
基于PyTorch实现word2vec模型
word2vec是google于2013年的《Distributed Representations of Words and Phrases and their Compositionality 》以及后续的《Efficient Estimation of Word Representations in Vector Space 》两篇文章中提出的一种高效训练词向量的模型, 基本出发点是上下文相似的两个词,它们的词向量也应该相似, 比如香蕉和梨在句子中可能经常出现在相同的上下文中,因此这两个词的表示向量应该就比较相似。本文前部分主要从理论方面介绍word2vec,后半部分主要基于PyTorch框架实现word2vec模型(skip-gram)。
word2vec理论
word2vec模型中比较重要的概念是词汇的上下文, 说白了就是一个词周围的词, 比如wtw_twt的范围为1的上下文就是wt−1w_{t-1}wt−1和wt+1w_{t+1}wt+1,在word2vec中提出两个模型(假设上下文窗口为3)
CBOW(Continuous Bag-of-Word): 以上下文词 ...
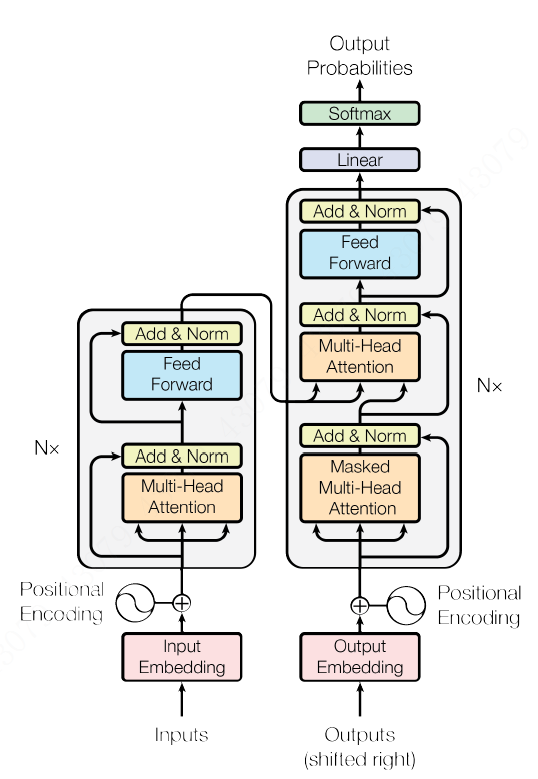
Transformer原理和实现
所谓 ”工预善其事,必先利其器“, BERT之所以取得这么惊才绝艳的效果,很大一部分原因源自于Transformer。为了后面更好、更快地理解BERT模型,这一节从Transformer的开山鼻祖说起,先来跟着”Attention is All You Need[1]“ 这篇文章,走近transformer的世界,在这里你再也看不到熟悉的CNN、RNN的影子,取而代之的是,你将看到Attention机制是如何被发挥的淋漓尽致、妙至毫颠,以及它何以从一个为CNN、RNN跑龙套的配角实现华丽逆袭。对于Bert来说,transformer真可谓天纵神兵,出匣自鸣!
看完本文,你大概能够:
掌握Encoder-Decoder框架
掌握残差网络
掌握BatchNormalization(批归一化)和LayerNormalization(层归一化)
掌握Position Embedding(位置编码)
当然,最重要的,你能了解Transformer的原理和代码实现。
Notes: 本文代码参考哈弗大学的The Annotated Transformer
Encoder-Decoder框架
E ...

self—attention
本系列文章希望对google BERT模型做一点解读。打算采取一种由点到线到面的方式,从基本的元素讲起,逐渐展开。
讲到BERT就不能不提到Transformer,而self-attention则是Transformer的精髓所在。简单来说,可以将Transformer看成和RNN类似的特征提取器,而其有别于RNN、CNN这些传统特征提取器的是,它另辟蹊径,采用的是attention机制对文本序列进行特征提取。
所以我们从self-Attention出发。
Attention is all your need
尽管attention机制由来已久,但真正令其声名大噪的是google 2017年的这篇名为《attention is all your need》的论文。
让我们从一个简单的例子看起:
假设我们想用机器翻译的手段将下面这句话翻译成中文:
“The animal didn’t cross the street because it was too tired”
当机器读到“it”时,“it”代表“animal”还是“street”呢?对于人类来讲,这是一个极其简单的问题,但是对 ...
认识交叉熵损失
交叉熵(cross entropy)是深度学习中常用的一个概念,一般用来求目标与预测值之间的差距,下面将主要介绍交叉熵损失。
交叉熵损失函数
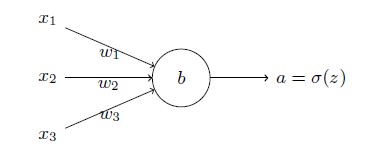
理想地,我们希望神经网络可以从错误中快速地学习。在实践中,这种情况经常出现吗?为了回答这个问题,让我们看看一个小例子。这个例子包含一个只有一个输入的神经元:
我们会训练这个神经元来做一件非常简单的事:让输入1 转化为0。当然,这很简单了,手工找到合适的权重和偏置就可以了,不需要什么学习算法。然而,看起来使用梯度下降的方式来学习权重和偏置是很有启发的。所以,我们来看看神经元如何学习。
为了让这个例子更明确,我们会首先将权重和偏置初始化为0.6 和0.9。这些就是一般的开始学习的选择,并没有任何刻意的想法。一开始的神经元的输出是0.82,所以这离我们的目标输出0.0 还差得很远。从下图来看看神经元如何学习到让输出接近0.0 的。注意这些图像实际上是正在进行梯度的计算,然后使用梯度更新来对权重和偏置进行更新,并且展示结果。设置学习速率η=0.15\eta =0.15η=0.15 进行学习,一方面足够慢的让我们跟随学习的过程,另一方面也保证了学习的时 ...
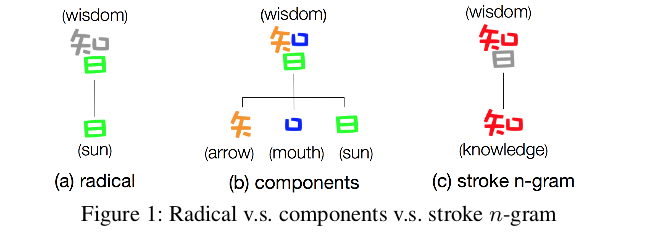
cw2vec Learning Chinese Word Embeddings with Stroke n-gram Information
cw2vec是蚂蚁金服2018年提出的基于笔画的中文词的embedding 方法。文中作者提到利用笔画级别的信息对于改进中文词语嵌入的学习至关重要。具体来说,首先将词转化为笔画序列,然后通过对笔画序列进行n-gram来捕获中文单词的语义和形态信息。
实现的代码地址: https://github.com/lonePatient/cw2vec-pytorch
1.介绍
我们知道,在中文中,每个单词的字符个数往往比英文单词少,每个字符包含了丰富的语义信息。但是字符级的信息足以恰当地捕捉单词的语义信息吗?是否还有其他有用的信息可以从单词和字符中提取出来,以更好地捕抓单词的语义?例如,两个单词“木材”和“森林”在语义上紧密相关。然而,“木材”由“木”和材”两个字符组成,而“森林”由“森”和“林 ”两个字符组成。如果仅考虑字符级信息,很显然该两个单词由不同的字符组成,那么在这两个单词之间是没有共享的信息。另外,如图1(a)所示,“日”作为“智”的一部分,但是几乎不包含与"智"相关的任何语义信息。除了传统的偏旁部首,再来看看另一种形式,如图1(b)所示,“智”被分解为“矢”, ...

PyTorch常用代码段
记录一些常用的Pytorch代码,方便后续查找。
编码风格
我们试图遵循 Google 的 Python 编程风格。请参阅 Google 提供的优秀的 python 编码风格指南(见参考资料)。
在这里,我们会给出一个最常用命名规范小结:
Type
Convention
Example
Packages & Modules
lower_with_under
from prefetch_generator import BackgroundGenerator
Classes
CapWords
class DataLoader
Constants
CAPS_WITH_UNDER
BATCH_SIZE=16
Instances
lower_with_under
dataset = Dataset
Methods & Functions
lower_with_under()
def visualize_tensor()
Variables
lower_with_under
background_color=‘Blue’
常用模块
常用的 ...
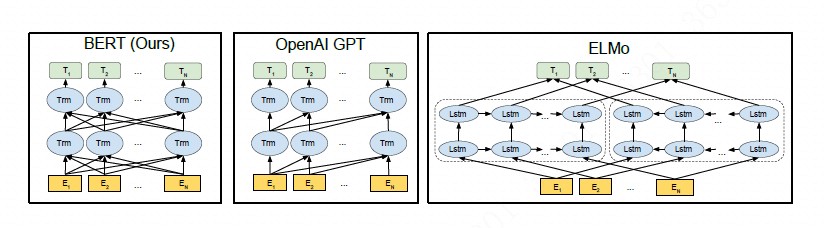
BERT-Pre-training of Deep Bidirectional Transformers for Language Understanding
本文介绍一种新的语言表征模型BERT—基于Transformers的双向编码器表示。异于最新语言表征模型,BERT基于所有层的左、右语境来预训练深度双向表征。BERT是首个大批句子层面和词块层面任务中取得当前最优性能的表征模型,性能超越许多使用任务特定架构的系统,刷新11项NLP任务当前最优性能记录,堪称最强NLP预训练模型!未来可能成为新行业基础。本文参考网上各大文章,整理翻译了BERT论文,在自己学习的同时也分享给大家,欢迎交流指教。
摘要
本文介绍一种称之为BERT的新语言表征模型,即Transformers的双向编码器表征量(BidirectionalEncoder Representations from Transformers)。不同于最近的语言表征模型(Peters等,2018; Radford等,2018),BERT旨在基于所有层的左、右语境来预训练深度双向表征。因此,预训练的BERT表征可以仅用一个额外的输出层进行微调,进而为很多任务(如问答和语言推理)创建当前最优模型,无需对任务特定架构做出大量修改。
BERT的概念很简单,但实验效果很强大。它刷新了11个NLP ...

Pytorch深度学习入门
在本教程中,将使用Pytorch框架介绍深度学习,并通过一个简单案例进行实验,通过本教程,你将可以轻松地使用Pytorch框架构建深度学习模型。(我也刚刚接触Pytorch)
Pytorch 简介
Pytorch 是一个基于 Torch 的 Python 机器学习包,而 Torch 则是一个基于编程语言 Lua 的开源机器学习包。Pytorch 有两个主要的特点:
利用强大的 GPU 加速进行张量计算(如 NumPy)
用于构建和训练神经网络的自动微分机制
相比其它深度学习库,Pytorch 具有以下两点优势:
与 TensorFlow 等其它在运行模型之前必须先定义整个计算图的库不同,Pytorch 允许动态定义图。
Pytorch 也非常适合深度学习研究,提供了最大的灵活性和运行速度。
Tensors
Pytorch 张量与 NumPy 数组非常相似,而且它们可以在 GPU 上运行。这一点很重要,因为它有助于加速数值计算,从而可以将神经网络的速度提高 50 倍甚至更多。为了使用 Pytorch,你需要先访问其官网并安装 Pytorch。如果你正在使用 Conda,你可以通 ...
如何找到一个好的学习率
我们知道学习率是深度学习模型中一个非常重要的超参数,因此,当训练深度学习模型时,我们如何确定学习率的大小? 如果学习率太小,网络将会训练很慢且耗时(比如学习率设置为1e-6)。如果学习率太高,网络在训练过程中可能会跳过最小值点。更糟糕的是,高学习率可能会导致loss不断变大,这样就脱离了模型的学习目标。
介绍
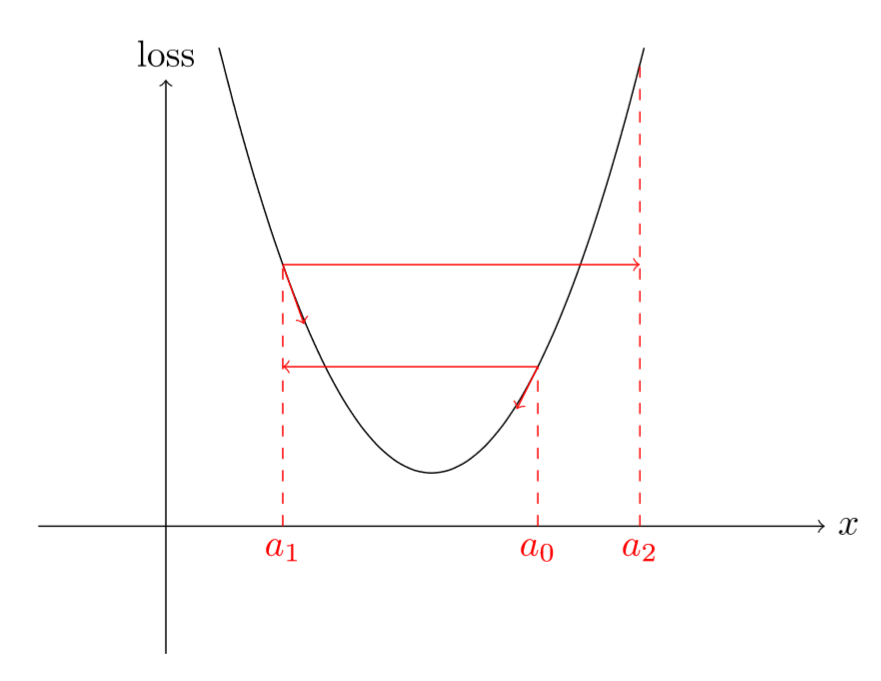
如下图所示,高的学习率,可能会出现跳过最小值点情况,并且loss还增加:
图1
因此,对于训练深度学习模型,我们需要选择一个合理的学习率大小,既不能太大也不能太小。以往我们根据不同的学习率实验或者经验得到一个“认为”合理的学习率,但在在这篇文章中提出了一种新方法: 在一个epoch中,首先,对优化器(比如SGD)设置一个非常低的学习率(如10-8),然后,在每次小batch数据训练中改变学习率(比如乘以某个因子),直到学习率达到一个非常高的值(如1或10)或者loss开始变大,停止训练,最后,我们将学习率和loss变化绘制在同张图中,如下图所示:
图2
仔细观察上图,会发现,一开始loss在减少,但是瞬间停止并且变大,这个主要是因为学习率非常低。但是,随着学习率的变大,lo ...
周期性学习率(Cyclical Learning Rate)技术
本文介绍神经网络训练中的周期性学习率技术。
Introduction
学习率(learning_rate, LR)是神经网络训练过程中最重要的超参数之一,它对于快速、高效地训练神经网络至关重要。简单来说,LR决定了我们当前的权重参数朝着降低损失的方向上改变多少。
1new_weight = exsiting_weight - learning_rate * gradient
这看上去很简单。但是正如许多研究显示的那样,单单通过提升这一步就会对我们的训练产生深远的影响,并且尚有很大的优化空间。
本文介绍了一种叫做周期性学习率(CLR)的技术,它是一种非常新的、简单的想法,用来设置和控制训练过程中LR的大小。该技术在jeremyphoward今年的fast.ai course课程中提及过。
Motivation
神经网络用来完成某项任务需要对大量参数进行训练。参数训练意味着寻找合适的一些参数,使得在每个batch训练完成后损失(loss)达到最小。
通常来说,有两种广泛使用的方法用来设置训练过程中的LR。
One LR for all parameters
一个典型的例子是SGD, 在 ...

