对深度可分离卷积、分组卷积、扩张卷积、转置卷积(反卷积)的理解
本问主要介绍几种不同类型的卷积。
1. 深度可分离卷积(depthwise separable convolution)
在可分离卷积(separable convolution)中,通常将卷积操作拆分成多个步骤。而在神经网络中通常使用的就是深度可分离卷积(depthwise separable convolution)。
举个例子,假设有一个3×3大小的卷积层,其输入通道为16、输出通道为32。
那么一般的操作就是用32个3×3的卷积核来分别同输入数据卷积,这样每个卷积核需要3×3×16个参数,得到的输出是只有一个通道的数据。之所以会得到一通道的数据,是因为刚开始3×3×16的卷积核的每个通道会在输入数据的每个对应通道上做卷积,然后叠加每一个通道对应位置的值,使之变成了单通道,那么32个卷积核一共需要(3×3×16)×32 =4068个参数。
1.1 标准卷积与深度可分离卷积的不同
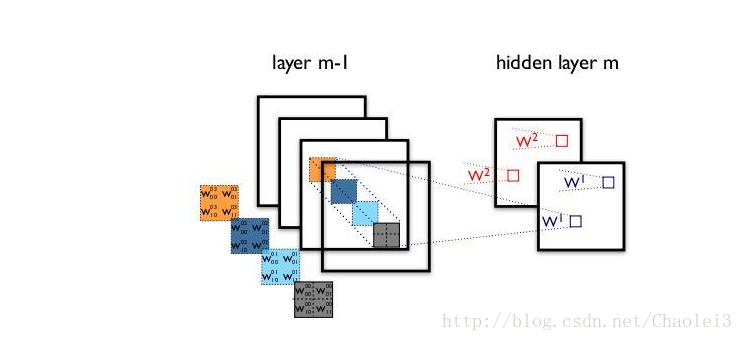
用一张来解释深度可分离卷积,如下:
可以看到每一个通道用一个filter卷积之后得到对应一个通道的输出,然后再进行信息的融合。而以往标准的卷积过程可以用下面的图来表示:
如下动图所示:
1.2 ...
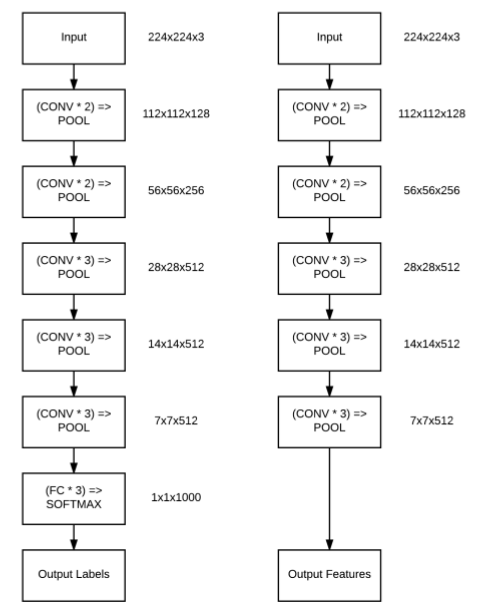
深度学习与计算机视觉(PB-03)-特征提取
从这节开始,我们将讨论关于迁移学习的内容,即用预先训练好的模型(往往是在大型数据上训练得到的)对新的数据进行学习.
首先,从传统的机器学习场景出发,即考虑两个分类任务:
第一个任务是训练一个卷积神经网络来识别图像中的狗和猫。
第二个任务是训练一个卷积神经网络识别三种不同的熊,即灰熊、北极熊和大熊猫。
正常情况下,当我们使用机器学习、神经网络和深度学习等进行实践时,我们会将这两个任务视为两个独立的问题。首先,我们将收集足够多的带有标记的狗和猫的数据集,然后在该数据集上训练一个模型。一般而言,对于不同的数据,都是不断地重复这个过程,即在第二个任务中,收集足够多的带有标记的熊品种的数据集,然后在该数据集上训练一个模型。
上面两个任务中,我们独立地对每一个任务收集数据,训练模型,两个任务之间是相互独立的。而迁移学习却是另外一种不同的训练模式——假如我们加载现有预先训练好的模型,并将其作为新分类任务的训练拟合过程开始点?比如上面两个任务,首先,我们在猫和狗的数据集上训练一个卷积神经网络。然后,我们使用从猫和狗数据集中训练得到的卷积神经网络去区分熊的种类,注意的是:训练模型的数据并没 ...
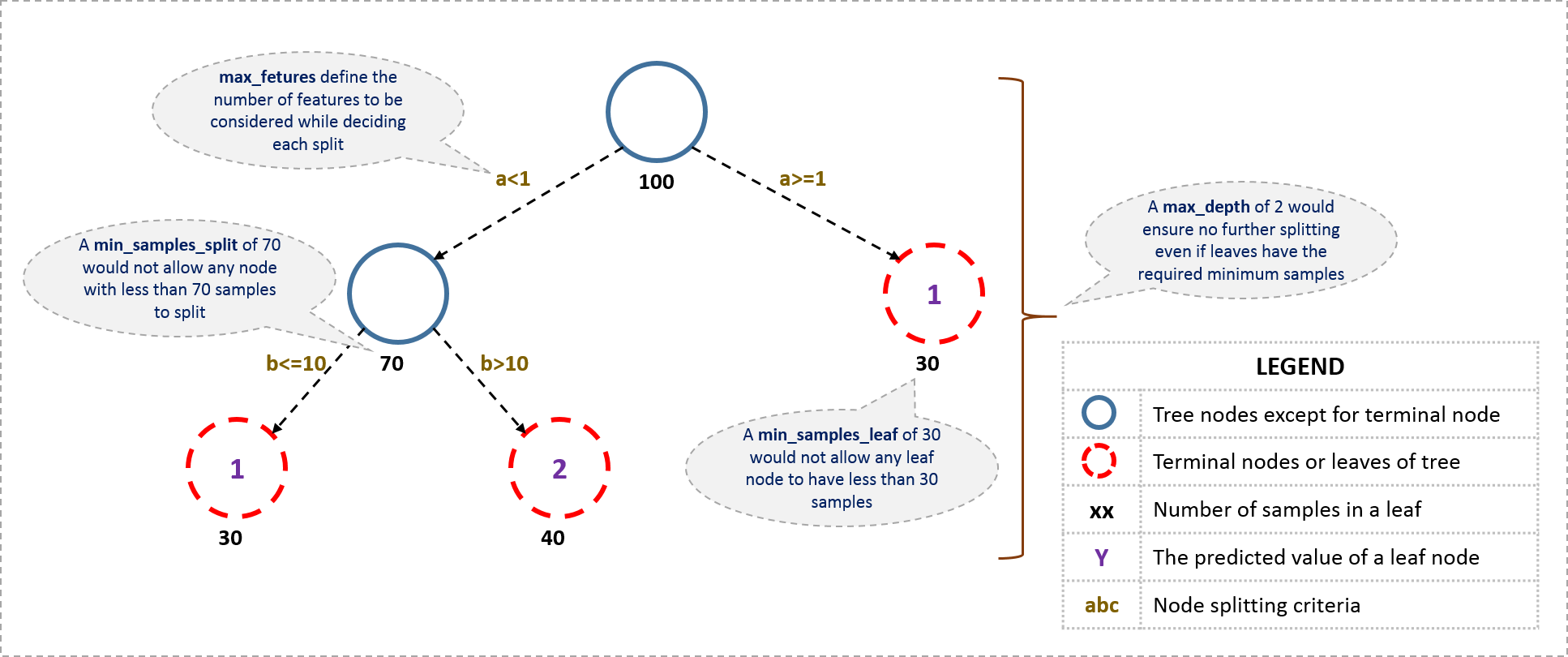
Gradient Boosting Machine(GBM)调参方法详解
如果一直以来你只把GBM当作黑匣子,只知调用却不明就里,是时候来打开这个黑匣子一探究竟了!
这篇文章是受Owen Zhang (DataRobot的首席产品官,在Kaggle比赛中位列第三)在NYC Data Science Academy里提到的方法启发而成。他当时的演讲大约有2小时,我在这里取其精华,总结一下主要内容。
不像bagging算法只能改善模型高方差(high variance)情况,Boosting算法对同时控制偏差(bias)和方差都有非常好的效果,而且更加高效。如果你需要同时处理模型中的方差和偏差,认真理解这篇文章一定会对你大有帮助,因为我不仅会用Python阐明GBM算法,更重要的是会介绍如何对GBM调参,而恰当的参数往往能令结果大不相同。
特别鸣谢: 非常感谢Sudalai Rajkumar对我的大力帮助,他在AV Rank中位列第二。如果没有他的指导就不会有这篇文章了。
1.目录
Boosing是怎么工作的?
理解GBM模型中的参数
学会调参(附详例)
2.Boosting是如何工作的?
Boosting可以将一系列弱学习因子(weak learners ...

深度学习与计算机视觉(PB-02)-数据增强
在深度学习实践中,当训练数据量少时,可能会出现过拟合问题。根据Goodfellow等人的观点,我们对学习算法的任何修改的目的都是为了减小泛化误差,而不是训练误差。
我们已经在sb[后续补充]中提到了不同类型的正则化手段来防止模型的过拟合,然而,这些都是针对参数的正则化形式,往往要求我们修改loss函数。事实上,还有其他方式防止模型过拟合,比如:
1.修改网络本身架构
2.增加数据
Dropout是通过修改网络本身结构以达到正则化效果的技术。Dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
在这节,我们讨论另外一种防止过拟合方法,叫做数据增强(data augmentation),该方法主要对训练数据集进行一定的变换,改变图片的外观,然后将得到的‘新’图片进行模型训练。使用数据增强技术可以得到更多的数据。
备注:预测时候是不是也可以利用data augmentation,结果使用投票方法得到呢?
数据增强
数据增强主要是运用各种技术 ...

加载预训练词向量模型-python
本文主要是使用python加载预训练的词向量模型,这些模型都是使用大规模的预料训练得到,如word2vec,glove和fasttext。使用预训练的模型可以提高我们的准确性。
简单看看三者之间的区别
Word2Vec
word2vec的主要思想是在根据每个单词的上下文训练一个模型,因此,类似的单词也会有类似的数字表示。
就像一个前馈神经网络(NN),假设你有一组独立的变量和一个你想要预测的目标变量,你首先把你的句子变成单词(tokenize),并根据窗口的大小创建多个词组。所以其中一个组合可以是一对单词,比如(“cat”,“purr”),其中"cat"是独立变量(X),而“purr”是我们想要预测的目标因变量(Y)。
我们通过一个由随机权值初始化的embedding层将“cat”输入到NN中,并将其传递到softmax层,最终目的是预测“purr”。优化方法如SGD将损失函数最小化"(target word | context words)" ,该方法试图将给定上下文单词的目标词的预测损失最小化。如果我们使用足够的epoch的训练,那么em ...
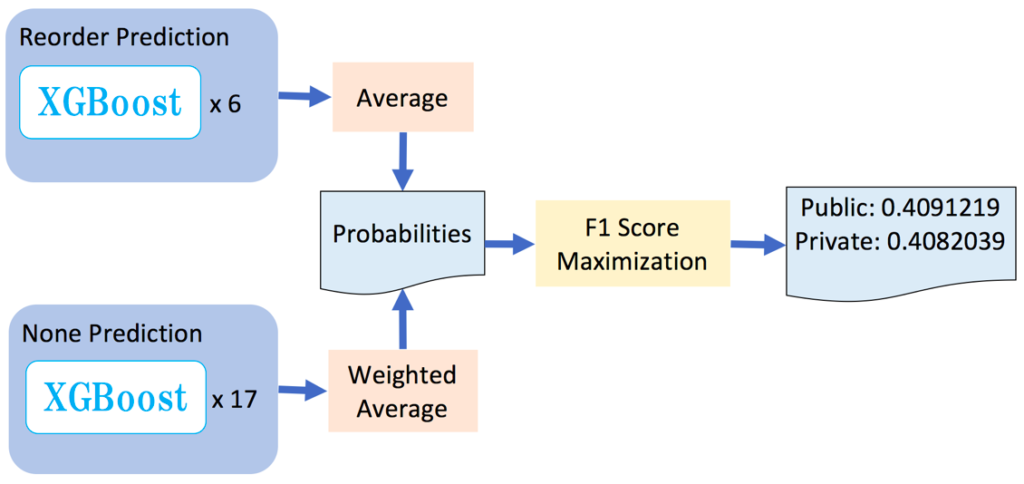
Instacart Market Basket Analysis(2nd place)
这个比赛是要根据顾客的历史购买记录,预测 Instacart 的消费者将再次购买哪种商品,这样可以在顾客需要这个商品的时候,货源是充足的。这种侧重于理解时间行为模式的问题使得这个问题与普通的项目推荐有所不同,在普通项目推荐中,我们通常假设用户的需求和偏好在短时间内相对固定。 对于Netflix来说,他们可以猜想你看了这部电影,你就会想看另一部类似的电影,但如果是你昨天买了杏仁黄油和卫生纸,今天你会不会再买这两样就不好说了.
数据说明:
12345678910111213141. 数据说明 数据共有300 0000orders, 20 0000users, 5000products, 每个user提供有4-100个orders2. 各数据内容了解 aisles:产品摆放位置说明 order_products__prior:订单产品关联表 orders.csv: 用户下单记录表。 products.csv: 产品ID分类,及其摆放位置的关系表 departments.csv: 产品分类表3. 目标分析 目标是预测用户下次购 ...
FM算法-python实现
我仍然记得第一次遇到点击率预测问题时的情形,在那之前,我一直在学习数据科学,对自己取得的进展很满意,在机器学习黑客马拉松活动中也开始建立了自信,并决定好好迎接不同的挑战。
为了做得更好,我购买了一台内存16GB,i7处理器的机器,但是当我看到数据集的时候却感到非常不安,解压缩之后的数据大概有50GB - 我不知道基于这样的数据集要怎样进行点击率预测。幸运地是,Factorization Machines(FM)算法拯救了我。
任何从事点击率预测问题或者推荐系统相关工作的人都会遇到类似的情况。由于数据量巨大,利用有限的计算资源对这些数据集进行预测是很有挑战性的。
然而在大多数情况下,由于很多特征对预测并不重要,所以这些数据集是稀疏的(每个训练样本只有几个变量是非零的)。在数据稀疏的场景下,因子分解有助于从原始数据中提取到重要的潜式或隐式的特征。
因子分解有助于使用低维稠密矩阵来表示目标和预测变量之间的近似关系。在本文中我将讨论算法Factorization Machines(FM) 和Field-Aware Factorization Machines(FFM),然后在回归/分类问题中 ...
Regularized Greedy Forests (RGF)-正则化贪心森林
本文主要简单的说明下boosting algorithms家族中的一个算法成员,叫做Regularized Greedy Forests (RGF),在GBDT的基础上,RGF算法针对GBDT每次迭代只优化新建树以及过拟合的问题,提出了正则化的全局优化贪心搜索改进算法:
1.每次迭代直接对整个贪心森林进行学习
2.新增决策树后进行全局的参数优化
3.引入显式的针对决策树的正则项来防止过拟合。
非线性函数学习中,梯度提升算法是当前最有效的一种算法,每一迭代都依赖与上次迭代训练的结果,错误分类的数据被增大权重,因此下次训练时候会重点关注权重比较大的数据.
然而,GBDT算法将决策树基函数看成一个黑盒子,因而可以很方便的将决策树替换成其他算法,但是,在GBDT算法中,每一次的迭代中的唯一目标就是学习出n个节点决策树,从而将单颗树的学习与整个森林的学习分隔开.没有很好的利用到决策树本身的性质.新增的决策树只会改变本身参数的变化而没有改变老决策树的参数.
相反,在RGF算法中主要分为两部分:
固定节点权重,更改森林的结构使得损失函数下降的最快
固定森林的结构,更新节点权重使得损失函数 ...
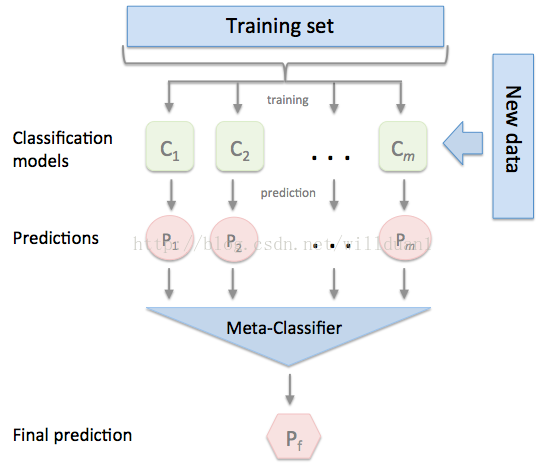
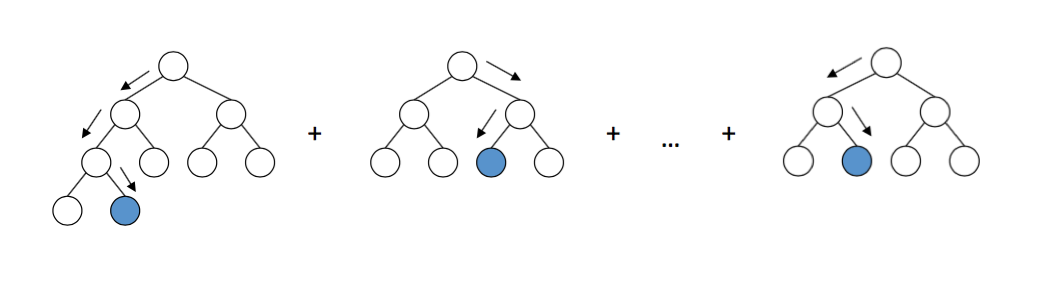
Ensemble之stacking
Stacking是一种模型组合技术,用于组合来自多个预测模型的信息,以生成一个新的模型。即将训练好的所有基模型对整个训练集进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测.
当然,stacking并不是都能带来惊人的效果,当模型之间存在明显差异时,stacking的效果是相当好的,而当模型都很相似时,带来的效果往往并不是那么亮眼。
实现
直接以kaggle的Porto Seguro’s Safe Driver Prediction比赛数据为例。
这是Kaggle在9月30日开启的一个新的比赛,举办者是巴西最大的汽车与住房保险公司之一:Porto Seguro。该比赛要求参赛者根据汽车保单持有人的数据建立机器学习模型,分析该持有人是否会在次年提出索赔。比赛所提供的数据均已进行处理,由于数据特征没有实际意义,因此无法根据常识或业界知识简单地进行特征工程。
数据下载地址: Data
加载所需要模块
123456789101112131415 ...
Kaggle网站流量预测任务第一名解决方案
近日,Artur Suilin 等人发布了 Kaggle 网站流量时序预测竞赛第一名的详细解决方案。他们不仅公开了所有的实现代码,同时还详细解释了实现的模型与经验。
该比赛主要预测维基百科约145000篇文章的未来网页流量问题,属于时序预测问题。
下面我们将简要介绍 Artur Suilin 如何修正 GRU 以完成网站流量时序预测竞赛。
预测有两个主要的信息源:
1.局部特征。我们看到一个趋势时,希望它会继续(自回归模型)朝这个趋势发展;看到流量峰值时,知道它将逐渐衰减(滑动平均模型);看到假期交通流量增加,就知道以后的假期也会出现流量增加(季节模型)。
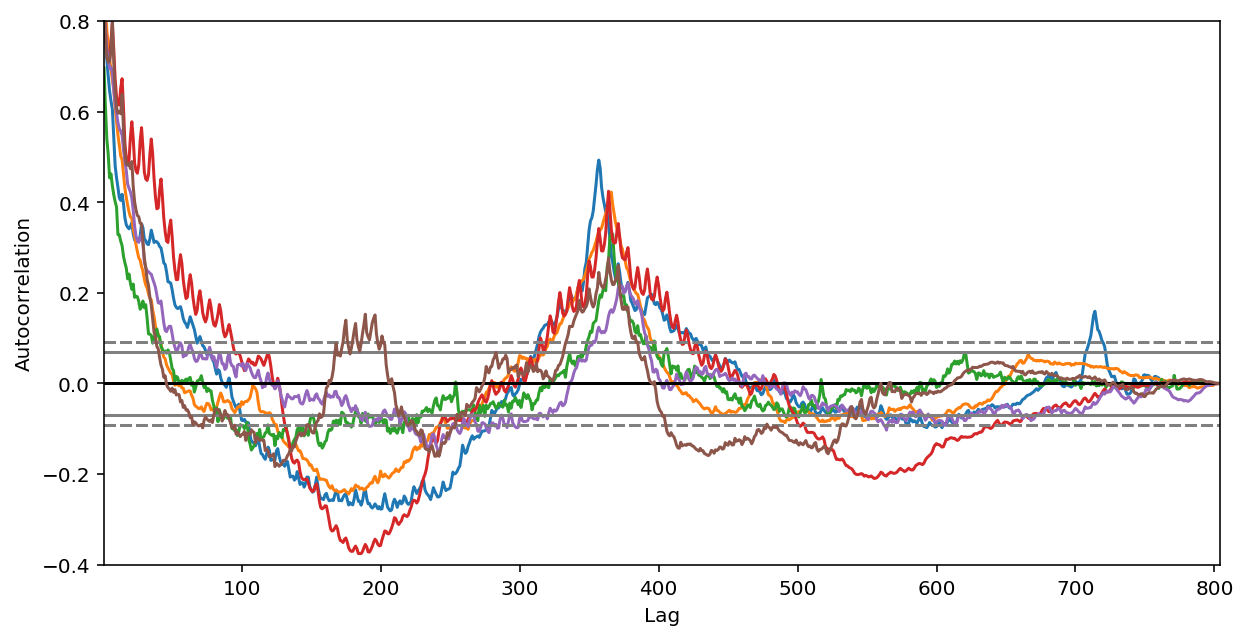
2.全局特征。如果我们查看自相关(autocorrelation)函数图,就会注意到年与年之间强大的自相关和季节间的自相关。
我决定使用 RNN seq2seq 模型进行预测,原因如下:
1.RNN 可以作为 ARIMA 模型的自然扩展,但是比ARIMA 更灵活,更具表达性.
2.RNN 是非参数的,大大简化了学习。想象一下对 145K 时序使用不同的ARIMA 参数。
3.任何外源性的特征(数值或类别、时间依赖或序列依赖 ...

