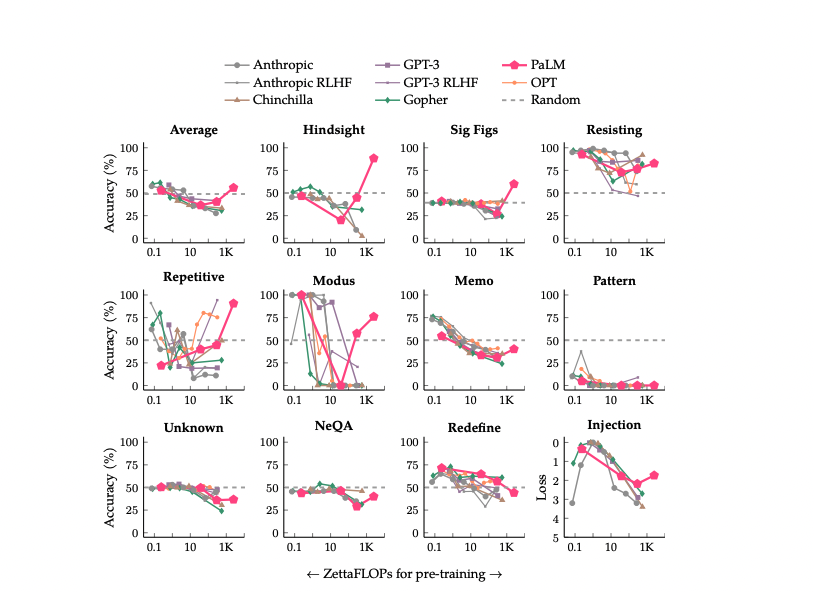
Inverse scaling can become U-shaped
扩大语言模型的规模已被证明可以提高性能并释放出新的能力。或许,也存在某些任务的结果会因模型规模的增加反而变得糟糕。这类任务被称为 Inverse Scaling,它们可以指示出训练数据或优化目标是否存在某种缺陷。
本文着眼于这些Inverse Scaling任务。作者评估了多达540B参数的模型,其训练计算量是Inverse Scaling Prize中评估的五倍。通过增加模型大小和训练计算量的范围,只有11个任务中的4个仍然是反比例缩放。其中11项任务中有6项表现出我们所谓的“U形缩放”—性能先是随着模型规模增大降到一定程度,然后随着模型的增大性能再次上升(剩余一项任务显示正向缩放)。
论文地址: https://arxiv.org/pdf/2211.02011.pdf
方法
在论文中,作者对这11个任务的缩放表现进行了详细研究。结果如下:
所有11项任务的PaLM结果如上图所示,可以看到在PaLM 540B模型后,11项任务中的只有4项保持反比例缩放。其中6个任务从反比例缩放变为U形曲线,而一个任务(Repetitive Algebra)则显示出与PaLM正相关的趋势。这种广泛 ...

ChatGPT 标注指南来了!数据是关键
ChatGPT 刚刚出来时,业内人士一致认为高质量的数据是一个非常关键的因素。 且不论这个结论在 ChatGPT 这里是否正确,但高质量的数据对模型大有裨益却是公认的。而且,我们也可以从公开的 InstructGPT 标注指南中对此窥探一二。
本文主要就围绕这份指南进行介绍,主要包括以下几个方面内容:
我们首先会简单介绍 ChatGPT 训练过程中的几个涉及到标注的任务,清楚了任务才能更好地了解标注。然后从宏观角度统领几个方面的设计,包括 数据、人员、规范 等。
标注数据: 包括数据收集、数据分析、数据预处理等。
标注人员: 包括人员筛选、人员特征、满意度调查等。
标注规范: 包括关键指标、标注方法细则、标注示例、FAQ 等。
多想一点: 主要是个人的一些补充和思考。
总体介绍
根据 ChatGPT 博客(相关文献【1】)的介绍,主要是前两个步骤需要标注数据:第一步的有监督微调 SFT(supervised fine-tuning)和 第二步的 RM(Reward Model)。
第一步需要对样本中的 Prompt 编写人工答案,这是高度人工参与过程,而且对标注人员要求很高;
第 ...
Large Language Models Are Human-Level Prompt Engineers
近期在 NLP 领域风很大的话题莫过于 Prompt,尤其当大型语言模型(LLM)与其结合,更是拉近了我们与应用领域之间的距离,当 LLM 在包括小样本学习在内的各种任务中表现出非凡的效果和通用性时,也存在着一个问题亟待解决:如何让 LLM 按照我们的要求去做?这也是本篇论文的一个重要出发点。
本文作者将 LLM 视为执行由自然语言指令指定程序的黑盒计算机,并研究如何使用模型生成的指令来控制 LLM 的行为。受经典程序合成和人工提示工程方法的启发,作者提出了自动提示工程师 (Automatic Prompt Engineer, APE) 用于指令自动生成和选择,将指令视为“程序”,通过搜索由 LLM 提出的候选指令池来优化,以使所选的评分函数最大化。
作者通过对 24 个 NLP 任务的实验分析指出,自动生成的指令明显优于先前的 LLM Baseline,且 APE 设计的提示可以用于引导模型真实性和信息量,以及通过简单地将它们预设为标准上下文学习提示来提高小样本学习性能。
论文地址: https://arxiv.org/abs/2211.01910
代码地址: https://gi ...

用于大型Transformer的8-bit矩阵乘法介绍
语言模型正变的越来越大,PaLM有540B的参数量,OPT、GPT-3和BLOOM则大约有176B的参数量,而且我们正朝着更大的模型发展。下图是近些年语言模型的尺寸。
这些模型很难在常用设备上运行。例如,仅仅推理BLOOM-176B就需要8张A00 GPUs(每张80G显存,价格约15k美元)。而为了微调BLOOM-176B则需要72张GPU。PaLM则需要更多的资源。
这些巨型模型需要太多GPUs才能运行,因此需要寻找方法来减少资源需求并保证模型的性能。已经有各种技术用来减小模型尺寸,例如量化、蒸馏等。
在完成BLOOM-176B训练后,HuggingFace和BigScience逐步探索在少量GPU上运行大模型的方法。最终,设计出了Int8量化方法,该方法在不降低大模型性能的情况下,将显存占用降低了1至2倍,并且集成到了Transformers模块中。具体关于LLM.int8内容可参考余下论文:
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
常用类型
浮点数在机器学习中也被称为"精 ...
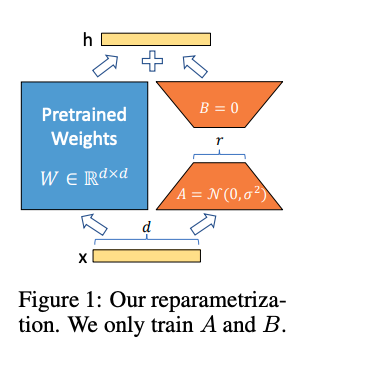
LoRA:Low-Rank Adaptation of Large Language Models
LoRA是微软研究员引入的一项新技术,主要用于处理大模型微调的问题。目前超过数十亿以上参数的具有强能力的大模型 (例如 GPT-3) 通常在为了适应其下游任务的微调中会呈现出巨大开销。 LoRA 建议冻结预训练模型的权重并在每个 Transformer 块中注入可训练层 (秩-分解矩阵)。因为不需要为大多数模型权重计算梯度,所以大大减少了需要训练参数的数量并且降低了 GPU 的内存要求。研究人员发现,通过聚焦大模型的 Transformer 注意力块,使用 LoRA 进行的微调质量与全模型微调相当,同时速度更快且需要更少的计算。
论文地址: https://arxiv.org/pdf/2106.09685.pdf
论文代码: https://github.com/microsoft/LoRA
介绍
LoRA的主要思想是将预训练模型权重冻结,并将可训练的秩分解矩阵注入Transformer架构的每一层,大大减少了下游任务的可训练参数数量。具体来说,它将原始矩阵分解为两个矩阵的乘积,其中一个矩阵的秩比另一个矩阵的秩低。这时只需要运用低秩矩阵来进行运算,这样,可以减少模型参数数量,提高训 ...
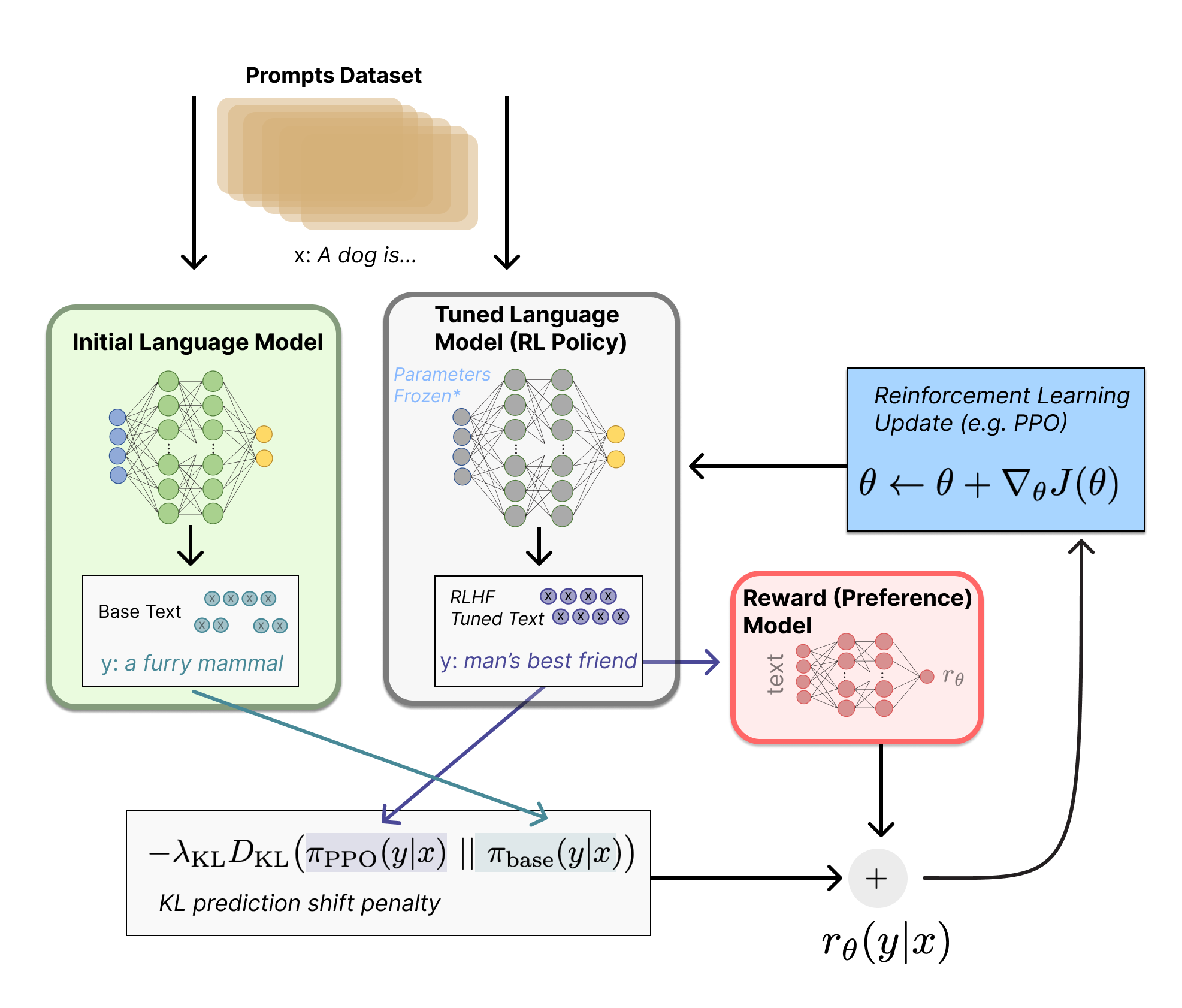
Reinforcement Learning from Human Feedback (RLHF)详解
OpenAI 推出的 ChatGPT 对话模型掀起了新的 AI 热潮,它面对多种多样的问题对答如流,似乎已经打破了机器和人的边界。这一工作的背后是大型语言模型 (Large Language Model,LLM) 生成领域的新训练范式:RLHF (Reinforcement Learning from Human Feedback) ,即以强化学习方式依据人类反馈优化语言模型。
过去几年里各种 LLM 根据人类输入提示 (prompt) 生成多样化文本的能力令人印象深刻。然而,对生成结果的评估是主观和依赖上下文的,例如,我们希望模型生成一个有创意的故事、一段真实的信息性文本,或者是可执行的代码片段,这些结果难以用现有的基于规则的文本生成指标 (如 BLUE 和 ROUGE) 来衡量。除了评估指标,现有的模型通常以预测下一个单词的方式和简单的损失函数 (如交叉熵) 来建模,没有显式地引入人的偏好和主观意见。
如果我们 用生成文本的人工反馈作为性能衡量标准,或者更进一步用该反馈作为损失来优化模型,那不是更好吗?这就是 RLHF 的思想:使用强化学习的方式直接优化带有人类反馈的语言模型。RL ...
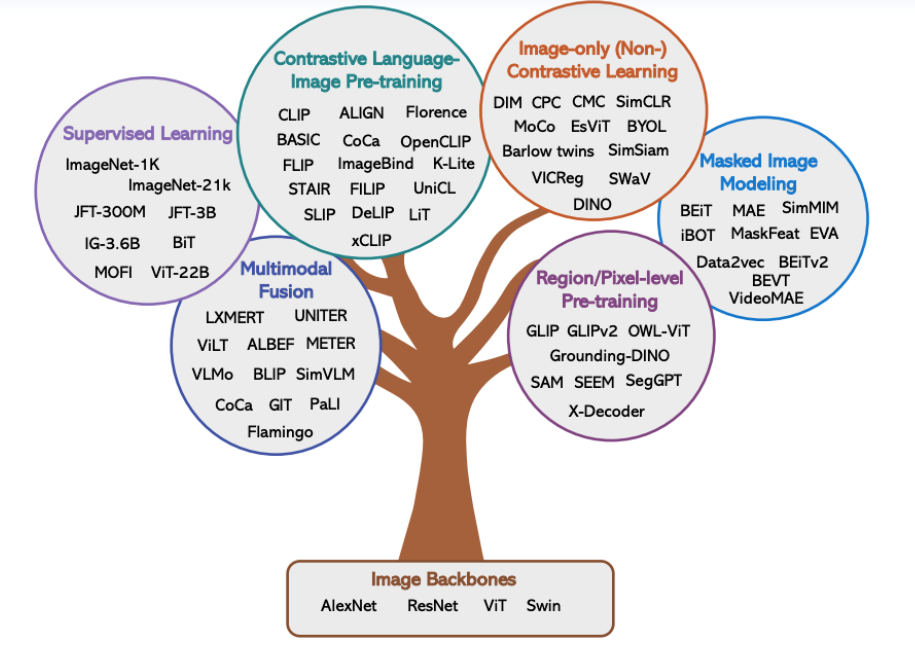
多模态预训练模型综述
预训练模型在NLP和CV上取得巨大成功,学术届借鉴预训练模型–>下游任务finetune–>prompt训练–>人机指令alignment这套模式,利用多模态数据集训练一个大的多模态预训练模型(跨模态信息表示)来解决多模态域各种下游问题。
多模态预训练大模型主要包括以下4个方面:
1.多模态众原始输入图、文数据表示:将图像和文本编码为潜在表示,以保留其语义
2.多模态数据如何交互融合:设计一个优秀架构来交叉多模态信息之间的相互作用
3.多模态预训练大模型如何学习萃取有效知识:设计有效的训练任务来让模型萃取信息
4.多模态预训练大模型如何适配下游任务:训练好的预训练模型fintune适配下游任务
本篇文章主要参考:《A survey of Vision-Language Pre-trained Models》
前置任务:文本-图语料对准备
预培训数据集,预训练多模态大模型的第一步是构建大规模的图像文本对。我们将训练前数据集定义为D=(W,V),N,i=1D = {(W, V )},N,i=1D=(W,V),N,i=1,其中W和V分别表示文本和图像,N是图像-文本对的数 ...

通向AGI之路:大型语言模型(LLM)技术精要
ChatGPT出现后惊喜或惊醒了很多人。惊喜是因为没想到大型语言模型(LLM,Large Language Model)效果能好成这样;惊醒是顿悟到我们对LLM的认知及发展理念,距离世界最先进的想法,差得有点远。我属于既惊喜又惊醒的那一批,也是典型的中国人,中国人善于自我反思,于是开始反思,而这篇文章正是反思的结果。
实话实说,国内在LLM模型相关技术方面,此刻,距离最先进技术的差距进一步加大了。技术领先或技术差距这事情,我觉得要动态地以发展的眼光来看。在Bert出现之后的一到两年间,其实国内在这块的技术追赶速度还是很快的,也提出了一些很好的改进模型,差距拉开的分水岭应该是在 GPT 3.0出来之后,也就是2020年年中左右。在当时,其实只有很少的人觉察到:GPT 3.0它不仅仅是一项具体的技术,其实体现的是LLM应该往何处去的一个发展理念。自此之后,差距拉得越来越远,ChatGPT只是这种发展理念差异的一个自然结果。所以,我个人认为,抛开是否有财力做超大型LLM这个因素,如果单从技术角度看,差距主要来自于对LLM的认知以及未来应往何处去的发展理念的不同。
国内被国外技术甩得越来越远, ...

万字拆解,追溯ChatGPT各项能力的起源
最近,OpenAI的预训练模型ChatGPT给人工智能领域的研究人员留下了深刻的印象和启发。毫无疑问,它又强又聪明,且跟它说话很好玩,还会写代码。它在多个方面的能力远远超过了自然语言处理研究者们的预期。于是我们自然就有一个问题:ChatGPT 是怎么变得这么强的?它的各种强大的能力到底从何而来? 在这篇文章中,我们试图剖析 ChatGPT 的突现能力(Emergent Ability),追溯这些能力的来源,希望能够给出一个全面的技术路线图,来说明 GPT-3.5 模型系列以及相关的大型语言模型是如何一步步进化成目前的强大形态。
Emergent Ability: 突现能力,表示小模型没有,只在模型大到一定程度才会出现的能力
我们希望这篇文章能够促进大型语言模型的透明度,成为开源社区共同努力复现 GPT-3.5 的路线图。
致国内的同胞们:
在国际学术界看来,ChatGPT / GPT-3.5 是一种划时代的产物,它与之前常见的语言模型 (Bert/ Bart/ T5) 的区别,几乎是导弹与弓箭的区别,一定要引起最高程度的重视。
在我跟国际同行的交流中,国际上的主流学术机构 ...

Zwift单机版详细安装过程
Zwift单机版本的详细安装过程,如果文字版安装有困难,可直接B站搜索相关视频进行安装。
Window系统
首先下载所需软件,如下(点击下载):
python-3.11.4-amd64
zoffline-helper-master
zwift-offline-master
ZwiftSetup
详细安装教程:
1、安装ZwiftSetup ,★★★★★等update进度跑完,再退出zwift★★★★★,包括托盘区任务图标;(已经安装并更新至最新版忽略此步)
2、安装"python-3.11.1-amd64",勾选“Add python.exe to PATH"
3、解压缩 zwift-offline-master;
安装依赖包,使用命令 win+R , 输入CMD 按住ctrl+shift+回车 出现命令字符框,
CD 到 zwift-offline-master 文件夹目录下,然后输入下列命令:
pip install -r requirements.txt 回车
如果安装一遍不成功出现红字,重新执行命令再安装一次
4、进入zwi ...

