前言
实验室如何训练一个拥有数百亿参数的前沿大模型?本文深入剖析七个开源权重的前沿模型:Hugging Face的 SmolLM3、Prime Intellect的 Intellect 3、Nous Research的 Hermes 4、OpenAI的 gpt-oss-120b、Moonshot的 Kimi K2、DeepSeek的 DeepSeek-R1 以及 Arcee的[Trinity series](https://github.com/arcee-ai/trinity-large-tech-report/blob/main/Arcee Trinity Large.pdf)。本文旨在提炼这些模型训练中使用的技术、动机和考量因素,重点关注训练方法而非基础设施。
本文的结构主要参考 Hugging Face 详尽的 SmolLM3 技术报告,因其内容最为详尽,并补充了 Intellect-3、gpt-oss-120b、Hermes 4、DeepSeek 和 Kimi的相关笔记。Hugging Face 在这里 详细介绍了 gpt-oss-120b 的基础设施。
概述
核心要点
- 前沿大模型训练是一个系统问题:数据混合、架构和稳定性选择主导了大多数算法调整。
- 从一个强的baseline开始,快速可靠地进行消融实验;降低变更风险,避免多变量编辑。
架构选择
- GQA(分组查询注意力) 在小groups size(2/4/8)时在相似模型规模的消融实验中通常优于 MHA 和 MQA;MLA 减少 KV 缓存但增加实现复杂度。
- 门控注意力(Gated Attention) 显著减少注意力汇聚(attention sinks)和loss尖峰。
- 文档内掩码(Intra-document masking) 对短上下文任务影响有限,但对长上下文扩展(4k→64k)至关重要。
- 嵌入共享(Tied embeddings) 在小模型中表现相当,参数量减少 18% 而性能几乎无损。
- RNoPE(无位置编码) 在长上下文场景下优于 RoPE。
- 对于长上下文,document masking + RNoPE/YaRN 风格的缩放是稳健的默认选择;注意力变体通过计算换取覆盖范围。
- 当负载平衡时,MoE 是高效的;路由、辅助或偏置平衡以及全局统计是必不可少的。
训练稳定性
- Logit softcapping(Gemma 首选)或 z-loss 用于控制 logits 幅度。
- QK-norm 防止注意力 logits 爆炸,但会增加约 3% 的训练开销。
- 梯度裁剪 和 数据过滤(如移除重复 n-gram)显著减少尖峰频率。
优化器
- AdamW 仍是默认选择,Muon 可以提供帮助,但需要谨慎的基础设施(全对全通信、填充、缩放特性)。。
- Muon 在大 batch size 下比 AdamW 更具样本效率,但需要全梯度张量访问。
- Kimi K2 引入 MuonClip 防止注意力 logits 爆炸。
数据策展
- 数据重述(Rephrasing):Kimi K2 在知识和数学领域使用,每个语料最多重述两次。
- Token 效用:高质量 token 应最大化利用,但需防止过拟合。
- 分词器设计应反映目标数据;词汇大小权衡嵌入成本与 token 压缩和 KV 缓存。
- 数据调度很重要:多阶段混合和后期高质量注入塑造最终行为。
后训练
- SFT(监督微调) 作为 RL 前的稳定基线。
- RL(强化学习):GRPO 节省内存,In-flight 权重更新提升效率。
- PTX 损失:防止在 RL 训练中灾难性遗忘高质量预训练数据。
- 中期训练和后期训练(SFT + 偏好/RL/蒸馏)通常决定推理和工具使用行为。
训练运维
- 吞吐量故障通常源于数据管道或存储问题,而非模型代码。
- Dataloader 行为(shuffle、packing、随机访问)会静默改变训练动态。
- 并行设置中的种子处理是高杠杆细节,需尽早验证。
- 将 evals 和日志视为一等公民——它们是发现回归的唯一途径。
- 缩放法则提供指导,但许多前沿模型过度训练;推理成本和稀疏性权衡通常驱动最终选择。
- 大多数训练失败源于常见原因:高学习率、有问题的数据批次、MoE 模型中的负载不平衡或存储/基础设施问题
最小训练指南
- 定义产品目标,尽早锁定跨知识、数学、代码、长上下文和指令遵循的评估体系。
- 选择基线架构,使用已充分验证的基线架构(大量的成功与失败经验);除非 MoE 至关重要,否则默认使用 dense + GQA + RoPE/RNoPE。
- 选择 tokenizer,匹配目标语言和领域;尽早冻结词汇表和特殊 token。
- 构建数据管道,包含去重、过滤和污染检查;明确测量数据质量。
- 运行小规模消融实验,针对注意力、位置编码、优化器和学习率调度;一次只改变一个变量。
- 规划多阶段数据混合;将最佳数据和推理密集型数据放到 全训练流程的后阶段中。
- 添加稳定性保障:logit softcapping(首选)、z-loss/QK-norm、梯度裁剪、精度策略、loss尖峰监控。
- 验证长运行吞吐量,确认 dataloader 行为(packing、shuffling、随机访问)。
- 运行主训练流程,使用间隔评估和一致的种子,特别是张量并行。
- 中训练填补领域空白(如果 在SFT 之后,存在特定领域表现不佳,说明预训练阶段缺乏该领域的知识分布 );逐步扩展上下文长度(4k → 32k → 64k → 128k)。
- 后训练:先进行SFT 训练,然后根据可验证奖励和工具使用目标选择偏好/RL/蒸馏。
- 重新评估,运行安全检查,锁定发布检查点并附带完整日志和配置。
通用实践
“学会识别什么值得测试,而不仅仅是如何运行测试。在无关选择上完美的消融实验,与在重要选择上草率的消融实验一样浪费算力。”
消融实验的设计哲学
消融实验需要快速(更快迭代 → 测试更多假设)且可靠(需要强区分能力,否则可能只是噪声)。
“一个扎实的消融实验设置的真正价值远不止构建一个好模型。当主训练运行中不可避免地出现问题时,我们希望对每一个决策都有信心,并快速识别哪些组件没有经过适当测试可能是问题的根源。这种准备节省调试时间,保持我们的理智。没有什么比盯着神秘的训练失败却完全不知道 bug 可能藏在哪里更糟糕的了。”
核心原则:
- 选择经过充分验证的基线架构和训练设置
- 风险规避原则:“永远不要改变任何未经测试证明有帮助的东西”
- 在评估中寻找:单调性(分数提升)、低噪声(分数对随机种子的抗性)、高于随机性能、排名一致性
- 优先评估! 在预训练和后训练之间,核心评估应保持一致,其实现应在基模型完成训练前很久就完成
- 平衡探索与执行:选择灵活性和稳定性而非峰值性能,为探索设定截止日期
模型架构与设置
模型架构决策从根本上决定了模型的效率、能力和训练动态。像 DeepSeek、gpt-oss-120b、Kimi 和 SmolLM 这样的模型系列具有截然不同的架构(密集型vs MoE)、注意力机制(MHA vs MLA vs GQA)、位置编码(RoPE、部分 RoPE、NoPE)等。当前并非所有关于模型的信息都公开可用:
| Kimi-K2 | Trinity Large | gpt-oss-120b | OLMo 3 | SmolLM | |
|---|---|---|---|---|---|
| 参数数量 | 1.06T | 400B | 116.83B | 32B | 3B |
| 注意力机制 | MLA | GQA (8 组) | GQA (8 组) | GQA (?) | GQA (4 组) |
| 位置嵌入 | RoPE (?) + YARN | RoPE + YARN | RoPE + YARN | RoPE + YARN | RNoPE + YARN |
| 架构 | MoE | MoE | MoE | 密集型 | 密集型 |
| 分词器 | tokenization_kimi | 自定义 | o200k_harmony | cl_100k | Llama3 |
从上表可以看出当前前沿模型的架构趋势:大规模模型(>100B)普遍采用 MoE 架构以获得更好的推理效率,而中小规模模型则倾向于 dense 架构。GQA 已成为注意力机制的主流选择,在 KV cache 效率和模型性能之间取得了良好平衡。
架构决策启发式
Hugging Face 建议遵循以下决策,如果以下任一条件为真,则选择 dense 架构:
- 内存受限(因为 MoE 必须加载所有专家)
- LLM 训练新手(专注于基础知识)
- 时间线紧张(使用有完善文档的简单训练方法)
决策建议:
- 如果内存或基础设施受限,默认使用 dense 模型 + GQA + RoPE/RNoPE
- 如果需要大规模推理效率且能管理路由复杂性,考虑 MoE + 强负载均衡
- 如果长上下文是核心需求,考虑document masking + RoPE 扩展(ABF/YaRN)或 RNoPE 变体
- 如果需要更简单的 kernel 和更快迭代,避免新颖注意力变体,除非你能快速地实现或者优化
注意力机制
MHA → MQA → GQA → MLA 的演进
多头注意力 (Multi-head attention,MHA) 对每个注意力头使用单独的查询、键和值投影,但这会创建一个大的 KV 缓存,成为推理瓶颈和 GPU内存消耗者。
为了解决这个问题,研究人员开发了 multi-query attention (MQA)和 grouped query attention (GQA)。在 MQA 中,KV值在所有头之间共享,但这会以牺牲注意力容量为代价,因为头无法存储专门针对每个头的信息。GQA 通过在一个小groups(例如 4 个)之间共享KV 值来缓解这个问题。
这三种注意力机制代表了效率-性能权衡的不同点:
- MHA:最高性能,但 KV cache 最大
- MQA:最小 KV cache,但性能下降明显
- GQA:在两者之间取得平衡,是当前的主流选择
- MLA:DeepSeek 提出的创新方案,通过潜在压缩实现接近 MQA 的效率但保持更好的性能
另一种替代方案是multi-latent attention (MLA) ,它存储一个压缩的潜在变量,可以在运行时解压缩/投影为 KV值。潜在变量通常比完整的 KV 缓存小得多(通常实现 4-8 倍压缩),这使得 KV 缓存参数计数更接近 GQA,同时保持比 MQA 更强的性能。
消融实验发现
Hugging Face 的消融实验发现(对于参数数量变化的变量,如将 MHA 改为 GQA,他们偶尔会调整其他超参数以保持模型大小大致相同):
- 小groups(2/4/8)的 GQA 优于 MHA
- MHA 优于 MQA 和 16 组的 GQA
- 在 HellaSwag、MMLU 和 ARC 等基准上,2/4/8 组的 GQA 表现最佳
为什么 GQA 优于 MHA?
从信息论角度,MHA 的每个头都有独立的 K、V 投影,这提供了最大的表达能力,但也带来了冗余。GQA 通过在小组内共享 K、V,实际上是在表达能力和计算效率之间找到了最佳平衡点。
Hugging Face 的消融实验表明,2/4/8 组的 GQA 表现最佳,这可能是因为:
- 小组保留了足够的头特异性信息
- 共享的 K、V 起到了一种"正则化"作用,防止过拟合
- 内存带宽的减少使得更大的 batch size 成为可能
门控注意力(gated attention)
**门控注意力(Gated attention)**在输出投影之前对缩放点积注意力输出应用逐元素门控机制。
其中 是位置 处的输入, 是 sigmoid 函数, 是学习的门投影矩阵。这个会分割成 个注意力头(一般 是查询头的数量),每个头的注意力输出与相应的门段进行逐元素乘法:
其中 表示头 在位置 处的缩放点积注意力输出, 表示逐元素乘法, 是头 的gate segment 。门控输出然后被连接并通过输出矩阵 投影以产生最终输出。
这实际上是注意力输出的自适应缩放。sigmoid 门将每个头的输出限制在 (0, 1) 范围内,这:
- 防止了注意力权重的极端值
- 实现了头之间的自适应重要性分配
- 起到了类似 dropout 的正则化效果
门控注意力减少注意力汇聚(接收不成比例高注意力的 token)、减少使训练不稳定的大激活,并改善评估和长序列泛化性能。关键是它稳定训练并减少loss尖峰,使其对大规模训练极具价值。
门控注意力的核心思想是通过可学习的门控机制动态调节每个注意力头的输出强度。这种设计有几个重要优势:
- 减少 attention sinks:某些 token(如句首 token)往往会吸引过多注意力,门控机制可以抑制这种现象
- 稳定训练:通过限制激活值的范围,减少训练过程中的数值不稳定
- 改善长序列泛化:门控机制可以帮助模型更好地处理长上下文中的信息流动
文档掩码(Document Masking)
预训练时,需要考虑固定序列长度,因为训练使用 [batch, sequence length, hidden] 形式的张量。由于文档长度可变且希望避免浪费计算的 padding,packing 允许在同一序列内 shuffle 和连接文档以达到序列长度。
Causal masking意味着对于同一批次中无关的文件 A 和 B,B 中的 token 可以 attend 到 A 中的 token,这会降低性能。 intra-document masking修改注意力掩码,使 token 只能 attend 到同一文档内的先前 token。
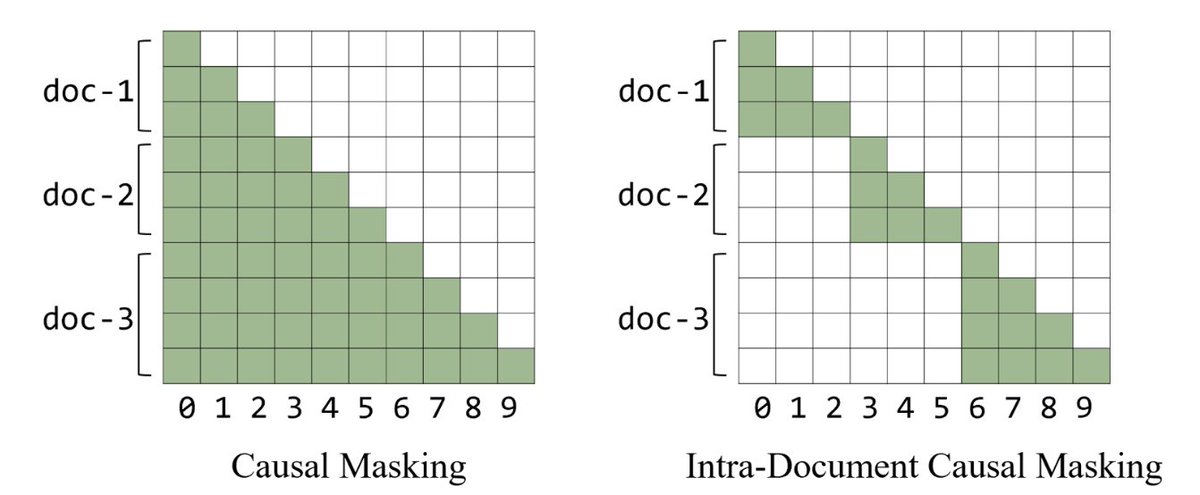
许多论文发现 intra-document masking对长上下文扩展和短上下文基准以及缩短平均上下文长度有益。
Hugging Face 发现,文档掩码在 PIQA 上有小幅提升,但在短上下文任务上否则没有明显影响。但与前述研究一致,他们观察到它对于从 4k 扩展到 64k token 变得至关重要。
模型规模考量: 对于较小模型,一些实现选择省略文档内掩码,发现额外的复杂性和潜在的跨文档学习减少在这些规模下不值得收益。但对于较大模型,文档内掩码变得更加关键,因为模型从跨文档注意力模式学习的能力相对于更清晰的文档边界收益而言减弱。
文档掩码的效果与模型规模相关。较小模型可能从跨文档注意力中获益(更多上下文),而较大模型有容量学习更清晰的文档边界。这反映了容量与结构之间的权衡:小模型需要所有可用信号,大模型可以从更清晰的结构中获益。
嵌入共享(Embedding Sharing)
输入嵌入(token-to-vector 查找)和输出嵌入(hidden states 到 vocab logits)通常表示为单独的矩阵,因此总嵌入参数为 ,其中 是词汇大小, 是隐藏维度。在小型语言模型中,这可以占总参数的高20%,例如 Llama 3.2 1B(在较大的模型中,嵌入占参数计数的比例小得多,在Llama 3.1 70B 中仅为 3%)。
问题在于 tying 它们时,输入/输出嵌入仍然代表不同的几何结构,像 “the” 这样的高频 token 可能由于从输入流和预测输出都获得梯度而主导表示学习。
Hugging Face 发现在 1.2B 模型上,绑定嵌入表现相当,尽管参数减少了 18%(从 1.46B 降至 1.2B),并且与同样具有 1.2B参数(更少层)的未绑定模型相比,未绑定模型显示更高的损失和更低的下游评估分数。
位置编码(positional encodings)
没有位置编码,transformer 就没有词序感,类似于词袋的概念。最初,使用绝对位置嵌入,通过学习一个查找表将位置索引映射到添加到token 嵌入的向量,但最大输入序列长度受限于它所训练的序列长度。相对位置编码随之而来,因为捕获 token 之间的距离比捕获它们的绝对位置更重要。
最常用的技术是旋转位置嵌入 (RoPE),它通过在 2D 平面中旋转查询和键向量来编码位置信息。RoPE 将相对位置编码为旋转角度:基于查询/键向量的维度,RoPE将其分成对(因为它们在 2D 空间中旋转)并根据 token 的绝对位置和基础频率进行旋转。在注意力期间,它们旋转位置之间的点积通过旋转角度的相位差直接编码它们的相对距离,其中相距k 个位置的 token 始终保持相同的角度关系。
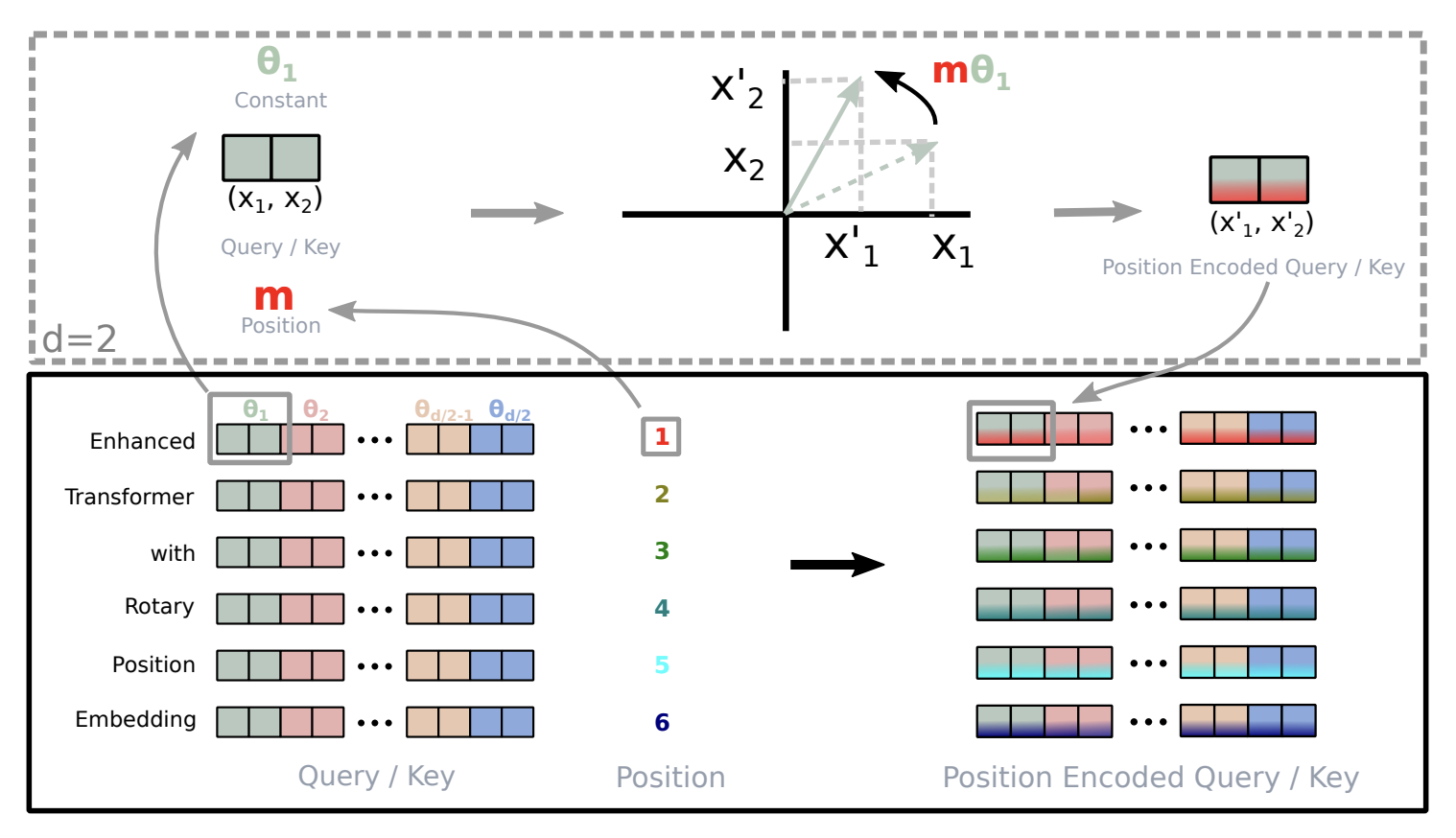
在预训练期间,模型在较短的上下文长度上训练(类似于文档掩码的想法,并且二次注意力很昂贵)以学习单词之间的短距离相关性。但随着序列长度的增长,旋转角度通过 增长。这可以通过在序列长度增加时使用 ABF (Adaptive Base Frequency) 或YaRN 等方法增加基础频率来解决,YaRN对不同组件应用更精细的频率插值,并包括动态注意力缩放和温度调整等其他技术。对于极长的上下文,YaRN 表现最佳,在 gpt-oss-120b中,它被用于将密集层的上下文长度扩展到 131k token。
最近,随着对长上下文的重视,NoPE (no position embedding)和混合方法 RNoPE出现了。NoPE仅使用因果掩码和注意力模式,因此不会遇到超出训练长度的外推问题,但在短上下文推理和基于知识的任务上表现较弱。RNoPE在注意力块上交替应用 RoPE 和 NoPE,其中 RoPE 处理局部上下文,NoPE 帮助长距离信息检索。另一个想法是部分 RoPE,它在同一层内应用RoPE/NoPE。
Hugging Face 使用 RoPE、RNoPE(每 4 层移除位置编码)和带文档掩码的 RNoPE 进行了消融实验。他们发现所有方法在短上下文任务上都达到了相似的性能,因此他们采用了RNoPE + 文档掩码,因为它为长上下文处理提供了基础。
长上下文注意力
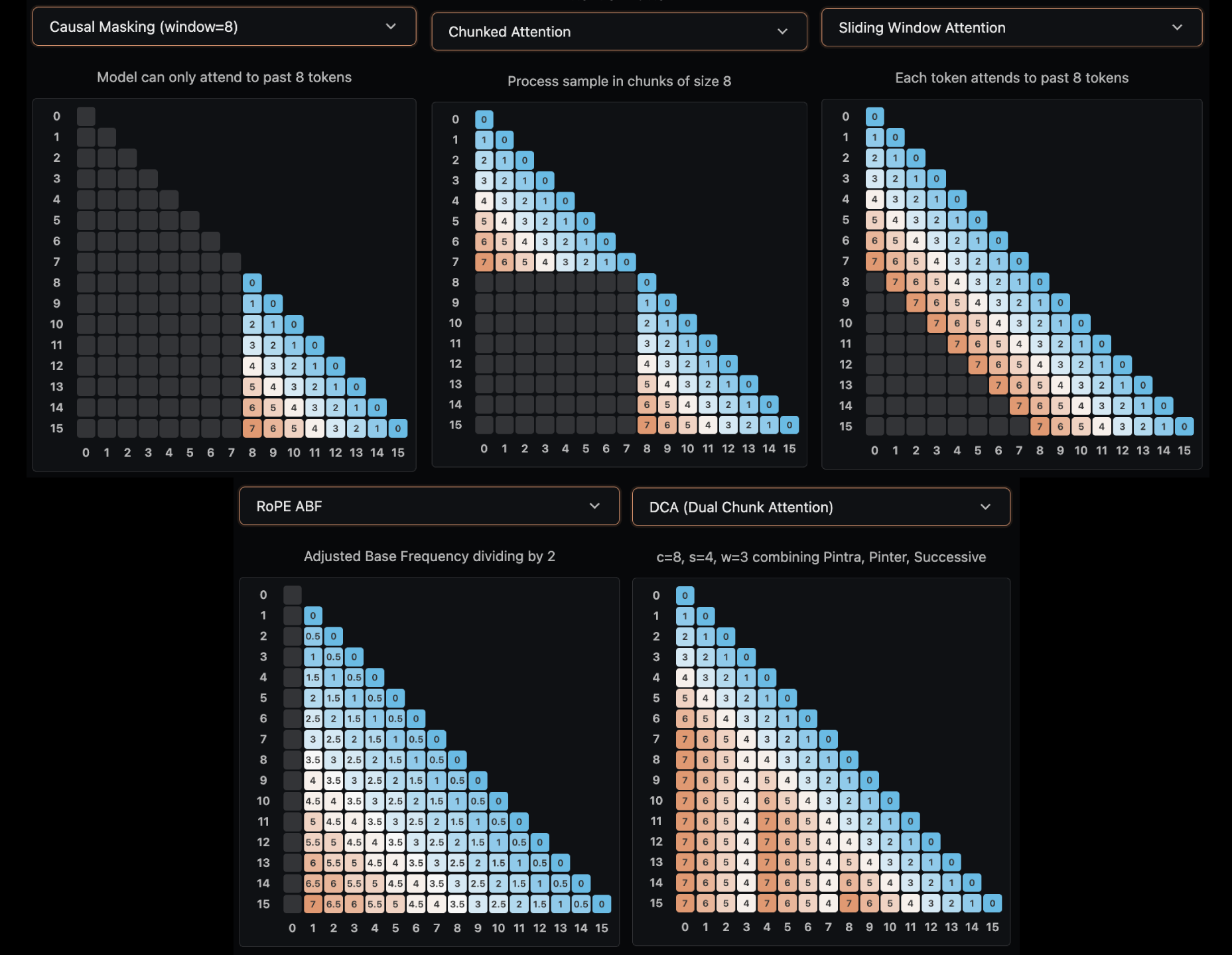
注意:本节涵盖注意力模式修改(改变哪些 token 可以关注哪些其他 token)。这些与 ABF/YaRN 等位置编码缩放方法(在"位置编码"部分讨论)不同,后者调整位置信息的编码方式而不改变注意力模式。以下方法修改注意力模式以减少计算成本:
- 分块注意力(Chunked Attention):将序列分成固定大小的块,其中 token 只能在其块内关注。Llama 4 与 RNoPE(特别是 RoPE 层)配对,这也减少了每层的 KV缓存大小,但它在长上下文任务上的性能下降。
- 滑动窗口注意力 (Sliding Window Attention ,SWA):每个 token 可以看到最多 w 个位置回来,创建一个维护局部上下文的滑动窗口。Gemma 3 将 SWA与每隔一层的全注意力结合使用。
- 双分块注意力 (Dual Chunk Attention,DCA): N 个 token 被分块成 C 组。在每个组内(如分块注意力),token 正常关注。在连续块之间,有一个局部窗口来保持局部性,更广泛地说,块间注意力允许查询以capped 相对位置上限关注先前的块。 Qwen-2.5使用 DCA 支持高达 100 万 token 的上下文窗口。
方法 计算复杂度 长程依赖 适用场景 全注意力 完美 短序列 分块注意力 受限 长序列但局部依赖强 SWA 受限于窗口 局部上下文重要 DCA 部分 超长上下文
交替使用局部和全局注意力表示使用局部注意力(限制在邻近token)的层和全局注意力(全序列)的层之间交替。这种模式平衡了计算效率与捕获局部和长距离依赖的能力。局部层减少二次复杂度同时保持局部上下文,全局层确保不会丢失远距离关系。当训练遇到不稳定性或损失尖峰时,调整全局层的比例(例如,增加它们的频率)可以导致更快的损失恢复,因为模型重新获得对某些模式至关重要的长距离信息的访问。交错策略对于全全局注意力在计算上不可行的长上下文模型特别有效。
混合专家模型 (MoE)
MoE(混合专家),类似于我们的大脑为不同任务激活不同区域,提供了密集模型的替代方案。在推理时,只有基于输入激活的某些"专家"被激活,与所有参数都活跃的密集模型相比,大大减少了计算。MoE 通过用多个 MLP(专家)替换前馈层并在 MLP之前添加可学习的路由器来选择专家来工作。路由器通常使用 top-k 门控,为每个 token 选择具有最高亲和度分数的 k 个专家,其中 k通常远小于专家总数(例如,384 中的 8 个)。
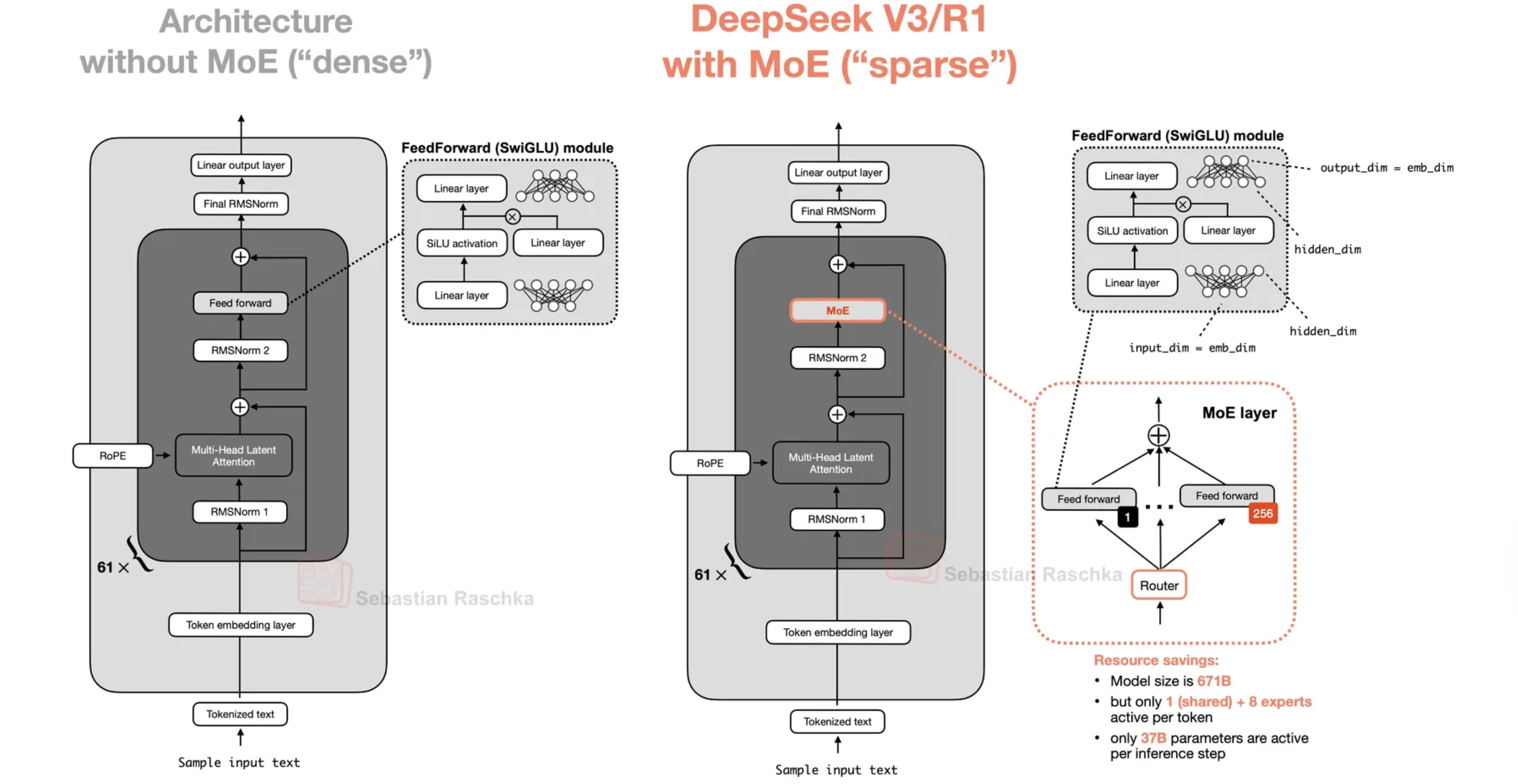 一般来说,对于固定数量和大小的活跃专家,增加专家总数可以改善损失,高稀疏性提高性能并从增加计算中获益更多。最近的模型更加稀疏,拥有超过100 个专家,每个 token 激活约 10 个专家。
一般来说,对于固定数量和大小的活跃专家,增加专家总数可以改善损失,高稀疏性提高性能并从增加计算中获益更多。最近的模型更加稀疏,拥有超过100 个专家,每个 token 激活约 10 个专家。
为了确定每个专家应该有多大,一个常见的指标是粒度,由 定义,其中更高的粒度对应更多具有更小维度的专家;这可以解释为与密集MLP 宽度匹配所需的专家数量成比例的数字。最近的模型粒度从 2(gpt-oss-120b)到8(qwen3-next-80b-a3b)不等。 Ant Group 表明,粒度不会显著改变损失,但会驱动效率杠杆(MoE 达到与密集模型相同损失所需的 flops比率)。总体而言,MoE 在训练和推理计算方面提供了密集模型的良好替代方案。
共享专家是始终开启的专家,它们吸收基本的、重复的模式,以便其他专家可以更积极地专业化;一个通常就足够了(DeepSeek-V2 使用两个,这增加了一点复杂性)。
负载平衡至关重要,因为如果失败,不仅训练和推理效率会急剧下降,而且有效学习能力也会下降。路由机制通常使用 top-k 门控:对于每个token,路由器计算亲和度分数(通常通过学习的线性投影后跟 softmax),选择 top k 个专家,其中 k通常远小于专家总数。为确保专家利用平衡,这可以通过添加基于损失的负载平衡器 (LBL)来解决,由 给出,其中 是专家总数, 确定平衡项的强度, 是路由到专家 的 token 比例,是概率质量(平均路由概率);因此在完美负载平衡中,。此外,不应太大,以至于路由均匀性会压倒主要训练目标。这些应该使用全局统计数据进行监控,而不是可能因局部批次狭窄而产生偏差的局部统计数据。
DeepSeek-V3 使用不同的无损失负载平衡,通过向路由 softmax 中的亲和度分数添加偏置项。除了基于偏置的方法外,还出现了其他几种路由和负载平衡策略。一些实现使用在训练期间适应的可学习路由函数,而其他实现包含专家容量约束,防止任何单个专家被淹没。这些方法的关键见解是,有效的负载平衡必须使用跨多个批次聚合的全局统计数据,因为局部批次统计数据可能具有误导性的狭窄性并偏向路由决策。
序列级辅助损失将传统辅助损失扩展到促进序列内平衡。
这里, 是序列长度, 是一个小的系数, 是指示函数(当其参数为真时为 1,否则为 0), 是每个 token的活跃专家数量。
这里,对于序列中每个位置 的每个 token ,每个专家 被分配一个路由分数 ,该分数被归一化为,在位置分配给专家 的路由概率比例。在整个序列上平均得到,表示专家 在整个序列中被考虑用于路由的平均频率。项进一步反映了专家 实际被选中(即,是 token 的 top- 专家之一)的次数比例,在添加偏置项 之后。损失 鼓励乘积 在不同专家之间相似,推动模型向平衡的路由决策和负载分配;如果任何专家被使用得太多或太少,损失会增加,将模型推回平衡状态。
无辅助损失的负载平衡方法通过以解耦方式维护偏置向量 来避免引入干扰梯度。设 为当前步骤中路由到专家 的 token数量, 为所有专家的平均负载。 更新为
其中 是偏置更新速度,一种学习率。这个特定版本包括专家偏置更新的额外重新中心化。
**序列级 MoE 平衡与均匀性 (SMEBU) **负载平衡在序列级别而非 token级别运行,确保专家利用在整个序列中保持平衡。归一化的每个专家违规计算为 和 ,这使得尺度与序列长度和批量大小无关。然后使用带有动量因子 的动量缓冲器更新 :
使用soft-clamping,可调节尺度 控制饱和速度; 在 上保持训练期间所需的连续性和稳定性,而 强制更新为 ,使更新步骤振荡。动量也作为一种噪声抑制形式引入,类似于动量
SGD 减少噪声梯度更新中的方差。
MoE 的路由可以看作是一个多智能体博弈:
- 每个专家是一个"玩家"
- Token 是"资源"
- 目标是最大化整体性能,同时保持负载均衡
基于损失的负载均衡(LBL)引入了一个"惩罚项":
当 时,这个项达到最小值。这实际上是在鼓励一个纳什均衡——每个专家获得相同比例的 token 和路由概率。
DeepSeek-V3 的无辅助损失负载均衡通过偏置项实现,这可以看作是一个分布式优化方案——每个专家根据全局统计信息调整自己的"吸引力"。
混合模型(Hybrid Models)
由于 transformer 不能高效处理长上下文,而 RNN 可以,一个想法是结合两者以获得两全其美的效果。通过从位置 的输出中删除softmax:
其中 、 和 分别是位置 和 处的查询、键和值向量, 是位置 的输出。通过定义 ,然后我们得到一个循环关系,其中 总结了所有过去的$ (k_j, v_j)$ 对:
其中 是来自前一时间步的状态。虽然这让我们更接近 RNN结构,但在实践中,softmax稳定训练,线性形式可以在没有归一化的情况下导致不稳定性。对于 RNN,通过为先前状态引入门 来忘记过去有时会有所帮助:
其中 表示逐元素乘法, 是学习的门控机制。 Mamba-2 是最流行的之一,用于 Nemotron-H 和 Falcon H1 等混合模型。混合架构越来越受欢迎,特别是在带有门控 DeltaNet 更新的 Qwen3-Next 和 Kimi 的下一个模型中,可能使用他们的“kimi delta attention.”。
架构总结
- 除非有充分理由和基础设施支持 MoE,否则使用经过验证的dense 架构基线。
- 小group的 GQA 是稳健的默认选择;MQA 最便宜但往往表现不佳。
- 对于长上下文,早期在方案中考虑 RNoPE/YaRN 加上 document masking。
- 混合架构很有前景,但仍然更难推理和操作。
训练稳定性
训练稳定性对于成功的大规模模型训练至关重要。几种技术有助于防止训练失败,包括正则化方法、仔细的初始化和架构选择。以下部分涵盖关键稳定性机制:
Z-loss
Z-loss 是添加到标准交叉熵损失的正则化项,可防止 logits 漂移到大幅度。softmax 分母是 ,通过将 添加到损失中,我们基于 进行惩罚,这表示整体 logit 尺度。
在他们的 1B 模型上,Hugging Face 发现添加 z-loss 不会影响训练损失或下游性能,因此由于训练开销,他们选择不包括它。对于 logit稳定,logit softcapping(见下文)在主流方案中通常更受欢迎,遵循 Gemma 2 和 Gemma 3 模型。
z-loss 的直觉是当 logits 很大时,softmax 梯度接近于零(饱和),导致梯度消失。通过保持 logits 较小,我们确保梯度流动保持活跃。系数通常设置得很小(如 1e-4),使其不会主导主训练目标。
logit softcapping
对数概率软截断通过平滑、可微分的变换将 logits 映射到有界范围,防止 logits过度增长。与硬剪辑(在边界处梯度为零,可能导致训练不稳定)不同,软截断使用 平滑压缩值。Gemma 2 报告介绍了生产模型中使用的公式:限制logits 使得值保持在 范围内,使用
其中 是控制输出范围的阈值超参数。除法在 之前归一化输入,乘以 将输出重新缩放到所需区间。与z-loss(向损失添加正则化项)不同,软截断直接在正向传递中操作激活,遵循 Gemma 2 和 Gemma 3 模型的做法。
Gemma 2 对注意力 logits(softmax 前)和最后一层应用 softcapping。他们为注意力层设置 =50 ,最终层设置 =30 。该技术可追溯到 Bello et al., 2016 在神经机器翻译中的应用。然而,一个注意事项是,对数概率软截断与训练期间的 Flash Attention / SDPA不兼容,因为这些融合内核假设标准注意力。Hugging Face Gemma 2 blog 博客指出,对于稳定的微调,必须使用 attn_implementation=“eager”;推理仍然可以使用 SDPA,质量差异最小。This writeup提供了简洁的技术概述。
特性 -loss Logit Softcapping 实现方式 损失函数正则项 前向传播修改 计算开销 额外的损失计算 每次前向都计算 效果 软约束 硬约束 与 Flash Attention 兼容性 兼容 不兼容 Hugging Face 的实验表明,logit softcapping 是首选方法,因为它更直接地控制 logits 的范围。
权重衰减与嵌入(weight decay and embeddings)
尽管权重衰减是一种正则化技术,但从嵌入中移除权重衰减可以提高训练稳定性。权重衰减导致嵌入范数减小,但这可能导致早期层中的梯度变大,因为LayerNorm 雅可比矩阵有一个 1/σ 项(来自归一化),与输入范数成反比。
Hugging Face 使用权重衰减基线、无权重衰减基线以及结合所有先前采用的更改的另一个基线进行了测试,发现没有显著的损失或评估结果差异,因此他们包括了无权重衰减。
QK-norm
与 z-loss 类似,QK-norm通过在计算注意力之前对查询和键向量应用 LayerNorm 来防止注意力 logits 变得过大。然而,提出 RNoPE的同一篇论文发现,它会损害长上下文任务,因为归一化通过剥离查询-键点积的幅度来淡化相关 token 并强调无关 token。
RMSNorm
RMSNorm 与 LayerNorm 保持相当的性能,同时计算更简单,因为避免了均值居中计算。一种称为depth-scaled sandwich norm的变体在注意力/MLP块之前和之后应用归一化,归一化尺度根据层深度进行调整:
其中 和 是层 的输入/输出, 是子层模块(如注意力、FFN 或 MoE)。RMSNorm 增益 是应用于 RMS归一化后的乘法因子,由 给出。在 Arcee的情况下,他们初始化 并 。这种深度相关的缩放考虑了不同层中激活的不同演变方式。三明治模式(预归一化和后归一化)提供了额外的稳定性,特别是在非常深的网络中,其中梯度流可能具有挑战性。
Arcee 还在语言建模头之前应用 RMSNorm 稳定最终隐藏状态,以确保在将其转换为 token 概率之前保持一致的输出激活尺度。
其他设计考虑因素
-
参数初始化:要么使用 和剪裁的归一化初始化(如 TruncDNormal 初始化所做的,通常 ),要么使用像 (maximal update parametrization)这样的方案,该方案规定权重和学习率应如何随宽度缩放,以便训练动态保持可比较。
- 剪裁防止可能使训练不稳定的极端初始化值,这对于嵌入层尤为重要,其中大的初始激活可能通过网络传播。
- 另一个启发式是设置 ,尽管确切的系数可能会有所不同。
- 在前向传递过程中,嵌入层的激活按 缩放:
。这使嵌入幅度相对于残差流保持在稳定范围内,并且在多个 transformer 实现中很常见。值得注意的是,Grok-1 和 Grok-2 检查点以及Trinity Large 和前两代 Gemma 模型都实现了这一点。
-
激活函数:SwiGLU 是大多数现代 LLM 使用的,不是 ReLU 或 GeLU;例如,gpt-oss-120b 使用门控 SwiGLU。一些例外是 Gemma2 使用GeGLU 和 nvidia 使用 。
-
宽度与高度:更深的模型在语言建模和组合任务上往往优于同等大小的更宽模型。在较小的模型中,这更为明显,但较大的模型利用更宽的模型进行更快的推理,因为现代架构支持更好的并行性。
稳定性总结
- 稳定化主要是关于合理的默认值,而不是奇特的技巧。
- Logit softcapping(Gemma 风格)是注意力/LM 头 logit 稳定的首选方法;z-loss 和 QK-norm是替代方案。
- QK-norm可能损害长上下文任务;不要假设它"总是好的"。
- 初始化和归一化细节随着深度的增加而变得更加重要。
- 早期跟踪损失尖峰;许多"神秘失败"是配置或数据问题。
分词器
分词器设计通常由几个考量因素指导:
- 领域:在数学和代码等领域,数字和其他特殊字符需要仔细处理。大多数分词器进行单数字分割,这更有效地帮助算术模式并防止数字记忆。像Llama3 这样的一些分词器进一步将数字 1 到 999 编码为唯一 token。
- 支持的语言:在英语文本上训练的分词器在遇到其他语言(如普通话或波斯语)时会非常低效。
- 目标数据混合:当从头训练分词器时,我们应该在反映最终训练混合的样本上进行训练。
更大的词汇量可以更有效地压缩文本,但它们会带来更大的嵌入矩阵成本,如嵌入部分所述。对于仅英语模型,50k 通常足够,而多语言模型需要超过100k。存在最佳大小,因为来自更大词汇量的压缩收益呈指数下降。
大型模型受益于大词汇量,因为额外的压缩在前向传递(投影到 QKV、注意力和 MLP)上节省的成本超过了 softmax 期间额外嵌入 token的成本。对于内存,更大的词汇意味着更少的 token,因此更小的 KV 缓存。
BPE(字节对编码)仍然是事实上的选择。从微小的单位(如字符或字节)开始,BPE 算法反复合并最常见的相邻对成为新
token。要评估分词器的性能,fertility 是一个常见指标,衡量编码一个单词所需的平均 token 数(或者,字符到 token 比率或字节到
token 比率,但由于单词长度可变性和字节表示,这些有局限性)。另一个是连续单词的比例,描述有多少单词被分割成多个部分。对于两者,较小的指标表示更高效的分词器。
有许多强大的现有分词器,如 GPT4 的分词器和 Gemma3 的分词器。通常,使用现有分词器就足够了;只有当我们想为低资源语言训练或有不同的数据混合时,才应该继续训练我们自己的分词器。
优化器与训练超参数
选择优化器和调整超参数非常耗时,并且会显著影响收敛速度和训练稳定性。虽然我们可能会尝试从大型实验室的模型中提取这些信息(尽管是有用的先验),但它们可能不适合特定用例。
AdamW
尽管发明了 10 多年,AdamW 仍然经受住了时间的考验。Adam(自适应动量估计)根据梯度的指数加权平均值 和平方梯度的指数加权平均值 以及权重衰减(“W”)来单独更新权重。指数移动平均值为每个参数提供自适应学习率:具有一致大梯度的参数获得较小的有效学习率(通过平方梯度项),而具有小或噪声梯度的参数获得较大的有效学习率。这种适应性有助于稳定训练并更快收敛:
其中 表示模型参数, 是学习率, 是权重衰减系数, 是步骤 的梯度, 和 是一阶和二阶矩估计(指数加权平均值), 和 是偏差校正版本, 和 是矩估计的指数衰减率, 是一个小常数(通常为 )以防止除零。即使对于现代 LLM,超参数也基本保持不变:权重衰减因子 或 ,,。
Muon
与 AdamW 按参数更新不同,muon 将权重矩阵视为单个对象并基于矩阵级操作进行更新。这种方法减少了轴对齐偏差(优化偏向某些坐标方向)并鼓励探索否则会被抑制的方向。通过考虑整个权重矩阵结构而不是单个参数,muon可以更好地捕获参数之间的相关性:
其中 表示步骤 的模型参数, 是损失函数, 是梯度矩阵, 是归一化梯度矩阵(通常为 ), 是具有 的动量缓冲矩阵, 是动量系数, 是学习率, 应用奇函数 。这篇博客和这篇博客更详细地描述了它的代数以及系数为何是这样的原因。Newton-Schulz迭代逼近矩阵符号函数:我们可以通过 估计 的 SVD 分解, 基本上替换了 ,因为迭代应用 (即 )收敛到符号函数,该函数归一化奇异值。这减少了沿轴的偏差,并鼓励探索原本会被抑制的方向。
Muon 比 AdamW 更样本高效,特别是在 AdamW 挣扎的大批量大小下。一些实现,包括 Arcee 的 Trinity Large,选择混合方法:对隐藏层使用 muon,而对嵌入和输出层保留 AdamW。这个决定源于这些层表现出的不同优化动态——嵌入和输出投影受益于按参数的自适应学习率,而隐藏层从 muon 的矩阵级结构感知中获益更多。
但由于 muon 在矩阵级别操作,应用 NewtonSchulz 需要访问完整的梯度张量。一种方法使用重叠轮询方案,其中每个 rank 负责收集对应其索引的所有梯度矩阵并在本地应用 muon。由于 FSDP 期望分片的梯度/更新,每个 rank 都有其 muon 更新梯度的分片,然后优化器步骤可以正常进行。然而,这会在许多矩阵上发出大量重叠的集合通信,在大规模时会崩溃。
Prime 采用的替代方案基于****全对全集合通信****,它进行批量置换,以便每个 rank 暂时拥有其矩阵的完整梯度,运行 muon,然后批量置换回来。这可能需要填充,因为许多张量被打包到连续缓冲区中,这可能会改变预期的大小。然而,这需要更少的集合通信,扩展性更好。
基于 Muon,Kimi K2 引入了 *MuonClip*,一种防止注意力 logits 爆炸的稳定化技术,这是大规模训练中常见的失败模式。其他策略包括 logit soft-cap,它对 softmax 前的 logits 应用 裁剪,或 QK-norm,它对 QK 矩阵应用 LayerNorm。然而,这些会导致缩放点积爆炸(使边界太晚)和 logit soft-cap 中模型不稳定区域周围梯度扭曲的问题,以及 key 矩阵在推理期间不被物化(从潜在变量投影)。
对于每个注意力头 ,考虑 、 和 (头 的 query、key 和 value 矩阵)。对于批次 和输入表示 ,将****最大 logit**** 定义为每个头的标量,作为 softmax 的最大输入:
其中 是 query/key 向量的维度, 和 索引序列中的位置, 缩放因子匹配标准注意力缩放。设置 (所有头的最大值)和目标阈值 (控制裁剪何时激活的超参数)。想法是每当 超过 时重新缩放 和 (头 的 key 和 query 投影权重矩阵)。此外,(全局裁剪因子),一种方法是同时裁剪所有头:
其中 指数对 强制乘法权重衰减;通常, 以确保对 query 和 key 的等比例缩放。然而,并非所有头都表现出爆炸 logits,这促使基于 的每头裁剪,这对 MHA 更直接但对 MLA 不太直接。MLA 的挑战是 key 从潜在变量投影而不是直接物化,因此裁剪必须应用于潜在到 key 的投影权重和潜在变量本身。他们仅在 和 (头特定组件)上应用裁剪,按 缩放,(头特定旋转)按 缩放,以及 (共享旋转)。除此之外,主 muon 算法被修改以匹配 Adam RMS 并启用权重衰减。对于每个权重 :
其中 和 是权重矩阵 的维度, 是适应矩阵大小的更新幅度的缩放因子(匹配 Adam 的 RMS 缩放行为),其他符号遵循标准 Muon 算法中的相同定义。权重衰减项 在梯度更新之前乘法应用。
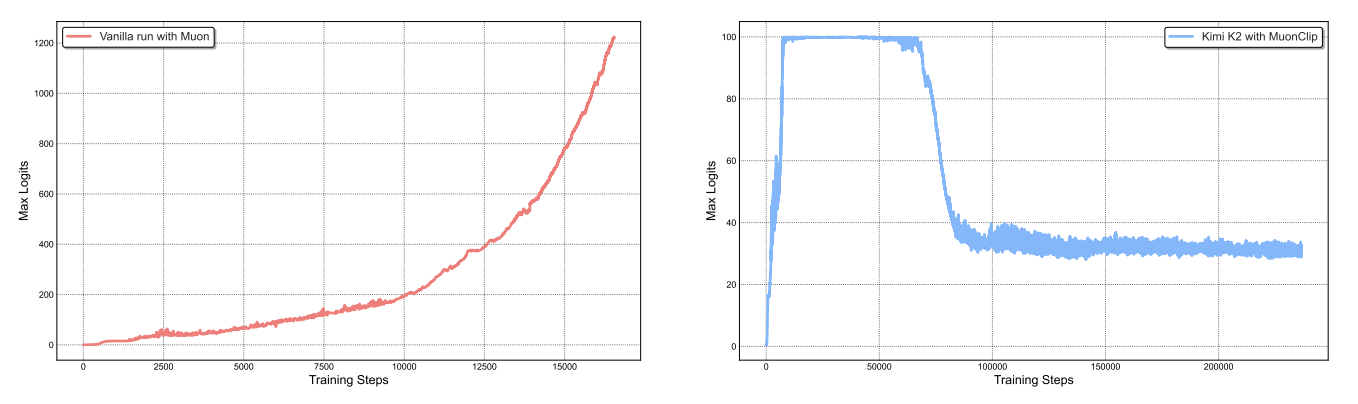
图 6:左:9B 激活、53B 总计 MoE 的中等规模训练运行,注意力 logits 快速发散。右:KimiK2 使用 MuonClip 和 的最大 logits,最大 logits 最终在约 30% 的训练步骤后衰减到稳定范围。来自 Kimi K2。
学习率(learning rates)
学习率有自己的生命周期:它们通常热身(对于短训练,通常为训练步骤的1%-5%,但大型实验室固定热身步骤)从零开始以避免混乱,然后在稳定到良好的最小值后退火。余弦退火曾经是首选调度器,但由于余弦周期需要匹配总训练持续时间,因此它也不灵活。替代方案包括warmup-stable-decay (WSD) 和 multi-step;在最后 x% 的 token 中,前者线性衰减学习率,而后者进行离散下降。对于 WSD,通常分配 10-20%用于衰减阶段,匹配余弦退火;在多步中,80/10/10 也匹配余弦退火,而 70/15/15 和 60/20/20 可以优于它。Deepseek-v3在衰减下降之间使用余弦退火,并在最终急剧步骤之前添加一个常量阶段。
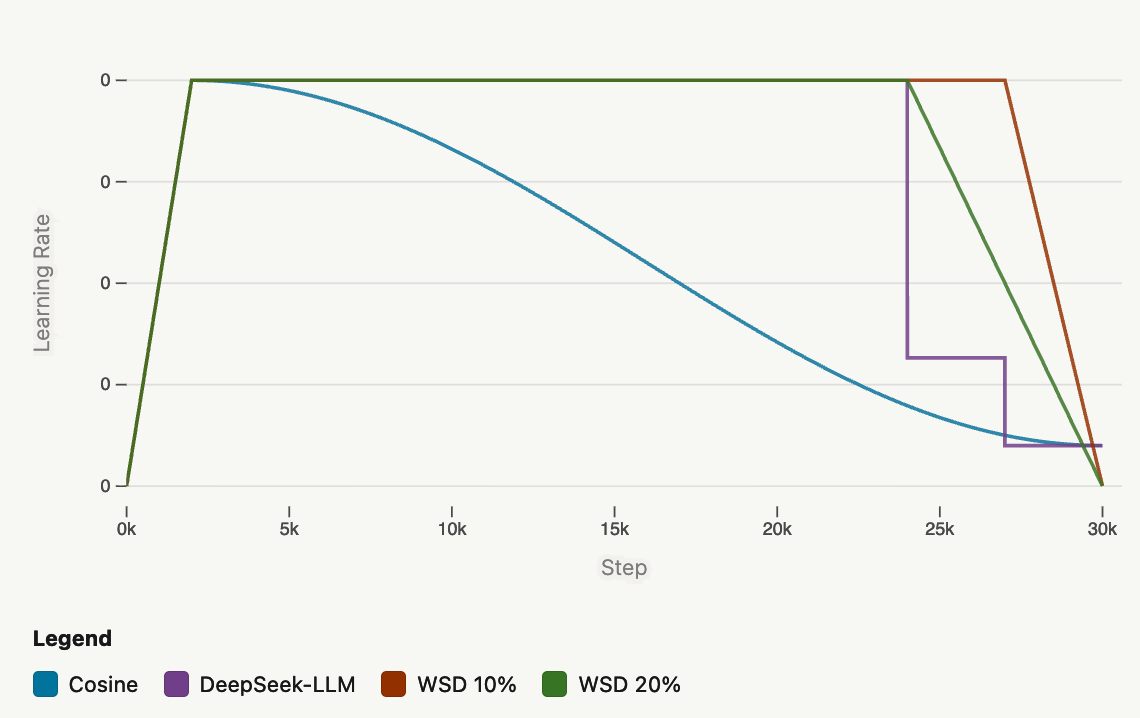
Hugging Face 的消融实验(在他们的 1B 模型上)表明,在 WSD 的衰减开始之前,WSD 往往表现不如余弦退火,但一旦进入衰减阶段,WSD在损失和评估指标方面显示出几乎线性的改进,这使得它在结束时能够赶上余弦退火。在对学习率进行进一步消融后,Hugging Face 团队确定了2e-4;增加会导致长训练运行期间不稳定的潜在风险增加。Kimi K2 也使用 WSD:前 10T 使用 2e-4 学习率,经过 500 步热身,然后 5.5Ttoken 使用从 2e-4 到 2e-5 的余弦衰减。
WSD 调度尤其有助于消融实验,因为它不需要为不同的 token 计数重新开始相同的运行,因为我们可以只重新训练结束部分(学习率衰减),同时保持前面部分。
batch size
存在一个关键的临界批量大小:太小可能会未充分利用计算,太大则模型需要更多 token 才能达到相同的损失。尽管如此,更大的批量大小提供更有效的梯度估计,并且更受欢迎。
一个有用的代理是,对于像 AdamW 或 Muon 这样的优化器,如果批量大小增加 倍,那么学习率应该按 倍缩放。直观地说,更大的批量提供更稳定的梯度估计(更低的方差),因此我们可以承受更大的步长。从数学上讲,协方差按 收缩,基于SGD 参数更新 ,我们有 ,其中 是原始批次大小。为了保持相同的更新方差,我们需要 。
随着训练的进行,临界批量大小增长。最初,由于模型正在进行大更新,很大,因此模型应该有较小的临界批量大小。在模型稳定后,更大的批量变得更有效。这激发了批量大小热身的想法。
不平衡的小批量可能在序列打包或数据分布创建具有高度可变序列长度或域组成的批量时出现,这可能导致破坏训练的梯度方差;当某些专家或模型组件接收不成比例的多或少的token 时,尤其如此。
Arcee 引入**随机顺序文档缓冲区 (RSDB) **来减少批量内相关性。在对文档进行分词后,它通过将 token 序列作为 RSDB 中的条目加载,读取头在索引0 处;重复此操作直到 RSDB 已满。从 RSDB 中随机采样的文档中的随机采样索引,基于读取头和索引读取 token并添加到单独的序列缓冲区。读取头位置更新,如果序列缓冲区已满,我们返回;否则,我们随机选择另一个文档索引并继续将 token读取到序列缓冲区,重复直到序列缓冲区已满。
内部缓冲区大小(在 Trinity Large 中:每个 GPU 8192)设置为用户指定缓冲区值的两倍,并在缓冲区达到用户指定值(在 Trinity Large
中:每个 GPU 4096)或需要清除旧文档/可以加载新文档时重新填充。Arcee 发现此优化显著提高了数据加载器性能。
缩放法则scaling laws
缩放法则(例如 Chinchilla 缩放法则)为确定如何随着模型大小的缩放而积极/保守地更新超参数提供了有用的近似方法。
首先,,其中 是以 FLOPs 衡量的计算预算, 是参数数量, 是训练 token 数量。 是根据每个参数的FLOPs 数量的经验估计得出的。
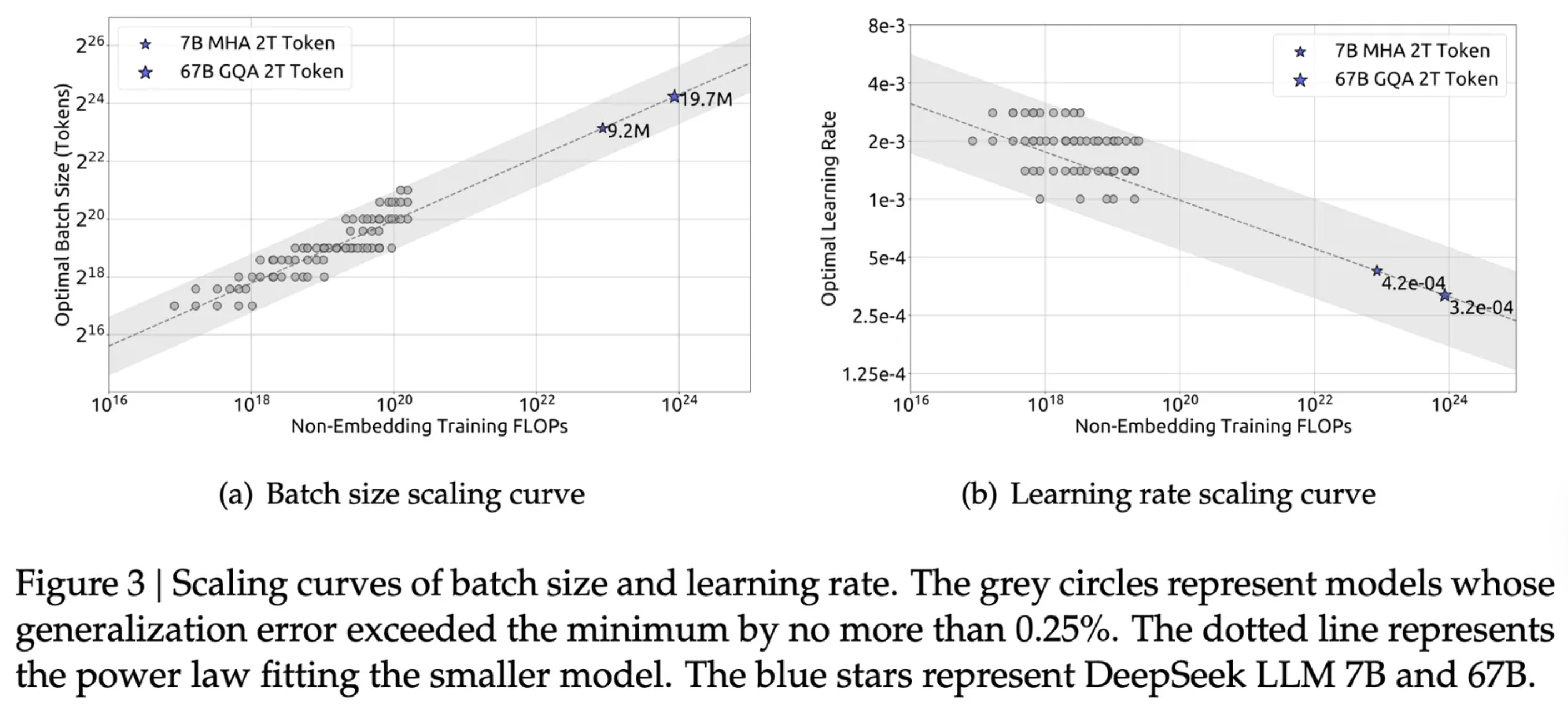
最初,缩放定律表明语言模型大小是主要约束,导致具有 175B 参数但仅在 300B token 上训练的 GPT-3模型。重新推导发现训练持续时间可以比大小提高更多收益;他们发现 GPT-3 的计算最优训练应该消耗 3.7T token。
然而,缩放法则几乎从未被严格遵循。最近,实验室一直在"过度训练"模型,超出缩放法则建议的训练持续时间(例如,Qwen 3 在 36T token上训练)。此外,"计算最优"缩放法则不考虑更大的模型在训练后由于推理而更昂贵。为此,Hugging Face 决定在 3B 模型上训练 11Ttoken。相比之下,Kimi K2 的 1T 模型包含 15.5T 预训练 token。
虽然一般缩放法则提供指导,但 Kimi K2 的缩放法则分析揭示了模型特定的见解。他们表明,增加稀疏性(专家总数与激活专家数量的比率)对于固定FLOPs 产生实质性的性能改进,因此他们将 MoE 专家数量增加到 384(DeepSeek-V3 中为 256),同时将注意力头减少到 64(DeepSeek-V3中为 128)以减少推理期间的计算开销。他们确定稀疏度为 48,激活 384 个专家中的 8 个,并发现将注意力头从 128 减少到 64 牺牲了0.5% 到 1.2% 的验证损失,但推理 FLOPs 减少了 45%。
数据整理与预训练
即使有完美的架构,模型的性能仍然严重依赖于其训练数据;再多的计算或优化也无法弥补在错误内容上的训练。为此,关键在于组装正确的数据混合,平衡训练目标并调整数据比例。这尤其困难,因为在固定计算预算下,增加一个比例必然会减少另一个,从而损害性能。
已经存在大型预训练数据集,如 FineWeb2 和 The Pile。然而,仍然存在大量信息差距,因此最近的模型还依赖于数学和编码等领域的专门预训练数据集。
一个考虑因素是数据质量。当然,在可能的最高质量数据上训练是可取的。但对于 T token的训练预算,由于高质量数据有限,仅过滤它会导致重复数据,这可能有害。因此,理想的混合包括更高和更低质量的数据。
另一个考虑因素是模型安全性。对于 gpt-oss-120b,OpenAI 通过在预训练中过滤有害内容来解决这个问题,重点关注危险的生物安全知识。他们使用GPT-4o 中使用的 CBRN(化学、生物、放射性和核)预训练过滤器。
多阶段训练
多阶段训练,即随着训练进展而演变数据混合的想法,可以更好地最大化高质量和低质量数据,因为 LM的最终行为在很大程度上由训练结束时看到的数据决定。因此,这激发了将更高质量数据保存到后期的策略。这引入了另一个变量,即何时开始更改混合,以及性能驱动干预的一般原则:如果某个基准开始停滞,这是引入该领域高质量数据的信号。
多阶段训练的核心直觉:
- 早期阶段:使用大规模、多样化的数据建立广泛的知识基础
- 中期阶段:引入更高质量的数据,细化模型能力
- 后期阶段:使用最高质量的数据,塑造最终行为
这种策略类似于课程学习,但更侧重于数据质量而非难度。
消融实验
虽然架构消融在较小的模型上进行(例如,在 1B 模型上训练以用于 3B模型),但数据混合消融在规模上进行,因为较大的模型具有理解各种领域的更大容量。此外,退火消融在主运行的检查点上进行(如 11T 中的7T token),以确定何时引入哪些数据集。
为了确定最佳数据比例,最近的模型通常使用验证损失或基于评估目标和数据域最小化的保留损失。然而,其中一些方法倾向于收敛到分发。
token utility
****Token 效率*是训练期间每个消耗的 token 实现多少性能改善。这可以通过更好的*token 效用****来改善,即每个 token 贡献的有效学习信号;这激发了寻找高质量 token 的最优平衡,因为它们应该被最大化利用,但也受到限制以防止过拟合和泛化降低。
Kimi K2 在知识和数学领域使用****数据重述****。对于知识,这以风格和视角多样化的提示形式重述文本,分块自回归生成逐渐构建长文档的重述版本,以及保真度验证以确保语义对齐。在主训练运行中,每个语料库最多重述两次。对于数学,通过重述为"学习笔记风格"和翻译成其他语言来增加多样性。
Kimi K2 的数据重述可以看作是对训练数据的数据增强。从信息论角度:
- 原始数据 包含信息
- 重述数据 是 的一个"视图",满足 (保留标签信息)
- 但 和 在表示空间中有不同的分布
通过引入多个重述视图,模型被迫学习不变表示——对表面形式的变化鲁棒,但保留语义内容。这类似于对比学习中的多视图学习。
预训练数据
SmolLM3
Hugging Face 的目标是构建一个在数学和编码方面也出色的多语言模型。在多阶段训练的第 1 阶段,他们在英语网络数据、多语言网络数据、代码数据和数学数据之间使用 75/12/10/3 的分割。
-
英语网络数据:他们对 FineWeb-Edu(教育和 STEM 基准测试)和 DCLM(常识推理)的混合进行消融,这是训练时两个强大的开放英语网络数据集,发现 60/40 或 50/50 的分割最好。后来,他们添加了其他数据集,包括 Pes2o、Wikipedia & Wikibooks 和 StackExchange。
-
多语言网络数据:选择了五种欧洲语言,数据来自 FineWeb2-HQ。选择了其他语言的较小部分,如中文或阿拉伯语,以允许其他人继续预训练 SmolLM3。最终,他们发现网络混合中 12% 的多语言内容最好。
-
代码数据:主要从 The Stack v2 and StarCoder2 提取,包括 16 种语言、Github PR、Jupyter/Kaggle notebook、Github issues 和 StackExchange 线程。尽管研究表明代码可以改善 LM 在编码之外的性能,但他们没有观察到这种效果(而是英语基准测试的退化),使用推荐的代码混合。他们遵循将最好的数据延迟到最后的原则,延迟添加其教育过滤的子集 Stack-Edu。
-
数学数据:使用 FineMath3+、InfiWebMath3+、MegaMath 以及指令/推理数据集如 OpenMathInstruct 和 OpenMathReasoning。
对于新阶段(使用总共 11T token 中约 7T 的检查点),他们在基线混合和新数据集之间使用 40/60 分割。SmolLM3 有三个阶段:8T token @ 4k 上下文用于基础训练,2T token @ 4k 上下文用于高质量注入,以及 1.1T token @ 4k 上下文的推理/问答阶段。
Hermes 4
使用来自 DCLM 和 FineWeb 的数据,Nous 首先使用余弦相似度为 0.7 的嵌入进行语义去重,然后使用 LLM-as-judge 过滤不完整或格式错误的消息。然后,他们通过 *DataForge* 处理预训练数据,这是一个基于图的合成数据生成器,允许大型和复杂的结构。通过在有向无环图中进行随机游走,其中节点实现从 struct → struct 的映射,使得如果从节点 到节点 有边,则 保证的后置条件必须满足 的前置条件。使用此工作流生成 QA 对,包括中间转换到其他媒介(例如,将维基百科文章转换为说唱歌曲)、问题生成,然后使用 LLM-as-judge 对指令和响应进行评分的问题/答案注释。此外,为了找到特殊兴趣的数据稀缺领域的覆盖集,他们递归地(深度优先搜索)生成子领域的分类法,其中叶子是提示,LLM 枚举 个子领域以形成分区。
DataForge 生成的数据用于预训练和后训练阶段,具体细节在下面的后训练数据部分提供。
数据总结
- 数据质量和多样性是模型性能的关键决定因素。
- 多阶段训练策略可以最大化不同质量数据的价值。
- 消融实验对于确定最佳数据比例和引入时机至关重要。
- 数据过滤和去重是确保训练效率的必要步骤。
- 领域特定数据对于提升模型在专业任务上的表现非常重要。
中训练(mid-training)
中训练是预训练和后训练之间的中间步骤,基础模型在大量领域特定 token 上进一步训练,特别是塑造模型专注于编码或推理等核心技能。通常,中期训练的决定是在初始 SFT 实验之后才做出的,因为它们可能揭示性能差距,表明需要在某些领域进行中期训练。但如果目标是激发浅层能力如风格或对话,计算最好花在后训练上。
一些配方包括额外的长上下文阶段;例如,Qwen3 首先在 4k 上下文训练 30T token,然后是主要在 STEM 和编码上的 5T 高质量 token 推理阶段,最后是 32k 上下文长度的长上下文阶段。
SmolLM3 也这样做,但他们不是直接从 4k 扩展到 128k,而是顺序从 4k 扩展到 32k 到 64k 到 128k,这允许模型在进一步推进上下文长度之前在每个长度上适应。对网络文章或书籍等长上下文文档进行上采样可以改善长上下文,但 Hugging Face 没有观察到改善;他们假设这是因为他们的基线混合已经使用 RNoPE 包含了长文档。
要从 4k 到 32k,然后到 64k,他们使用 RoPE ABF 并将基础频率分别增加到 2M 和 5M。像 10M 这样的基础频率在 RULER 长上下文基准测试上略有改善,但损害了 GSM8k 等短上下文任务,因此被放弃。要达到 128k,他们发现从 64k 检查点使用 YARN(而不是从 32k 四倍增加)产生更好的性能,这证实了在接近所需推理长度训练有益于性能的假设。
Kimi K2 将学习率从 2e-5 衰减到 7e-6,在 4k 序列长度上训练 400B token,然后在 32k 序列长度上训练 60B token。要扩展到 128k,他们使用 YARN。
虽然中期训练数据通常来自网络数据,但另一种强大的方法是使用来自更好模型的蒸馏推理 token,正如 Phi-4-Mini-Reasoning 从 DeepSeek-R1 所做的那样。当应用于基础模型时,蒸馏中期训练使 AIM24 等基准测试分数提高 3 倍,MATH-500 提高 11 分,GPQA-D 提高近 6 分。SmolLM3 也进行蒸馏中期训练。他们考虑了包括来自 DeepSeek-R1(4M 样本)和 QwQ-32B(1.2M 样本)的推理 token 的数据集,但决定将 Mixture of Thoughts 数据集延迟到最终 SFT 混合中使用。他们发现,如果基础模型在预训练期间还没有看到大量推理数据,进行一些中期训练几乎总是有意义的,因为他们注意到 /no_think 推理模式在推理基准测试上也有改善。
后训练
后期训练是模型开发的最后阶段,包括监督微调 (SFT)、偏好优化 (PO) 和强化学习 (RL) 等步骤。这个阶段的目标是将预训练模型转变为对用户友好、符合人类偏好的实用工具。
评估
考虑到当今 LLM 作为编码智能体和能够推理的助手的标准,研究人员关心四大类评估:
-
知识:对于小模型,GPQA Diamond 测试研究生级别的多选题,比 MMLU 等其他评估提供更好的信号。另一个测试事实性的好方法是 SimpleQA,尽管小模型由于知识有限表现差得多。
-
数学:AIME 仍然是领先的基准测试,MATH-500 等其他基准为小模型提供有用的健全性检查。
-
代码:LiveCodeBench 通过竞争性编程跟踪编码能力,而 SWE-bench Verified 是更复杂的替代方案但对小模型更难。
-
多语言:除了 Global MMLU 针对模型预训练/应该表现良好的语言外,没有太多选择。
这些评估测试以下内容:
-
长上下文:RULER、HELMET 以及最近发布的 MRCR 和 GraphWalks 基准测试长上下文理解。
-
指令遵循:IFEval 使用验证器对可验证指令进行验证,IFBench 以更多样化的约束集扩展它。对于多轮,Multi-IF 和 MultiChallenge 更受青睐。
-
对齐:带有人类注释者和公共排行榜的 LMArena 是最受欢迎的。但由于这些评估的成本,LLM-as-judge 评估已经出现,包括 AlpacaEval 和 MixEval。
-
工具调用:TAU-Bench 测试模型在客户服务环境中使用工具解决用户问题的能力,包括零售和航空。
为了防止过拟合,还包括封装鲁棒性或适应性的评估,如 GSMPlus,它对 GSM8k 的问题进行扰动。另一种方法是使用间隔评估或氛围评估/竞技场,如手动探测模型行为。其他技巧包括使用小子集加速评估(特别是如果与更大评估有相关性),固定 LLM-as-judge 模型(如果评估需要),将消融期间使用的任何内容视为验证,使用 avg@k 准确率,尽量不要(不要)benchmax!
后训练数据
Intellect 3
首先值得一提的是,Intellect-3 是一个 106B 参数的 MoE(12B 激活),在 Z.ai 的 GLM-4.5-Air 基础模型之上进行后训练,他们有自己的后训练栈,包括 prime-rl(大规模异步 RL 的开放框架)、verifiers 库(用于从其 Environments Hub 进行训练和评估)、沙盒代码执行和计算编排。
与 Environments Hub 集成,Prime 在旨在提高编码和推理能力的多样化挑战性环境混合上进行训练。对于数学,他们设计了一个考虑长 CoT 推理的环境,包含来自 Skywork-OR1、Acereason-Math、DAPO 和 ORZ-Hard 的 21.2K 道挑战性数学问题,所有这些都是从 AIME、NuminaMath、Tulu3 math 等策划的数据集,测试从多选题到证明到涉及图形的困难数学问题。即使使用验证器,仍有相当数量的假阴性,因此他们额外使用 opencompass/CompassVerifier-7B 作为 LLM-judge 验证器。对于科学(主要是物理、化学和生物),他们从 MegaScience 过滤了 29.3K 道挑战性问题,同时使用 LLM-judge 验证和标准数学验证器。对于逻辑(如数独或扫雷游戏),从 SynLogic 改编了 11.6K 问题和验证器。
对于代码,他们主要使用其 Synthetic-2 dataset 以及 Prime Sandboxes 来验证解决方案。他们还开发了两个支持 R2E-Gym、SWE-smith 和 Multi-SWE-bench 等常见格式脚手架的 SWE 环境,用于在配备 Bash 命令和编辑工具时修复 Github 项目中的问题。此外,智能体的最大轮次数设置为 200。
Prime 还通过其网络搜索环境专注于深度研究能力,该环境为模型提供一组搜索工具。环境要求模型使用工具回答数据集中的问题,使用 z-AI’s DeepDive dataset 获得 1 或 0 的奖励,其中 1K 样本用于 SFT 轨迹生成,2.2K 样本用于 RL。在 Qwen/Qwen3-4B-Instruct-2507 上测试时,34 批次大小的 26 步 SFT,然后是组大小 16 和批次大小 512 的 120 步 RL,足以达到 0.7 的平均奖励。
Hermes 4
他们使用 300k 提示,主要来自 WebInstruct-Verified、rSTAR-Coder 和 DeepMath-103k 的 STEM 和编码,并对 >2k 字符的提示进行去重和过滤。
Nous 使用 Atropos 对约 1k 个任务特定验证器进行拒绝采样。用于生成数据集的一些环境包括:
-
答案格式训练:奖励简洁呈现的最终答案,如 LaTeX 中的 ,但采样了超过 150 种输出格式。环境还强制执行
<think和</think分隔符。 -
指令遵循:利用 RLVR-IFEval 进行可验证任务集,带有约束指令如"你回答中的每第 个词必须是法语。"
-
模式遵循:促进生成(从自然语言提示和模式生成有效 JSON 对象)和编辑(识别和纠正格式错误 JSON 对象中的验证错误)
-
工具使用:通过训练模型通过
<tool_calltoken 生成推理和产生工具调用来促进智能体行为。
Kimi K2
Kimi K2 选择关注的一个关键能力是工具使用。虽然 -bench 和 ACEBench 等基准测试存在,但由于成本、复杂性、隐私和可访问性,大规模构建真实世界环境通常很困难。Kimi K2 基于 ACEBench 的数据合成框架大规模模拟真实世界工具使用场景:
- 工具规范生成:从真实世界工具和 LLM 合成工具构建大型工具规范仓库
- 智能体和任务生成:对于从仓库采样的每个工具集,生成一个智能体在相应任务上使用该工具集
- 轨迹生成:对于每个智能体/任务,生成智能体完成任务的轨迹
使用来自 Github 的 3k+ 真实 MCP 工具和在金融交易、软件应用和机器人控制等领域分层生成的 20k 合成工具。通过不同系统提示与不同工具组合的组合确保智能体之间的多样性,任务使用带有 LLM judge 的明确评分标准进行评分。
对于 RL,Kimi K2 对数学、STEM 和逻辑任务的处理与其他模型类似。编码和软件工程主要来自竞争级编程问题和 GitHub 的PR/issues。对于指令遵循,他们使用两种验证机制:通过代码解释器对可验证输出进行确定性评估,以及对不可验证输出进行 LLM-as-judge 评估。数据使用专家精心设计的提示和评分标准构建,受 AutoIF 启发的智能体指令增强,以及专门针对特定失败模式或边缘情况生成额外指令的微调模型。
聊天模板(chat template)
设计/选择一个好的对话模板,需要考虑几个重要因素包括****系统角色可定制性*、*工具调用*、*推理*和*与推理引擎的兼容性****(如 vLLM 或 SGLang)。Qwen3 和 GPT-OSS 满足所有标准,Qwen3 专为混合推理设计。
Qwen3:
1 | <|im_start|>system |
在 SmolLM3 中,尽管也专为混合推理设计,但他们丢弃了对话中除最后一轮外的所有推理内容,以避免在推理期间扩大上下文,但对于训练,保留推理 token 以正确调节模型很重要。因此,Hugging Face 编排了自己的对话模板,满足所有标准。Vibe tests最初揭示了一个 bug,即没有将自定义指令传递到其自定义模板中,但这很快被修补。
虽然从 Qwen3 模板获得灵感,但 Intellect-3 总是推理(不是混合),通过主要在仅推理 SFT 轨迹上训练;他们使用 qwen3_coder 工具调用解析器和 deepseek_r1 推理解析器以确保推理链被一致表示。
gpt-oss-120b 使用 harmony 对话模板,引入了决定每条消息可见性的"通道"。例如,final 用于显示给用户的答案,commentary 用于工具调用,analysis 用于 CoT token。这允许模型将工具调用与 CoT 交错。
Hermes 4 发现,将对话模板中的 assistant 改为 me 会导致显著不同的行为,Hermes 4 通过在识别出助手轮次使用的 token 的敏感性后,将助手更改为第一人称标识符来适应 Llama 3 的对话模板:
- assistant 模板:模型倾向于更正式、更"助手式"的回应
- me 模板:模型表现出更个性化、更直接的风格
这导致明显不同的行为,更多内容在“行为与安全”章节的“行为与潜在能力”子章节中探讨。
DeepSeek-R1-Zero 的对话模板看起来与其他模板非常相似,但另外包括 标签以提供最终答案。
监督微调 (SFT)
大多数后训练流程以****监督微调(SFT)*开始,因为它与 RL 相比成本较低,由于目标函数简单使得SFT 比较稳定,并且可通过SFT 快速建立可用 baseline。通常,基础模型过于粗糙,无法从更高级的后训练方法中受益。SFT 的数据 通常以***从更强模型蒸馏****的形式出现。强模型可能因成功而跳过 SFT 阶段,因为没有更强的模型可以蒸馏(DeepSeek R1-Zero 就是这种情况)。
R1-Zero的意义:证明了在足够强的Base Model + 可验证任务 + 高效RL算法条件下,SFT并非必需,模型可以通过纯强化学习自主发展出复杂推理能力。这为超越人类标注数据限制、实现真正的自主改进开辟了新路径。
SFT 的数据集策划很重要;数据集表面看起来可能很好,但在这些数据集上训练的模型可能最终过度偏向某些领域,如科学。为此,Hugging Face 策划了一个约 100k 例子和 76.1M token 的数据混合,主要包括指令遵循、推理和可操控性,用于思考和非思考模式。重要的是,数据应该在模式之间配对,否则没有指示何时给出简洁答案或使用扩展推理。
原则:
- 质量 > 数量(100K精选 > 1M粗糙)
- 分布平衡(避免科学/代码过度索引)
- 模式配对(同一问题的多形态回答)
- 可引导性(用户能控制输出风格)
- 显式信号(
标签等模式标记)
对于训练,还有其他考虑:全微调 vs 更参数高效的方法如 LoRA 或 QLoRA,专门的内核如 FlashAttention(通过在后向传播期间即时重新计算注意力来减少内存使用,以计算换内存)或 SonicMoE 等以提高计算效率,仅对assistant token 掩码损失,所需的并行类型,学习率调整,以及序列长度调整以匹配数据分布以加速训练(对更大数据集更有用)。
训练考虑:
- 全微调 vs 参数高效方法(LoRA、QLoRA)
- 专用内核(FlashAttention、SonicMoE)
- 仅对助手 token 进行损失掩码
- 学习率调整
- 序列长度调整以匹配数据分布
*Cute cross-entropy kernel*(CCE)是一个内存高效的 CUDA 内核,用于计算交叉熵损失。CCE 不在全局内存中物化完整的 logit 矩阵,而是仅计算正确 token 的 logit,并使用更快的内存层级即时评估所有词表项的 log-sum-exp,大幅减少内存消耗。该内核利用 softmax 的稀疏性,跳过对数值精度以下贡献可忽略的元素的梯度计算。这使其对具有大词表的模型特别有价值。
在 Intellect-3 中,Prime 将 SFT 分为两个阶段:通用推理 SFT 和智能体 SFT。在第一阶段,他们使用来自 Nemotron 的后训练数据集和 AM-DeepSeek-R1-0528-Distilled的数据集,包括数学、代码、科学、工具、聊天和指令分割,总计 9.9B token。在第二阶段,他们针对智能体行为、工具使用和长程控制(gpt-oss-120b 也针对智能体行为和工具使用),使用开源智能体数据集如 SWE-Swiss 和使用 DeepSeek-R1 从 Environments Hub 合成生成的数据集的混合。除了微调智能体行为的目的外,此阶段还具有将模型推向更长有效上下文长度的效果。使用上下文并行,他们从 65K 上下文窗口扩展到 98K。
在 Hermes 4 中,他们也进行两个阶段的 SFT,都围绕推理。他们指出,尽管在最多 16k token 长度的序列上训练,但推理任务上的推理长度经常超过 41k token。因此,他们进行第二阶段,教模型在 30k token(他们的预算)生成结束的 标签。这种在固定 token 计数的插入允许模型学习计数行为(“当你达到 个 token 时,停止”),同时确保模型自身的分布不会显著改变。这也避免了在完整自生成输出上递归训练时的模型崩溃问题,这会导致分布收窄和质量退化。
capabilities
Hugging Face 团队发现将单轮推理数据泛化到多轮数据存在问题,源于区分轮次之间的 /think 和 /no_think 标签的困难。因此,他们使用 Qwen3-32B 构建了一个新数据集 IFThink,*将单轮指令增强为多轮对话*,带有可验证指令和推理轨迹;这大幅改善了多轮推理。
掩码用户轮次(Masking user turns)是另一个设计选择,因为否则也会对用户查询计算损失,牺牲生成高质量助手响应以预测用户查询。在实践中,掩码对下游评估没有巨大影响,但在大多数情况下仍产生几个点的改善。
sequence packing
Sequence packing是另一个改善训练效率的选择。想法类似于intra-document masking,序列被打包到批次中以避免通过过多填充 token 浪费填充计算,但有最小化批次边界间文档截断的额外约束。
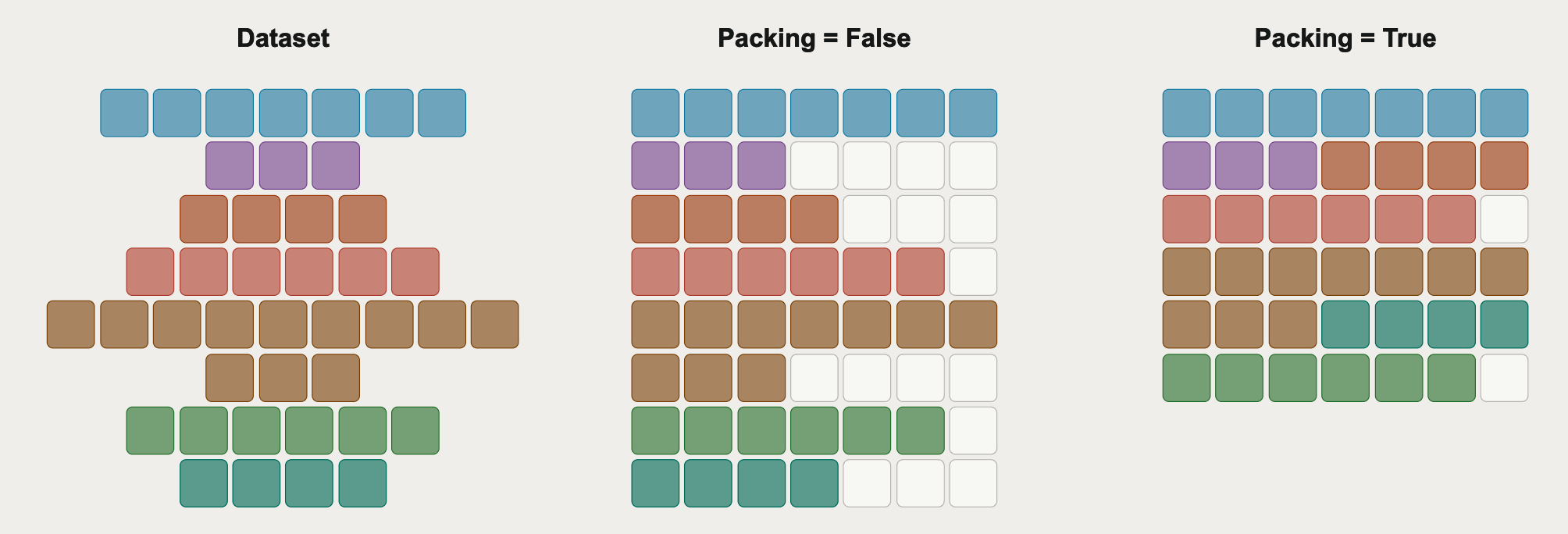
图 9:序列打包策略的比较。来自 Hugging Face。
上图中,最后的打包方法使用****最佳适应递减*(在 TRL 中实现),其中每个序列被放置在插入后最小化剩余空间的批次中。Hermes-4 使用的另一种方法是*首次适应递减****,将序列放置在第一个有足够剩余空间的批次中,实现 的批次效率。
尽管产生高达 33x 的 token/批次/优化步骤,但对于固定的 token 预算,打包改变了训练动态,因为更多数据意味着更少的梯度更新。这对每个样本更重要的更小数据集特别有害。128 的有效批次大小使 IFEval 等评估下降高达 10%;对于大于 32 的有效批次大小,平均性能下降(对于 SmolLM3 和数据集)。但对于大数据集,打包几乎总是有益的。
学习率与轮次(learning rate and epochs)
SFT 的学习率通常比预训练小一个数量级,因为模型已经学习了丰富的表示,激进的更新可能导致灾难性遗忘。而且因为 SFT 运行时间比预训练短得多,进行完整的学习率扫描是有意义的。对于 SmolLM3,3e-6 或 1e-5 的学习率效果最好。当启用打包时,由于更大的有效批次大小和相同 token 预算获得更少更新,进一步降低学习率更安全。
一旦确定了好的数据混合并调整了超参数,训练超过一个轮次(消融中通常做的)也会导致几个百分点的性能提升;在 LiveCodeBench v4 上,性能从第二到第三轮次几乎翻倍。
一个有趣的探索是预训练和后训练的优化器是否应该相同。AdamW 仍然是预训练和后训练的默认选择,当用 Muon 测试时,使用相同的优化器仍然产生最佳性能。
偏好优化 (PO)
因为 SFT 从根本上说是模仿学习的一种形式,极大的 SFT 数据集可能由于收益递减或数据中未包含的失败模式而变得冗余。另一个有用的信号是偏好,即响应 A 或 B 哪个更受偏好,这使模型性能能够扩展到超越 SFT 单独的限制。此外,偏好优化比 SFT 需要更少的数据,因为起点已经很强。
对于生成偏好数据集,有几种方法:
-
强 vs 弱:对于固定提示 ,强模型 和弱模型 ,总是偏好强模型的输出 而非弱模型的输出 。这很容易构建,因为强模型的输出可靠地更好。使用 DPO 等方法,可以强制执行强响应和弱响应之间的差异。
-
带评分的在线策略:使用相同的模型和提示,生成多个候选响应,并让外部模型(例如 LLM-as-judges)使用评分标准或验证器对响应进行评分,提供偏好标签。这需要校准良好且可靠的 LLM-as-judge,但也允许持续引导偏好数据。
虽然偏好优化通常被认为是一种提高有用性或对齐程度的手段,但它也能教会模型更好地推理,例如利用强弱偏好。
通常有三个超参数会影响训练动态:
-
学习率:当测试从比 SFT 中使用的学习率小 2x 到 200x 的大小时,Zephyr7B 发现使用小 10x 的学习率提供最佳性能改善,SmolLM3 最终使用小 20x 的学习率(1e-6)来平衡
/think和/no_think模式之间的性能。 -
:范围从 0 到 1,控制是更接近参考模型(低 )还是更接近偏好数据(高 )。如果太大,可能会抹去 SFT 检查点的能力,因此通常首选 0.1 或更高的 值。
-
偏好数据集大小:当测试从 2k 到 340k 对的大小时,性能基本保持稳定,尽管 Hugging Face 注意到超过 100k 对的数据集在扩展思考方面性能下降。就此而言,不要害怕创建自己的偏好数据,特别是考虑到推理已经变得多么便宜。
算法
除了普通的 DPO(直接偏好优化),研究人员探索了多种替代方案:
-
KTO(Kahneman-Tversky 优化):不是成对,KTO 根据样本是否标记为期望/不期望来分配更新,借鉴人类决策制定的想法,以及参考点 和类似奖励的对数比率项。
-
ORPO(odds ratio 偏好优化):通过将 PO 与 SFT 结合,通过整合的 odds ratio 项加入交叉熵损失。这使其计算效率更高,因为不需要使用 DPO 中用于计算 的单独参考模型。
-
APO(锚定偏好优化):不是只优化 DPO 中 和 之间的差异,APO-zero 强制 上升和 下降,而 APO-down 将 都推下(如果 的质量低于当前模型则有用)
Hugging Face 发现 APO-zero 具有最佳的整体域外性能。
**DPO **
**直接偏好优化(DPO)**通过将偏好学习问题重新表述为分类问题,避免了训练单独奖励模型的需要。给定一个偏好数据集,其中包含提示 、选择的响应 和拒绝的响应 ,DPO 优化以下目标:
其中 是策略模型, 是参考模型, 是控制偏离参考模型的 KL 散度惩罚强度的超参数。
PPO
**近端策略优化(PPO)**是一种强化学习算法,通过以下步骤迭代改进模型:
- 使用当前模型生成响应
- 使用奖励模型对响应评分
- 使用 PPO 目标更新模型:
其中 是概率比, 是优势估计。
GRPO
**组相对策略优化(GRPO)**是 DeepSeek-R1 使用的方法,它为每个提示生成一组响应,并使用组内相对比较来计算优势,而不是训练单独的价值函数:
其中 是第 个响应的奖励, 是组内所有响应的奖励向量。
偏好优化方法的选择考量:
方法 优点 缺点 DPO 简单、稳定、无需奖励模型 可能过度优化、对数据质量敏感 PPO 灵活、可结合多种奖励 需要奖励模型、超参数敏感 GRPO 无需价值函数、稳定 需要多次采样、计算成本高
强化学习 (RL)
SFT和PO可能会遇到瓶颈,因为从根本上说,它们优化的目标是生成与数据集外观相似的输出,而PO通常是离策略的,在多步奖励分配方面表现较弱。强化学习(RL)则通过提供奖励来提供帮助。通过与环境的交互传递信号。验证者可自动检查正确性并提供这些奖励信号,目标也可针对超越偏好标签进行优化。
在RLHF(基于人类反馈的强化学习)中,会提供人类比较数据,并训练一个奖励模型来预测人类偏好信号。随后,利用强化学习对策略进行微调,以最大化所学的奖励。这样一来,RLHF实现了策略内优化,因为它采用当前训练中使用的策略进行采样,并根据奖励模型给出的奖励进行更新。这也使得RLHF能够发现偏好数据集中未出现的行为模式。
在RLVR(带有可验证奖励的强化学习)中,这一方法由DeepSeek-R1推广开来。验证者会检查模型的输出是否符合特定标准(例如,是否给出了正确的数学答案或通过了所有代码单元测试),从而生成奖励信号,使整个过程更具可扩展性和客观性。随后,策略会被微调,以生成更多经过验证且正确的输出。当存在奖励漂移问题时(与基于学习的奖励模型相比,验证者提供的信号更加稳定),或者需要采用KL控制以防止策略崩溃,又或者在处理多步推理任务中的过时策略问题时,RLVR尤其具有价值。
虽然策略优化算法通常是在线策略的,如 GRPO,但在实践中,为了最大化吞吐量,它们实际上可能略微离策略。例如,在 GRPO 中,如果不冻结策略,顺序生成多个 rollout 批次并进行优化器更新,会使只有第一个批次在线策略,所有后续批次都离策略;这被称为飞行中更新(in-flight updates)。当吞吐量至关重要时(例如,大规模 RL 训练),当奖励漂移可能从过时策略累积时,当需要仔细监控推理和训练策略之间的 KL 散度时,以及当长 rollout 跨越多个策略更新时,飞行中更新最为重要。权衡在于训练效率和策略一致性;重要性采样裁剪(如 IcePop)等技术有助于缓解离策略偏差。
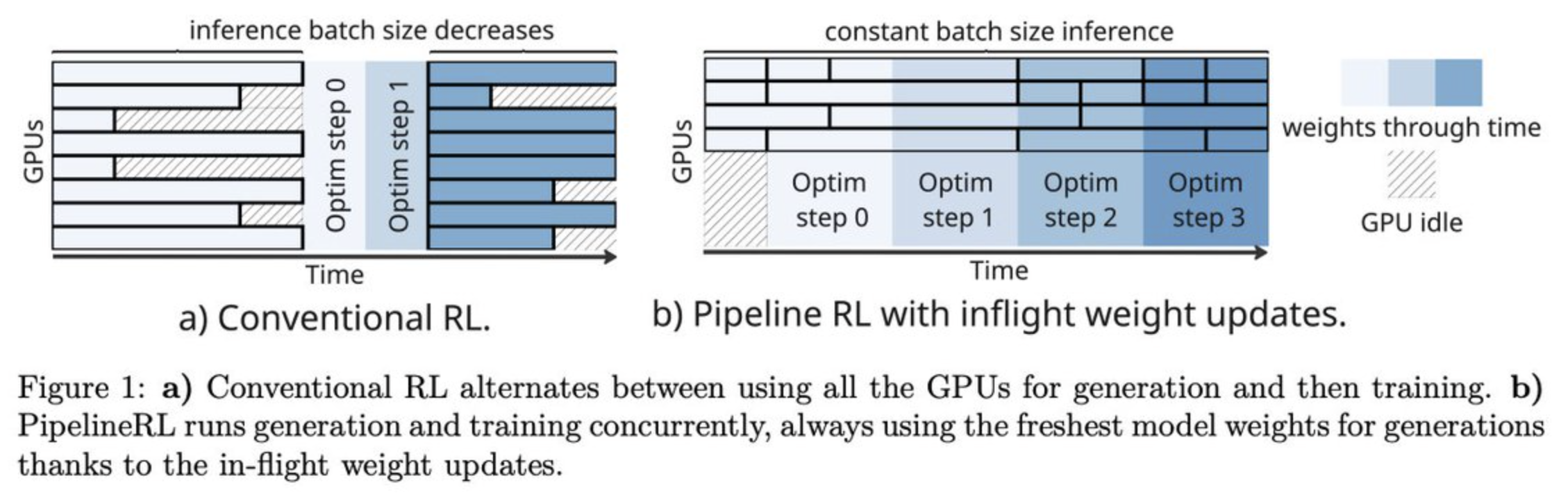
在 Intellect-3 的背景下,它在两个集群(一个用于训练,一个用于推理)之间使用 CPU 编排器,编排器持续轮询训练器以在新策略可用时更新推理池,推理池暂时停止生成以更新权重,然后继续 rollout。这样,长 rollout 可能由多个策略生成,但他们通过 max_off_policy_steps 参数限制策略漂移。此外,他们实现 IcePop 来稳定 MoE 训练:
其中 如果 时 ,否则为 。 的目的是考虑训练策略和推理策略之间的离策略性质,使它们不会在每个 token 上显著分歧。当重要性权重 落在 之外时, 将其裁剪为 0,有效地忽略该 token 对梯度的贡献。这是重要性采样背后的想法,其中 rollout 来自推理策略,但我们正在优化训练策略。Prime 使用默认值 。 和 在乘法意义上不必对称。原因之一是在 很小(大 )的罕见情况下,更紧的 会裁剪高熵 token,这会使学习动态变差。
Kimi K2 从其之前的模型 K1.5 采用了不同的策略优化方法:
其中 是采样响应的平均奖励, 是用于稳定学习的正则化参数,类似于 KL 散度。
另一个考虑是 PTX loss:预训练交叉熵损失。在联合 RL 训练期间,模型可能灾难性地遗忘有价值的高质量数据。因此,他们使用手工选择的高质量样本策划数据集,并通过 PTX loss 将其整合到 RL 目标中。优点是双重的:可以利用高质量数据,并且可以缓解 RL 期间任务过拟合的风险,从而实现更好的泛化。
为了在整个训练过程中平衡探索和利用,他们实施温度衰减。对于创意写作和复杂推理等任务,初始阶段的高温度对于生成多样化和创新的响应很重要;这可以防止过早收敛到局部最优,并促进发现有效策略。在后期阶段,温度被衰减(遵循调度),这样就不会有过多的随机性,也不会损害模型输出的可靠性和一致性。
Kimi K2 的温度衰减是一个退火策略:
- 早期高温度():鼓励探索,发现多样的响应策略
- 后期低温度():鼓励开发,精细化已发现的策略
这可以形式化为一个多臂老虎机问题,其中"臂"是不同的响应策略,温度控制探索的概率。
从优化角度,高温度对应于更"平坦"的损失景观,允许优化器逃离局部最小值;低温度对应于更"尖锐"的损失景观,允许精细化解决方案。
与其它模型相比,DeepSeek-R1-Zero显得尤为突出,因为它证明了即使在没有监督微调的情况下,强化学习同样可以发挥高效作用。该模型在推理任务上实现了强化学习的冷启动(具体而言,采用GRPO以降低训练成本;他们使用了1.04万步训练,批量大小为512,每400步更换一次参考策略,同时将Ir设为3e-6,KL系数设为0.001)。在奖励机制方面,它采用了两种类型的奖励:一种是基于回答正确性的准确度奖励,另一种则是格式奖励,用于强制模型将其思考过程置于“思考标签”之间。通过纯强化学习,DeepSeek-R1-Zero成功获得了稳健的推理能力,这充分验证了强化学习在有效学习和泛化推理方面的潜力。此外,模型还展现出了一些行为特征,例如反思(重重新评估先前步骤)以及探索多种解题思路,这些行为进一步提升了其推理能力。与训练初期相比,诸如“等待”或“失误”等反思性词汇的出现次数增加了5到7倍。值得注意的是,这种反思性行为的出现颇具突然性:在第4千至第7千步之间,这类词汇的使用还比较零星,但自第8千步之后,其使用频率便出现了显著飙升。
DeepSeek-R1-Zero 中反思行为的涌现(“wait”、“mistake” 等词的使用增加 5-7 倍)是一个相变现象:
- 4k-7k 步:偶尔使用,系统处于"无序"状态
- 8k 步后:显著尖峰,系统进入"有序"状态
这可以用自组织临界性来解释:RL 奖励函数(准确性 + 格式)创造了一个反馈循环,当模型偶然发现反思有助于提高准确性时,这个行为被强化,最终导致反思行为的"雪崩"。
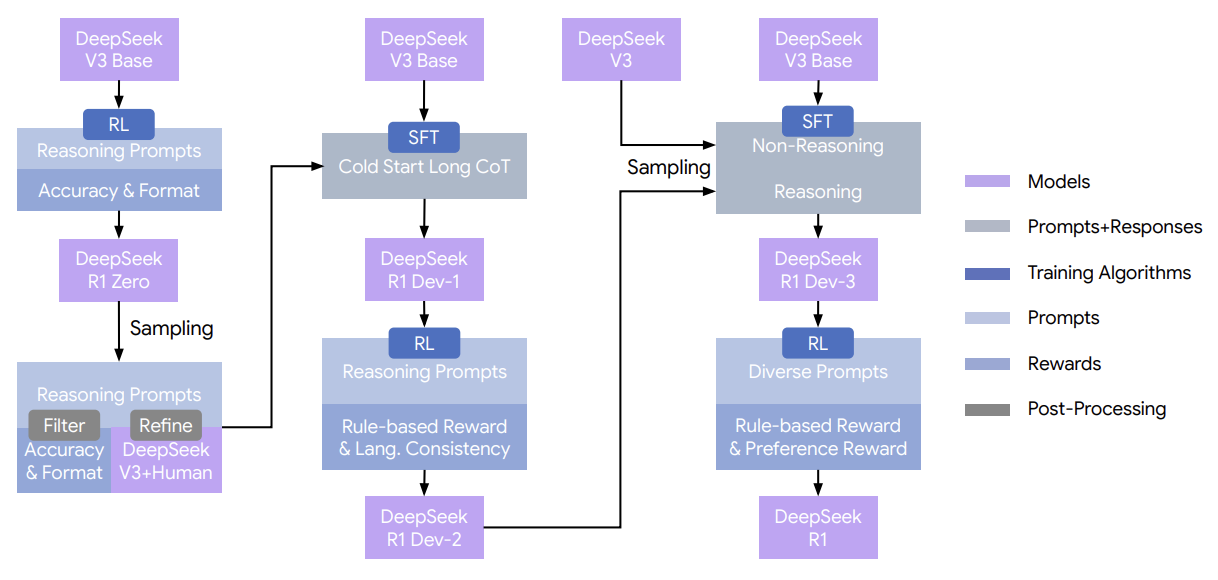
对于DeepSeek-R1,他们收集了数千条长思维链数据,以微调DeepSeek-V3-Base作为强化学习的起点。从DeepSeek-R1-Zero中,他们了解到可读性是个问题:回复有时会混杂多个语言或缺乏用于突出显示答案的Markdown格式。他们通过引入语言一致性奖励(CoT中目标语言词汇的比例)来解决前者问题,并通过设计一种可读性较强的模式,在每个回答的末尾包含摘要,来解决后者问题。他们还执行了第二个强化学习阶段,旨在提高模型的有用性和无害性,同时保持其推理能力。
为了提高实用性,他们着重强调最终摘要的实用性和相关性。为了生成偏好对,他们对DeepSeek-V3进行了四次查询,并随机将回复分配为回复A或回复B;然后,他们对独立判断取平均值,保留得分差异足够大的配对,并使用成对损失来定义目标。为了确保无害性,他们会对回复进行评估,以识别并缓解任何潜在的风险、偏见或有害内容。他们使用了一个数据集,其中模型生成的回复被标注为“安全”或
令人印象深刻的是,他们发现将DeepSeek-R1的输出提炼到更小的模型(如Qwen-32B)中,能够显著提升推理能力,甚至优于需要大量计算资源的大型强化学习模型。此外,这表明尽管提炼策略既有效又经济,但我们未来将越来越需要功能更强大的基础模型以及更大规模的强化学习。

除了主训练流程之外,DeepSeek 的附录文档还介绍了影响其设计选择的其他注意事项:
-
GRPO 优于 PPO:PPO 对每个标记都有 KL 惩罚(鉴于自回归特性,序列分布之间的 KL 散度可分解为随时间变化的各个标记之间 KL 散度之和)。由于强化学习确实能够实现更长时间的推理,而 PPO 隐式地惩罚了响应的长度(且由于无需额外的价值模型,计算成本更低),因此 GRPO 更为优选;在 MATH 任务上,GRPO 的表现始终优于 PPO,其中 的表现又持续优于 。λ = 1.0 λ = 0.95
-
产品驱动的DeepSeek-R1:当推理过程与第一人称思维模式一致时,用户会觉得回答更直观。因此,在少量长链式思维数据上进行微调后,DeepSeek-R1更多地使用“我”,而DeepSeek-R1-Zero则更多地使用“我们”。之前已提及其他考量因素,例如语言一致性,同时确保链式思维保持连贯且一致。DeepSeek-R1-Zero生成的原始链式思维可能蕴含着超越当前人类先验局限性的潜力,因此人工标注者会将推理轨迹转化为更易于人类理解/更具对话性的形式。
-
推理时的温度系数:他们观察到,采用贪婪解码来评估长输出推理模型会导致更高的重复率和更大的变异性。这与最近的研究相吻合,可由学习难度带来的风险规避以及对时间相关误差的归纳偏置来解释,即在决策点上,模型倾向于重新选择先前青睐的动作(从而导致循环)。
RLVR与评分标准
在混合推理模型上进行 RLVR 的目标是提高推理能力,而不会过度延长 token 数量。对于 /no_think,天真地应用 GRPO 可能导致奖励黑客,因为模型开始发出更长的 CoT(向 /think 转移);因此,奖励和 token 长度都增加。SmolLM3 观察到了这一点,发现 RLVRed /no_think 轨迹显示了与推理模型相关的认知行为,如"Wait, …"。
这可以通过过长完成惩罚来缓解,该惩罚惩罚超过一定长度的完成,这是一个由软惩罚阈值和硬惩罚阈值/最大完成长度参数化的函数。惩罚从软阈值增加到硬阈值,超过后者,惩罚为 -1(有效奖励 = 0)。
对于 /no_think,SmolLM3 决定在 2.5k-3k 范围内的长度惩罚,平衡了性能提升和响应长度增加。然而,在混合推理模型上联合进行 RL 是困难的,因为它需要单独的长度惩罚,其相互作用可能导致不稳定。这也是实验室分别发布 instruct 和 reasoning 变体的原因。
Kimi K2 使用自我批评评分标准奖励机制,模型评估自己的输出以生成偏好信号。K2 actor 生成 个 rollout,K2 critic 通过对评分标准组合进行成对评估来排名所有结果;这些结合了核心评分标准(基本价值观)和规范性评分标准(旨在消除奖励黑客),以及人类注释的评分标准(用于特定指令上下文)。
critic 模型使用可验证信号进行细化,这种迁移学习过程将其更主观的判断建立在可验证数据上。这应该允许 critic 与策略的演进同步重新校准其评估标准。
在线数据过滤
为了使强化学习更有效,课程学习是一种行之有效的方法,它能逐步让模型接触难度递增的问题。首先,根据问题的已观测解题率,将问题划分为不同难度等级(如简单、中等和困难)。在Intellect-3数学与编程任务中,这一过程是通过针对每个问题调用Qwen/Qwen3-4B-Thinking-2507模型八次完成的;而在科学与逻辑任务中,则对该同一模型进行了16次调用。随后,在每个阶段,他们都会保持一种均衡的课程安排,避免使用过于简单或难度过高的问题进行训练——因为这类问题无法提供有意义的学习信号(同时也有助于维持GRPO中的梯度稳定)。在Kimi K2中,这一做法是通过利用SFT模型的pass@k准确率来实现的。
强化学习的替代方案
一种替代方案是在线 DPO(参见偏好优化部分的"On policy with grading")。另一种是在线策略蒸馏。信号不是来自偏好,而是来自更强的教师模型,学生模型在每个训练步骤采样响应,学生/教师 logits 之间的 KL 散度提供学习信号。这样,学生可以持续从教师那里学习。此外,在线策略蒸馏比 GRPO 便宜得多,因为不是每个提示采样多个 rollout,我们只采样一个,教师在单次前向-后向传递中评分;正如 Qwen3 技术报告所指出的,其性能提升也可能全面更大。一个限制因素是学生和教师必须共享相同的分词器,Hugging Face 的 General On-Policy Logit Distillation(GOLD)允许将任何教师蒸馏到任何学生中。
Thinking Machine 的博客进一步表明,在线策略蒸馏缓解了灾难性遗忘,即在新模型上后训练的模型在其他先前领域上退化的情况。具体来说,他们发现中期训练 70% 并结合在线策略蒸馏可以达到模型及其中期训练版本的最佳性能,有效地通过廉价的蒸馏恢复行为。
鉴于上述算法,在它们之间选择可能很困难;Hugging Face 恰当地描述了这一点:
| 算法 | 何时使用 | 权衡 | 最佳模型规模 |
|---|---|---|---|
| 在线 DPO | 你可以廉价地获得偏好标签。最适合将行为与演进的分布对齐。 | 易于迭代扩展,比 RL 更稳定,但取决于标签质量和覆盖范围。少数训练框架支持。 | 任何规模,偏好捕获超越模仿的改进。 |
| 在线策略蒸馏 | 你有更强的教师模型,想要高效迁移能力。 | 实现简单,运行便宜,继承教师偏见,上限受教师限制。仅 TRL 和 NemoRL 支持 | 对中小型模型(<30B)最有效。 |
| 强化学习 | 当你有可验证奖励或需要多步推理/规划的任务时最佳。可以与奖励模型一起使用,但存在奖励黑客等挑战,模型利用奖励模型的弱点。 | 灵活且强大,但成本高且难以稳定;需要仔细的奖励塑形。大多数后训练框架支持。 | 中大型模型(20B+),额外容量让它们利用结构化奖励信号。 |
对于 DPO(半在线和在线),也有可能使用更少的计算匹配 GRPO。具体来说,他们发现半在线 DPO(训练器和生成器之间每 100 步同步)通常比每 10 步同步的半在线 DPO、在线 DPO 和 GRPO 更好。
局限性
DeepSeek在开发DeepSeek-R1时还尝试了其他一些实验性方法,但最终都以失败告终。他们借鉴受 AlphaGo 和 AlphaZero 的灵感,采用了蒙特卡洛树搜索(MCTS)来测试提升推理阶段计算可扩展性的可行性。这种方法将答案分解成更小的片段,以便模型能够系统地探索解空间。为此,他们引导模型生成与推理步骤相对应的标签。然而,问题在于,与国际象棋相比,标记生成所涉及的搜索空间呈指数级增长。因此,他们为每个节点设定了最大扩展限制,但这却导致模型陷入局部最优解。此外,由于标记生成本身的复杂性,训练精细的估值模型也颇具难度。
他们还探索了过程奖励模型,该模型会奖励多步骤任务中的中间思考过程。DeepSeek 指出存在三个局限性:首先,在一般推理中定义细粒度的步骤颇具难度;其次,难以判断当前的中间步骤是否具有挑战性(以大语言模型作为评判标准可能无法取得令人满意的效果);此外,这种做法容易导致奖励被“黑客”利用——模型可能会单纯优化表面上看似合理的推理表现,而并不真正完成实质性的任务步骤。
后训练要点总结
- SFT 是稳定的基线;偏好/RL 方法应该由可验证奖励或明显收益来证明
- 混合推理模型需要仔细的长度控制以避免奖励黑客
- 工具使用和智能体数据集现在是后训练的一等目标
- 许多"花哨"的方法在实践中失败;跟踪什么不起作用,而不仅仅是起作用的
行为与安全
安全测试与缓解
在后训练期间,他们执行额外的 RL 阶段,奖励符合 OpenAI 针对不安全提示的策略的答案。因为所有这些模型都有开放模型权重,一个担忧是恶意方可以增强模型的有害能力。通过对 gpt-oss-120b 运行 Preparedness 评估,OpenAI 确认该模型在生物/化学能力、网络能力和 AI 自我改进方面未达到高能力的阈值。
他们还测试了对抗行为者是否可以通过微调 gpt-oss-120b 来达到上述领域的高能力。他们通过以下方式模拟攻击:
- 在现实的模拟网络中评估模型在大学 Capture the Flag 挑战或网络操作中的表现
- 通过逐步在与生物风险相关的领域专家数据上训练来创建对抗性微调版本
- 在 SWE-bench verified、OpenAI PRs 和 PaperBench(重现 AI 研究的能力)上进行基准测试
经过审查,他们的安全咨询小组得出结论,即使经过鲁棒的微调,gpt-oss-120b 仍然无法在上述领域达到高能力。此外,他们确定发布模型是否会推进生物能力的前沿,包括病毒学和隐性知识等评估,在开放基础模型中(这也增加了风险),发现还有其他开放权重模型达到或接近 gpt-oss-120b,因此他们决定发布对前沿的影响很低。
OpenAI 还使用其他指标评估安全性能:
-
禁止内容:在 ProductionBenchmarks 上进行基准测试,他们考虑不同类别,如 PII、性、骚扰、仇恨、自残,使用更能代表生产数据的对话。他们使用 LLM-as-judge 评估完成,并根据相关 OpenAI 政策确定 not_unsafe。性能与 o4-mini 相当。
-
越狱:他们使用试图绕过模型拒绝的对抗性提示进行测试,特别是 StrongReject,它将越狱示例插入安全拒绝评估,并使用相同的政策评分器。性能与 o4-mini 相当。
-
指令层次:它遵循系统 > 开发者 > 用户 > 助手 > 工具的层次。他们使用系统、开发者和用户消息(有时冲突)对模型进行后训练,模型必须学会选择层次中更高的指令。这包括测试通过用户消息提取系统提示和提示注入劫持。对于 PII 保护,性能与 o4-mini 相当,但对于消息冲突,gpt-oss-120b 比 o4-mini 低约 15%。
-
幻觉和 CoT:推理模型的 CoT 对于检测不当行为非常有帮助,当被施压不要有"坏想法"时,模型可能学会在不当行为时隐藏其思考。为了衡量幻觉,他们使用两个数据集,一个是事实寻求问题,另一个是关于人的公开事实,并考虑准确性和幻觉率。这里,幻觉率不仅仅是 1 - 准确性,因为模型也可以输出"我不知道"之类的答案。性能比 o4-mini 稍差,考虑到模型规模,这是预期的。
-
公平性和偏见:他们还在 BBQ 评估上评估 gpt-oss-120b,该评估测试对属于受保护类别的人的社会偏见,涵盖九个社会维度。性能与
o4-mini相当。
行为与潜在能力
模型的行为不仅由训练数据决定,还受到对话模板、训练阶段和超参数的影响。
角色标识的影响
Hermes 4 发现,将对话模板中的 assistant 改为 me 会导致显著不同的行为:
- assistant 模板:模型倾向于更正式、更"助手式"的回应
- me 模板:模型表现出更个性化、更直接的风格
这表明即使是看似微小的模板变化也会影响模型的"人格"。
推理模式的影响
混合推理模型(如 Qwen3)需要在训练时明确区分思考和非思考模式:
- 思考模式:使用
<think/>标签包裹推理过程 - 非思考模式:直接给出答案
训练数据应该包含两种模式的配对示例,否则模型可能无法正确判断何时使用哪种模式。
安全对齐
安全对齐是后训练的重要组成部分,旨在防止模型生成有害内容。
安全训练方法
- 安全 SFT:在安全相关数据上进行监督微调
- 安全 RLHF:使用人类反馈强化学习优化安全行为
- 红队测试:主动寻找模型的安全漏洞
安全与能力的平衡
过度强调安全可能导致:
- 过度拒绝:模型拒绝回答合理问题
- 能力下降:模型在某些任务上表现变差
因此,需要在安全性和有用性之间找到平衡。
the training marathon
在主训练运行开始之前,确保基础设施准备就绪。这包括集群上的 Slurm 预留、压力测试 GPU(GPU Fryer 或 DCGM),以及通过将检查点上传到第三方并在保存下一个后删除本地副本来避免存储膨胀。为此,检查点和自动恢复系统很重要。
评估也出奇地耗时(Allen Institute 在评估上花费了大约 20% 的计算),因此确保自动化和日志记录(不仅是评估分数,还有吞吐量、损失、梯度范数和节点健康状况)至关重要。
吞吐量消失
Hugging Face 在开始主运行几小时后观察到约 40% 的吞吐量下降(从 14k 到 8k tokens/sec/GPU)。问题来自数据存储;他们的集群使用具有"保持热"缓存模型的网络附加存储,该模型存储频繁访问的文件并将"冷"文件驱逐到第三方 S3。有 24TB 的训练数据,存储被推到极限,因此它在训练中期驱逐了数据集分片。这意味着取回它们并造成降低吞吐量的停顿。
第一个修复是通过预留一个预加载数据集的备用节点并使用 fpsync 复制(s5cmd 花了两倍时间)来交换存储方法。这解决了节点死亡且替换 GPU 没有数据的问题,因为通过与备用节点交换,训练可以继续。因此,新的备用节点不会被浪费,可以运行评估或开发作业。
再次测试,他们发现吞吐量有较小但仍显著的下降。在对产生相同结果的各个节点进行实验后,他们专注于训练步骤的变化,发现较小的步骤计数导致较小的吞吐量下降。他们使用的 nanotron 数据加载器正在增长查找表,使训练步骤读取下一个 token 块,而不是保持有界或预计算。存储在全局内存中,增长的表导致分配失败和页面错误/更差的缓存局部性。因此,他们切换到 Tokenizedbytes 数据加载器,解决了吞吐量问题。
损失噪声
然而,SmolLM3 的损失曲线看起来更加噪声。他们发现数据加载器存在问题,因为它按顺序读取每个文档的序列。没有序列洗牌,批次不再代表整体数据分布,增加了梯度方差。此外,长文件(例如代码)会提供许多连续序列,也会导致损失峰值。为了解决,他们离线重新洗牌了 tokenized 序列;另一种选择是将数据加载器更改为进行随机访问,这具有更高的内存使用和更慢的运行时间。
张量并行
两天和 1T token 后,评估显示在类似配方下,SmolLM2(1.7B)在训练的同一阶段比 SmolLM3 表现更好。团队发现张量并行存在问题:SmolLM2 的权重适合单个 GPU,而对于 SmolLM3,它们必须在 2 个 GPU 之间共享。
此外,两个 TP rank 使用相同的随机种子而不是不同的种子初始化,这导致相似的激活/梯度、特征多样性丧失和较低收敛。
并行策略
张量并行(Tensor Parallelism, TP):将模型层分割到多个 GPU 上。每个 GPU 计算部分矩阵乘法,然后通过 all-reduce 操作同步结果。
流水线并行(Pipeline Parallelism, PP):将模型的不同层分配到不同 GPU。数据以流水线方式流经各阶段,需要精心调度以最小化气泡。
数据并行(Data Parallelism, DP):每个 GPU 持有完整模型副本,处理不同数据批次。梯度通过 all-reduce 同步。
序列并行(Sequence Parallelism, SP):对于长序列,将序列维度分割到多个 GPU。与张量并行结合使用。
专家并行(Expert Parallelism, EP):对于 MoE 模型,将不同专家分配到不同 GPU。路由器决定每个 token 发送到哪个专家。
通信优化
- 梯度累积:在同步前累积多个微批次的梯度,减少通信频率
- 混合精度训练:使用 FP16/BF16 进行计算,FP32 进行梯度累积
- 梯度压缩:压缩梯度以减少通信量
- 通信与计算重叠:在计算时异步传输数据
容错机制
大规模训练不可避免会遇到硬件故障。关键策略包括:
- 检查点保存:定期保存模型状态
- 弹性训练:自动检测故障并从检查点恢复
- 冗余计算:关键计算使用冗余节点
多客户端编排器
推理吞吐量应随使用的节点数量线性扩展。然而,Prime 发现 vLLM 提供的标准多节点数据并行策略没有实现这一点,因为随着节点增加,吞吐量趋于平稳。他们抽象了多客户端编排器,使每个推理节点部署在独立服务器上(运行自己的 vLLM 引擎和调度器,管理自己的 KV 缓存并批处理自己的请求),编排器为每个节点维护一个客户端(避免单共享队列瓶颈)。组 rollout 请求根据轮询调度分布在客户端之间,保持利用率平衡。
常见问题
训练不稳定有一些常见的罪魁祸首:高学习率、不良数据、数据-参数状态交互(峰值可能来自数据批次和模型参数状态的特定组合)、不良初始化(OLMo2 揭示 可以在缩放初始化上改善稳定性)和精度(呃,不是 fp16)。
除了上述想法如 logit softcapping、z-loss 或 QK-norm,数据过滤(OLMo2 删除具有重复 n-gram 的文档,特别是具有 1-13 token 跨度的 32+ 次重复的文档)显著减少峰值频率。如果峰值仍然发生,常见方法包括通过跳过有问题的批次或收紧梯度裁剪来围绕峰值重新训练。
训练运维要点总结
- 吞吐量故障通常是数据管道或存储问题,而不是模型代码
- 数据加载器行为(洗牌、打包、访问模式)可以静默改变训练动态
- 并行设置中的种子处理是一个高杠杆细节;尽早验证
- 将评估和日志记录视为一等公民;这是你注意到回归的方式
结语
训练一个前沿大模型是一个复杂的系统工程问题,涉及架构设计、训练稳定性、数据策展、优化器选择、后训练策略和运维管理等多个方面。本文通过深入剖析七个开源前沿模型的训练实践,提炼出一套系统性的方法论。
核心启示:
- 没有银弹:每个设计选择都是权衡,需要根据具体场景做出决策
- 消融实验是关键:快速、可靠的消融实验是做出正确决策的基础
- 稳定性优先:在大规模训练中,稳定性比峰值性能更重要
- 数据为王:高质量的数据策展和混合策略是模型性能的决定性因素
- 系统思维:训练大模型是一个系统工程,需要关注数据管道、存储、并行策略等"非模型"因素
本文基于 Alex Wa 的 “frontier model training methodologies” 翻译,原文链接:https://djdumpling.github.io/2026/01/31/frontier_training.html