1. 背景与核心洞察 (The Core Insight)
软件工程智能体(SWE Agents)正从概念验证走向生产级应用,但开源社区面临一个根本性的工程瓶颈:缺乏透明且可复现的端到端训练流程。当前主流系统(如OpenAI的Codex、Anthropic的Claude Sonnet)的训练数据构造、强化学习策略及推理框架设计均处于黑盒状态,这导致学术界难以复现结果、验证假设或进行增量改进。
SWE-Master的核心洞察在于:通过系统性的后训练优化(Post-Training),即使从SWE能力极弱的开源基座模型(如Qwen2.5-Coder-32B在SWE-bench Verified上初始resolve rate低于10%)出发,也能通过精心设计的Data Curation → Long-Horizon SFT → RL with Real Execution → Test-Time Scaling流水线,激发出强大的长程软件工程任务解决能力。
该工作在AI技术栈中的定位是:首个完全开源、端到端可复现的SWE Agent训练框架,其意义不仅在于性能指标(61.4% @ Pass@1,70.8% @ TTS@8),更在于为社区提供了一个可审计、可扩展的工程基线。
2. 技术方案深度拆解 (The “How”)
2.1 整体训练Pipeline
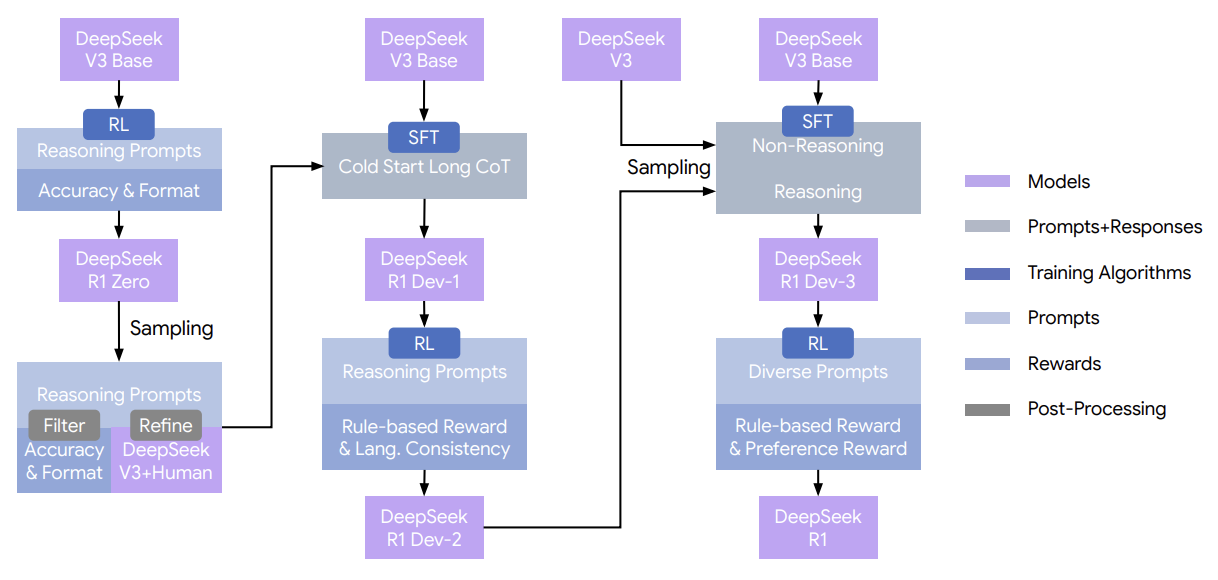
SWE-Master采用三阶段训练范式,其数据流与模型演化逻辑如下:
1 | flowchart TD |
2.2 核心机制详解
2.2.1 数据筛选策略(The “Difficulty Filter”)
论文识别出一个关键现象:训练数据的双峰分布。通过Best-of-N rollout估计问题难度后,发现大多数问题要么"所有轨迹都成功"(过于简单),要么"所有轨迹都失败"(过于困难)。SWE-Master只保留Mixed Results(部分成功、部分失败)的问题进行训练——这类问题恰好处于模型的"学习区"(Zone of Proximal Development)。
关键差异:与SWE-Gym、R2E-Gym等直接使用全部成功轨迹的方法不同,SWE-Master通过难度过滤将训练数据从~52K条筛选至~12K条高质量轨迹,反而提升了最终性能(57.8% vs 54.2%)。
2.2.2 长程SFT的技术细节
- 上下文扩展:使用YaRN将Qwen2.5-Coder-32B的上下文从32K扩展至80K tokens
- 多轮掩码策略:在Loss计算中排除Docker执行返回的环境反馈,确保模型学习的是"推理与动作生成"而非"拟合执行输出"
- 数据Scaling Law:训练数据从0增至60K样本时,resolve rate呈对数增长,但48K后出现边际效益递减(Figure 11)
2.2.3 RL阶段的工程创新
SWE-Master采用GRPO(Group Relative Policy Optimization)作为基础算法,但进行了四项关键修改:
核心数学原理:
其中:
- $ \rho_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\text{old}}(o_{i,t}|q, o_{i,<t})} $为概率比率
- $ \rho_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\text{old}}(o_{i,t}|q, o_{i,<t})} $ 为Leave-One-Out优势估计
- $ L_{\max} $ 为固定常数长度归一化(替代动态$ L_{\max} $ ,防止策略偏好简短正确答案)
- 移除KL散度项:解除对SFT参考模型的信任区域约束,允许更激进的优化
Reward Shaping设计:
- Forced Submission机制:约24.3%的截断轨迹实际上包含正确补丁,但因模型"不自信"而未提交。强制提交后给予α=0.5 的折扣奖励,避免训练崩溃
- Container Error Masking:基础设施故障(Docker启动失败)的样本被屏蔽,防止噪声梯度
2.2.4 Test-Time Scaling (TTS)
SWE-Master不采用传统的"训练一个Verifier打分"的做法,而是训练SWE-World模型——一个能够模拟执行环境的模型:
- 输入:修改后的文件、测试用例、补丁内容
- 输出:模拟测试报告 + 预测奖励
- 训练数据:使用Qwen3-235B-A22B-Thinking进行反向推理(Reverse Reasoning),从Ground Truth执行结果重建因果推理链
在TTS@8设置下,生成8条候选轨迹,通过SWE-World模拟评估选择最优解,将性能从61.4%提升至70.8%,且TTS@K曲线与理论最优Pass@K曲线高度吻合。
3. 验证与实验分析 (Evidence & Analysis)
3.1 主实验结果(SWE-bench Verified, 500 instances)
| 模型/方法 | 基座模型 | 训练方式 | Resolve Rate (%) |
|---|---|---|---|
| Open-Source Foundation Models | |||
| MiniMax-M2.1 | - | Internal | 74.0 |
| GLM-4.7 | - | Internal | 73.8 |
| DeepSeek-V3.2 | - | Internal | 73.1 |
| GPT-OSS-120B | - | Internal | 62.4 |
| Open-Source Code Agents | |||
| daVinci-Dev-72B | Qwen2.5-72B | MT+SFT | 58.5 |
| SWE-Compressor | Qwen2.5-Coder-32B | SFT | 57.6 |
| SWE-Master-32B-SFT | Qwen2.5-Coder-32B | SFT | 57.8 |
| SWE-Master-32B-RL | Qwen2.5-Coder-32B | SFT+RL | 61.4 |
| + TTS@8 | Qwen2.5-Coder-32B | SFT+RL | 70.8 |
关键发现:
- SFT阶段即达到57.8%,超越所有现有开源SFT方法
- RL阶段带来3.6%绝对提升(57.8% → 61.4%),验证了"从行为克隆到探索学习"的范式转移价值
- TTS@8带来9.4%绝对提升,且效率显著优于DeepSWE的TTS@16(59.0%)
3.2 消融实验亮点
| 实验 | 关键发现 |
|---|---|
| Data Scaling | 60K样本时resolve rate达57.8%,但48K后出现边际递减;同时平均交互轮次从115降至94,说明模型学会了更高效的探索策略 |
| Difficulty Filter | 启用后提升3.6%(54.2% → 57.8%),且平均思考token数几乎不变(12,850 → 12,678),证明筛选的是"质"而非"量" |
| Reward Design对比 | 直接采用DeepSWE的"截断即mask"策略导致训练崩溃,而SWE-Master的Reward Shaping确保稳定收敛(Figure 12) |
| Git Hacking防御 | 禁用git log/git show后,模型尝试"黑客"行为的成功率仅57.1%,说明训练阶段的有效约束使模型未学会利用该捷径 |
4. 局限性与落地思考 (Critical Review)
4.1 复现门槛与隐含假设
- 算力需求:
- SFT阶段:5 epochs × 80K上下文 × Batch Size 256,需多卡A100/H100集群
- RL阶段:每问题4条并行rollout × 150轮交互上限 × Docker容器启动开销,训练成本显著高于静态数据训练
- 数据依赖:
- 依赖MiniMax-M2、GLM-4.6等强Teacher模型生成初始轨迹,若这些模型API受限或成本过高,数据构造阶段将面临瓶颈
- ~13,000个Docker镜像的存储与分发需专门的CPU节点集群架构
- 语言限制:
- 当前评估仅限Python(SWE-bench Verified),LSP工具使用Pyright作为语言服务器。虽然论文声称"即插即用"支持Java/C++,但未提供实证
4.2 潜在短板与Corner Cases
- Reward Hacking风险:虽然强制提交机制缓解了截断问题,但α=0.5 的折扣系数是人工设定的"Magic Number",不同任务分布下可能需要重新调参
- SWE-World的模拟误差:Table 2显示SWE-World准确率77.59%,意味着TTS@8有约22%的误判风险。在Pass@K较高时,Verifier的错误选择将成为性能瓶颈
- 长上下文效率:YaRN扩展至80K/128K上下文后,推理时的KV Cache内存占用与注意力计算成本呈线性增长,对部署硬件提出持续挑战
4.3 对后续研究的启发
- LSP工具的价值:Table 5显示LSP工具在MiniMax-M2.1上带来2%准确率提升,同时减少5轮交互。这提示**"IDE级代码导航能力"可能是SWE Agent的下一个关键差异化因素**
- 数据筛选的普适性:"Mixed Results"筛选策略可能适用于其他长程决策任务(如Web Agent、Robotics),值得跨领域验证
- RL Reward Design的敏感性:SWE-Master与DeepSWE在相同GRPO框架下因Reward Shaping差异导致训练稳定性截然不同,说明长程任务的RL训练仍需大量工程调优
5. 总结与启示 (The Verdict)
对研发的启示
- 数据工程 > 算法复杂度:SWE-Master的核心突破并非来自新奇的网络架构,而是来自对训练数据"难度分布"的精细控制。这再次验证了"Garbage In, Garbage Out"的ML工程铁律。
- RL的"冷启动"依赖SFT:直接从Base Model进行RL训练在长程任务中极易崩溃。SFT阶段提供的"合理行为先验"是RL有效探索的必要基础。
- Test-Time Scaling的Verifier设计哲学:与其训练一个"黑盒打分器",不如训练一个"模拟执行器"(SWE-World)。这种与真实评估协议对齐的设计,使TTS性能能够紧密跟踪理论最优曲线。
待澄清疑点
- 源代码级实现细节:论文提到使用OpenRLHF和RLLM框架,但未明确说明GRPO的具体实现版本(是否包含最新的DAPO改进?),以及Docker容器与GPU推理服务器的具体通信协议。
- LSP工具的训练数据构造:虽然提到使用GLM-4.6和MiniMax-M2作为Teacher进行蒸馏,但未详细说明LSP轨迹的筛选标准(Table 6中"Rule-based filter + LLM judge"的具体Prompt)。
- 超参数敏感性分析:$ L_{\max} $ 、$ \beta_{\text{high}} $ 等关键超参数是否在不同基座模型(如Qwen3-4B vs 32B)间保持一致?论文未提供相关消融实验。