【速读】:该论文提出了一种新的推理质量度量指标——深度思考率(Deep-Thinking Ratio, DTR),通过分析模型内部各层预测分布的收敛行为来量化推理努力程度。研究发现,DTR与任务准确率呈现稳定正相关(平均r=0.683),显著优于基于token长度(r=-0.594)或置信度(r=0.605)的基线方法。基于此,作者设计了Think@n采样策略,在保持或超越标准自一致性性能的同时,将推理成本降低约50%。
【论文链接】:arXiv:2602.13517
【机构信息】:University of Virginia(弗吉尼亚大学);Google(谷歌)
【开源链接】:未开源
1. 背景与核心洞察 (The Core Insight)
当前大语言模型(LLM)的推理能力主要通过生成显式的思维链(Chain-of-Thought, CoT)来实现,业界普遍采用"测试时计算扩展"(test-time compute scaling)策略——即通过生成更长的推理轨迹来提升任务性能。然而,一个日益凸显的问题是:token数量并非推理质量的可靠代理指标。
近期多项研究揭示了令人困惑的现象:
- 逆缩放(Inverse Scaling):更长的推理轨迹有时反而导致性能下降
- 过度思考(Overthinking):模型可能在无关细节上纠缠不休,放大错误启发式
- 倒U型关系:CoT长度与准确率之间存在非单调关系
这些发现暴露了一个根本性问题:我们缺乏一种机制上可解释、与推理质量真正相关的度量标准。传统的基于输出长度的指标将"冗余 verbosity"与"有效思考"混为一谈,而基于置信度的方法又容易受到模型过度自信的影响。
本文的核心洞察源于对Transformer内部计算过程的观察:
当模型对某个token的预测在早期层就稳定下来时,后续层所做的修改相对有限;而当预测分布持续到深层才收敛时,说明该token经历了更充分的内部 deliberation。
基于这一洞察,作者提出了深度思考率(DTR)——通过追踪每个生成token在各层的预测分布演化,识别那些"深层收敛"的token,并将其比例作为推理努力程度的量化指标。
2. 技术方案深度拆解 (The “How”)
2.1 核心机制:从隐藏状态到深度思考判定
DTR的计算流程可分为三个关键步骤:
Step 1: 中间层预测分布提取
对于具有层的自回归语言模型,在生成第个token时,模型产生一系列残差流状态。通过共享的unembedding矩阵,将各层隐藏状态投影到词表空间:
Step 2: 收敛深度量化
计算中间层分布与最终层分布之间的Jensen-Shannon散度(JSD):
其中为Shannon熵。JSD被选用的原因在于其对称性和有界性()。
为确保严格收敛判定,采用累积最小值:
定义收敛深度为首次低于阈值的层数:
Step 3: 深度思考token判定与序列级聚合
设定深度比例,定义深层思考区域:
若,则该token被标记为深度思考token。对于长度为的生成序列,深度思考率定义为:
2.2 算法流程
1 | 算法:计算深度思考率(DTR) |
2.3 可视化:token级别的收敛热力图
论文通过热力图直观展示了不同token的收敛行为差异:
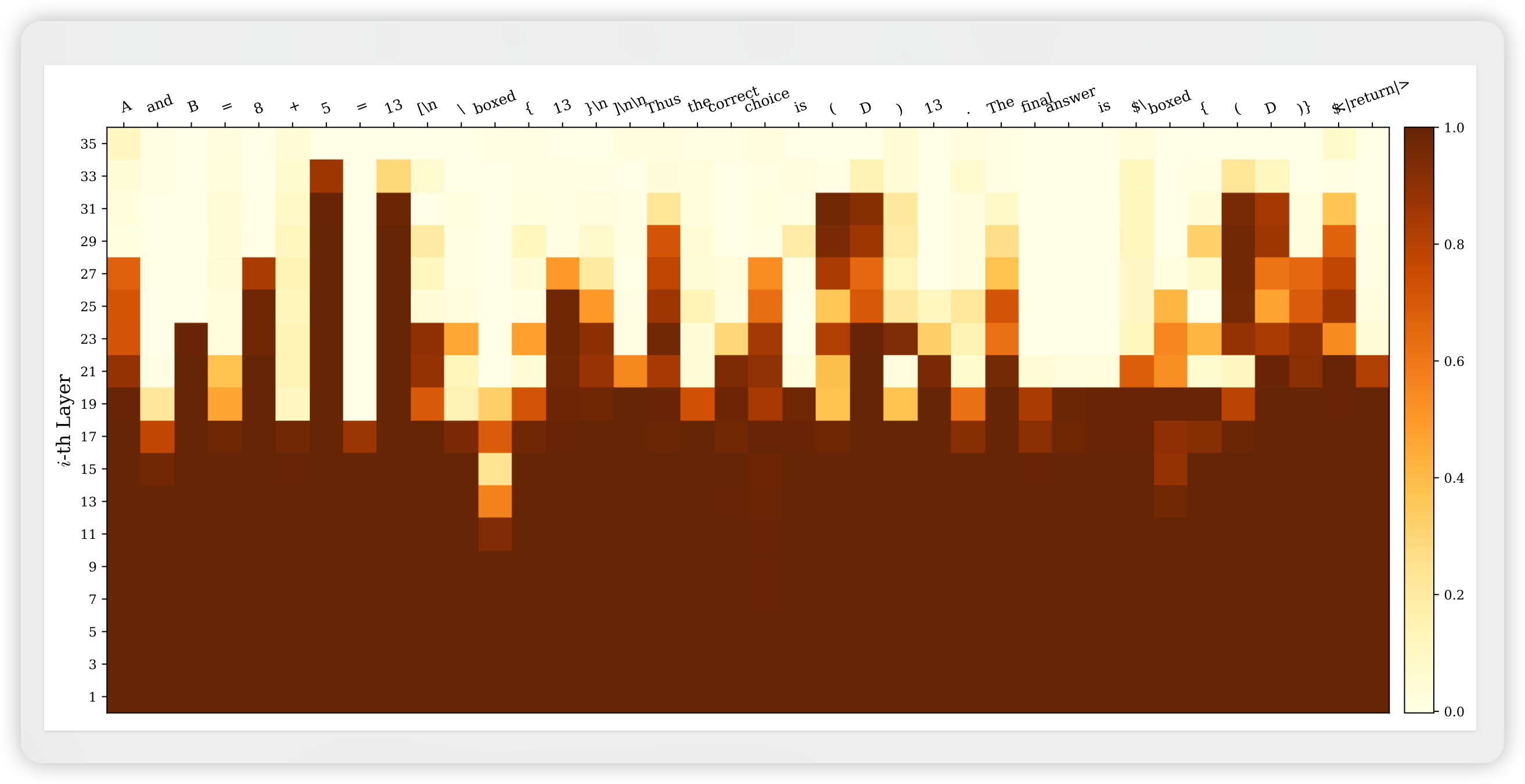
图:GPT-OSS-120B-high在GPQA-D问题上的JSD热力图。横轴为生成token序列,纵轴为层数(1-36层)。颜色越深表示JSD越大(分布差异越大)。
关键观察:
- 功能词/模板词(如"and", “is”, “boxed”):在浅层即收敛(JSD快速趋近于0)
- 运算符后内容(如"+", "="后的token):持续到深层才稳定
- 答案token(如"13", “(D)”):往往在深层才出现并稳定
这一现象支持了DTR的直观解释:需要更多"思考"的token确实在深层经历更剧烈的分布修正。
2.4 与基线的本质差异
| 维度 | Token长度 | 置信度指标 | DTR(本文) |
|---|---|---|---|
| 测量空间 | 输出空间 | 输出分布 | 内部层间演化 |
| 核心假设 | 长=思考多 | 高置信=正确 | 深层收敛=有效思考 |
| 机制可解释性 | 低 | 中 | 高 |
| 与准确率相关性 | 不稳定/负相关 | 中等 | 强正相关 |
DTR的核心创新在于:它不是在输出层面统计token数量,而是在模型内部追踪每个token的"计算轨迹"——即预测分布从初始猜测到最终决策的演化路径。
3. 验证与实验分析 (Evidence & Analysis)
3.1 实验设置
评测模型:
- GPT-OSS系列(20B/120B,low/medium/high推理级别)
- DeepSeek-R1-70B(蒸馏版)
- Qwen3-30B-Thinking
评测任务:
- AIME 2024/2025(数学竞赛)
- HMMT 2025(哈佛-麻省理工数学竞赛)
- GPQA-Diamond(研究生级科学问答)
超参数设置:,,每问题采样25个response。
3.2 核心发现:DTR与准确率的相关性
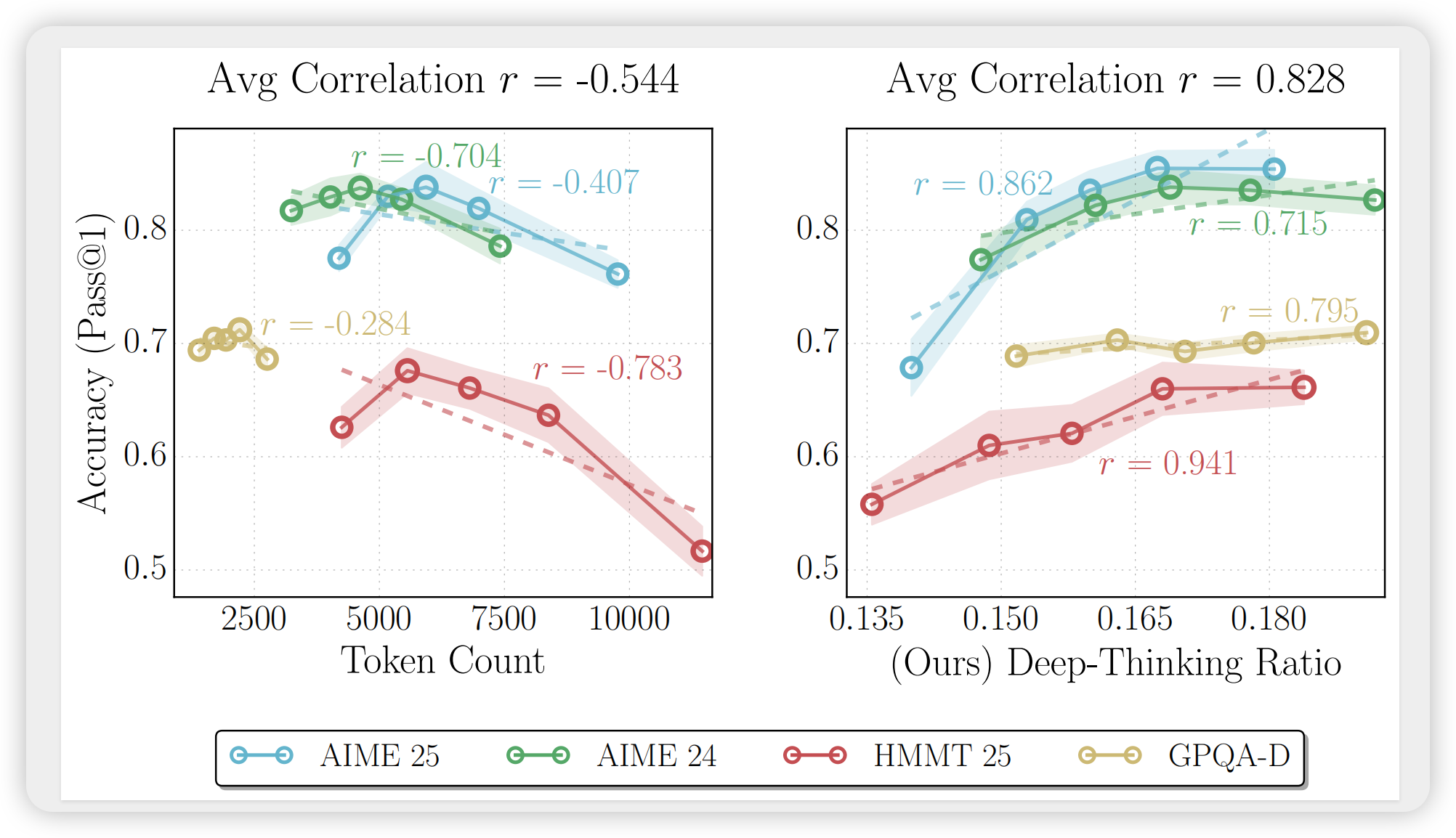
图:GPT-OSS-120B-medium在四个benchmark上的相关性对比。左:token count与准确率呈负相关(平均r=-0.544);右:DTR与准确率呈强正相关(平均r=0.828)。
定量结果(Pearson相关系数):
| 方法 | 平均r | 特点 |
|---|---|---|
| Token Count | -0.594 | 多数情况下负相关,验证"逆缩放"现象 |
| Reverse Token Count | 0.594 | 简单反向,无机制解释力 |
| Log Probability | 0.527 | 中等正相关,但波动大 |
| Negative Perplexity | 0.219 | 相关性弱 |
| Negative Entropy | 0.571 | 中等正相关 |
| Self-Certainty | 0.605 | 最佳基线,但仍不及DTR |
| DTR (Ours) | 0.683 | 最强且最稳定的正相关 |
关键观察:
- DTR在32个模型-任务组合中仅有2个出现负相关,稳定性远超基线
- Token长度在多数设置下呈负相关,直接反驳了"越长越好"的直觉
- Self-Certainty作为最佳置信度基线,仍比DTR低约0.08
3.3 超参数敏感性分析

图:不同阈值对DTR-准确率关系的影响。过于宽松,导致趋势平缓;和表现更稳健。
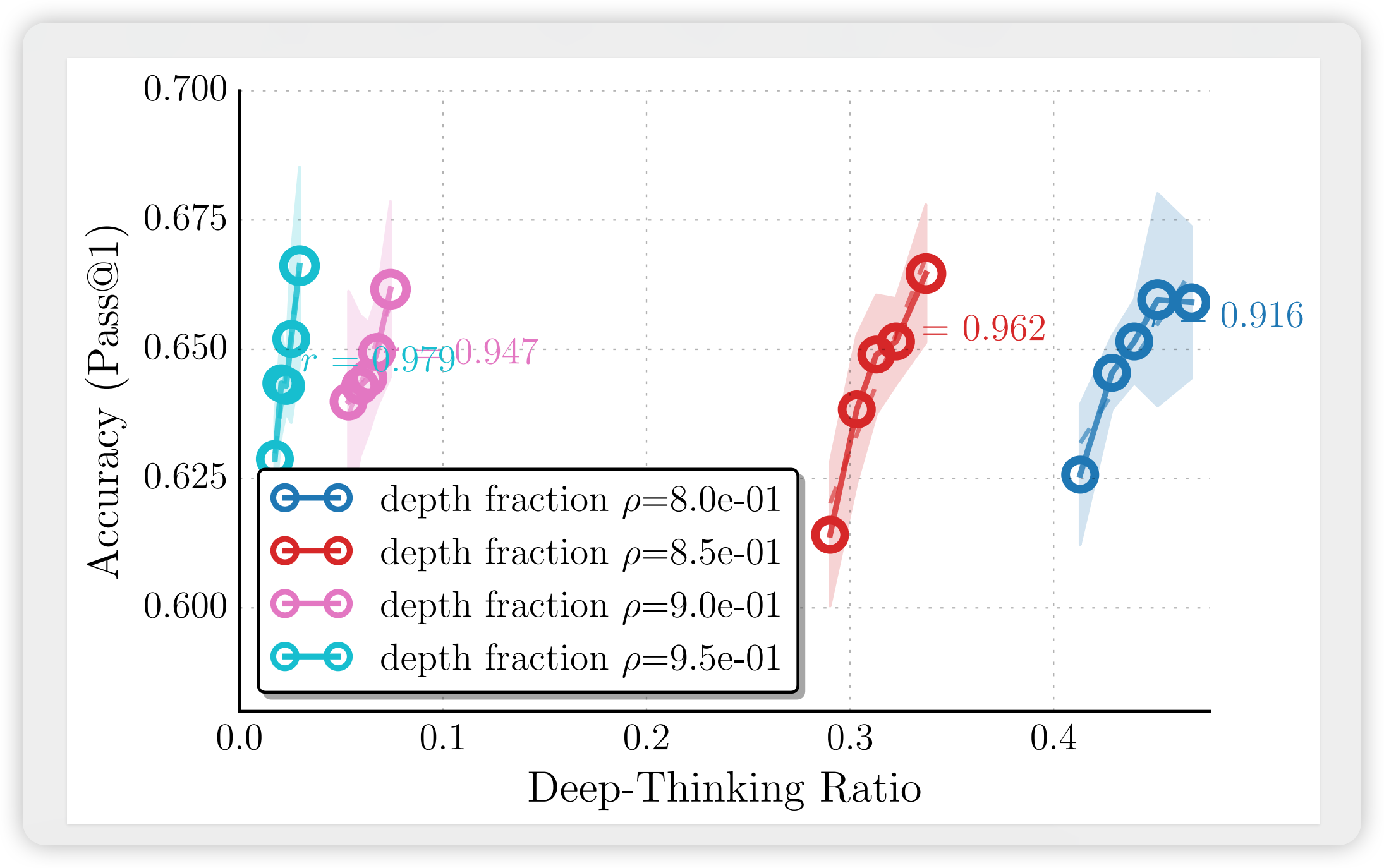
图:不同深度比例的影响。主要影响DTR的取值范围,对相关性趋势影响较小,说明指标对深层定义具有一定鲁棒性。
结论:在严格性和稳定性之间取得了最佳平衡。
3.4 Think@n:基于DTR的高效测试时扩展
基于DTR的可靠性,作者提出了Think@n策略——在并行采样中选择DTR最高的比例样本进行多数投票。
成本计算模型:
- Cons@n:完整解码所有个样本,成本
- Think@n:基于前缀(50 tokens)估计DTR,仅解码高DTR样本,成本
实验结果:
| 方法 | AIME 25 Acc | Cost (k tokens) | Cost Reduction |
|---|---|---|---|
| Cons@n | 92.7% | 307.6 | – |
| Mean@n | 80.0% | 307.6 | – |
| Long@n | 86.7% | 307.6 | – |
| Short@n | 87.3% | 255.7 | -17% |
| Self-Certainty@n | 87.3% | 150.6 | -51% |
| Think@n | 94.7% | 155.4 | -49% |
表:OSS-120B-medium上的Best-of-N结果。Think@n在准确率上超越Cons@n的同时,将推理成本降低约50%。
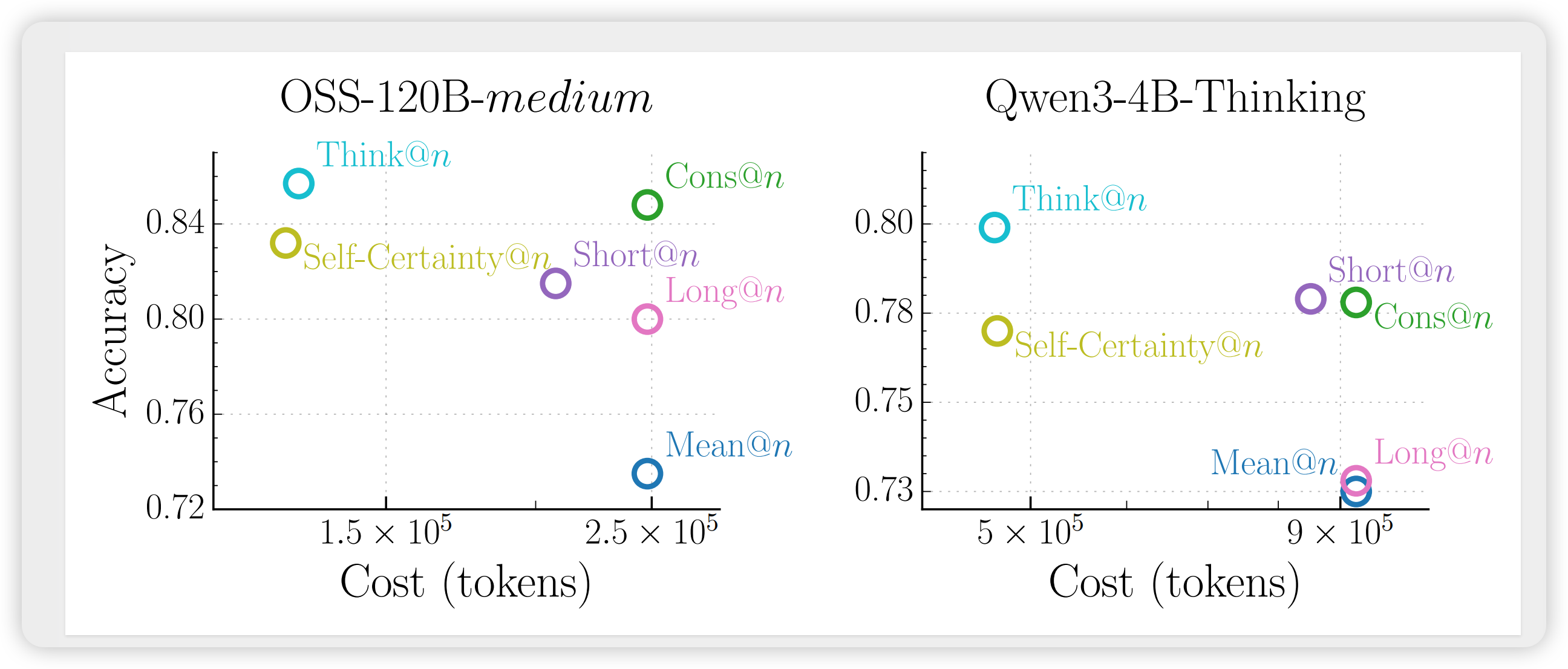
图:准确率-成本权衡的Pareto前沿。Think@n位于最优前沿,Self-Certainty@n虽成本相近但准确率明显落后。
3.5 距离度量对比
作者对比了JSD、KLD和余弦相似度三种距离度量:
- JSD-based DTR:AIME 25 (r=0.869), HMMT 25 (r=0.895) —— 稳定强正相关
- KLD-based DTR:AIME 25 (r=-0.698), HMMT 25 (r=0.409) —— 不稳定,可能因早期高熵分布导致数值问题
- Cosine-based DTR:AIME 25 (r=0.633), HMMT 25 (r=0.172) —— 隐藏空间直接比较效果较差
启示:在预测分布空间(而非隐藏状态空间)度量差异至关重要。
4. 局限性与落地思考 (Critical Review)
4.1 复现门槛与工程约束
计算开销:
- DTR计算需要获取所有中间层的隐藏状态,这意味着无法使用标准的"仅返回最终输出"的API调用
- 对于层模型,每个token需要计算次投影和JSD,计算复杂度为
- 实际部署中可能需要定制推理框架支持
模型依赖性:
- 实验显示,不同推理级别(low/medium/high)的同一模型会产生系统性的DTR差异——high级别模型的DTR反而更低
- 这表明DTR不适合跨模型/跨配置直接比较,更适合在同一模型内做相对排序
4.2 潜在短板
阈值敏感性:
- 虽然的选择相对鲁棒,但的选择对结果有显著影响
- 过于宽松,可能过滤掉有价值的信息
- 缺乏自适应阈值选择机制
前缀估计的准确性:
- Think@n依赖前缀(50 tokens)估计DTR,这一假设在理论上未经严格验证
- 对于某些任务,早期token可能无法充分代表整体推理质量
任务局限性:
- 实验集中在数学和科学推理任务,DTR在开放式生成、创意写作等任务上的有效性未知
- 对于非推理类任务,"深度思考"的定义可能不再适用
4.3 未明说的隐含假设
- Unembedding矩阵的通用性:方法假设对各层隐藏状态都适用,但LM head通常是针对最终层优化的
- 层间独立性的忽视:Transformer各层之间存在残差连接,DTR将每层视为独立预测器可能过于简化
- 收敛即正确的假设:深层收敛并不必然意味着正确,只是表明模型"思考过"
4.4 对工程落地的启示
适用场景:
- 高价值推理任务(如数学证明、代码生成)的response筛选
- 在线推理服务的早期停止策略,降低平均延迟
- 模型推理行为的诊断分析
集成建议:
- 可与现有自一致性方法结合,作为样本重排序的辅助信号
- 建议在服务层实现,而非模型层,以保持模型通用性
- 对于资源受限场景,可考虑仅采样部分层进行估计(如每4层采样一次)
5. 总结与启示 (The Verdict)
5.1 对研发的启示
-
从"量"到"质"的范式转变:本文有力证明了token数量并非推理质量的有效代理,未来工作应更多关注内部计算动态
-
层间分析的价值:通过挖掘Transformer各层的预测演化,可以获得输出层面无法捕捉的丰富信息
-
早期停止的新思路:Think@n展示了基于内部状态的早期拒绝策略,这比传统的基于生成长度的截断更具针对性
-
评估指标的设计原则:好的推理质量指标应具备(a)机制可解释性(b)与任务性能稳定相关(c)计算可行
5.2 待澄清疑点
-
开源实现细节:论文未开源,以下细节需参考代码确认:
- 隐藏状态提取的具体实现(是否包含LayerNorm?)
- JSD计算的数值稳定性处理
- 前缀长度50的选择依据
-
跨架构泛化性:
- 在MoE架构(如DeepSeek-V3)上是否有效?
- 在非Transformer架构(如RWKV、Mamba)上是否适用?
-
动态阈值的可能性:
- 是否可以根据问题难度自适应调整和?
- 能否结合任务类型设计任务特定的阈值?
-
与训练动态的关系:
- DTR是否可以作为训练过程中的监控指标?
- 能否通过DTR反馈优化模型架构或训练目标?

