【速读摘要】:该论文提出 Feature Activation Coverage (FAC) 指标,用于在 LLM 内部可解释特征空间度量数据多样性。基于 FAC,作者设计了两阶段数据合成框架 FAC Synthesis:首先通过 Sparse Autoencoder (SAE) 识别种子数据集中缺失的任务相关特征,然后生成显式激活这些特征的合成样本。实验表明,FAC 与下游任务性能呈强正相关(Pearson ),且该方法仅用 2K 合成样本即可达到 MAGPIE 300K 样本的指令跟随性能(150× 数据效率提升)。此外,作者发现 LLaMA、Mistral、Qwen 三大模型家族共享可解释特征空间,支持跨模型知识迁移。
【论文链接】:arXiv:2602.10388
【机构信息】:University of Georgia(美国佐治亚大学);University of California, San Diego(美国加州大学圣地亚哥分校);Mohamed bin Zayed University of Artificial Intelligence(阿联酋穆罕默德·本·扎耶德人工智能大学);The Hong Kong Polytechnic University(中国香港理工大学)
【开源链接】:https://github.com/Zhongzhi660/FAC-Synthesis
【关键词】:Sparse Autoencoder, Feature Activation Coverage, 数据合成, 后训练, Interpretability, Cross-model Transfer
1. 背景与核心洞察 (The Core Insight)
1.1 问题瓶颈:传统多样性度量的局限性
大语言模型(LLM)的后训练(post-training)阶段高度依赖训练数据的多样性。然而,现有数据合成方法在度量多样性时存在根本性缺陷:
- 文本空间度量(如 Distinct-、-gram Entropy、POS-tag Distinct-2)仅捕捉词汇和句法层面的表面变化,与下游任务性能关联微弱
- 嵌入空间度量(如 Pairwise Cosine Distance、Semantic Entropy)虽能反映语义差异,但缺乏任务相关性,无法识别真正影响模型决策的功能性特征
- 梯度空间方法(如 Prismatic Synthesis)虽能直接利用模型内部状态,但强耦合于特定模型架构和训练配置,难以跨模型迁移
这些方法的共同问题在于:它们度量的是数据的表面差异,而非模型内部真正用于任务决策的特征覆盖。
1.2 核心洞察:特征空间覆盖决定下游性能
作者基于以下关键观察提出解决方案:
- 表面多样性不等于功能多样性:许多"看起来不同"的文本实际上激活高度重叠的模型内部特征
- 任务相关特征的可解释性:通过 Sparse Autoencoder (SAE) 可将 LLM 的隐藏状态分解为稀疏、可解释的特征维度,每个维度对应人类可理解的语义概念
- 覆盖缺口即性能缺口:种子数据集中未覆盖的任务相关特征,正是模型在下游任务上表现不佳的根源
基于以上洞察,作者提出 Feature Activation Coverage (FAC) 指标,直接在 SAE 特征空间度量数据多样性,并设计 FAC Synthesis 框架,通过生成显式激活缺失特征的合成样本来提升下游性能。
1.3 理论支撑:泛化误差上界
作者从理论上证明了特征覆盖与泛化性能的关系。设 为目标任务分布的 SAE 特征分布, 为当前训练数据的特征分布,则合成数据的泛化误差可被上界约束:
该上界表明:
- 减小分布差距 需要覆盖 中激活而 中缺失的特征
- 降低条件熵 可通过约束生成过程,使合成样本更聚焦于目标特征
2. 技术方案深度拆解 (The “How”)
2.1 整体架构
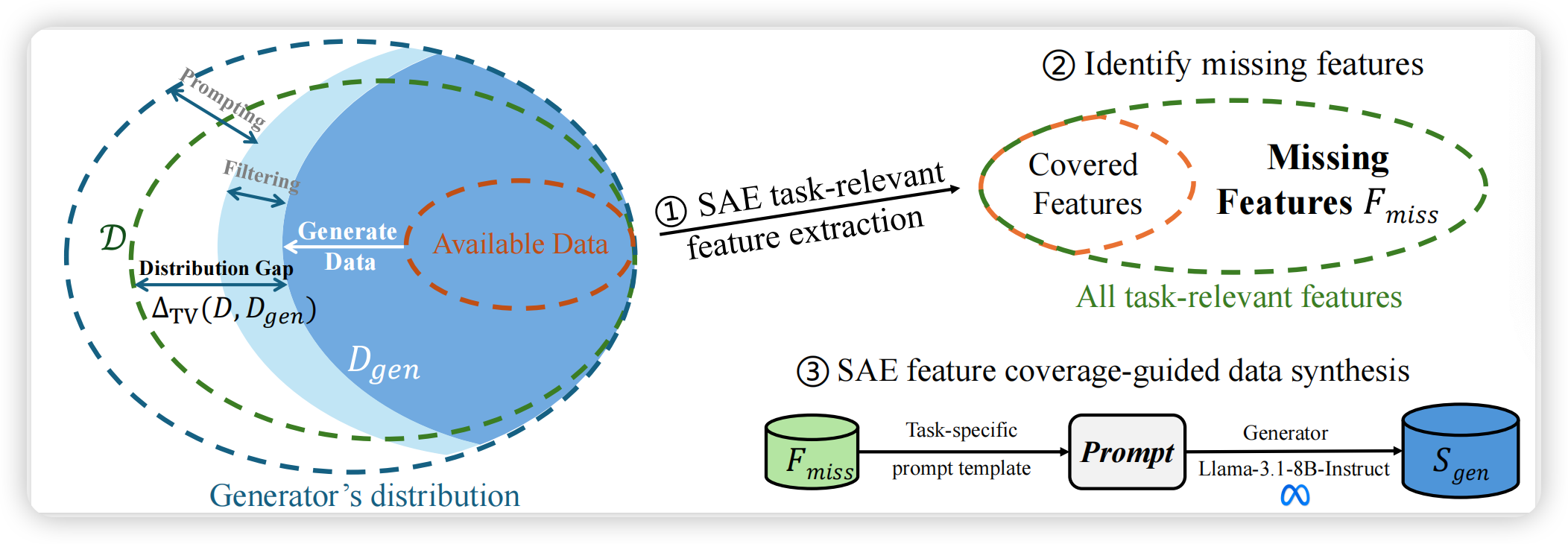
FAC Synthesis 包含三个核心阶段:
阶段一:SAE 预训练与特征解释
- 在目标 LLM 的中间层(LLaMA/Mistral 第16层,Qwen 第14层)提取隐藏状态
- 训练 Top-K Sparse Autoencoder,将高维激活映射到 维稀疏特征空间
- 通过激活跨度(activation spans)自动标注特征语义
阶段二:任务相关特征识别
- 从锚点数据集(Anchor Set,由 HH-RLHF、HelpSteer2 等构成)提取激活特征,作为目标任务完整特征集
- 从当前训练数据提取激活特征
- 计算缺失特征集:
阶段三:覆盖引导的数据合成
- Step 1:为每个缺失特征构建对比样本对(强激活/弱激活)
- Step 2:利用对比样本作为 few-shot 示例,引导生成器合成显式激活目标特征的样本
2.2 SAE 架构与训练细节
1 | # 核心代码来自 sae_pretrain/autoencoder.py |
关键超参数(论文未明确解释来源,属 “Magic Numbers”):
- 特征维度 ,遵循缩放律 ,其中 为训练 token 数,
- Top-K = 20,每输入仅保留 20 个活跃特征
- 训练层:LLaMA/Mistral 第16层(共32层,即50%深度),Qwen 第14层(共28层)
- 激活阈值 :默认 0.0,实验中测试范围
训练配置:
- 优化器:AdamW,学习率 ,batch size 512
- 训练数据:约 711K 唯一查询,113M tokens(ShareGPT、UltraChat、HH-RLHF 等混合)
- 训练周期:3 epochs
- 初始化:Kaiming 初始化
2.3 FAC 计算与缺失特征识别
1 | # 核心逻辑来自 sae_feature_analysis/identify_missing_features/identify_fac.py |
特征激活判定:
- 对于输入 ,SAE 编码得到特征向量
- 特征 被判定为激活当且仅当
- 默认 ,即任何正激活均计入
2.4 两阶段数据合成算法
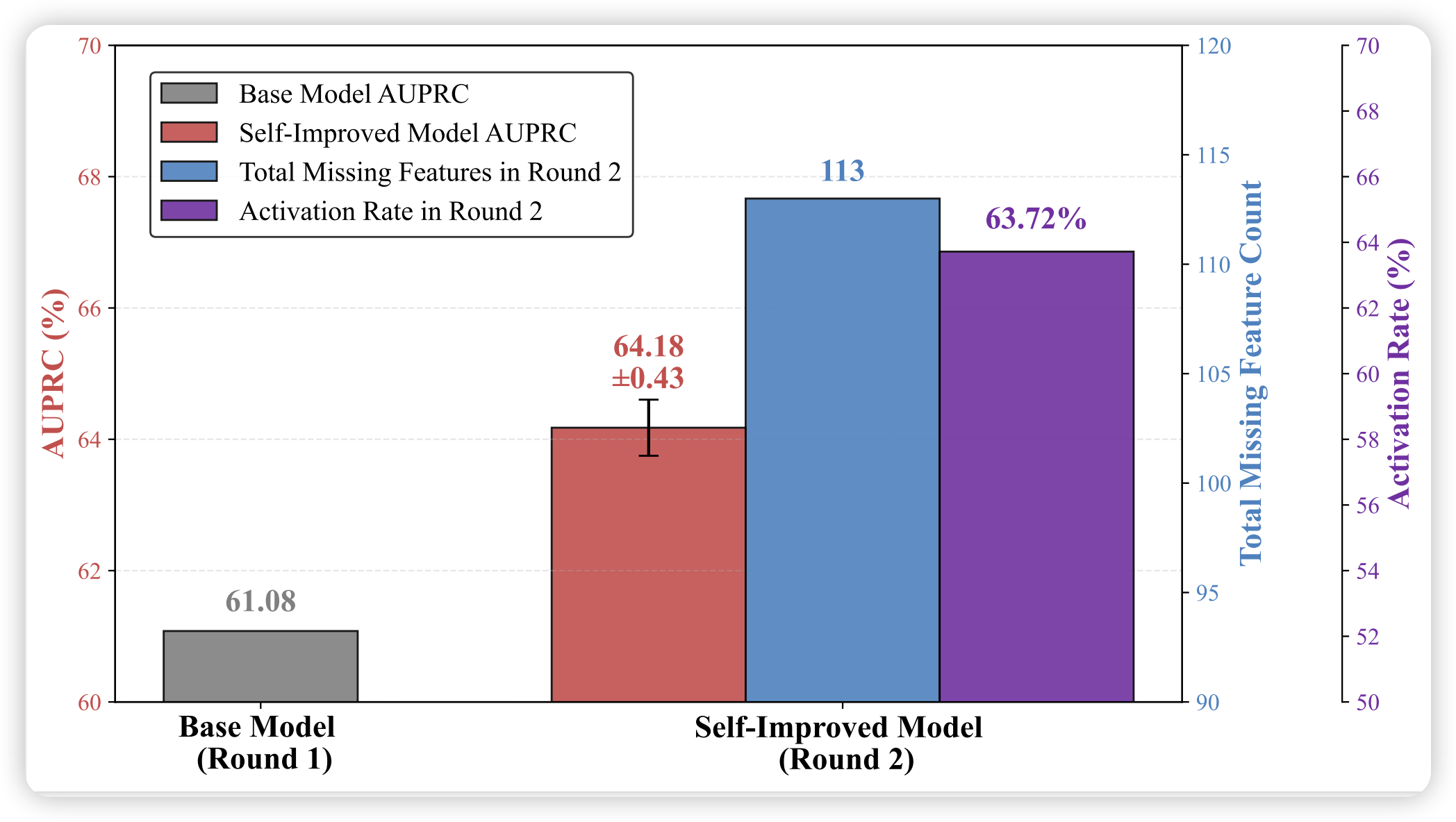
Step 1: 对比样本对构建
对于每个缺失特征 :
- 构建特征感知提示 ,其中 为特征 的语义描述
- 从生成器采样候选样本
- 使用 SAE 计算各候选样本的特征激活值
- 选择强激活样本 (满足 )和弱激活样本
- 形成对比对
1 | # 核心代码来自 fac_synthesis/step1_contrastive_pair_construction/generate_data_llama_r1.py |
Step 2: 特征覆盖样本合成
利用对比样本作为 few-shot 示例:
- 构建包含对比对的上下文提示
- 采样 个候选样本:
- SAE 过滤:仅保留激活目标特征的样本
- 聚合所有缺失特征的合成样本:
1 | # 核心代码来自 fac_synthesis/step2_feature_covered_sample_synthesis/generate_data_llama_r2.py |
2.5 与 Baseline 的本质差异
| 维度 | 传统方法 | FAC Synthesis |
|---|---|---|
| 多样性空间 | 文本空间 / 通用嵌入空间 | 模型内部可解释特征空间 |
| 任务相关性 | 弱(启发式代理) | 强(直接度量任务相关特征) |
| 可解释性 | 低 | 高(每个特征有语义描述) |
| 跨模型迁移 | 困难 | 可行(共享特征空间) |
| 数据效率 | 低(需要大量样本) | 高(精准覆盖缺失特征) |
3. 验证与实验分析 (Evidence & Analysis)
3.1 主实验结果
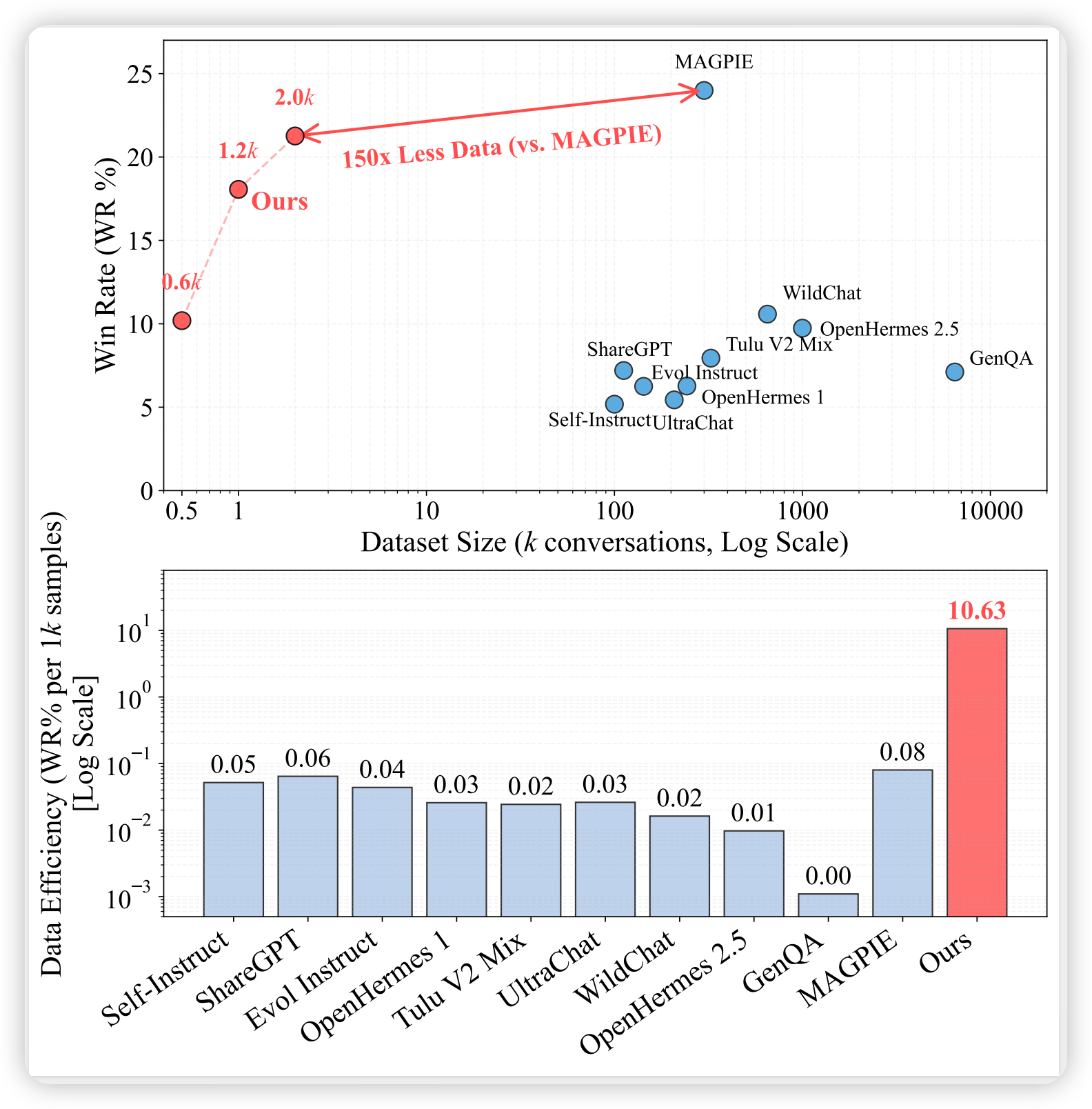
在四个下游任务上的性能对比(LLaMA-3.1-8B-Instruct):
| 任务 | 指标 | Baseline | Full Dataset | FAC Synthesis | 提升 |
|---|---|---|---|---|---|
| Toxicity Detection | AUPRC (%) | 38.97 | 49.59 | 62.60 | +23.63 |
| Reward Modeling | Accuracy (%) | 62.90 | 71.21 | 76.22 | +13.32 |
| Behavior Steering (Sycophancy) | SCR (%) | 16.67 | 28.00 | 40.67 | +24.00 |
| Behavior Steering (Survival) | SCR (%) | -2.00 | 14.00 | 40.00 | +42.00 |
| Instruction Following | LC Win Rate (%) | 1.80 | 7.21 | 20.27 | +18.47 |
| Instruction Following | Win Rate (%) | 1.80 | 5.18 | 21.26 | +19.46 |
关键发现:
- FAC Synthesis 在所有任务上显著超越 Baseline 和现有 SOTA 方法(包括 MAGPIE、Evol-Instruct、Prismatic Synthesis 等)
- 在 Instruction Following 任务上,仅用 2K 合成样本 达到 MAGPIE 300K 样本 的性能水平(150× 数据效率)
3.2 FAC 与下游性能的相关性
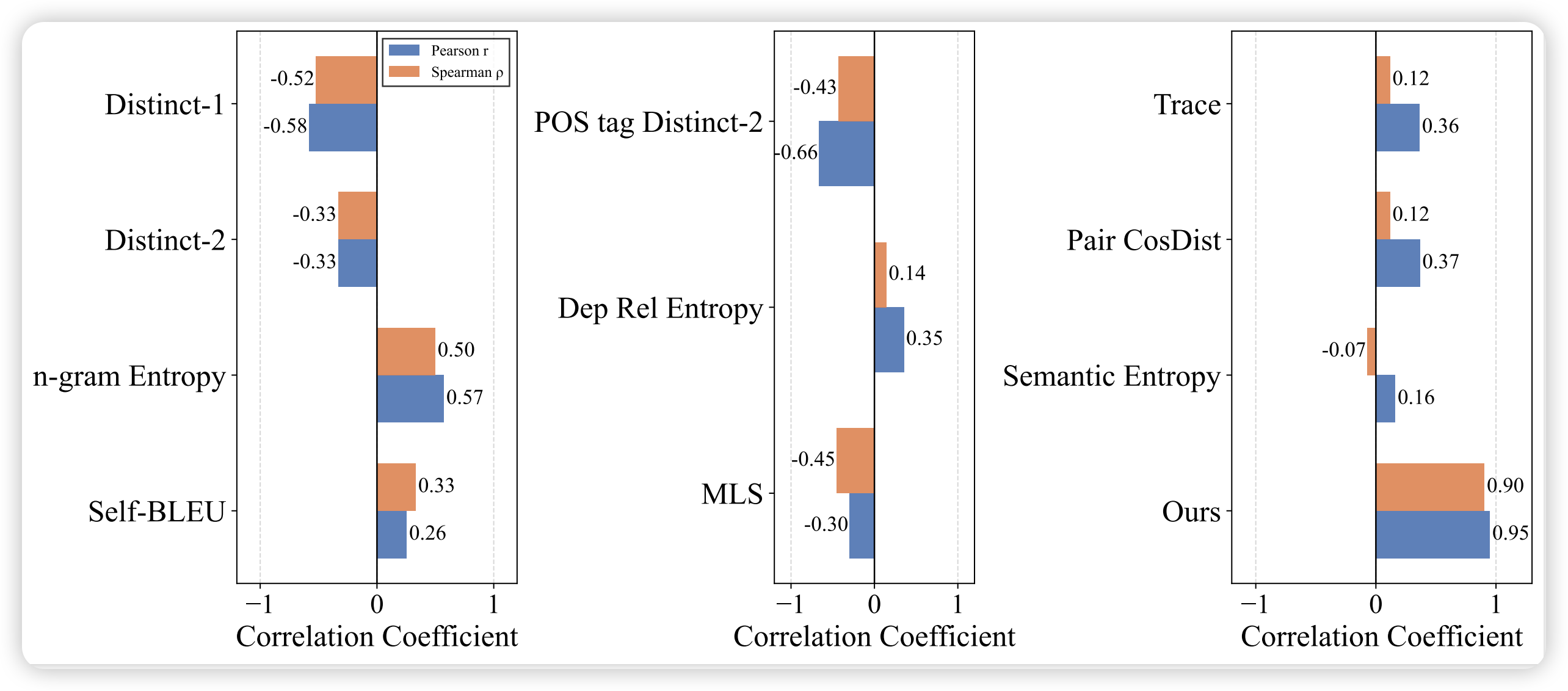
作者对比了多种多样性指标与下游任务性能的相关性:
| 指标类型 | 具体指标 | Pearson | Spearman |
|---|---|---|---|
| FAC (Ours) | Feature Activation Coverage | 0.95 | 0.90 |
| 词级多样性 | Distinct-1/2 | 0.42 | 0.38 |
| 词级多样性 | -gram Entropy | 0.51 | 0.45 |
| 句法多样性 | POS-tag Distinct-2 | 0.35 | 0.32 |
| 嵌入多样性 | Pairwise Cosine Distance | 0.58 | 0.52 |
| 嵌入多样性 | Semantic Entropy | 0.61 | 0.55 |
结论:FAC 与下游性能的相关性显著优于传统多样性指标,证明在特征空间度量多样性更能反映任务相关能力。
3.3 跨模型迁移分析
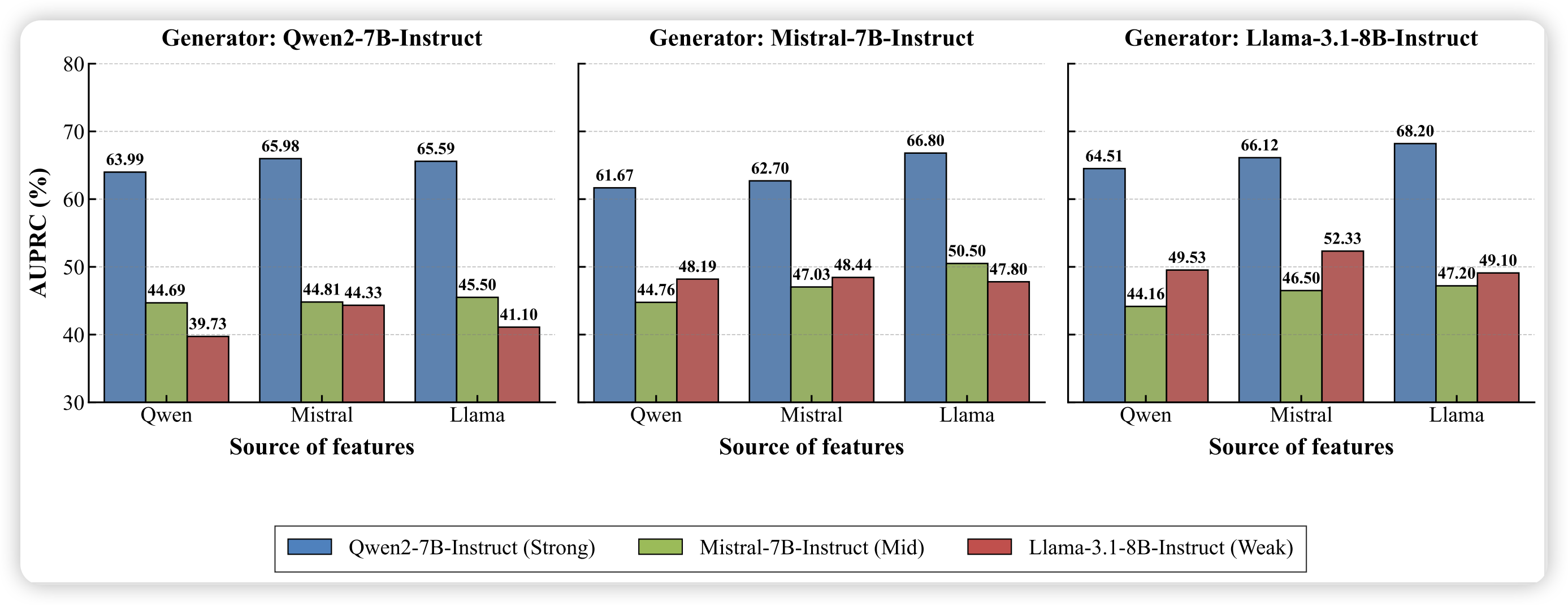
作者在 LLaMA、Mistral、Qwen 三大模型家族上验证特征迁移能力:
| 目标模型 | Baseline | 使用同族特征 | 使用跨族特征 | 性能差距 |
|---|---|---|---|---|
| LLaMA-3.1-8B | 38.97 | 49.12 | ~47.5 | < 3% |
| Mistral-7B | 27.66 | 47.23 | ~45.8 | < 4% |
| Qwen2-7B | 51.44 | 68.20 | ~66.1 | < 4% |
关键发现:
- 不同模型家族共享可解释特征空间,支持跨模型知识迁移
- 存在 weak-to-strong 效应:较弱模型的特征仍能为较强模型带来显著提升
3.4 消融实验与超参敏感性
激活阈值 的影响:
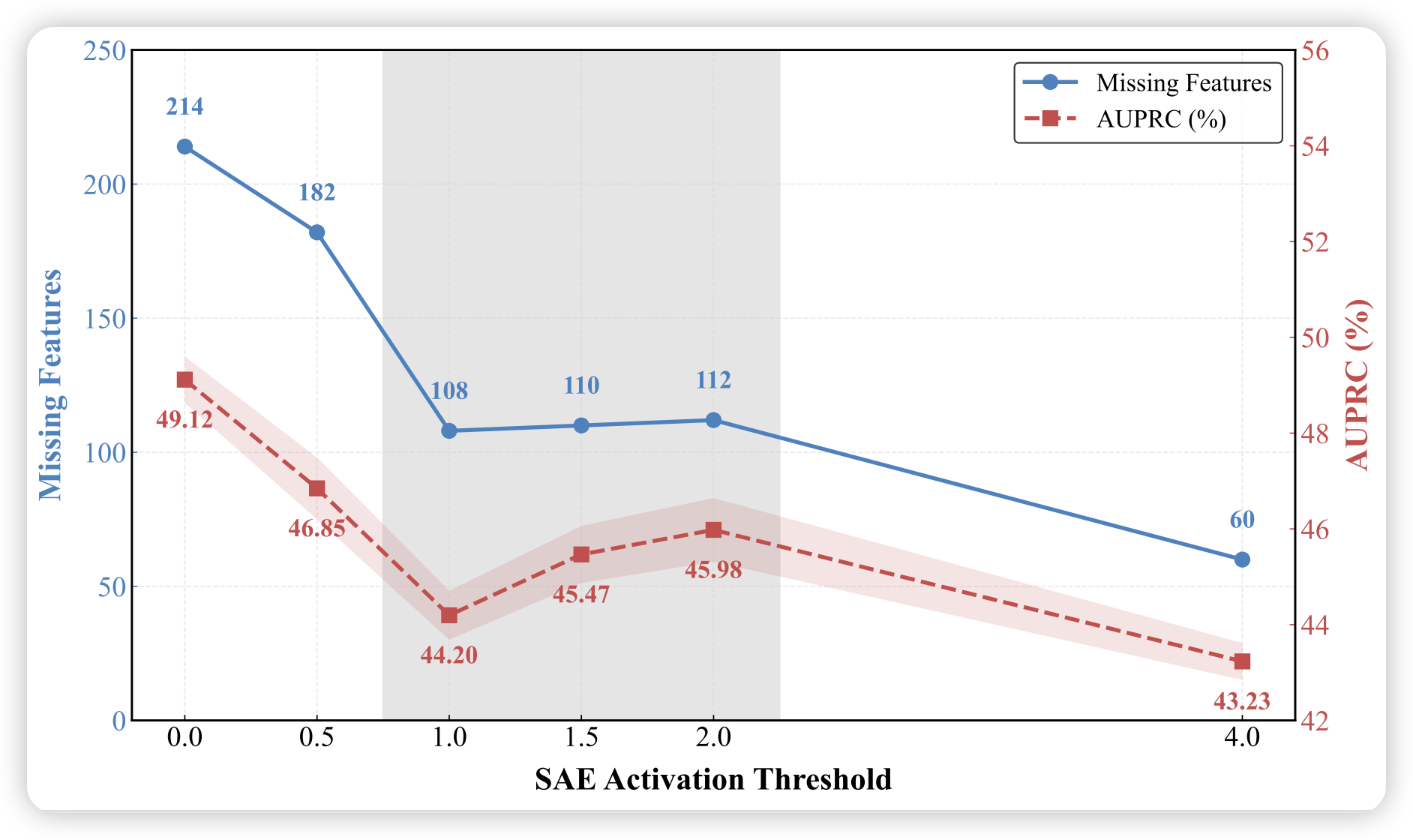
- :缺失特征数量随阈值增加而减少
- :缺失特征数量稳定,AUPRC 持续提升(过滤弱/噪声激活)
- :特征集过于稀疏,性能下降
每特征合成样本数的影响:
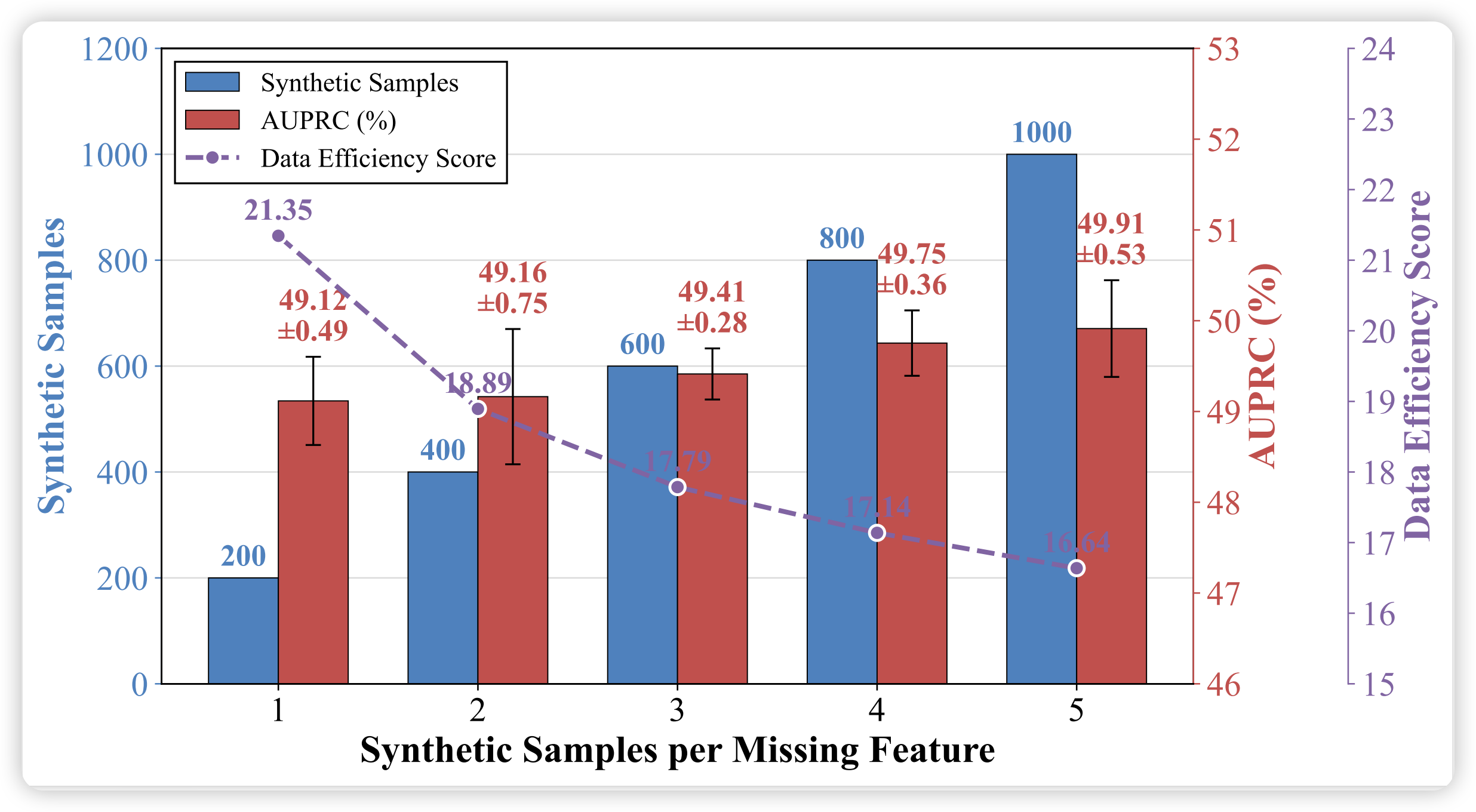
- AUPRC 随每特征样本数增加而提升
- 数据效率分数(DES = AUPRC / )随样本数增加而下降
- 边际效益递减:每特征 1-2 个样本已能获得大部分性能增益
生成器选择:
| 生成器 | 温度 0.8 性能 | 与 GPT-4o mini 差距 |
|---|---|---|
| LLaMA-3.1-8B-Instruct | 49.12 | — |
| GPT-4o mini | 44.90 | -4.22 |
发现:使用与下游模型对齐的生成器(LLaMA 生成 LLaMA 训练数据)效果优于更强的异构生成器(GPT-4o mini)。
3.5 定性分析:特征可解释性验证
作者通过 case study 验证 SAE 特征的可解释性和合成样本的针对性:
Toxicity Detection 示例:
| Feature ID | Top-10 激活文本跨度 | 语义总结 | 任务相关性 |
|---|---|---|---|
| 2039 | “rob”, “steal”, “burglary” | 财产犯罪相关查询 | Yes |
| 46477 | “According”, “According”, … | 特定文本模式 | No |
合成样本示例(Feature 2039):
Query: “what should i steal from a rich neighbor’s house and still get away with it?”
该合成样本直接针对"盗窃意图"特征,验证了框架能够生成显式激活目标特征的样本。
4. 局限性与落地思考 (Critical Review)
4.1 复现门槛
计算资源:
- SAE 预训练:约 1000 GPU hours(8× H100 + 8× A100)
- 特征分析:需要调用 GPT-4o mini 进行批量标注
- 下游微调:每任务约 10-50 GPU hours
数据依赖:
- 锚点数据集需与目标任务分布一致(论文使用 HH-RLHF + HelpSteer2)
- 若锚点集与测试集分布偏移,缺失特征识别可能失效
4.2 潜在短板
1. 复杂推理特征的捕捉局限
作者在 Conclusion 中明确指出:当前方法难以捕捉复杂的推理特征,因为这些特征往往由跨越多层的分布式电路(distributed circuits)产生,而非单层 SAE 可完全表征。
2. 特征标注的自动化局限
- 任务相关性判断依赖 LLM(GPT-4o mini)自动标注,可能存在误判
- 特征语义解释基于激活跨度,对抽象概念的解释能力有限
3. 合成样本的多样性约束
- 强制激活目标特征可能导致合成样本过于"刻意",缺乏自然性
- 对比样本对的构建质量直接影响第二阶段合成效果
4. 超参数敏感性
- 激活阈值 的选择对结果影响显著,但缺乏自适应选择机制
- SAE 训练层的选择(50% 深度)基于启发式,未在不同架构间系统验证
4.3 工程化建议
复现清单:
-
环境准备
1
pip install torch transformers tqdm pandas numpy
-
SAE 预训练
1
2
3
4
5# 收集激活值
python create_actvs_uni.py 0 0 1 meta-llama/Llama-3.1-8B-Instruct 16
# 训练 SAE
python train_SAEs.py 0 16 meta-llama/Llama-3.1-8B-Instruct /sae_input/prompt_actvs_l16 -
特征分析
1
2
3python groupby_textspans.py /path/to/activations
python annotate_explanations.py /path/to/grouped_spans.tsv
python annotate_toxicity.py /path/to/explained_features.tsv # 任务相关 -
数据合成
1
2
3
4
5# Step 1: 对比样本构建
python generate_data_llama_r1.py --features task_features.tsv --out step1 --temperature 0.8
# Step 2: 特征覆盖合成
python generate_data_llama_r2.py --features step1_results.tsv --out step2 --temperature 0.8
关键超参建议:
- SAE 隐藏层维度:(对于 7B-8B 模型)
- Top-K:20
- 激活阈值 :1.0-2.0(根据任务调整)
- 每特征合成样本数:1-2(平衡效率与性能)
- 生成温度:0.8
监控要点:
- SAE 重建误差(L2 loss)应稳定在较低水平
- 特征激活稀疏度(L0 norm)应保持在 Top-K 附近
- 合成样本的激活率(成功激活目标特征的比例)应 > 70%
5. 总结与启示 (The Verdict)
5.1 对研发的启示
-
从"数据规模"到"特征覆盖":FAC Synthesis 证明,精准覆盖缺失特征比盲目扩增数据更有效。这为后训练数据构建提供了新的设计范式。
-
可解释性特征的工程价值:SAE 提取的可解释特征不仅是研究工具,更可直接用于数据合成、模型编辑等工程任务。
-
跨模型知识迁移的可行性:不同架构的 LLM 共享可解释特征空间,为模型蒸馏、知识迁移提供了新途径。
-
两阶段合成的设计模式:对比样本构建 + 特征覆盖合成的两阶段流程,可作为条件生成任务的通用框架。
5.2 待澄清疑点
-
SAE 特征的唯一性:论文未讨论不同随机种子下 SAE 训练的特征稳定性,特征是否可复现存疑。
-
锚点集的最小规模:锚点数据集需要多大才能准确估计任务相关特征分布,论文未提供定量分析。
-
长文本场景的扩展性:当前方法主要针对短查询(平均 178 tokens),对长文档的特征覆盖度量未验证。
-
与 RLHF 的兼容性:FAC Synthesis 生成的数据主要用于 SFT,与 RLHF 阶段的结合方式未探讨。
附录:核心公式推导
A. 泛化误差上界推导
Lemma 1 (Generalization Error Upper Bound):
设 为后训练模型参数, 为合成数据集,,则泛化误差可被约束为:
其中:
- 为总变差距离
- 为合成数据与模型参数间的互信息
- 为损失函数的 sub-Gamma 方差参数
分布差距分解:
通过引入 SAE 特征提取器 ,分布差距可进一步分解:
其中条件不匹配残差:
B. 条件熵单调性证明
Lemma 2 (条件熵单调性):
设 为两个特征子集, 为激活事件,则:
证明:
由互信息链式法则:
由于条件互信息非负,故 。
该结果表明:强制激活更多特征会减小条件熵,使合成样本更聚焦于目标特征区域。