Output: ---------------------------------------------------------------------------------------------------- I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
Output: ---------------------------------------------------------------------------------------------------- I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll
Output: ---------------------------------------------------------------------------------------------------- I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's timefor me to take a break
# now we have 3 output sequences print("Output:\n" + 100 * '-') for i, beam_output inenumerate(beam_outputs): print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Output: ---------------------------------------------------------------------------------------------------- 0: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's timefor me to take a break 1: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's timefor me to get back to 2: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's timefor me to take a break 3: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's timefor me to get back to 4: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's timefor me to take a step
Output: ---------------------------------------------------------------------------------------------------- I enjoy walking with my cute dog. He just gave me a whole new hand sense." But it seems that the dogs have learned a lot from teasing at the local batte harness once they take on the outside. "I take
Nice,生成的文本看起来不错,但是仔细看,看起来仍然不是很连贯。三元组(“new”、“hand”、“sense”)(“local”、“batte”、“harness”)看起来很怪,不像是人写出来的,这在sampling生成中是一个很大的问题,同时他也经常胡言乱语 Ari Holtzman et al. (2019)。
Output: ---------------------------------------------------------------------------------------------------- I enjoy walking with my cute dog, but I don't like to be at home too much. I also find it a bit weird when I'm out shopping. I am always away from my house a lot, but I do have a few friends
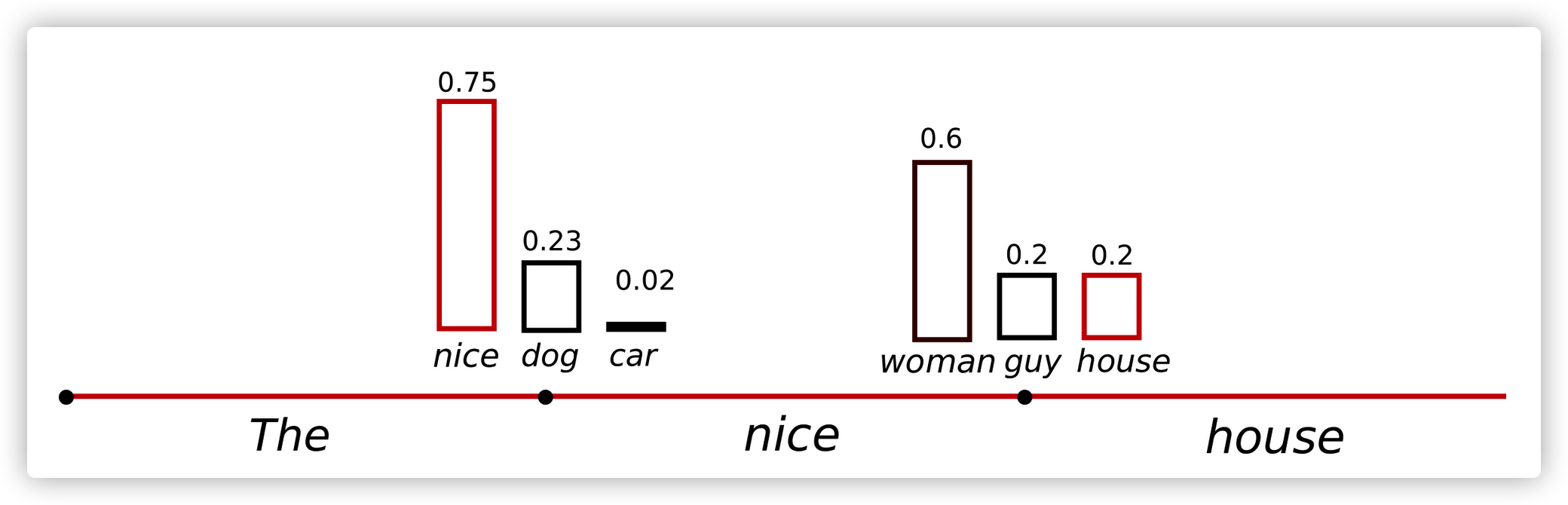
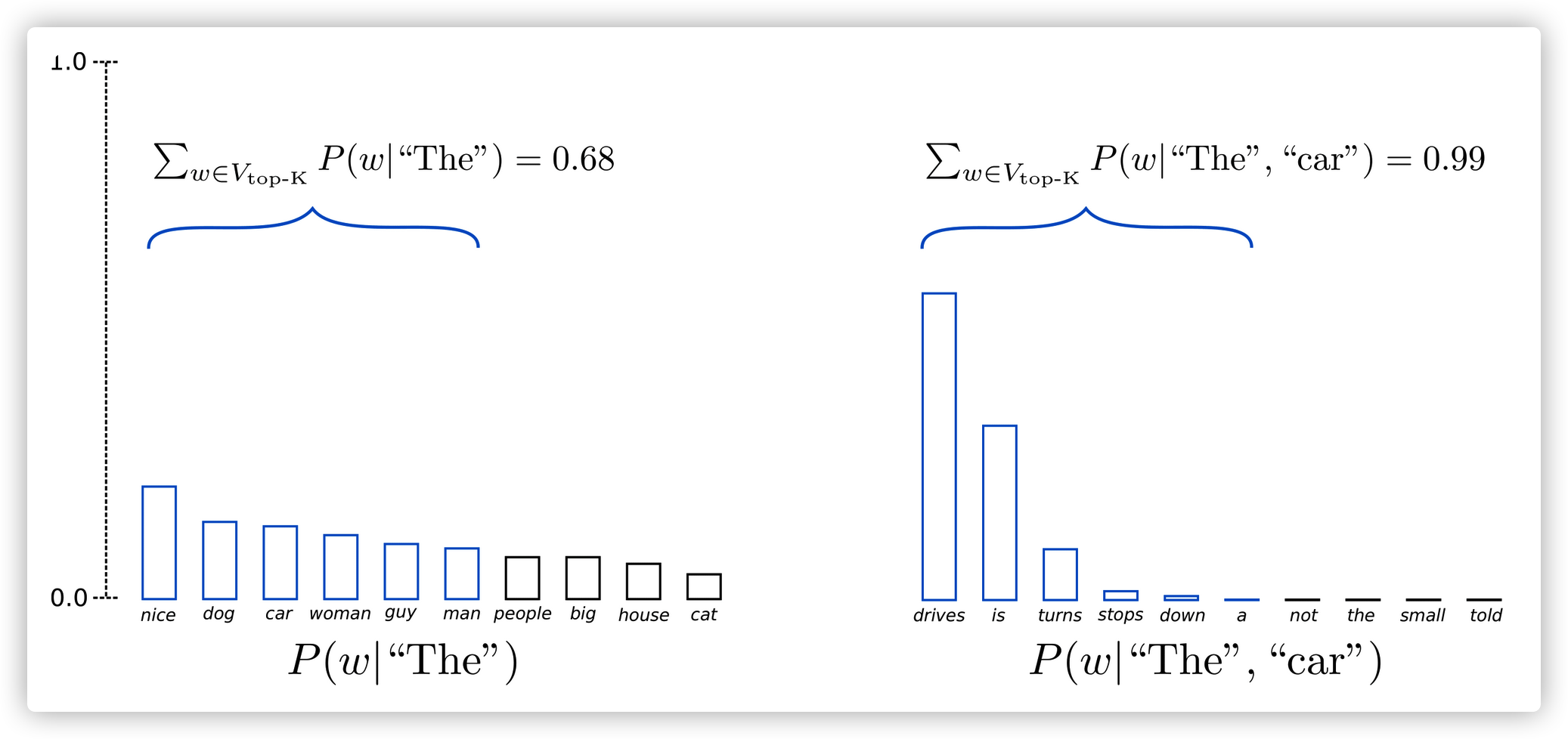
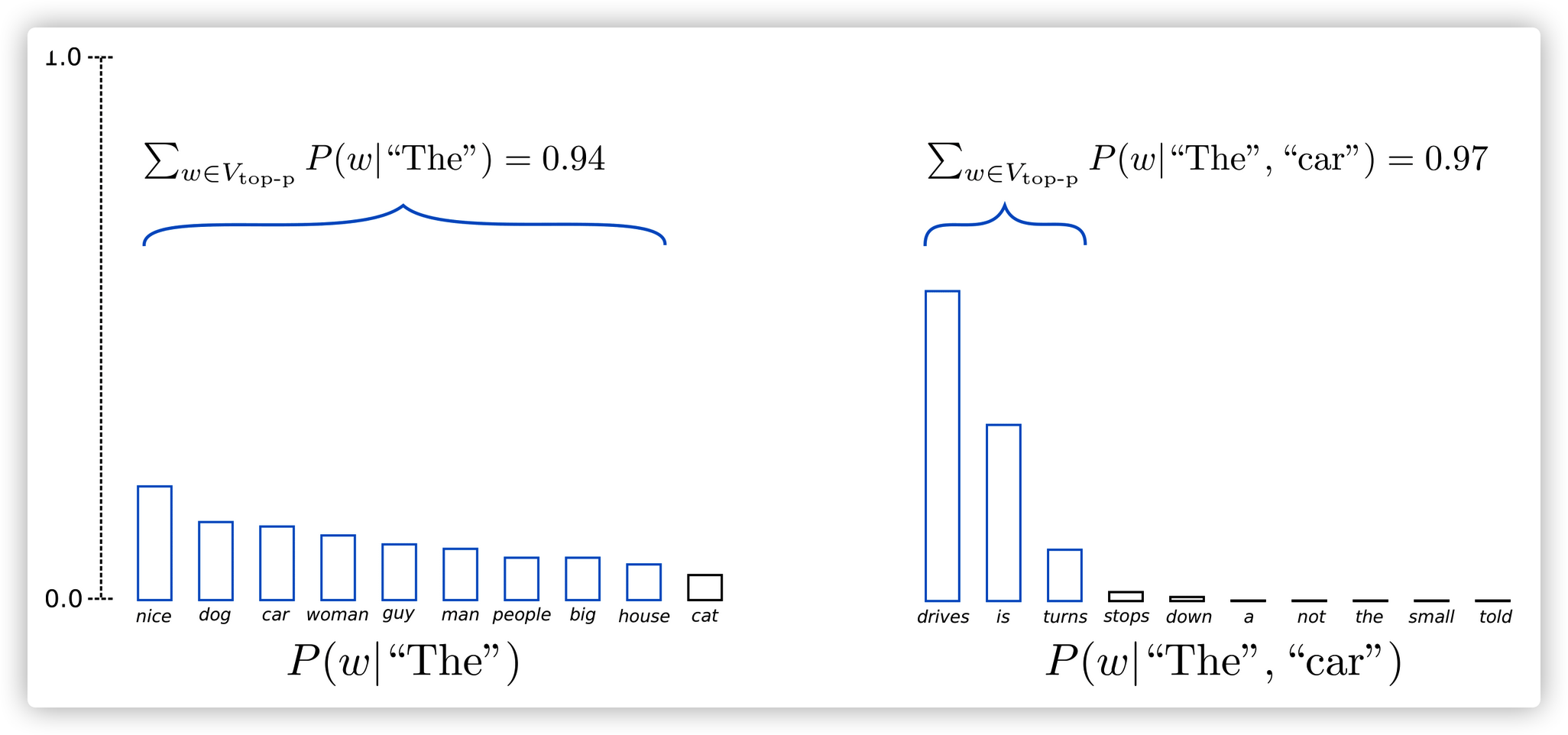
Fan et. al (2018)介绍了一个简单有效的sampling方法,叫做Top-K sampling。 Top-K是直接挑选概率最高的K个单词,然后重新根据softmax计算这K个单词的概率(redistributed),再根据概率分布情况进行采样,生成下一个单词。Top-k采样也可以结合Temperature Sampling方法。。GPT2用了这种抽样方法,这也是它生成故事效果好的主要原因。
优缺点和K值的选取
优点:可以避免低概率词的生成,基本top-k的采样方法,能够提升生成质量,因为它会把概率较低的结果丢弃(removing the tail),因此能使得生成过程不那么偏离主题。
Output: ---------------------------------------------------------------------------------------------------- I enjoy walking with my cute dog. It's so good to have an environment where your dog is available to share with you and we'll be taking care of you.
We hope you'll find this story interesting! I am from
Output: ---------------------------------------------------------------------------------------------------- I enjoy walking with my cute dog. He will never be the same. I watch him play.
Guys, my dog needs a name. Especially if he is found with wings.
print("Output:\n" + 100 * '-') for i, sample_output inenumerate(sample_outputs): print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
1 2 3 4 5 6 7 8
Output: ---------------------------------------------------------------------------------------------------- 0: I enjoy walking with my cute dog. It's so good to have the chance to walk with a dog. But I have this problem with the dog and how he's always looking at us and always trying to make me see that I can do something 1: I enjoy walking with my cute dog, she loves taking trips to different places on the planet, even in the desert! The world isn't big enough for us to travel by the bus with our beloved pup, but that's where I find my love 2: I enjoy walking with my cute dog and playing with our kids," said David J. Smith, director of the Humane Society of the US. "So as a result, I've got more work in my time," he said. Cool,现在可以用transformers实现这些解码技术,生成你的故事了。
总结
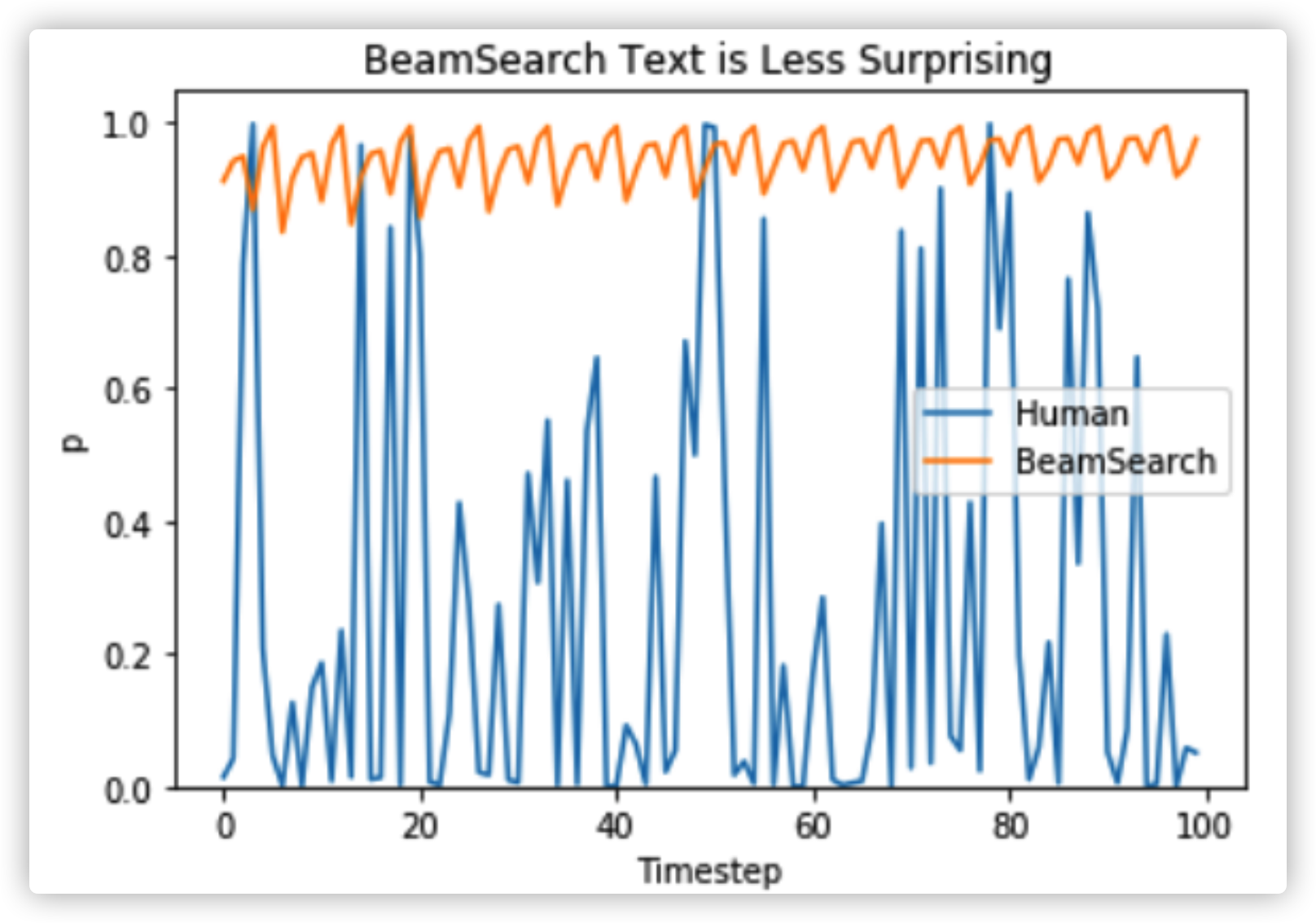
在开放语言生成领域,top-p和top-k这些解码方法,比greedy search、beam search生成的文本更流利。如今,也有很多证据证明了greedy search、beam search的缺点,如生成重复的词序列,是因为训练的模型导致的,而不是解码方式Welleck et al. (2019)。同时,在Welleck et al. (2020)中,也证明了,top-K和top-p抽样也会生成重复的词序列。
在Welleck et al. (2019)中,在调整训练目标后,通过人类评测beam search和top-p sampling发现,beam search的生成文本更流利。
感谢这个博客的贡献者:Alexander Rush, Julien Chaumand, Thomas Wolf, Victor Sanh, Sam Shleifer, Clément Delangue, Yacine Jernite, Oliver Åstrand and John de Wasseige