Colossal-LLaMA-2:千元预算半天训练,效果媲美主流大模型,开源可商用中文LLaMA-2
千元预算半天训练,效果媲美主流大模型,开源可商用中文LLaMA-2 [代码] [博客] [模型权重]
LLaMA-2相较于LLaMA-1,引入了更多且高质量的语料,实现了显著的性能提升,全面允许商用,进一步激发了开源社区的繁荣,拓展了大型模型的应用想象空间。
然而,从头预训练大模型的成本相当高,被戏称「5000万美元才能入局」,这使得许多企业和开发者望而却步。那么,如何以更低的成本构建自己的大型模型呢?
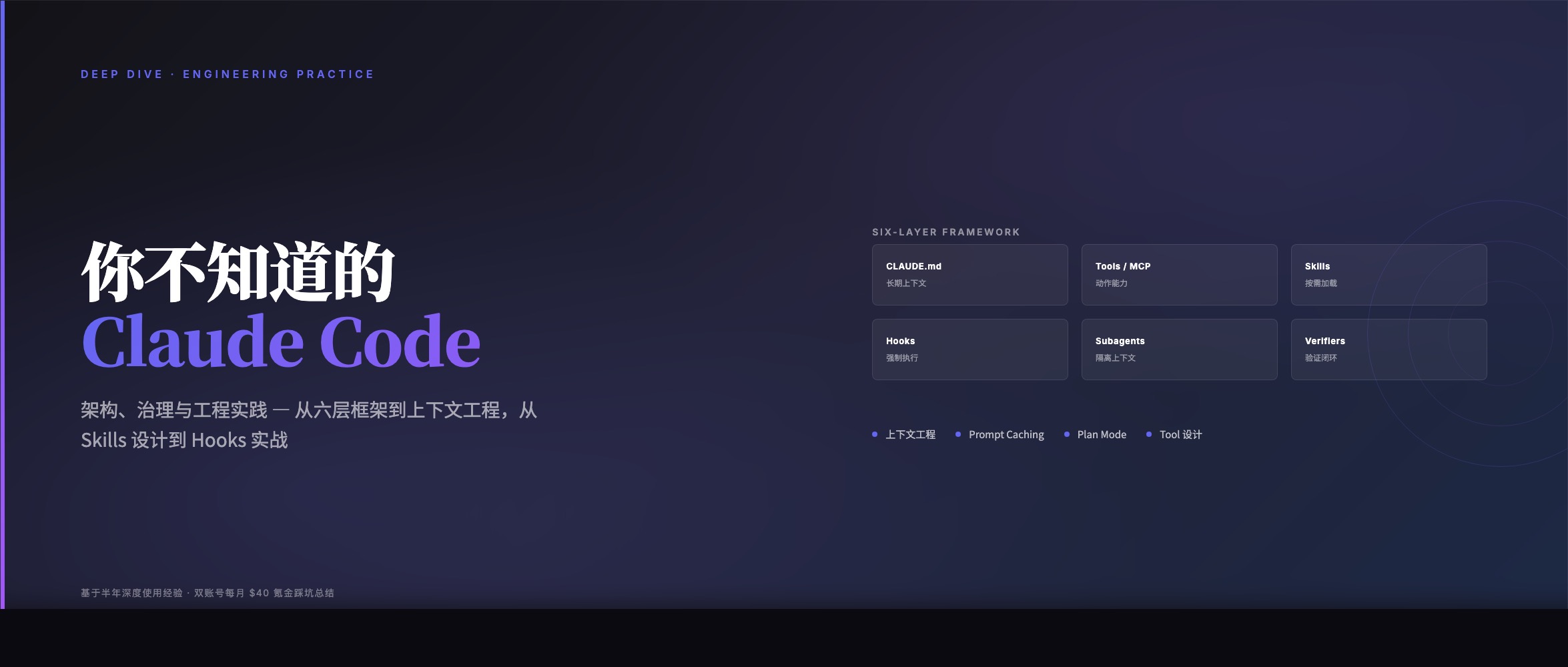
作为大模型降本增效的领导者,Colossal-AI团队充分利用LLaMA-2的基础能力,采用高效的训练方法,仅使用约8.5B token数据、15小时、数千元的训练成本,成功构建了性能卓越的中文LLaMA-2,在多个评测榜单性能优越。
相较于原始LLaMA-2,在成功提升中文能力的基础上,进一步提升其英文能力,性能可与开源社区同规模预训练SOTA模型媲美。
秉承Colossal-AI团队一贯的开源原则,完全开源全套训练流程、代码及权重,无商用限制,并提供了一个完整的评估体系框架ColossalEval,以实现低成本的可复现性。
此外,相关方案还可迁移应用到任意垂类领域和从头预训 ...

Lost in the Middle:How Language Models Use Long Contexts
大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。近日,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。即,大模型对输入中不同位置的文本信息利用能力是不同的,对召回的若干条文档片段进行合理的位置安排,能有效提高模型的回答效果。 本文将简单介绍一下这个现象。
假设我们检索出来的相关文档为doc1,doc2,doc3,如下所示
存在一个问题是:这里doc1、doc2、doc3应该怎么排序合适?
作者做了一系列的实验,这里直接给出结论:把关键信息位于输入上下文的开始或结尾时,模型表现最佳。而关键信息位于长上下文的中部,性能可能会大幅下滑。
那么如果在做RAG检索的时候,可以将相似度高的放到前后,而相似度低的放在中间。我们在实际项目中实验也有类似的结论。
实验场景
在论文中,作者以以下两种场景进行实验:
(1)wiki问答场景:大模型输入中包含一个 ...
提升LLM的两种方式对比:RAG vs Finetuning
随着人们对大型语言模型 (LLM) 的兴趣激增,许多开发人员和组织正忙于利用其能力构建应用程序。然而,当开箱即用的预训练LLM没有按预期或希望执行时,如何提高LLM应用的性能的问题。最终我们会问自己:我们应该使用检索增强生成(RAG)还是模型微调来改善结果?
在深入研究之前,让我们揭开这两种方法的神秘面纱:
RAG:这种方法将检索(或搜索)的能力集成到LLM文本生成中。它结合了一个检索系统和一个法学硕士,前者从大型语料库中获取相关文档片段,后者使用这些片段中的信息生成答案。本质上,RAG 帮助模型“查找”外部信息以改进其响应。
微调:这是采用预先训练的 LLM 并在较小的特定数据集上对其进行进一步训练的过程,以使其适应特定任务或提高其性能。通过微调,我们根据数据调整模型的权重,使其更适合我们应用程序的独特需求。
RAG 和微调都是增强基于 LLM 的应用程序性能的强大工具,但它们涉及优化过程的不同方面,这在选择其中之一时至关重要。
以前,我经常建议组织在进行微调之前尝试使用 RAG。这是基于我的看法,即两种方法都取得了相似的结果,但在复杂性、成本和质量方面有所不同。我甚至用这样的图 ...
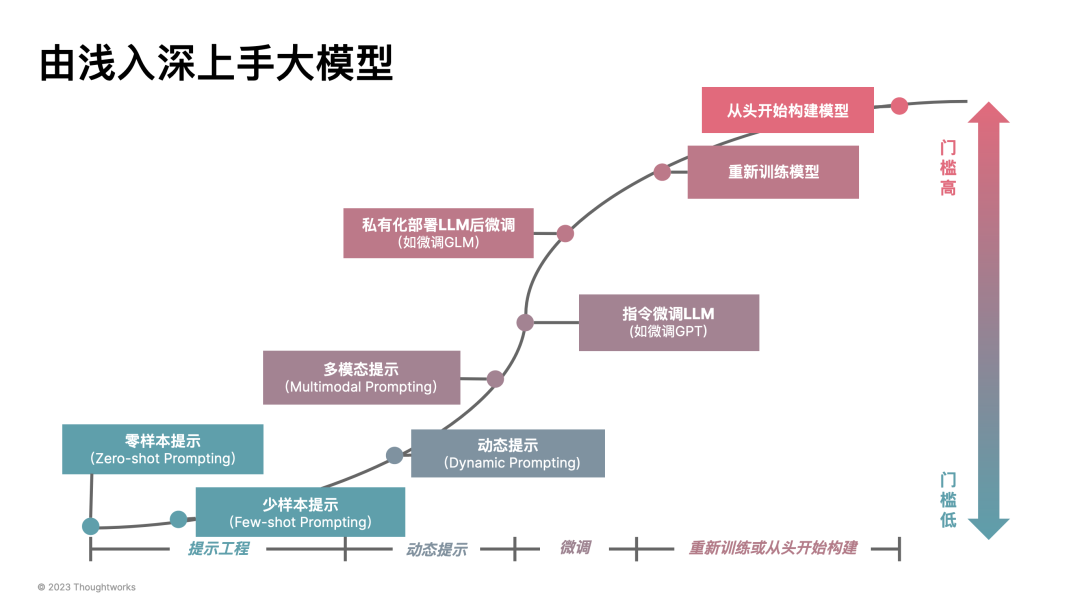
如何工程化落地LLM:五类模式加速 AI 应用开发
几个月前,在 Thoughtworks 的内部 AIGC 研讨会里,我们一直达成了一系列一致观点,诸如于:如果没有 “开源模型” 降低企业应用 LLM 的成本,那么 LLM 会很快消亡。所以,我们相信开源 LLM + LoRA 微调会成为企业的一种主流方式。现今,我们可以看到 LLaMA 2、Code LLaMA 2 等模型在不断刷新这种可能性。
而在模型不是问题之后,作为架构师、开发人员,我们应该致力于:将 LLM 以工程化的方式落地。于是,在过去的几个月里,我们开发了一系列不同领域的 LLM 应用 PoC(Proof of Concept),尝试从不同的角度思考如何构建好 LLM 应用。诸如于:
语言与生态的角度,探索优化语言间的交互?
技术架构应该如何设计?
Prompt 建模与优化?
有哪些模式构建更好的模型上下文?
语言 API 应该包含那些内容?
其它的一些问题,还包含如何通过小模型、传统 LLM 降低大模型花费?每个问题都是一个比较有意思的问题,也是我们在落地时要考虑的。
语言与生态的角度:LLM Service as a API vs FFI
已经有大量的企业尝试 ...

Chat Markup Language
在笔者应用大模型的场景中,对话模型(即大模型-chat系列)通常具有比较重要的地位,我们通常基于与大模型进行对话来获取我们希望理解的知识。然而大模型对话是依据何种数据格式来进行训练的,他们的数据为什么这么来进行组织,本篇文章将进行总结。
Chat Markup Language
Chat Markup Language (CML) 是一种用于描述对话结构的标记语言。它可以帮助大模型和 AI 助手之间的对话更加结构化和清晰。CML 可以描述对话中的各种元素,例如对话的开始和结束、用户和 AI 助手的发言、对话中的问题和回答等等。使用 CML 可以使得对话的处理更加方便和高效,同时也可以提高对话的可读性和可维护性。
DeepMind的相关研究指出,相关研究指出,LLM可以通过选取合适的prompt)来转化为对话代理。这些文本提示通常包含一种所谓的“系统”信息来定义 LLM 的角色,一种更好的结构化方法是ChatML,它对每个对话轮次进行包装,并使用预定义的特殊Token来表示询问或回答的角色。这种方法可以更好地区分对话中不同角色的发言,并且可以更准确地捕捉对话的语境和上下文。相比于简单的插 ...

Claude 教你写 AI 提示词,可能是最专业的 AI 工程师写的提示工程教程
Claude被训练成一名乐于助人、诚实且无害的助手。它习惯于对话,你可以用普通英语指导它。
你给 Claude 的指令的质量会对它的输出质量产生很大的影响,特别是对于复杂的任务。本提示设计指南将帮助你学习如何制作能够产生准确且一致结果的提示。
Claude通过序列预测工作
Claude 是一个基于大型语言模型的会话助理。该模型使用你发送给它的所有文本(您的提示)以及迄今为止生成的所有文本来预测下一个最有帮助的标记。
这意味着 Claude 一次按顺序构造一组字符的响应。它在写入后无法返回并编辑其响应,除非你在后续提示中给它机会这样做。
Claude 也只能看到(并做出预测)其上下文窗口中的内容。它无法记住以前的对话,除非你它们放入提示中,并且它无法打开链接。
什么是提示(Prompt)?
给 Claude 的文本旨在引出或“提示”相关输出。提示通常采用问题或说明的形式。例如:
1Why is the sky blue?(为什么天空是蓝色的)
Claude 响应的文本称为“输出”。
123由于空气中的分子散射太阳光,天空对我们来说呈蓝色。较短波长的光(蓝色)比较长波长的光(如红色和黄色) ...


基于大语言模型的AI Agents—Part 1
代理(Agent)指能自主感知环境并采取行动实现目标的智能体。基于大语言模型(LLM)的 AI Agent 利用 LLM 进行记忆检索、决策推理和行动顺序选择等,把Agent的智能程度提升到了新的高度。LLM驱动的Agent具体是怎么做的呢?接下来的系列分享会介绍 AI Agent 当前最新的技术进展。
什么是AI Agent?
代理(Agent)这个词来源于拉丁语“agere”,意为“行动”。现在可以表示在各个领域能够独立思考和行动的人或事物的概念。它强调自主性和主动性 (参考链接)。智能代理/智能体是以智能方式行事的代理;Agent感知环境,自主采取行动以实现目标,并可以通过学习或获取知识来提高其性能 (参考链接)。
可以把单个Agent看成是某个方面的专家。
一个精简的Agent决策流程:
Agent:P(感知)→ P(规划)→ A(行动)
其中:
**感知(Perception)**是指Agent从环境中收集信息并从中提取相关知识的能力。
**规划(Planning)**是指Agent为了某一目标而作出的决策过程。
**行动(Action)**是指基于环境和规划 ...

LLM推理加速
本研究的重点是优化延迟的各种方法。具体来说,我想知道哪些工具在优化开源 LLM 的延迟方面最为有效。
🏁mlc 是最快的。这个速度太快了,以至于我都有些怀疑,并且现在我有动力去评估质量(如果我有时间的话)。在手动检查输出结果时,它们似乎与其他方法没有什么不同。
❤️ CTranslate2 是我最喜欢的工具,它是最快的工具之一,也是最容易使用的工具。在我尝试过的所有解决方案中,它的文档是最好的。与 vLLM 不同,CTranslate 似乎还不支持分布式推理。
🛠️ vLLM 确实很快,但 CTranslate 可能更快。另一方面,vLLM 支持分布式推理,而这正是大型模型所需要的。
Text Generation Inference如果想以标准方式部署 HuggingFace LLM,文本生成推理是一个不错的选择(但速度远不及 vLLM)。TGI 有一些不错的功能,如内置遥测(通过 [OpenTelemetry](via OpenTelemetry))以及与 HF 生态系统(如inference endpoints)的集成。值得注意的是,从 2023 年 7 月 ...

GPT最佳实践 - 提升Prompt效果的六个策略
本指南分享了提高GPT的效果的策略和方法。这里描述的方法有时可以结合使用以获得更好的效果。同时鼓励多尝试试验,找到最适合自己的方法。
[TOC]
以下是提高Prompt效果的六个策略:
1. 编写清晰的提示
如果GPT输出的内容过长,可以要求进行简短的回复;如果输出过于简单,可以要求使用专业的写作水准输出内容。如果你不喜欢输出的格式,可以提供自己想要的格式。越是明确表达自己的需求,越有可能得到满意的答案。
具体方法:
在查询中提供更多细节可以获得更相关的答案
可以要求模型采用特定的人设
使用分隔符清楚地指示输入的不同部分
指定完成任务所需的步骤
提供例子
指定所需的输出长度
1.1 在查询中包含详细信息以获得更相关的答案
为了获得高度相关的响应,请确保请求中提供了所有重要的详细信息或上下文。否则,模型将会猜测你的意思,结果的相关度也会降低。
在下面的表格中,右边是推荐的写法,效果会比左边的更好,因为提供了更多具体的细节信息。
更差的
更好的
如何在 Excel 中添加数字?
如何在 Excel 中添加一行美元金额?我想对整张行自动执行此操作,所有总计都在右侧名为“总计 ...