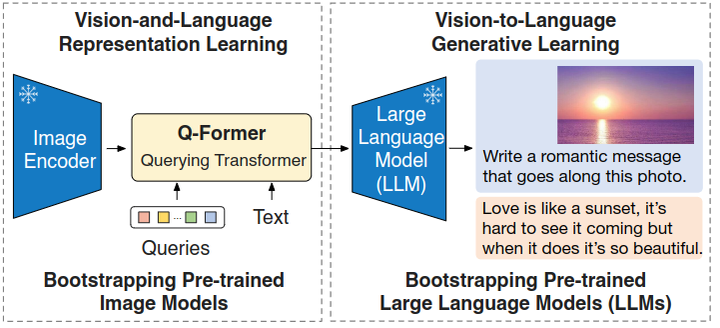
本篇博文我们主要关注半监督学习,在实际应用环境中,获得高质量的标注数据是比较耗时和昂贵的,往往都是小部分标注数据和大量的无标注数据,除了高效利用标注数据,还需要将大量的无标注数据发挥出价值。半监督学习(Semi-supervised learning,SSL)是一种学习方法,其使用少量标注的数据和大量未标注的数据进行学习,从而得到一个高质量模型。本文作者提出一种名为FixMatch的半监督学习算法,通过对每一张没有标注的图片进行弱增强和强增强,首先对弱增强产生的数据通过模型产生伪标签,当模型的预测得分高于一定的阈值时,伪标签作为该样本标签,并与强增强数据模型预测结果进行计算损失。实验结果表明,FixMatch在众多的半监督学习方法中达到了最好的效果。仅用了250张标注数据,在CIFAR-10数据集上达到了94.93%的准确率;仅用了40张标注数据,在CIFAR-10数据集上达到了88.61%的准确率(每个标签仅4张标注数据)。
方法
本文作者提出的FixMatch算法示意图如下所示:
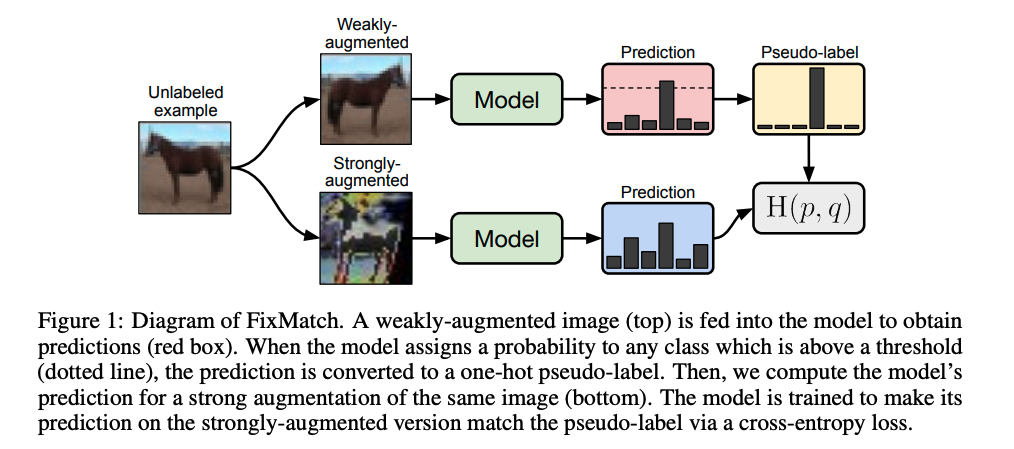
FixMatch训练过程包含两部分:有监督训练和无监督训练。对于有标注数据,进行常规的有监督训练过程即可,这里我们主要重点介绍无监督训练过程,从上图可以看到,对于每张未标注的图像,使用弱增强和强增强获得两张增强图像。首先,弱增强图像通过模型得到预测得分,当模型的预测得分高于一定的阈值时,对应的类别作为 ground truth 的标签,即伪标签。然后,强增强的图像通过相同模型得到预测得分,并使用交叉熵损失将此预测得分与 ground truth 伪标签进行比较。
具体来说,对于一个类的分类任务,给定一个batch大小的标注数据,无标注数据,其中是标注数据与无标注数据之间的比例大小。FixMatch损失包含两部分:有标签的图片用有监督的损失,没有标签的图片用无监督的损失, 两个损失都是标准的交叉熵损失。
首先,看看有监督的损失函数,标准的交叉熵损失函数:
对于没有标签图片,前面提到会使用两种数据增强,弱增强产生伪标签,如果伪标签的得分大于一定的阈值(,论文中的阈值取0.95),那么,就用该伪标签和强增强获得的特征计算交叉熵损失,即:
从上公式可以看到,对伪标签设定一定的阈值,那么训练初始阶段未标注数据一般未参与训练,因为初始阶段模型能力较低,因此其对未标注的数据的输出预测将低于阈值。这样,将仅在标注的数据上训练模型。但是随着训练的进行,模型对标注的数据变得更加准确,因此,对未标注数据的预测也将开始超过阈值。这样,损失将很快也开始包含对未标注图像的预测。
最后,FixMatch的损失函数为:
其中是一个超参数,用来平衡两个损失函数的。
从本文作者使用的弱增强和强增强技术来看,弱增强不至于图像失真,再加上输出伪标签阈值的设置,极大程度上降低了引入错误标签噪声的可能性,而仅仅使用弱增强可能会导致训练过拟合,无法提取到本质的特征,所以使用强增强。强增强带来图片的严重失真,但是依然是保留足够可以辨认类别的特征。有监督和无监督混合训练,逐步提高模型的表达能力。
实验
实验数据
为了验证FixMatch模型的有效性,作者对常用的 SSL 的数据集(例如 CIFAR-10,CIFAR-100,SVHN,STL-10 和 ImageNet)进行了评估。
实验参数
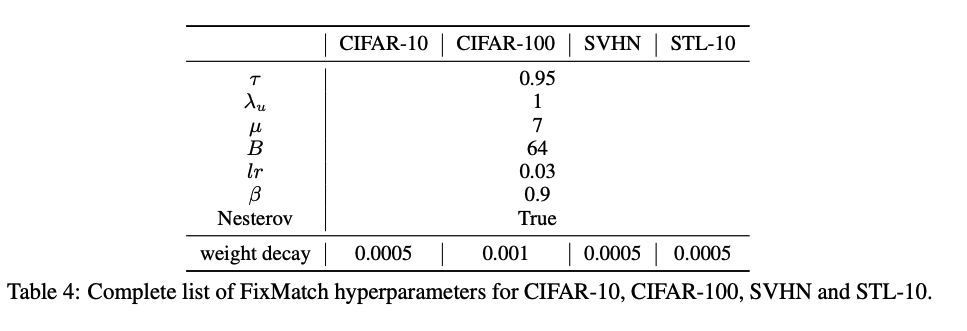
超参数如下所示:
实验结果
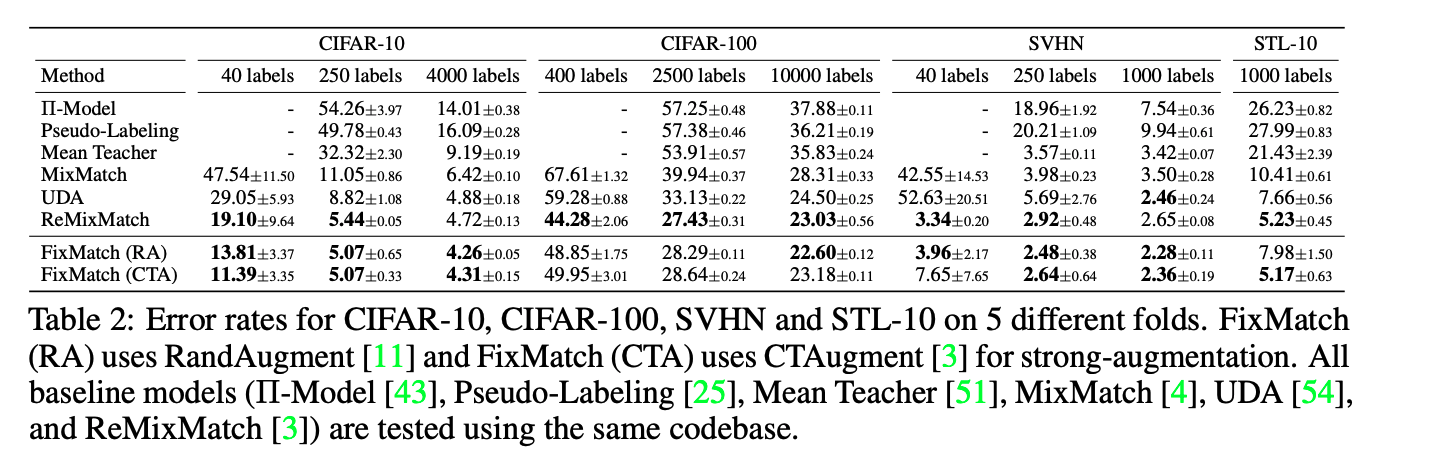
-
FixMatch 在 CIFAR-10 和 SVHN 基准测试中获得了 state of the art 的结果。
-
在 CIFAR-100 上,ReMixMatch 优于 FixMatch。为了理解原因,作者从 ReMixMatch 中借用了各种组件到 FixMatch 上,并测量了它们对性能的影响。他们发现,*Distribution Alignment(DA)*组件促使模型以相同的概率预测所有类,这就是原因。因此,当他们将 FixMatch 与 DA 结合使用时,他们实现了 40.14%的错误率,而 ReMixMatch 的错误率为 44.28%。
-
STL-10 数据集由 100,000 个未标注图像和 5000 个标注图像组成。我们需要预测 10 类(飞机,鸟,汽车,猫,鹿,狗,马,猴子,船,卡车)。它是半监督学习的更具代表性的评估方法,因为其未标注的集合具有分布以外的图像。在所有方法中,对 1000 张带标签的图像进行 5 折评估时,FixMatch 的 CTAugment 可以实现最低的错误率。
作者还评估了 ImageNet 上的模型,以验证其是否适用于大型和复杂的数据集。他们将训练数据的 10%作为标记的图像,其余的 90%作为未标记的图像。同样,所使用的体系结构是 ResNet-50 而不是 WideResNet,并且 RandAugment 被用作增强。他们的 top-1 错误率达到 28.54%±0.52,比 UDA 高 2.68%。top5 的错误率是 10.87%±0.28%。
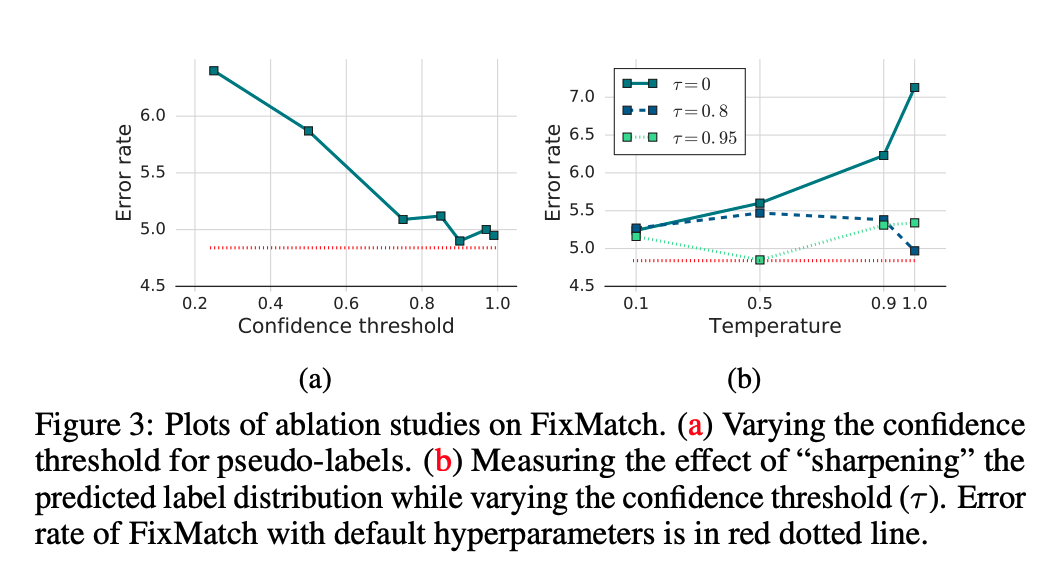
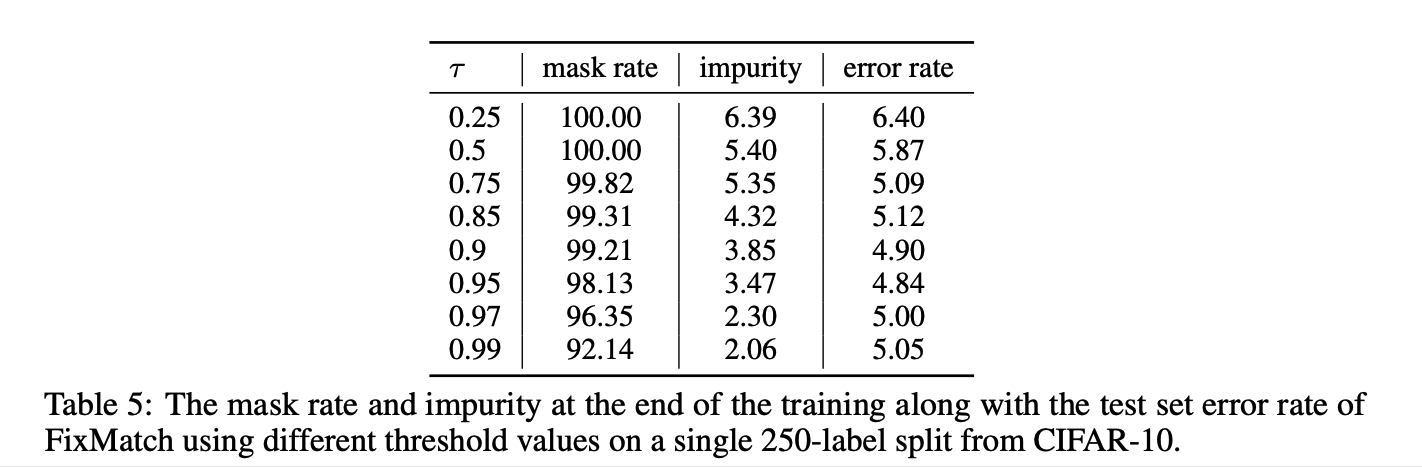
在阈值和Temperature参数实验中,可以看到阈值0.95的错误率最低,但增加到0.97或0.99并没有造成太大伤害。相比之下,当使用一个较小的阈值时,准确率下降了1.5%以上。阈值大小控制着伪标签的质量和数量之间的权衡。未标注数据的伪标签的准确性随着阈值的增加而增加,这说明伪标签的质量比数量对于达到较高的精度更重要。
更详细的消融实验,见原始论文附录。
小结
本文作者提出一种名为FixMatch的半监督学习算法,通过对每一张没有标注的图片进行弱增强和强增强,首先对弱增强产生的数据通过模型产生伪标签,当模型的预测得分高于一定的阈值时,伪标签作为该样本标签,并与强增强数据模型预测结果进行计算损失。实验结果表明,FixMatch在众多的半监督学习方法中达到了最好的效果。仅用了250张标注数据,在CIFAR-10数据集上达到了94.93%的准确率;仅用了40张标注数据,在CIFAR-10数据集上达到了88.61%的准确率(每个标签仅4张标注数据)。