model = AutoModelForCausalLM.from_pretrained( model_name, quantization_config=bnb_config, device_map="auto", # dispatch efficiently the model on the available ressources max_memory = {i: max_memory for i inrange(n_gpus)}, ) tokenizer = AutoTokenizer.from_pretrained(model_name, use_auth_token=True)
# Needed for LLaMA tokenizer tokenizer.pad_token = tokenizer.eos_token
defcreate_prompt_formats(sample): """ Format various fields of the sample ('instruction', 'context', 'response') Then concatenate them using two newline characters :param sample: Sample dictionnary """
INTRO_BLURB = "Below is an instruction that describes a task. Write a response that appropriately completes the request." INSTRUCTION_KEY = "### Instruction:" INPUT_KEY = "Input:" RESPONSE_KEY = "### Response:" END_KEY = "### End" blurb = f"{INTRO_BLURB}" instruction = f"{INSTRUCTION_KEY}\n{sample['instruction']}" input_context = f"{INPUT_KEY}\n{sample['context']}"if sample["context"] elseNone response = f"{RESPONSE_KEY}\n{sample['response']}" end = f"{END_KEY}" parts = [part for part in [blurb, instruction, input_context, response, end] if part]
# SOURCE https://github.com/databrickslabs/dolly/blob/master/training/trainer.py defpreprocess_dataset(tokenizer: AutoTokenizer, max_length: int, seed, dataset: str): """Format & tokenize it so it is ready for training :param tokenizer (AutoTokenizer): Model Tokenizer :param max_length (int): Maximum number of tokens to emit from tokenizer """ # Add prompt to each sample print("Preprocessing dataset...") dataset = dataset.map(create_prompt_formats)#, batched=True) # Apply preprocessing to each batch of the dataset & and remove 'instruction', 'context', 'response', 'category' fields _preprocessing_function = partial(preprocess_batch, max_length=max_length, tokenizer=tokenizer) dataset = dataset.map( _preprocessing_function, batched=True, remove_columns=["instruction", "context", "response", "text", "category"], )
# Filter out samples that have input_ids exceeding max_length dataset = dataset.filter(lambda sample: len(sample["input_ids"]) < max_length) # Shuffle dataset dataset = dataset.shuffle(seed=seed)
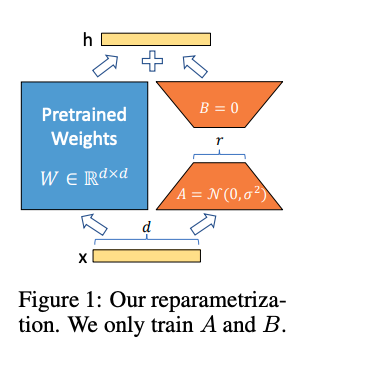
defcreate_peft_config(modules): """ Create Parameter-Efficient Fine-Tuning config for your model :param modules: Names of the modules to apply Lora to """ config = LoraConfig( r=16, # dimension of the updated matrices lora_alpha=64, # parameter for scaling target_modules=modules, lora_dropout=0.1, # dropout probability for layers bias="none", task_type="CAUSAL_LM", )
defprint_trainable_parameters(model, use_4bit=False): """ Prints the number of trainable parameters in the model. """ trainable_params = 0 all_param = 0 for _, param in model.named_parameters(): num_params = param.numel() # if using DS Zero 3 and the weights are initialized empty if num_params == 0andhasattr(param, "ds_numel"): num_params = param.ds_numel
deftrain(model, tokenizer, dataset, output_dir): # Apply preprocessing to the model to prepare it by # 1 - Enabling gradient checkpointing to reduce memory usage during fine-tuning model.gradient_checkpointing_enable()
# 2 - Using the prepare_model_for_kbit_training method from PEFT model = prepare_model_for_kbit_training(model)
# Get lora module names modules = find_all_linear_names(model)
# Create PEFT config for these modules and wrap the model to PEFT peft_config = create_peft_config(modules) model = get_peft_model(model, peft_config) # Print information about the percentage of trainable parameters print_trainable_parameters(model) # Training parameters trainer = Trainer( model=model, train_dataset=dataset, args=TrainingArguments( per_device_train_batch_size=1, gradient_accumulation_steps=4, warmup_steps=2, max_steps=20, learning_rate=2e-4, fp16=True, logging_steps=1, output_dir="outputs", optim="paged_adamw_8bit", ), data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False) ) model.config.use_cache = False# re-enable for inference to speed up predictions for similar inputs ### SOURCE https://github.com/artidoro/qlora/blob/main/qlora.py # Verifying the datatypes before training dtypes = {} for _, p in model.named_parameters(): dtype = p.dtype if dtype notin dtypes: dtypes[dtype] = 0 dtypes[dtype] += p.numel() total = 0 for k, v in dtypes.items(): total+= v for k, v in dtypes.items(): print(k, v, v/total) do_train = True # Launch training print("Training...") if do_train: train_result = trainer.train() metrics = train_result.metrics trainer.log_metrics("train", metrics) trainer.save_metrics("train", metrics) trainer.save_state() print(metrics) ### # Saving model print("Saving last checkpoint of the model...") os.makedirs(output_dir, exist_ok=True) trainer.model.save_pretrained(output_dir) # Free memory for merging weights del model del trainer torch.cuda.empty_cache() output_dir = "results/llama2/final_checkpoint" train(model, tokenizer, dataset, output_dir)