这个比赛是要根据顾客的历史购买记录,预测 Instacart 的消费者将再次购买哪种商品,这样可以在顾客需要这个商品的时候,货源是充足的。这种侧重于理解时间行为模式的问题使得这个问题与普通的项目推荐有所不同,在普通项目推荐中,我们通常假设用户的需求和偏好在短时间内相对固定。 对于Netflix来说,他们可以猜想你看了这部电影,你就会想看另一部类似的电影,但如果是你昨天买了杏仁黄油和卫生纸,今天你会不会再买这两样就不好说了.
数据说明:
1 | 1. 数据说明 |
接下来,简单查看下第二名的解决思路:
问题描述
这次比赛的目标是预测杂货店的回购情况:根据用户的购买记录(一组订单以及每个订单中购买的产品),来预测他们以前购买过哪些产品将在下一个订单中被回购?
这个问题与一般的推荐问题有一点不同,在一般的推荐系统中,我们经常面临一个冷开始的问题,即对我们从没见过的新用户和新项目进行预测和推荐。例如,电影网站可能需要推荐新电影并为新用户提供推荐。

这个问题自带的顺序性和时间性也使得它很有趣:我们如何衡量距离该用户上次购买此物品的时间?用户是否有特定的购买模式,他们是否在一天的不同时间购买不同类型的产品?比赛的F1评价指标确保我们的模型具有高精度和高召回率。
主要方法
我用了XGBoost来建造了两个梯度提升树模型
- 预测回购-哪一个被购买过的产品将在下次被购买呢?这个模型取决于用户和产品。
- 预测None-用户下一次购买的商品会包含之前购买过的吗?这个模型只和用户有关

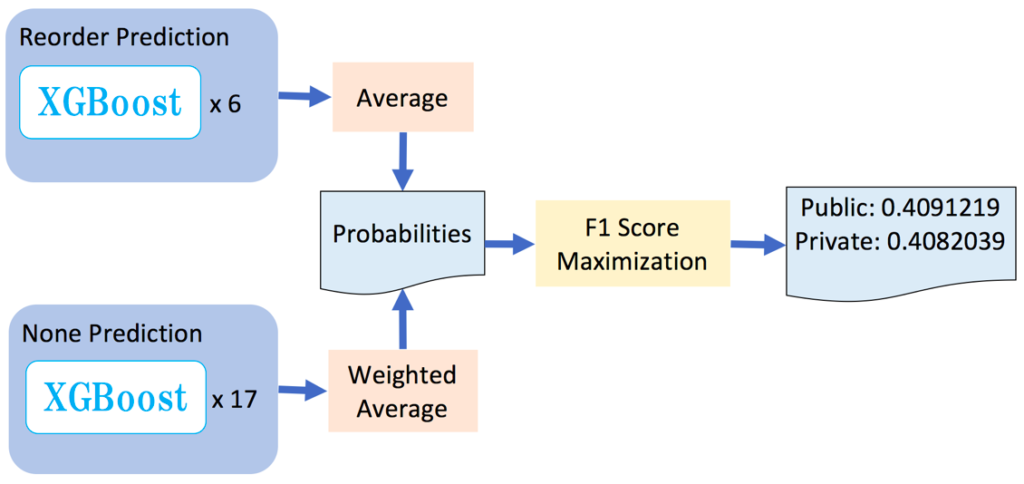
以下是模型流程图:
-
回购预测模型使用XGBoost来创建六个不同的梯度增强树模型(每个GBDT使用不同的随机种子)。我对这6个模型的预测取了一个平均,以获得用户A将在下一个订单中回购商品B的概率。
-
预测None模型使用XGBoost创建十七个不同的模型。其中11个使用eta参数(步长缩小),设置为0.01,其他使用eta参数,设置为0.002。我对这些预测进行加权平均,以获得用户A不会在下一个订单重新购买任何以前购买过的物品的概率。
-
为了将这些概率转换成二进制的Yes / No分数,哪一些商品用户A将在下一个订单中再次购买,我把它们输入到我创建的一个特殊的F1分数最大化算法中,详细如下。
探索性数据分析
让我们来探索一下数据。
用户有多狂热?他们下了多少订单呢
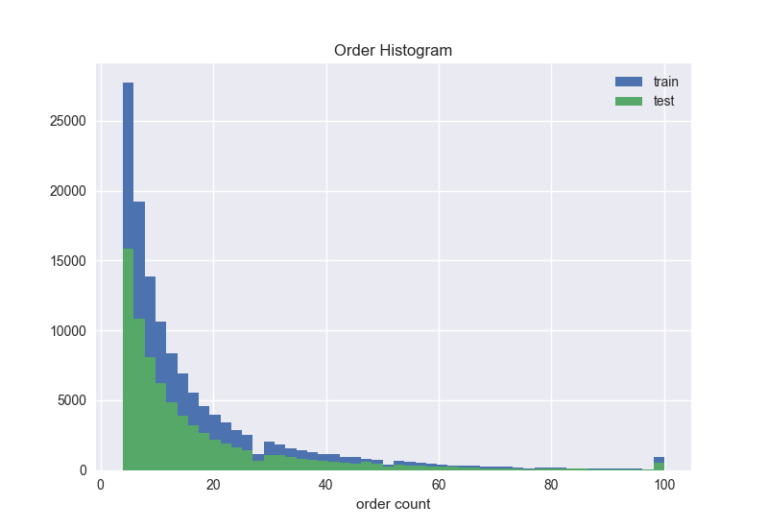

商品有多抢手呢?他们多久被购买一次呢?
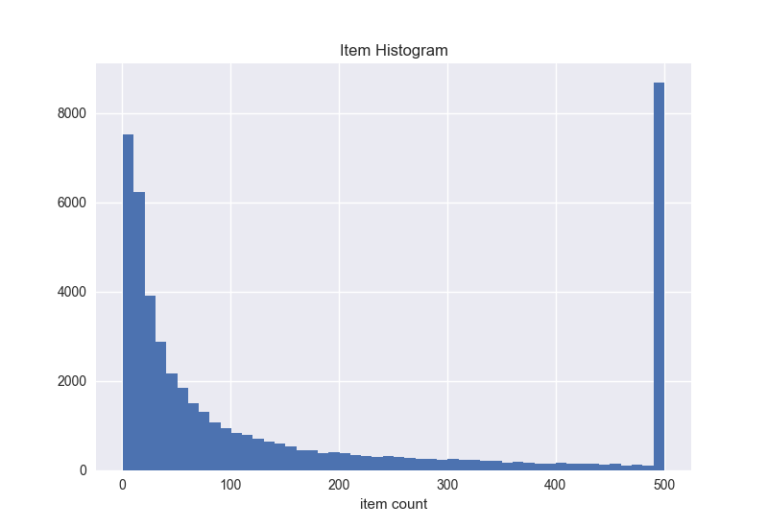
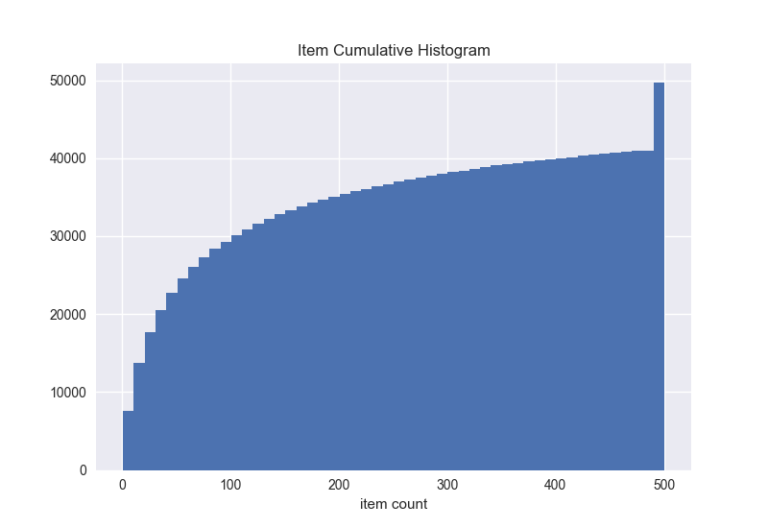
数据增强
我有一个想法就是更多的数据会帮助我做出更好的预测。所以,我决定增加我能够训练的数据量。
我们有三个数据集:
- 1.包含用户购买历史的“之前”数据集。
- 2.训练和测试数据集包括了我们可以训练和测试我们模型的将来的订单的数据。
我没有只用我们给定的数据集来训练我的模型,我通过加入每个用户最新的3个订单来增加我的训练数据集的大小。
下面的图表做了很好的解释:

我不是只使用提供的训练集(“tr”),我也往回看了一格(所在单元格用黄色阴影表示)来收集更多的数据。
特征工程
我建立了四种类型的特征:
- 1.日期时间特征:在哪一天,在什么时间?
- 2.用户特征:用户是什么样的?
- 3.商品特征:商品是什么样的?
- 4.用户x 商品特征:用户对商品有什么样的想法?
这是我创建这些特征的思路:
用户特征:
- 1.该用户多久回购商品
- 2.下订单的时间间隔
- 3.用户打开app的时间(一天之中)
- 4.该用户之前有没有购买过有机,不含麸质,或者亚洲商品
- 5.关于订单大小的特征
- 6.有多少商品不是之前购买过的
商品特征:
- 1.订单间隔时间的数据
- 2.该商品多久被购买一次
- 3.在购物车中的位置
- 4.多少用户只会购买该商品一次
- 5.有多少商品会跟该商品一同被购买
- 6.连续订单的数据
- 7.在N个订单中,该商品被回购的概率
- 8.在一周之中该商品在哪一天被回购的分布
- 9.在第一次订单之后,该商品被回购的概率
用户x 商品特征:
- 1.在该用户下过的订单中,有多少个订单用户购买过这个商品
- 2.距离该用户上次下单已经过去多少天了
- 3.该用户有多少次连续购买过此商品
- 4.商品在购物车中的位置
- 5.用户今天有没有购买过该商品
- 6.共同出现的商品的数据
- 7.替代商品
日期时间特征:
- 1.以周几作为衡量
- 2.以小时作为衡量
如果想要看到我所有的特征和他们如何生成的,请看我的Github
哪一个特征最有用?
我们可以从下图中,看到对于回购模型最重要的特征。。。
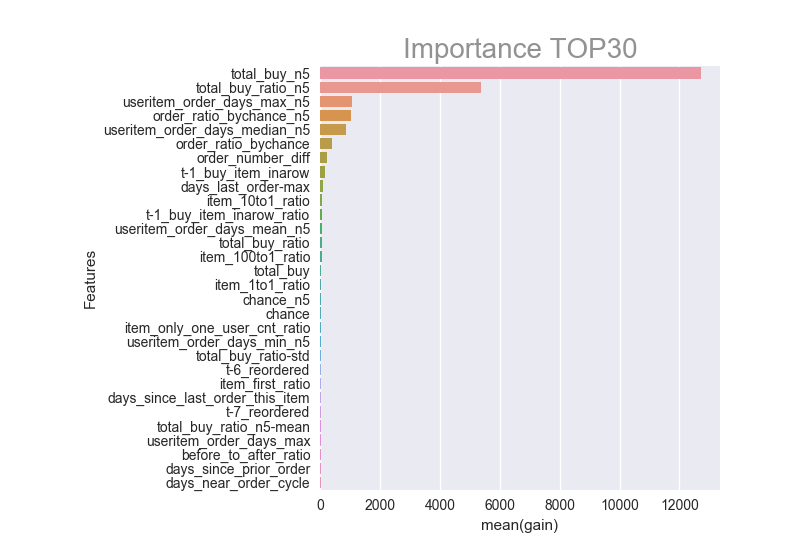
我们来解释一下最好的特征:
- 1.useritem_order_days_median_n5- 用户A没有购买商品B的天数的中位数
- 2.total_buy_n5(UserA, Item B) - 是在最近的5次订单中,用户A购买商品B的总次数
- 3.Total_buy_ratio_n5- 是在用户A的最近5次订单中,购买了商品B的订单比重
- 4.Useritem_order_days_max_n5- 在下面会有更详尽的描述,这个特征捕捉了用户A没有购买商品B的最长时间
- 5.order_ratio_by_chance_n5- 捕捉了在最近的订单中用户A有机会购买商品B的比例,而且用户A确实购买了。(“机会”是指用户在第一次遇到该商品之后,再遇到的购买该商品的机会的数量,例如,如果用户A的订单号为1-5,并且在订单号2时购买了商品B,则该用户有4次购买该产品的机会,订单编号2,3,4和5.)
注: 后缀“_n5”表示“near5”,即从最近的5个订单中提取的特征
对于预测None的模型,最重要的特征是…
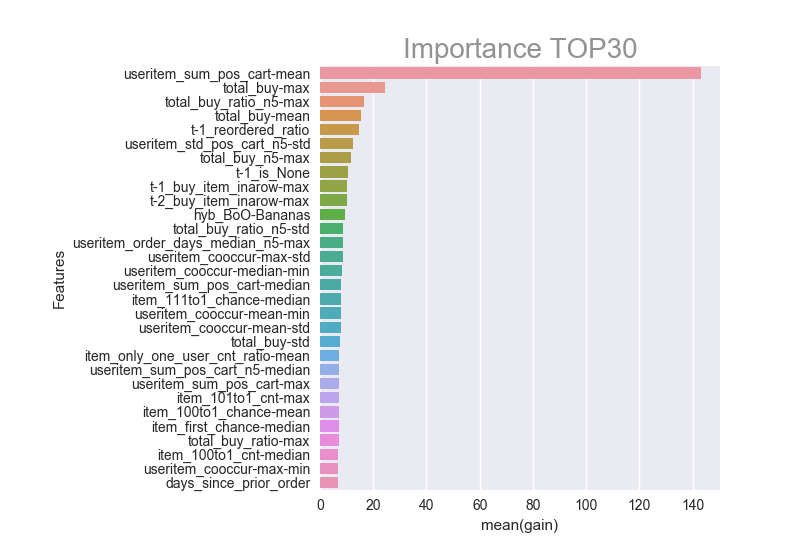
- 1.useritem_sum_pos_cart-mean(UserA) – 对于这个特征,下面会有更详尽的描述,是用来衡量该用户有没有一次购买很过商品的倾向
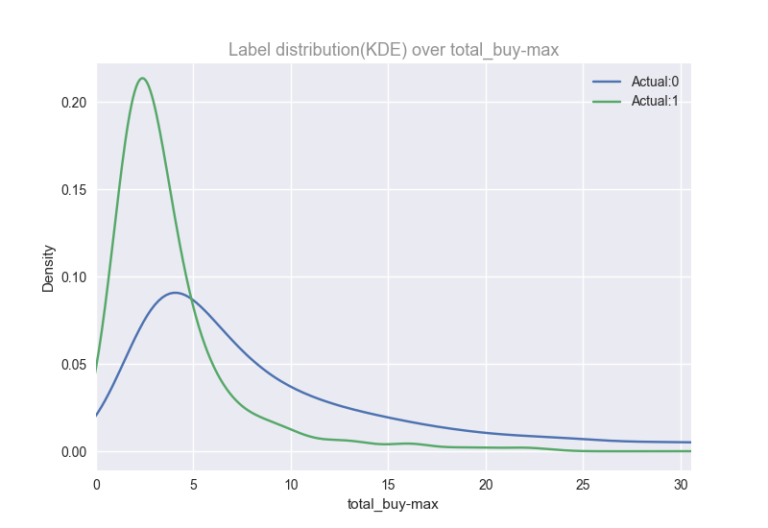
- 2.total_buy-max – 用户购买任何物品的最大次数
- 3.total_buy_ratio_n5-max-- 最近5个订单中,用户购买特定商品的所在订单的最大比例。例如,如果用户在最近的5次订单中有4次购买了一件商品,但是没有其他商品被更经常购买,那么这个特征就是0.8
- 4.total_buy-mean – 用户购买任何商品的平均次数
- 5.T-1_reordered_ratio-- 以前订单中回购商品的比例
想法
这是我对这个问题的一些重要的想法。
对于回购的重要发现-#1
让我们考虑一下回购的问题。常识告诉我们,过去多次购买的产品很有可能被再次回购。但是,该商品没有被回购时可能会有一个模式。我们可以尝试找出这种模式,并了解用户何时不回购一个商品。
比如说,考虑一下下面这个用户。
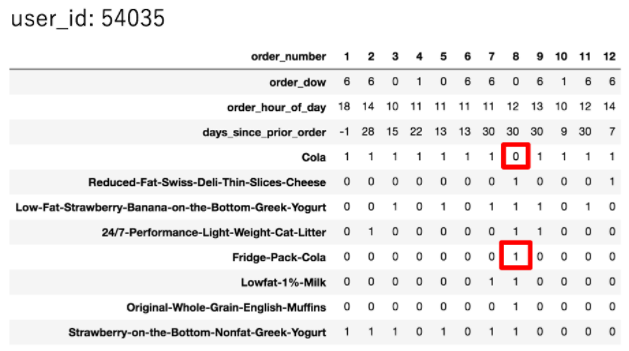
这个用户几乎总是买可乐。但是在8号订单中,他没有买。为什么呢?可能是因为该用户买了冰箱包的可乐。
所以,我创建了捕获这种行为的特征。
对于回购的重要发现- #2
- 1.Days_since_last_order_this_item(用户A,商品B)是我创建的一项特征,用于度量自用户A上次订购项目B以来经过的天数。
- 2.Useritem_orders_days_max(用户A,商品B)是上一个特征一直以来的最大值,即,用户A没有购买B的最长时间。
- 3.Days_last_order-max(用户A,商品B)是之前两个特征之间的差异。所以这个功能告诉我们用户有没有准备好回购这个物品。
事实上,如果我们绘制特征的分布,我们可以看到它能很好的预测我们的目标值。

对于回购的重要发现- #3
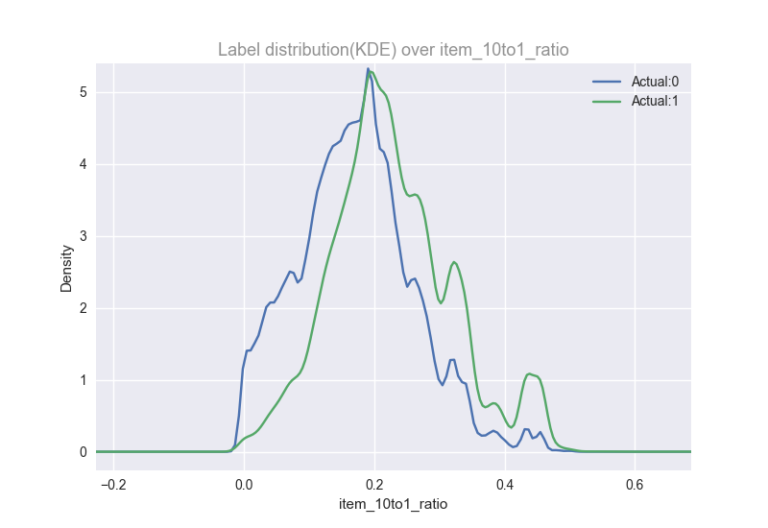
我们已经知道,水果比蔬菜更频繁地被回购(见3百万Instacart订单,公开源)。我想知道商品被购买的频率,所以我做了一个item_10to1_ratio特征,这个特征被定义为一个商品被回购和不被回购的比率。
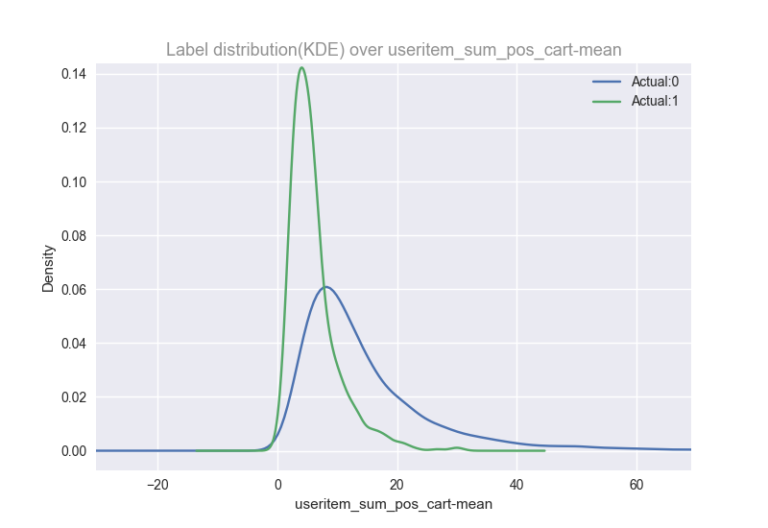
预测None模型的重要发现-#1
- 1.Useritem_sum_pos_cart(用户A,商品B)–是商品B落入用户A的购物车中的位置号码的总和。
- 2.Useritem_sum_pos_cart-mean(用户A)是上述特征的在所有商品中的平均值。
此功能表示,一次不购买多件商品的用户更有可能成为“None”。
None预测模型的重要发现- #2
Total_buy-max(用户A)是用户A购买任何商品的总次数。它可以预测用户是否会回购。
None预测模型的重要发现- #3
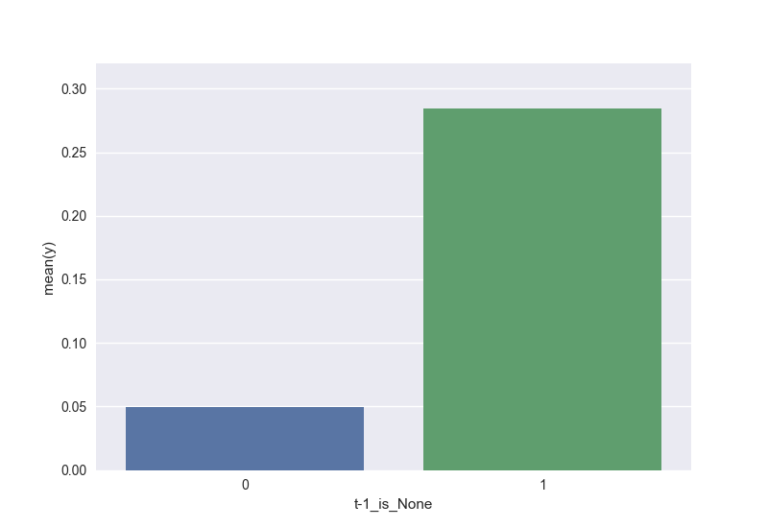
t-1_is_None(用户A)是一个二进制特征,表示用户的先前的回购订单是否为无(即不包含回购的产品)
如果先前的订单是无,那么下一个订单也将是30%概率的无。
F-1最大化
在这个比赛中,评估指标是F1 score,是在单一指标中能够同时捕捉到精准度和召回率的方法。
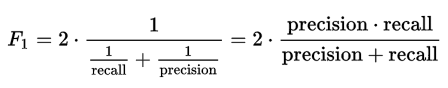
因此,我们不需要返回回购的概率,而是将它们转换为二进制1/0(是/否。
为了执行这个转换,我们需要知道一个阈值。首先,我使用网格搜索来找到0.2的通用阈值。不过,我在Kaggle讨论板上看到了一些评论,建议不同的订单应该有不同的阈值。
要理解为什么,我们来看一个例子。
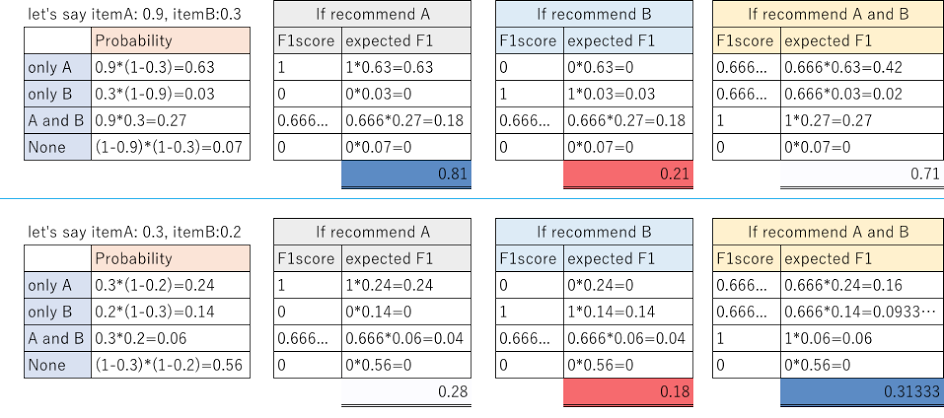
我们来看第一行的订单。假设我们的模型预测商品A将有0.9概率被回购,商品B将以0.3概率被回购。如果我们预测只有A将会被回购,那么我们预期的F1分数是0.81; 如果我们预测只有B会被回购,那么我们预期的F1分数是0.21; 如果我们预测A和B都将被回购,那么我们预期的F1得分为0.71。
因此,我们应该预测,商品A并且只有商品A将被回购。如果我们使用0.3和0.9之间的阈值,就会发生这种情况。
同样,对于第二行中的订单,我们的最佳选择是预测商品A和B将被回购。当阈值小于0.2(商品B将被回购的概率)时,这将会发生。
这说明每个订单都应该有自己的阈值。
寻找阈值
我们如何决定阈值?我写了一个模拟算法。
假设我们的模型预测商品A将有0.9的概率被回购,商品B的概率为0.3。然后使用这些概率模拟9,999个目标标签(是否订购A和B)。例如,模拟的标签可能看起来像这样。

然后我计算每组标签的预期F1分数,从最大概率的商品开始,然后添加商品(例如[A],然后[A,B],然后[A,B,C]等) 直到F1分数达到最大值然后下降。

预测None
考虑None的一种方法是概率:(1 - 商品A)(1 - 商品B)…
但另一种方法是试图预测“无”的一个特例。 通过创建None模型并将None作为另一个商品,我能够将我的F1分数从0.400提高到0.407。