为什么需要知识图谱?什么是知识图谱?KG的前世今生
标题的命名顺序可能让有的读者不太习惯。通常在介绍一个陌生事物的应用前,我们会给出其定义。之所以换个顺序,是为了不让读者一开始就接触比较冰冷生硬的概念刻板描述(后面我尽量用更具体、准确的例子来表达),另一方面也是为了通过现实生活中的例子自然的引入知识图谱的概念。希望通过这种方式加深读者的印象和理解。为了减轻读者理解的负担,我尽可能地避免引入过多的概念和技术细节,将其留到后续的文章进行介绍。
言归正传,本文主要分为三个部分。第一个部分介绍我们为什么需要知识图谱,第二个部分介绍知识图谱的相关概念及其形式化表示。最后,作一个简单的总结,并介绍该专栏后续文章会涉及的内容。
一. 看到的不仅仅是字符串
当你看见下面这一串文本你会联想到什么?
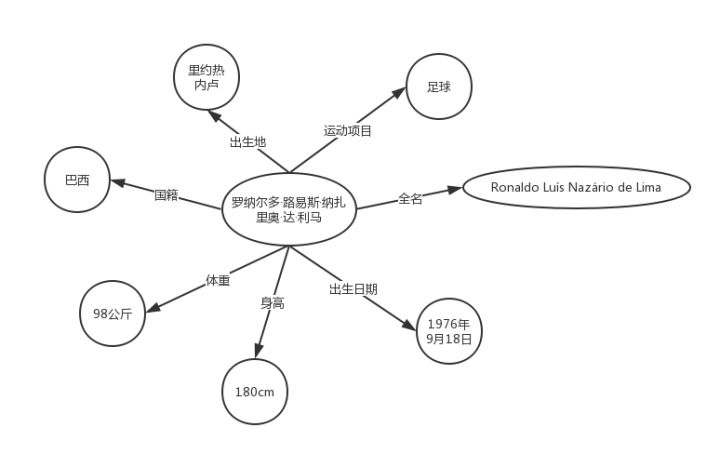
Ronaldo Luís Nazário de Lima
估计绝大多数中国人不明白上面的文本代表什么意思。没关系,我们看看它对应的中文:
罗纳尔多·路易斯·纳萨里奥·德·利马
这下大部分人都知道这是一个人的名字了,当然,不出什么意外,还是个外国人。但还是有一部分人不知道这个人具体是谁。下面是关于他的某张图片:
从这张图片我们又得到了额外信息,他是一 ...

深度学习与计算机视觉(PB-10)-Kaggle之猫狗比赛
在第9节中,我们提到了当数据太大无法加载到内存中时,如何使用HDF5保存大数据集——我们自定义了一个python脚本将原始图像数据集序列化为高效的HDF5数据集。在HDF5数据集中读取图像数据集可以避免I/O延迟问题,从而加快训练过程。
假设我们有N张保存在磁盘上的图像数据,之前的做法是定义了一个数据生成器,该生成器按顺序从磁盘中加载图像,N张图像共需要进行N个读取操作,每个图像一个读取操作,这样会存在I/O延迟问题。如果将图像数据集保存到HDF5数据集中,我们可以一次性读取batch大小的图像数据。这样极大地减少了I/O调用的次数,并且可以使用非常大的图像数据集。
在本节中,我们将学习如何为HDF5数据集定义一个图像生成器,从而方便使用Keras训练卷积神经网络。生成器会不断地从HDF5数据集中生成用于训练网络的数据和对应的标签,直到我们的模型达到足够低的损失/高精度才会停止。
在训练模型之前,我们将实现三种新的图像预处理方法——零均值化、patch Preprocessing和随机裁剪(也称为10-cropping或过采样)。之后,我们将利用Krizhevsky等人2012年的论 ...

数据挖掘模型中的IV和WOE详解
本文主要介绍下金融行业常用的数据分析的方法,比如IV,WOE,KS指标等。
IV的用途
IV的全称是Information Value,中文意思是信息价值,或者信息量。
我们在用逻辑回归、决策树等模型方法构建分类模型时,经常需要对自变量进行筛选。比如我们有200个候选自变量,通常情况下,不会直接把200个变量直接放到模型中去进行拟合训练,而是会用一些方法,从这200个自变量中挑选一些出来,放进模型,形成入模变量列表。那么我们怎么去挑选入模变量呢?
挑选入模变量过程是个比较复杂的过程,需要考虑的因素很多,比如:变量的预测能力,变量之间的相关性,变量的简单性(容易生成和使用),变量的强壮性(不容易被绕过),变量在业务上的可解释性(被挑战时可以解释的通)等等。但是,其中最主要和最直接的衡量标准是变量的预测能力。
“变量的预测能力”这个说法很笼统,很主观,非量化,在筛选变量的时候我们总不能说:“我觉得这个变量预测能力很强,所以他要进入模型”吧?我们需要一些具体的量化指标来衡量每自变量的预测能力,并根据这些量化指标的大小,来确定哪些变量进入模型。IV就是这样一种指标,他可以用来衡量自变量的预测 ...
Character Embeddings for deep learning
本文介绍字符嵌入,从字符的角度考虑embedding问题。
字符嵌入
机器学习需要输入数值数据,类似于文本数据需要转化为数值型,因此,词嵌入是常用的将文本数据转化为数值数据的方法,比如像word2vec算法,你可以获取一个单词的数值表示,并且可以使用这些数值向量得到句子/段落/文本等数值表示。
但是,训练一个数据集的词向量模型可能非常昂贵。解决这一问题的学术方法是使用预先训练的词向量模型进行单词嵌入,例如斯坦福大学的研究人员收集的Glove向量。然而,GLove向量非常大,;最大的一种(300维,约8400亿tokens)在磁盘上是5.65 GB,在不太强大的计算机上加载时可能会遇到内存不足问题。
为什么不使用字符嵌入呢?你可以计算相对较少的向量,而且可以将这些向量加载到内存中,并使用这些向量来衍生出单词向量,进而可以用来衍生出句子/段落/文档/等向量。但是,训练字符嵌入在计算上更加昂贵,因为字符的数量比tokens多5-6倍左右.
为什么不使用现有的预先训练的单词嵌入来推断单词中相应的字符嵌入?借鉴“bag-of-words“,思考“bag-of-characters”。例如,“ ...
如何使用深度学习提取文本中实体
本文介绍了如何使用深度学习执行文本实体提取。作者尝试了分别使用深度学习和传统方法来提取文章信息,结果深度学习的准确率达到了 85%,远远领先于传统算法的 65%。
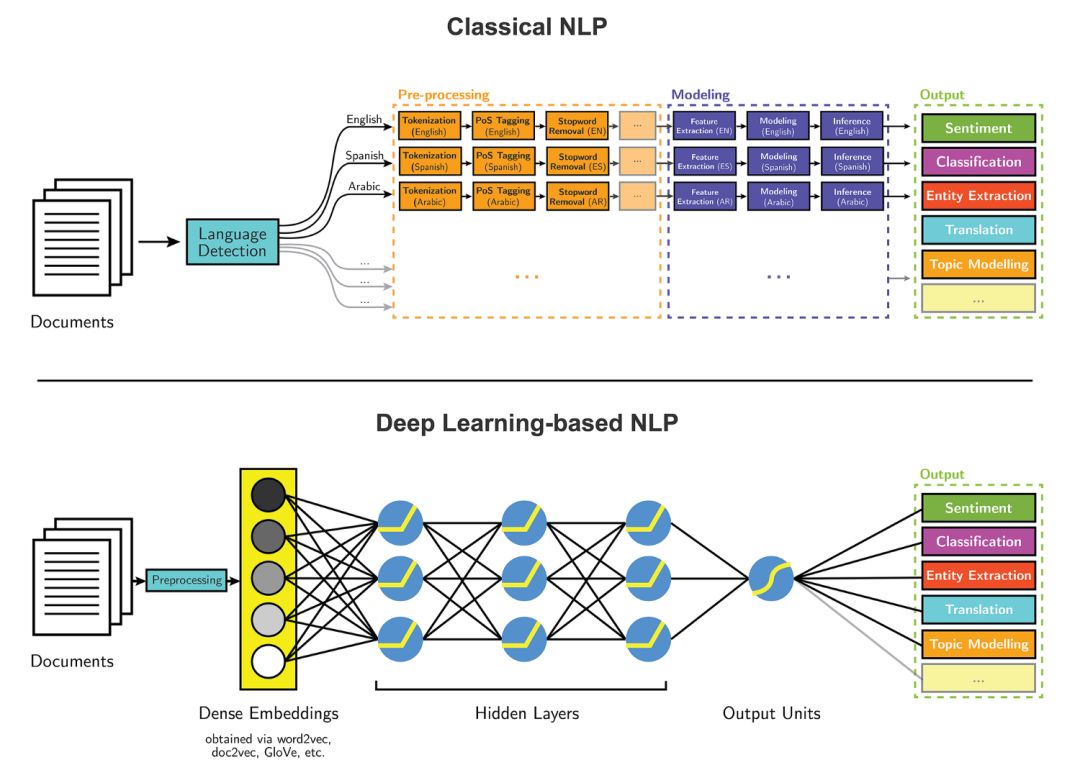
传统的NLP建模流程和使用深度学习技术的NLP建模流程如下图所示:
文本实体提取是自然语言处理(NLP)的主要任务之一。随着近期深度学习领域快速发展,我们可以将这些算法应用到 NLP 任务中,并得到准确率远超传统方法的结果。我尝试过分别使用深度学习和传统方法来提取文章信息,结果非常惊人:深度学习的准确率达到了 85%,远远领先于传统算法的 65%。
本项目的目标是把文章中的每个单词标注为以下四种类别之一:组织、个人、杂项以及其他;然后找到文中最突出的组织和名称。深度学习模型对每个单词完成上述标注,随后,我们使用基于规则的方法来过滤掉我们不想要的标注,并确定最突出的名称和组织。
模型的高级架构
在这里要感谢 Guillaume Genthial 这篇关于序列标注的文章,本项目建立在这篇文章的基础之上。
上图是对每个单词进行分类标注的模型高级架构。在建模过程中,最耗时间的部分是单词分类。我将解释模型的每个组成部分,帮助读者 ...

人脸聚类——python实现
本文主要是如何使用python进行人脸聚类。
使用Python进行人脸聚类
人脸常用的应用有人脸识别和人脸聚类。人脸识别和人脸聚类并不相同,但概念高度相关。当我们使用监督学习进行面部识别时,我们需要同时具有:
1.我们想要识别的面部的示例图像
2.与每个面部相对应的名字(即,“类标签”)。
但对于人脸聚类,我们使用的是无监督学习算法,我们只有没有名字(或者说标签)的人脸本身,并且我们需要识别和计算数据集中某些独特的人。
在本文的第一部分中,我们将讨论人脸聚类数据集以及将用于构建项目的项目结构。
需要编写两个Python脚本:
一个用于提取和量化数据集中的人脸
另一个是对面部进行聚类,其中每个结果聚类(理想情况下)代表一个独特的个体
然后,我们将在样本数据集上运行我们的人脸聚类管道并检查结果。
配置环境
所需要的python模块:
OpenCV
dlib
face_recognition
imutils
scikit-learn
如果有GPU,则需要安装带有CUDA的dlib。
人脸聚类数据集
图1 人脸数据集样本
由于2018年世界杯半决赛,我认为将人脸聚类应用于著名足 ...
深度学习与计算机视觉(PB-09)-使用HDF5保存大数据集
到目前为止,我们使用的数据集都能够全部加载到内存中。对于小数据集,我们可以加载全部图像数据到内存中,进行预处理,并进行前向传播处理。然而,对于大规模数据集(比如ImageNet),我们需要创建数据生成器,每次只访问一小部分数据集(比如mini-batch),然后对batch数据进行预处理和前向传播。
Keras模块很方便进行数据加载,可以使用磁盘上的原始文件路径作为训练过程的输入。你不需要将整个数据集存储在内存中——只需为Keras数据生成器提供图像路径,生成器会自动从路径中加载数据并进行前向传播。
然而,这种方法非常低效。读取磁盘上的每张图像都需要一个I/O操作,这样会造成一定的延迟。训练深度学习网络本身已经够慢了,所以我们应该尽可能避免I/O瓶颈。
一个比较合理的解决方案是将原始图像生成HDF5数据集,就像我们第3章中所做的那样,只是这一次我们存储的是原始图像,而不是提取的特征。HDF5不仅可以存储大量的数据集,而且还可以用于I/O操作,特别是用于从文件中提取batch(称为“片”)。我们将在磁盘上的原始图像保存到HDF5文件中,这可以让模型快速的遍历数据集并在其上训练深度学习网 ...
深度学习与计算机视觉(PB-08)-应用深度学习最佳途径
在Starter Bundle第10章中,我们提到了训练一个神经网络模型所需要的四个因素,即:
数据集
loss函数
神经网络结构
优化算法
有了这四个因素,实际上我们是可以训练任何深度学习模型,但是,我们如何训练得到一个最优的深度学习模型?如果效果达不到理想效果,又该如何去优化模型?
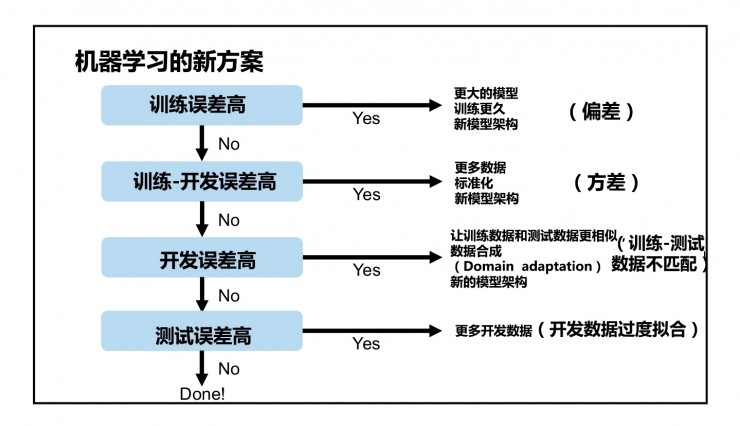
在深度学习实践中,你会发现,深度学习最难的部分其实是如何根据模型的准确性/损失曲线来进行下一步操作。如果模型的训练错误率太高,该如何处理?如果模型的验证错误率很高,又该如何处理?当验证错误率与训练错误率相差不大,而测试集错误率很高,这又该如何处理?
在这一章中,我们将讨论深度学习在应用时的一些技巧,首先是经验准则,根据经验准则来优化模型。然后是决策准则,根据决策准则来决定是从头开始训练深度学习模型还是应用迁移学习。通过本章内容,你将会对专业的深度学习实践者在训练他们自己的网络时使用的经验法则有一个很好的理解。
训练准则
以下内容主要来自于在第30届神经信息处理系统大会(NIPS 2016)中,吴恩达教授发表演讲:《利用深度学习开发人工智能应用的基本要点(Nuts and Bolts of Buil ...
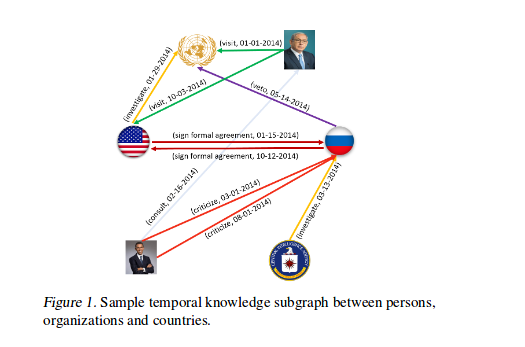
Know-Evolve-Deep Temporal Reasoning for Dynamic KG
对于带有时序属性的大规模事件数据,需要动态更新的知识图谱来保存知识图谱中关系的时序信息(每条边包含时间属性)。本文提出了 Know-Evolve 这种基于神经网络的动态知识图谱来学习实体在不同时刻的非线性表示。在动态知识图谱中,事件由四元组表示,相比于普通的三元组,增加了时间信息,因此在动态知识图谱中,实体之间的可能通过多个相同的关系连接,但是这些关系会关联到不同的时序信息。Know-Evolve 中,使用时间点过程(temporal point process)来描述时间点的影响。
前言
事件的发生,重现都伴随着时间的变化而变化,例如下图,时序知识图谱中每条边都有与之相关的时间属性。而静态知识图谱忽略了时间概念,无法具有对事件的推理能力。因此,大多数工作都关注于实体-关系的表示,学习现有的知识推断未知的事实。但这些方法缺乏利用时序知识图谱表示的底层数据中丰富的时序动态的能力,除了关系(结构)依赖之外,有效地捕获跨事件的时间依赖性有助于提高对实体行为的理解,以及它们如何随着时间的推移对事件的生成做出贡献。
时间点过程
在时间点过程中,某一时刻发生某事件的概率可以表示为
f(t)=λ ...
Plot Python XGBoost feature importances
对xgboost的特征重要性进行可视化。
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283## 加载模块import numpy as npimport pandas as pdimport xgboost as xgbfrom scipy import sparseimport matplotlib.pyplot as pltfrom pylab import plot, show, subplot, specgram, imshow, savefigimport randomimport operatorfrom sklearn.cross_validation import train_test_splitfrom sklearn.preprocessing import LabelEncoder, OneHotEn ...

