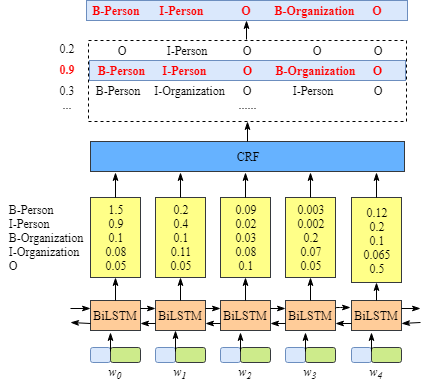
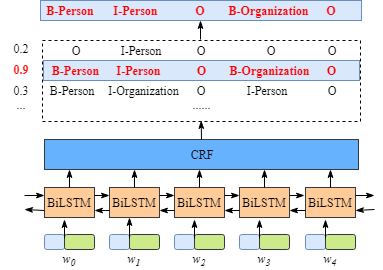
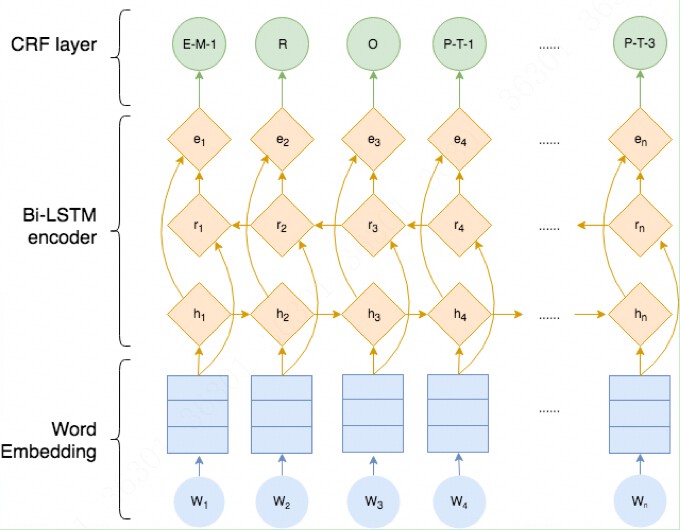
现有NLP的数据增强大致有两条思路:一个是加噪,另一个是回译,均为有监督方法。加噪即为在原数据的基础上通过替换词、删除词等方式创造和原数据相类似的新数据。回译则是将原有数据翻译为其他语言再翻译回原语言,由于语言逻辑顺序等的不同,回译的方法也往往能够得到和原数据差别较大的新数据。本文借鉴sentence-level的传统数据增强方法,探究了不同的数据增强方法对NER任务的影响,发现:在低资源条件下,数据增强效果增益比较明显,而在充分数据条件下,数据增强可能会带来噪声,导致指标下降。
方法
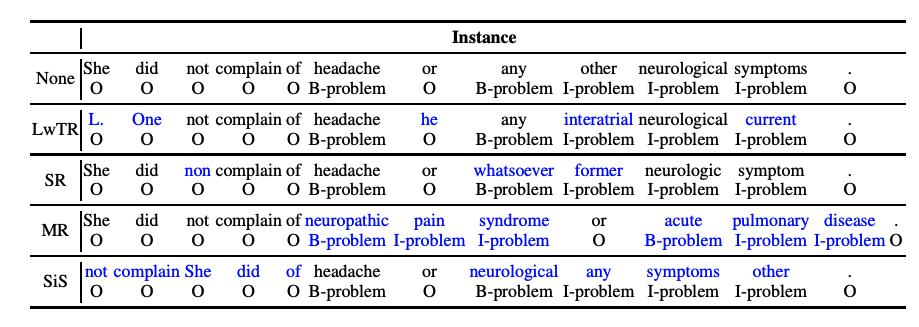
在本文中,作者借鉴了sentence-level的传统数据增强方法,将传统的文本增强方法应用于NER任务中,并进行全面分析与对比。主要有以下4种数据增强方法(如下图所示):
Label-wise token replacement (LwTR):即相同标签的token替换,通过一个二项分布来决定token是否被替换;如果被替换,则从训练集中选择相同的token进行替换。
Synonym replacement (SR):即同义词替换,利用WordNet查询同义词,然后根据二项分布随机替换。如果替换的同义词大于1个token,那就依次延展BIO标签。
Mention replacement (MR):即实体替换,与同义词方法类似,利用训练集中的相同实体类型进行替换,如果替换的mention大于1个token,那就依次延展BIO标签,如下图:「headache」替换为「neuropathic pain syndrome」,依次延展BIO标签。
Shuffle within segments (SiS):按照mention来切分句子,然后再对每个切分后的片段进行shuffle。如下图,共分为5个片段: [She did not complain of], [headache], [or], [any other neurological symptoms], [.]. 。也是通过二项分布判断是否被shuffle(mention片段不会被shuffle),如果shuffle,则打乱片段中的token顺序。
实验
为了探究数据增强对NER任务的影响,本文在2个NER数据集上实验: MaSciP、i2b2-2010。
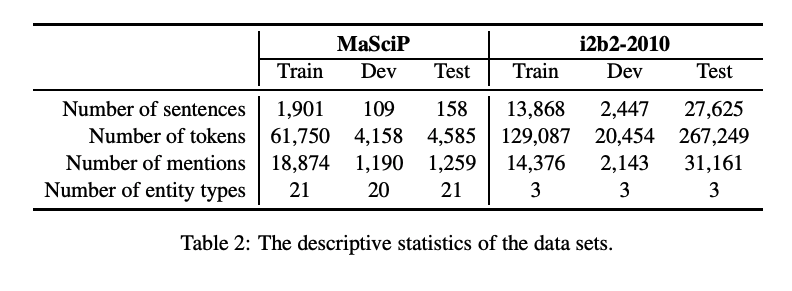
为了模拟低资源条件下,本文设置了以下四种不同资源条件:
Small(S):包含50个训练样本;
Medium (M):包含150个训练样本;
Large (L):包含500个训练样本;
Full (F):包含全量训练集
实验结果
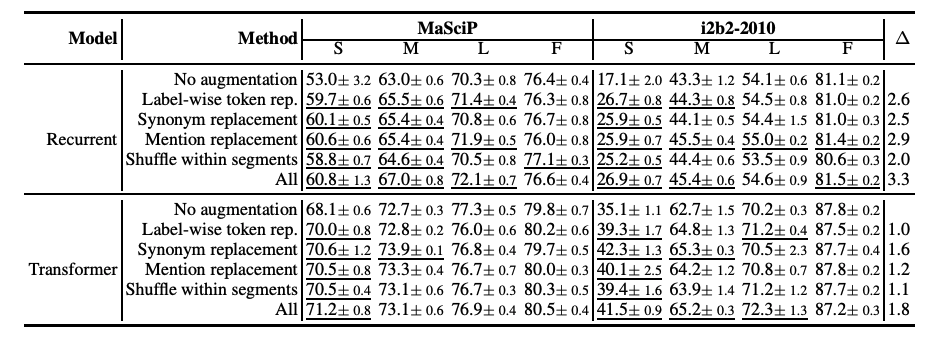
由上图可以看出:
4种传统的数据增强方法都超过不使用任何增强的baseline效果。
对于RNN网络,实体提及替换优于其他方法;对于Transformer网络,同义词替换最优。
总体上看,所有增强方法一起使用(ALL)会由于单独的增强方法。
低资源条件下,数据增强效果增益更加明显;
充分数据条件下,数据增强可能会带来噪声,甚至导致指标下降
小结
本文借鉴sentence-level的传统数据增强方法,探究了不同的数据增强方法对NER任务的影响,实验表明,数据增强在NER任务中起到正向作用,并且在低资源条件下,数据增强效果增益比较明显,而在充分数据条件下,数据增强可能会带来噪声,导致指标下降。
参考: 知乎