 (如C4),目标是最小化
- 中间训练(Midtraining):插入于预训练和后训练之间,数据为通用数据与专业数据的混合 ,满足
- 后训练(Posttraining/SFT):在目标数据集 上进行监督微调
2.2 理论分析框架
作者提供了简化的理论分析来说明Midtraining如何同时改善目标域性能和减少遗忘。关键公式推导如下:
对于单步梯度下降,设 ,利用 -平滑性假设:
累积 步后的遗忘量:
关键结论:遗忘量由两部分组成:
- 梯度冲突项 :当预训练和后训练梯度方向一致时为负(有助于减少遗忘),冲突时为正
- 梯度幅度项 :总是非负,对遗忘有正向贡献
Midtraining的作用是改变初始化 ,使后训练的梯度 与预训练梯度 更加对齐,同时降低梯度幅度。
2.3 关键实验变量
| 参数 | 设置 |
|---|---|
| 模型规模 | 70M, 160M, 410M, 1B (Pythia架构) |
| 预训练数据 | C4 (128B tokens, ~61k steps) |
| Midtraining数据 | Starcoder(代码)、Math(数学)、FLAN(指令)、KnowledgeQA(知识QA)、DCLM(高质量网页) |
| 后训练数据 | GSM8k(数学)、Pycode(代码)、SciQ(科学QA)、LIMA(指令) |
| Midtraining插入点 | 6k/20k/40k steps (视数据可用性) |
| 混合比例 | 5%-20%专业数据 + C4 |
2.4 分布式接近度(Proximity Advantage)
为量化Midtraining数据的有效性,作者定义了接近度优势:
其中 是基于模型tokenizer计算的unigram token统计的token级接近度。正值表示Midtraining混合数据 比纯C4更接近目标分布 。
3. 验证与实验分析 (Evidence & Analysis)
3.1 核心发现一:领域特异性效益
实验结论:Midtraining的利益高度依赖于目标领域与预训练数据的差异程度。
| 模型规模 | 代码任务 (Pycode) | 数学任务 (GSM8K) |
|---|---|---|
| 70M | Starcoder混合: 2.504 vs 基线 2.656 (↓5.7%) | Math混合: 1.339 vs 基线 1.384 (↓3.3%) |
| 160M | Starcoder混合: 2.134 vs 基线 2.314 (↓7.8%) | Math混合: 1.114 vs 基线 1.163 (↓4.2%) |
| 1B | Starcoder混合: 1.888 vs 基线 2.174 (↓13.2%) | Math混合: 0.851 vs 基线 0.942 (↓9.7%) |
关键观察:
- 代码和数学领域的Midtraining收益最大(与C4通用网页数据差异最大)
- FLAN指令数据、KnowledgeQA、DCLM等通用性较强的混合数据对下游任务几乎无提升
- 不匹配的Midtraining(如代码数据→数学任务)无效益
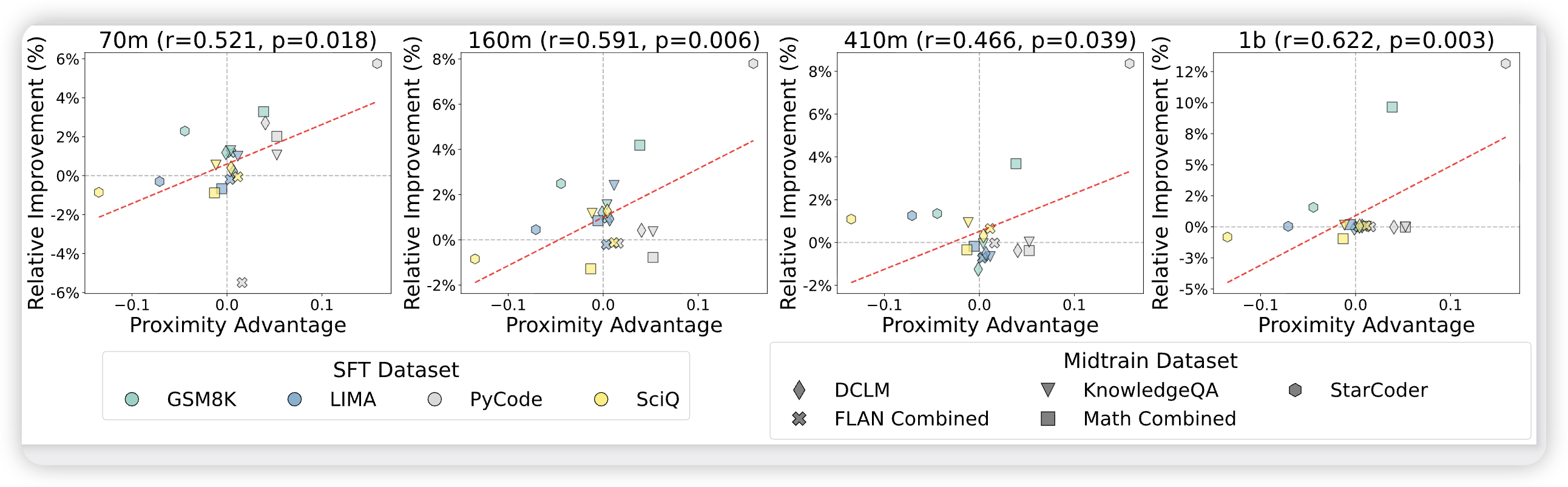
3.2 核心发现二:接近度优势与性能相关性
作者发现接近度优势与下游性能提升呈强正相关:
- 70M模型:
- 更大模型同样保持显著相关性
这验证了分布式桥接假设:Midtraining数据越接近目标分布,桥接效果越好。
3.3 核心发现三:Midtraining vs 持续预训练
实验设置:比较Midtraining(混合通用数据)与持续预训练(完全切换到专业数据,混合权重=0)
| 设置 | 代码任务 SFT loss | 代码任务 C4 loss (遗忘) |
|---|---|---|
| 70M基线 | 2.656 | 6.152 |
| Midtraining (Starcoder 20%) | 2.504 | 6.032 |
| 持续预训练 (Starcoder 100%) | 2.530 | 6.109 |
结论:保持通用数据混合的Midtraining在两个指标上同时优于纯持续预训练——不仅目标域损失更低,遗忘也更少。
3.4 核心发现四:时机与混合权重的交互作用
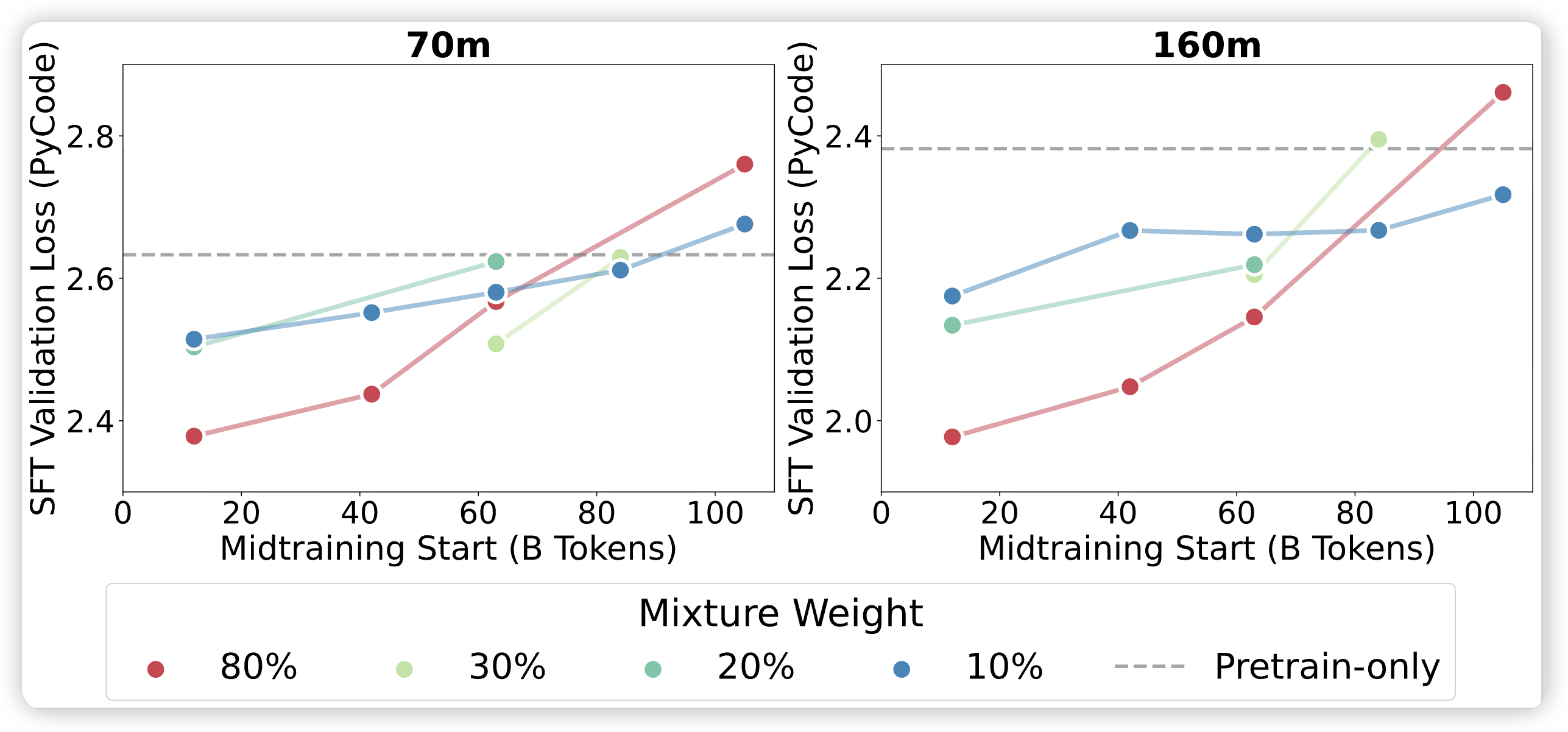
实验在70M和160M模型上系统变化:
- Midtraining开始时间:12B / 63B / 105B tokens
- 专业数据混合比例:10% / 20% / 30% / 80%
关键发现:
- 强交互效应:最佳混合比例取决于引入时机
- 早期引入 + 高混合比例:效果最佳(12B tokens + 80% = 最佳代码loss)
- 晚期引入 + 高混合比例:效果最差(105B tokens + 80% 显著劣于 10%)
- 不可补偿性:后期引入无法通过增加混合比例来弥补——"可塑性窗口"一旦错过无法重建
这暗示存在一个关键可塑性窗口:模型在预训练早期对分布偏移的适应能力更强,后期引入高比例专业数据会导致"刚性"无法有效学习。
3.5 核心发现五:表征变化分析
作者使用线性Centered Kernel Alignment (CKA) 分析模型表征变化:
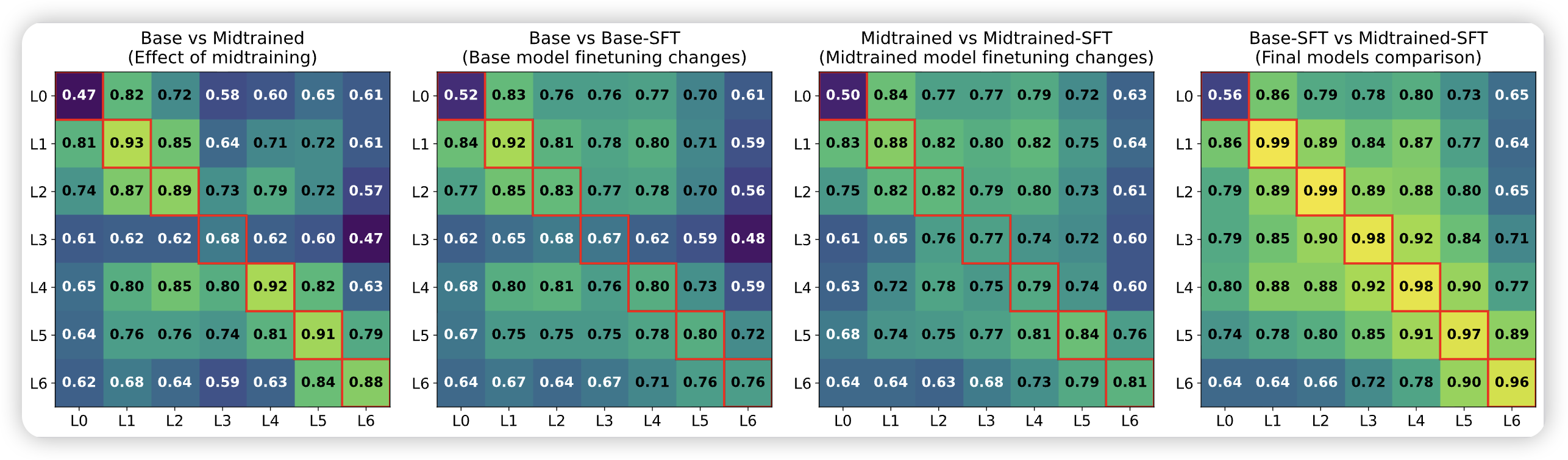
发现:
- Midtraining模型在下游SFT后,最后一层的变化幅度更小
- 无论是否经过Midtraining,最终微调后的模型表征高度相似
- 意味着Midtraining的作用是提供更好的初始化,使模型能以更小的参数位移达到相同的最终状态
4. 局限性与落地思考 (Critical Review)
4.1 潜在短板
- 规模泛化性存疑:实验仅在70M-1B模型上完成,未在更大模型(7B+)验证
- 领域覆盖有限:仅覆盖代码、数学、指令、知识QA、高质量网页,未测试医学、音乐等专业领域
- RL后训练未涉及:仅研究SFT后训练,未探索Midtraining对RLHF/PPO的影响
- 接近度指标局限:仅用token级unigram统计,未考虑语义层面接近度
- 可塑性窗口理论:窗口具体大小与模型规模的关系未明确
4.2 工程化建议
基于本文发现,对模型训练实践的建议:
- 领域选择:将Midtraining重点用于与通用预训练差异大的领域(代码、数学、科学推理)
- 时机优先:在预训练流程中尽早引入专业数据(而非等到训练末期"降温"阶段)
- 混合策略:早期可使用较高混合比例(20%-80%),晚期需保守(10%-20%)
- 优先于持续预训练:即使目标是领域适应,也应选择Midtraining而非纯持续预训练
- 评估遗忘:同时监控目标域损失和通用域损失,两者通常可兼得
5. 总结与启示 (The Verdict)
对研发的启示
- Midtraining是分布式桥接,非简单的"练到目标数据":它的核心价值在于降低预训练-后训练的梯度冲突,而非让模型提前见过目标数据
- 可塑性窗口是真实存在的:预训练早期对分布偏移的适应能力更强,这可能与表示的可塑性有关
- 领域差异决定效果上限:与预训练数据越远的领域,Midtraining收益越大
- 遗忘与适应可以兼得:与直觉相反,保持通用数据混合不仅不会"稀释"专业学习,反而同时改善目标域性能和通用能力保持
待澄清疑点
- 更大规模的验证:1B以上的模型是否保持相同规律?
- 多阶段Midtraining:多个连续的Midtraining阶段是否比单阶段更有效?
- RL后训练的交互:Midtraining对RLHF/PPO的影响是否与SFT相同?
- 理论保证:可塑性窗口的具体数学刻画是什么?
- 最优混合调度:是否可以设计动态混合比例schedule而非固定值?