关系分类在自然语言处理时一个很重要的语义处理任务,目前state-of-the-art的系统非常依赖于词汇量,例如WordNet等,还有一个问题是重要的信息不知道在句子中的什么位置。因此,本文提出基于attention构建双向LSTM网络(attention-based bidirectional long short-term memory networks (att-BLSTM)),用于capture句子中的重要信息。并从作者的实验中可以看出,性能较好,而且需要注意的是该论文的模型没有使用任何的基于词汇构造而成的特征,仅仅依赖于词向量。
主要内容
model
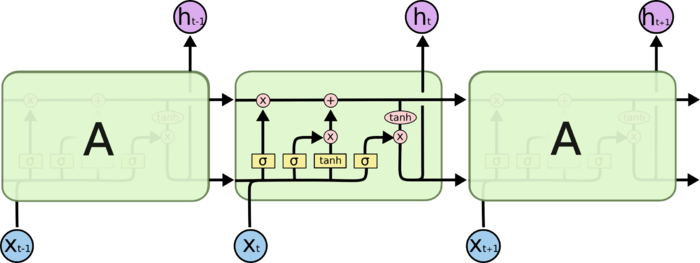
可以从图中看到,该论文在处理模型之前,也做了词向量跟位置向量的处理,模型结构如下图所示:
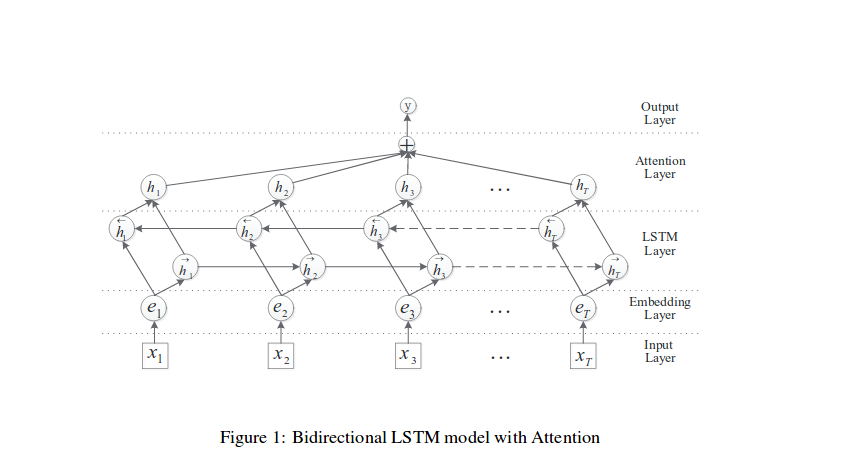
这里我们主要简单说明下每一层的作用:
1.输入层:将原始句子输入该层
2.embedding层:将每一个单词映射到一个低维向量
3.LSTM层:利用BLSTM模型从step(2)中得到高级特征
4.attention层:产生一个权重向量,并与LSTM的每一个时间点上word-level特征相乘得到sentence-level特征向量。
5.输出层:将得到的senten-level特征向量用于关系分类。
word embedding
从论文中可以看出,作者在输入层中使用了词向量跟位置向量的处理操作。
attention
从论文可以看到,作者使用的是常见的attention机制,下面简单的进行说明:
假设由LSTM得到的输出向量为,记为H,其中T为句子的长度,则可得到:
从而可以得到:
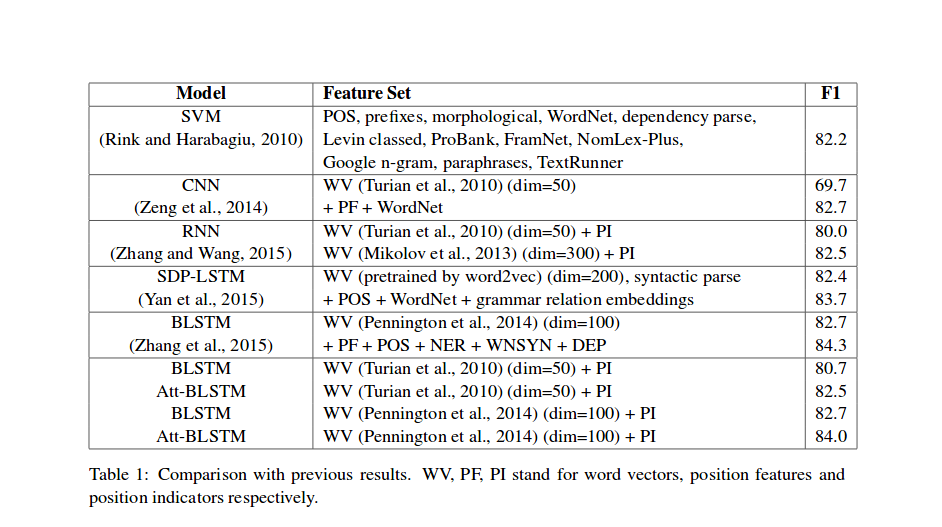
实验结果
实验结果如下所示:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 闲记算法!
相关推荐


评论

