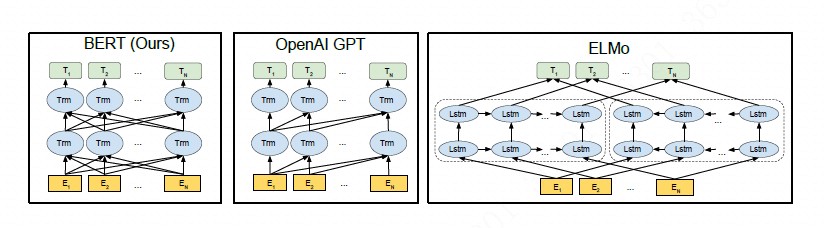
BERT通常只训练一个encoder用于自然语言理解,而GPT的语言模型通常是训练一个decoder。如果要将BERT或者GPT用于序列到序列的自然语言生成任务,通常只有分开预训练encoder和decoder,因此encoder-attention-decoder结构没有被联合训练,attention机制也不会被预训练,而decoder对encoder的attention机制在这类任务中非常重要,因此BERT和GPT在这类任务中只能达到次优效果。
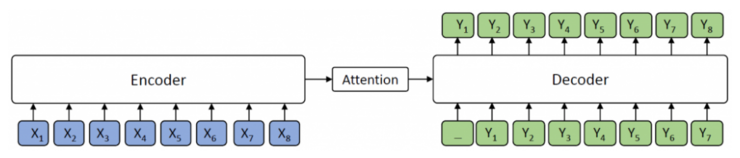
如上图 所示,encoder将源序列 作为输入并将其转换为隐藏表示的序列,然后decoder通过attention机制从encoder中抽象出隐藏表示的序列信息,并自动生成目标序列文本 。
本文针对文本生成任务, 在BERT的基础上,提出了Masked Sequence to Sequence pre-training(MASS),MASS采用encoder-decoder框架以预测一个句子片段,其中encoder端输入的句子被随机masked连续片段,而decoder端需要生成该masked的片段,通过这种方式MASS能够联合训练encoder和decoder,从而提高语言建模能力。在一系列的文本生成任务实验中验证了该结构的有效性。
MASS
**MASS核心思想:**MASS对句子随机屏蔽一个长度为k的连续片段,然后通过encoder-attention-decoder模型预测生成该片段。
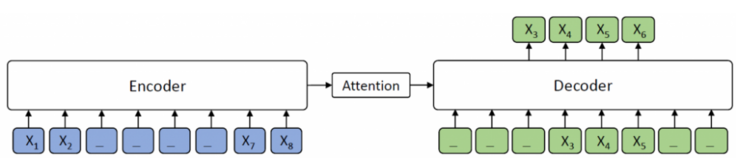
如上图 所示,encoder端的第 3-6 个tokens被masked,而在decoder端,仅有masked的tokens被预测出来,而其他tokens则bemasked。
MASS 预训练具有以下优势:
-
decoder端的其他tokens(在encoder端未被masked的tokens)被masked,从而使得decoder提取更多信息以帮助预测连续句子片段,促进encoder-attention-decoder结构的联合训练;
-
为了给decoder提供更多有用的信息,encoder被强制提取未被masked的tokens的含义,这可以提高encoder理解源序列文本的能力;
-
decoder被设计用以预测连续的tokens(句子片段),这可以提升decoder的语言建模能力。
预训练
MASS 有一个重要的超参数 k(masked的片段的长度)。通过调整 k 值,MASS 可以将 BERT 中掩蔽的语言建模和 GPT 中的标准语言建模结合起来,从而将 MASS 扩展成一个通用的预训练框架。
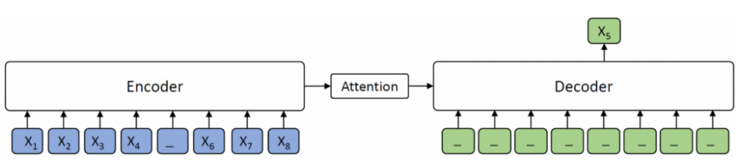
当 时,根据 MASS 的设计,encoder端的一个tokens被masked,而decoder端则会预测出该被masked的token,如下图所示。decoder端没有输入信息,因而 MASS 等同于 BERT 中掩蔽的语言模型。
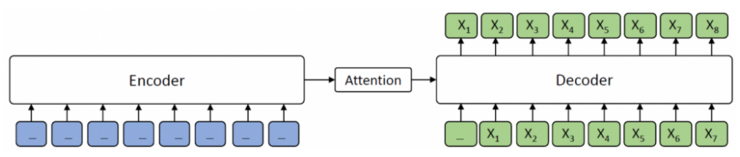
当$ k = mm$ 是序列的长度)时,在 MASS 中,encoder端的所有tokens都被masked,而decoder端会预测所有的tokens,如下图所示。decoder端无法从encoder端提取任何信息,MASS 等同于 GPT 中的标准语言模型。
MASS 在不同 k 下的概率形式如下表所示,其中 m 为序列长度,u 和 v 为被masked序列的开始和结束位置, 表示从位置 u 到 v 的序列片段, 表示该序列从位置 u 到 v 被masked掉。可以看到,当 或者 m 时,MASS 的概率形式分别和 BERT 中的masked语言模型以及 GPT 中的标准语言模型一致。

讨论
与BERT和GPT的不同:
标准的语言模型中最典型的代表是ELMo和GPT,自然语言理解中最具代表性的是BERT。BERT使用一个encoder去提取单个句子或者句子对的表征。标准的语言模型和和BERT都仅仅分别预训练encoder或者decoder。虽然它们可以在自然语言理解任务上取得令人瞩目的成果,但是在自然语言生成任务上显得不合时宜。这是由于自然语言生成一般利用encoder-decoder框架,其生成的语言序列是条件概率。
MASS在自然语言生成任务上联合了预训练的encoder和decoder。首先,通过seq2seq框架仅仅预测被masked的tokens。MASS强制要求encoder理解透彻未被masked的tokens含义,同时激励decoder从encoder这里抽取有意义的信息。其次,通过预测连续的tokens而非离散的tokens,decoder端能够构建更好的语言建模能力。第三,在decoder端对于在encoder端未被masked的input tokens进行masked(即,在decoder的inputs上放弃先验信息)。例如,当想要预测,只有作为decoder端的输入,其他的tokens被masked掉。这促使decoder端从encoder端抽取更多有用信息,而不是使用此前tokens中的丰富信息。
实验及其结果
模型配置:
以Transformer为基本的模型结构,Transformer是由4层encoder+4层decoder+512 embedding/hidden size + 2048 feed-forward filter size。文本摘要和对话生成是单语种任务,NMT涉及多语言,所以除了英语之外,还需要预训练一个多语种模型。本文考虑了English, German, French 和 Romanian,其中英语在所有的下游任务中都会被用到,其他语种只会在NMT任务中用到。此外,为了区分不同的语种,在输入的句子中增加了一个language embedding。
预训练的细节:
对于被masked掉的token用以特定字符取代,其他的处理与BERT的一样(80%的随机替换,10%的随机其他token,10%的未masked)。此外本文还研究了不同的连续长度k对accuracy的影响,这点后面补充结果。为了降低内存占用和计算时长,本文设计去掉decoder端的padding,但是保持unmasked tokens的positional embedding(即,如果前2个token被masked,第3个token的positional embedding仍然是2,而不是0)。这种方式可以在维持accuracy不变的前提下,在decoder端降低大约50%的计算量。本文采用的优化器是Adam,其学习率是,训练的机器设备是4张 NVIDIA P100 GPU,每个mini-batch有32*4 个句子。
无监督NMT的实验结果:
在无监督NMT任务上与此前的模型对比,结果如下:
在无监督翻译任务上,我们和当前最强的 Facebook XLM 作比较(XLM 用 BERT中的masked预训练模型, 以及标准语言模型来分别预训练encoder和decoder)。可以看到,MASS 的预训练方法在 WMT14 英语 - 法语、WMT16 英语 - 德语一共 4 个翻译方向上的表现都优于 XLM。MASS 在英语 - 法语无监督翻译上的效果已经远超早期有监督的encoder - 注意力 - decoder模型,同时极大缩小了和当前最好的有监督模型之间的差距。
这里选用的预训练模型有BERT+LM和去噪自encoder(DAE)。在BERT中采用masked语言模型以预训练encoder,再采用标准的语言模型预训练decoder。在预训练decoder时候,我们并不采用masked的语言模型。这是由于多数的自然语言生成任务都是自回归的,其双向的语言模型适用。第2个baseline是DAE,DAE是预训练encoder和decoder。这2个Baselines预训练后,在无监督的翻译对上进行微调,其策略与之前介绍的MASS相同。
从上图可以看出,DAE的BLEU得分比BERT+LM更高,而MASS在所有的数据上都一枝独秀。DAE采用了一些降噪方法,如随机masked一些tokens或者互换相邻的tokens,其decoder能够很容易通过encoder-decoder attention学习到未masked的tokens含义。另一方面,DAE的decoder端能够充分利用输入的所有句子,这使得下一个token的预测(类似语言模型)变得容易许多。这也就无需强制decoder从encoder端学习到更多有用的表征。
其他实验结果,请查看论文详细说明。
MASS的分析
我们通过实验分析了屏蔽 MASS 模型中不同的片段长度(k)进行预训练的效果,如下图所示。
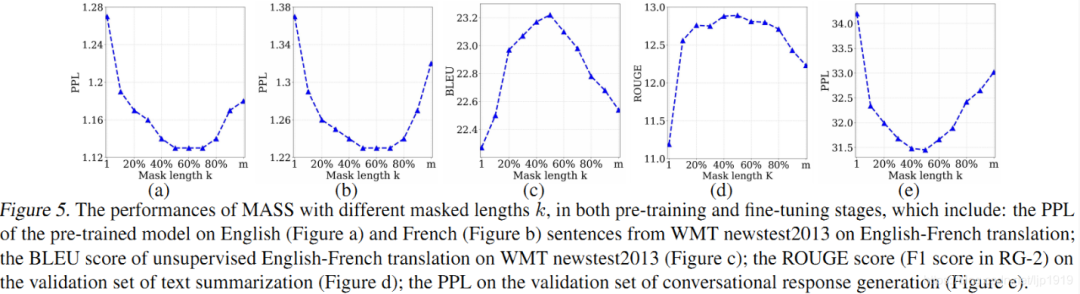
当 k 取大约句子长度一半时(50% m),下游任务能达到最优性能。屏蔽句子中一半的词可以很好地平衡encoder和decoder的预训练,过度偏向encoder(k=1,即 BERT)或者过度偏向decoder(k=m,即 LM/GPT)都不能在该任务中取得最优的效果,由此可以看出 MASS 在序列到序列的自然语言生成任务中的优势。
论文地址: https://arxiv.org/pdf/1905.02450.pdf
代码地址: https://github.com/microsoft/MASS