本文主要内容如下:
- 介绍: 在命名实体识别任务中,BiLSTM模型中CRF层的通用思想
- 实例: 通过实例来一步步展示CRF的工作原理
- 实现: CRF层的一步步实现过程
备注: 需要有的基础知识:你只需要知道什么是命名实体识别,如果你不懂神经网络,条件随机场(CRF)或者其它相关知识,不必担心,本文将向你展示CRF层是如何工作的。本文将尽可能的讲的通俗易懂。
1.介绍
基于神经网络的方法,在命名实体识别任务中非常流行和普遍。在文献[1]中,作者提出了BiLSTM-CRF模型用于实体识别任务中,在模型中用到了字嵌入和词嵌入。本文将向你展示CRF层是如何工作的。
如果你不知道BiLSTM和CRF是什么,你只需要记住他们分别是命名实体识别模型中的两个层。
1.1开始之前
我们假设我们的数据集中有两类实体——人名和地名,与之相对应在我们的训练数据集中,有五类标签:
- B-Person
- I-Person
- B-Organization
- I-Organization
- O
假设句子由5个字符组成,即,其中为人名实体,为组织实体,其他字符的标签为"O"。
1.2 BiLSTM-CRF 模型
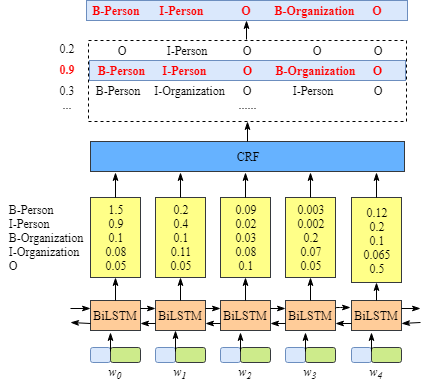
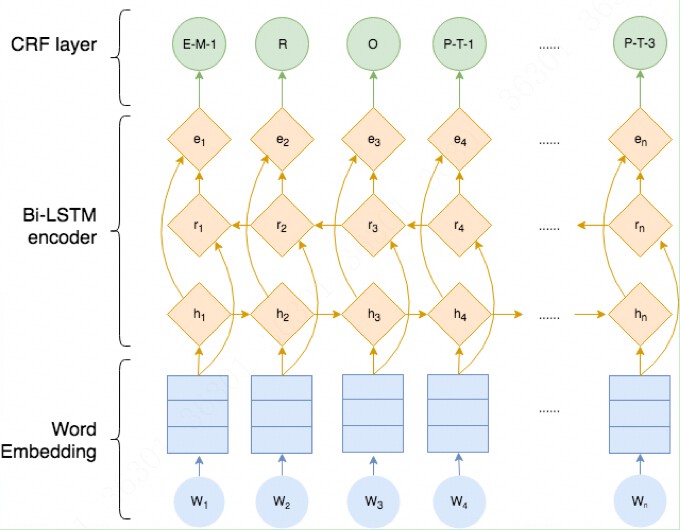
首先,对该模型进行简单的介绍,具体的模型结构,如下图所示:
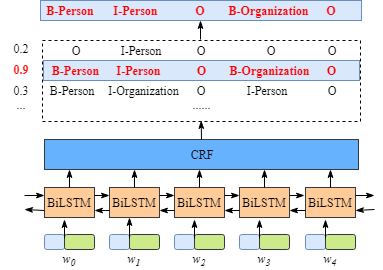
-
句子中的每一个单元都代表着由字嵌入或词嵌入构成的向量。其中,字嵌入一般是随机初始化的,而词嵌入一般是通过一个预训练好的词向量模型得到的。所有的嵌入在训练过程中都会调整到最优。
-
这些字或词嵌入作为BiLSTM-CRF模型的输入,输出的是句子中每个单元的标签。
为了更容易了解CRF层的运行原理,我们需要知道BiLSTM的输出层。
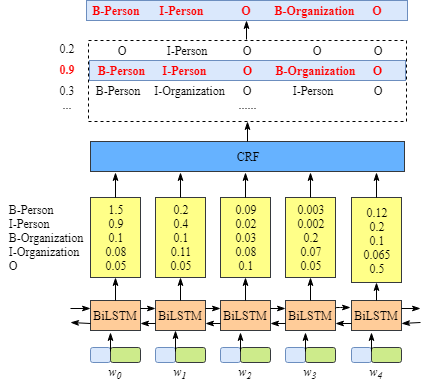
1.3 如果没有CRF层会怎样
你也许已经发现了,即使没有CRF层,我们也可以训练一个BiLSTM命名实体识别模型,如图下图所示:
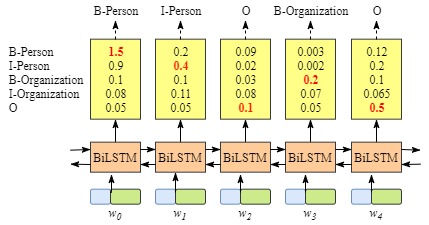
虽然我们可以得到句子中每个单元的正确标签,但是我们不能保证标签每次都是预测正确的。例如,如下图所示:
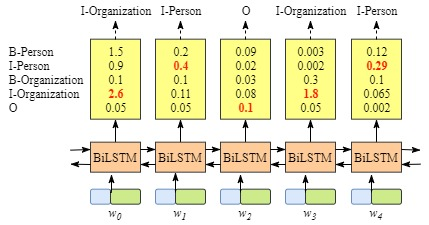
1.4 CRF层能从训练数据中学到约束规则
CRF层可以为最后预测的标签添加一些约束来保证预测的标签是合理的。在训练过程中,这些约束可以通过CRF层自动学习到。
这些约束可以是:
- 句子中第一个词总是以标签“B-“ 或 “O”开始,而不是“I-”
- 标签“B-label1 I-label2 I-label3 I-…”,label1, label2, label3应该属于同一类实体。例如,“B-Person I-Person” 是合理的序列, 但是“B-Person I-Organization” 是不合理标签序列.
- 标签序列“O I-label” 是不合理的,实体标签的首个标签应该是 “B-“ ,而非 “I-“, 换句话说,有效的标签序列应该是“O B-label”。有了这些约束,标签序列预测中不合理序列出现的概率将会大大降低。
下一节,将通过CRF层的损失函数,解释CRF层如何从训练数据集中学习到这些约束。
参考文献
[1] Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K. and Dyer, C., 2016. Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360.
https://arxiv.org/abs/1603.01360