交叉验证是一种用来衡量和评估机器学习模型性能的技术,在模型训练过程,我们创建了训练集的多个分区,并在这些分区的不同子集上进行训练/测试。
本文我们主要介绍不同的交叉验证方法。
交叉验证经常用于给定的数据集训练、评估和最终选择机器学习模型,因为它有助于评估模型的结果在实践中如何推广到独立的数据集,最重要的是,交叉验证已经被证明产生比其他方法更低的偏差的模型。
模型无法保持稳定?
让我们通过以下几幅图来理解这个问题:
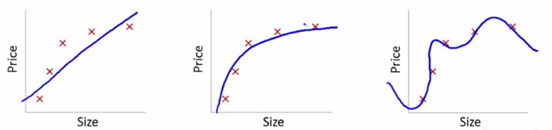
此处,我们试图找到size和price的关系,三个模型各自做了如下工作:
- 1.第一个模型使用了线性等式。对于训练数据集,该模型存在很大的误差。这样的模型效果往往不太好,这是
欠拟合的一个例子。此模型不足以发掘数据背后的趋势。 - 2.第二个模型发现了price和size的正确关系,此模型误差低,拟合关系较强。
- 3.第三个模型对于训练数据集而言几乎是零误差。这是因为此模型把每一个数据点的偏差(包括噪声)都纳入了考虑的范围,也就是说,这个模型太过敏感了,甚至会捕抓到在当前训练数据集出现的一些随机模式。这是“过拟合”的一个例子,这个模型往往会造成在训练效果很好而在测试效果很差。
在kaggle比赛中,一个常见的做法是对多个模型进行迭代,从中选择表现良好的。然而,最终的分数是否会有改善仍然未知,因为我们不知道这个模型是更好的发掘了数据之间的关系好事过拟合了。为了解答这个难题,我们应该使用交叉验证(cross-validation)技术,它能够帮助我们发现更加具有通用性的模型。
什么是交叉验证
交叉验证意味着需要保留一个样本数据集,不用来训练模型。在最终完成模型前,用这个数据集验证模型。
交叉验证包含以下步骤:
- 1.保留一个样本数据集
- 2.用剩余部分训练模型
- 3.用保留的数据集验证模型,这样有助于了解模型的有效性
交叉验证常用方法
交叉验证有很多方法,下面介绍其中几种:
“验证集” 方法
保留50%的数据用于验证,剩下50%训练模型。之后用验证集测试模型,不过这个方法的主要缺陷在于,由于只是使用了50%的数据进行训练模型,原数据中的一些重要的信息可能被忽略,也就是说会有较大的偏差。
比如:
1 | from sklearn.model_selection import train_test_spit |
留一法交叉验证(LOOCV)
这个方法只保留一个数据作为验证,用剩余的数据集训练模型,然后对每个数据点重复这个过程。这个方法有利有弊:
- 由于使用了所有的数据点,所以偏差较低
- 验证过程重复了n次(n为数据点个数),导致执行时间很长
- 由于用一个数据点作为验证集,这个方法导致模型的有效性的差异更大,得到的估计结果深受此点的影响,如果这个点是一个离群点,会引起很大的偏差。
比如:
1 | from sklearn.model_selection import LeaveOneOut |
注:当然你可以设置为多个,即不在使用一个而是使用p个,这种叫做LPOCV
k-折交叉验证
从以上两个方法中,我们可以学到:
- 1.应该使用较大比例的数据集来训练模型,否则会导致失败,最终得到偏差较大的模型
- 2.验证数据集的比例应该恰到好处,如果太少,会导致验证模型的有效性时,得到的结果波动较大
- 3.训练和验证过程应该重复多次,训练集合验证集不能一成不变,这样有助于验证模型的有效性
是否有一种方法可以兼顾到这三个方面呢?
答案是肯定的,这个方法就是‘k-折交叉验证’,该方法简单易行。简要步骤如下:
- 1.把整个数据集随机划分成k份
- 2.用其中k-1份训练模型,然后用第k份验证模型
- 3.记录每个预测结果获得的误差
- 4.重复这个过程,知道每份数据都做过验证集
- 5.记录下的k个误差的平均值,被称为交叉验证误差。可以被用做衡量模型性能的标准
当k=10,k-折交叉验证示意图吐下:

这个会遇到一个问题,“如何确定一个合适的K值?“
记住,当K值越小,偏差越大,另一方面,k值越大,虽然偏差变小了,但是结果波动越大,越不稳定。小的k值,则会变得像“验证集方法”,大的k值,则会变得像“留一法”。所以一般建议的k值在5-10之间。
比如:
1 | from sklearn.model_selection import KFold |
分层k-折交叉验证(stratified k-fold cross validation)
分层采样就是在每一份子集中都保持原始数据集的类别比例,保证采样数据跟原始数据的类别分布保持一致,如下所示:
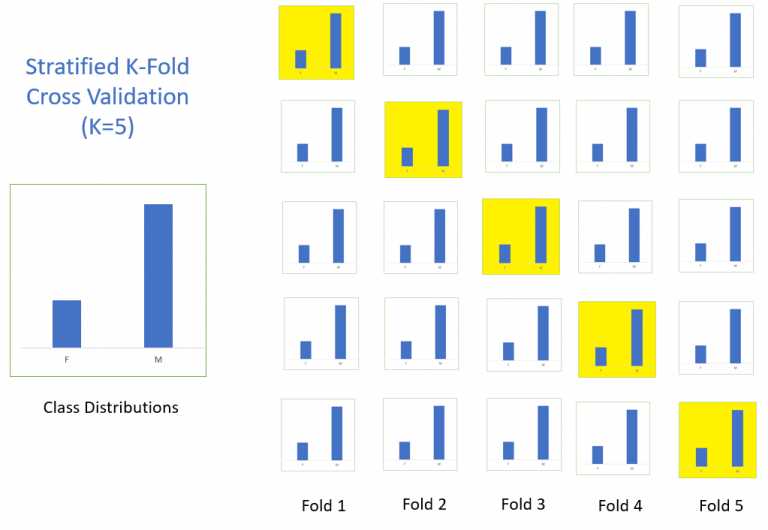
该方法在有效的平衡方差和偏差。当针对不平衡数据时,使用随机的K-fold交叉验证,可能出现在子集中叫少的类别的分布与原始类别分布不一致。因此,针对不平衡数据往往使用stratified k-fold交叉验证。
如下:
1 | from sklearn.model_selection import StratifiedKFold |
当训练数据集不能代表整个数据集分布是,这时候使用stratified k折交叉验证可能不是好的方法,而可能比较适合使用简单的重复随机k折交叉验证。
重复的k折交叉验证,主要是会重复进行n次的k折交叉验证,这样会产生n次结果,一般通过平均方法或者(投票规则)得到最后的结果
Python代码如下:
1 | from sklearn.model_selection import RepeatedKFold |
Adversarial validation
在处理真实数据集时,经常会遇到测试集和训练集分布非常不同的情况。因此,训练集上的交叉验证结果可能与测试集上的结果相差甚远。在这种情况下,Adversarial validation提供了一个有趣的解决方案。
整体思路是根据特征分布来检查训练数据集和测试数据集之间的相似性程度。如果模型(对训练数据和测试数据进行训练)效果很好,我们可以怀疑它们是完全不同的。这种直觉可以通过组合训练和测试集,并标记0和1标签(0-train,1-test),然后通过一个二分类任务来进行评估。
主要的计算步骤如下:
- 首先移除原始的训练集标签数据
1 | train.drop(['target'],axis = 1,inplace=True) |
- 创建新的target变量,train数据target为1,test数据target为0
1 | train['is_train'] = 1 |
- 合并train和test数据集
1 | df = pd.concat([train,test],axis = 0) |
- 针对新的标签数据,拟合一个二分类模型
1 | y = df['is_train'] |
- 对train进行预测,并按概率进行排序,并选择top n%个样本作为验证集(n%是针对train数据集)
1 | probs = clf.predict_proba(x1)[:,1] |
val_set_ids将从训练数据集中获取与test数据集最相似的部分数据对应的id,但是,在使用这种验证技术时必须小心。一旦测试集的分布发生变化,验证集可能不再是评估模型的好子集。
时间序列的交叉验证
时间序列数据时一种特殊数据类型,随机地分割一个时间序列数据集是不合理的,因为这样会打乱数据集的时间顺序属性、。对于时间序列预测问题,我们采用以下方式进行交叉验证。
- 1.每一部分按照时间链方式构建
- 2.假设我们有一个时间序列,表示某产品在n年内的年需求量。则交叉验证数据集构建方式如下:
1 | fold 1: training [1], test [2] |
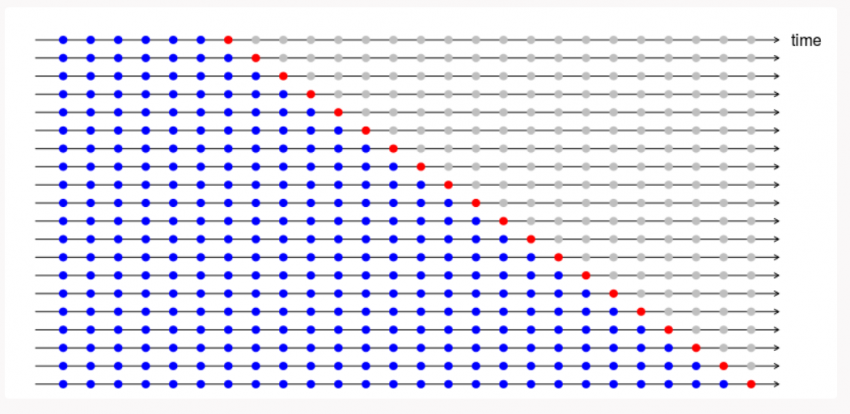
我们逐步地选择一个新的train数据集和test数据集。
python代码如下:
1 | from sklearn.model_selection import TimeSeriesSplit |
更加详细的时间序列交叉验证可以参考该文章:地址
如何衡量模型的偏差-方差?
K-折交叉验证之后,我们得到K个不同的模型误差估计值(e1,e2,…,ek),理想的情况是,这些误差值相加为0,若要计算模型的偏差,我们对这些误差值计算平均值,平均值越低,模型越好。
模型的波动程度的计算与之类似,我们对这些误差值计算标准差,标准差越小说明模型的稳定越好。
我们应该试图在偏差和方差之间找到一种平衡。降低方差、控制偏差可以达到这个目的,这样会得到一个更好的模型。