本研究的重点是优化延迟的各种方法。具体来说,我想知道哪些工具在优化开源 LLM 的延迟方面最为有效。
-
🏁mlc 是最快的。这个速度太快了,以至于我都有些怀疑,并且现在我有动力去评估质量(如果我有时间的话)。在手动检查输出结果时,它们似乎与其他方法没有什么不同。
-
❤️ CTranslate2 是我最喜欢的工具,它是最快的工具之一,也是最容易使用的工具。在我尝试过的所有解决方案中,它的文档是最好的。与
vLLM不同,CTranslate 似乎还不支持分布式推理。 -
🛠️ vLLM 确实很快,但 CTranslate 可能更快。另一方面,vLLM
支持分布式推理,而这正是大型模型所需要的。 -
Text Generation Inference如果想以标准方式部署 HuggingFace LLM,文本生成推理是一个不错的选择(但速度远不及
vLLM)。TGI 有一些不错的功能,如内置遥测(通过 [OpenTelemetry](via OpenTelemetry))以及与 HF 生态系统(如inference endpoints)的集成。值得注意的是,从 2023 年 7 月 28 日起,TGI 的许可证被修改为限制性更强,可能会影响某些商业用途。
为了专注于延迟,我将以下变量保持不变:
- 所有预测请求的批量大小为
n = 1(吞吐量保持不变)。 - 除非另有说明,所有实验均在
Nvidia A6000 GPU上进行。 - 最大输出令牌数始终设置为
200。 - 所有数据均以固定的 9 个提示的平均值计算。
- 使用的模型是 HuggingFace Hub 2 上的 meta-llama/Llama-2-7b-hf。
除了批量大小为 n = 1 和使用 A6000 GPU(除非另有说明)之外,我还确保在测量延迟之前通过发送初始推理请求为模型预热。
以下是Llama-v2-7b模型结果:
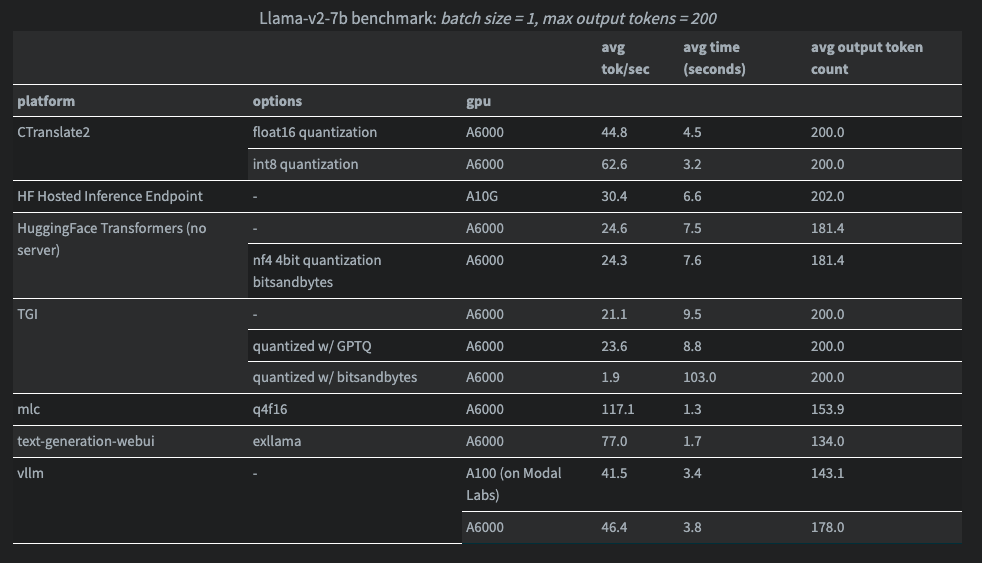
在某些情况下,我没有使用 A6000,因为该平台没有这种 GPU。如果你愿意,可以忽略这些记录,但我仍然认为这些信息很有价值。
我注意到在使用 vLLM 时,LLM 的输出有很大不同(tokens数量更少)。我不确定是我做错了什么,还是它改变了 LLM 的行为。
此外,我们的目标并不是要在这些基准上做到超级精确,而是要对这些工具的工作原理以及它们在开箱后的相互比较有一个大致的了解。上述工具中有些是推理服务器,除了优化影响延迟的模型外,还能执行日志记录、跟踪等功能。我们的目的是要找出工具之间的显著差异。
要想在开源 LLM 上取得成功,您需要具备的一项能力就是高效地为模型提供服务。模型推理工具分为两类:
-
推理服务:这些推理服务可帮助提供网络服务,该服务可提供 REST/grpc 或其他接口,以服务的形式与您的模型进行交互。这些推理服务通常有参数,可帮助您在吞吐量和延迟之间做出权衡。此外,一些推理服务还具有日志记录、模型版本管理等功能。您可以在本说明的 "服务 "部分了解更多相关信息。对于 LLM,常用的推理服务有Text Generation Inference (TGI) 和 vLLM。
-
模型优化:可以修改模型,使推理速度更快。例如 quantization, Paged Attention, Exllama等。
推理服务和模型优化技术结合使用是很常见的。一些推理服务(如 TGI 和 vLLM)甚至可以帮助你应用优化技术。
MLC
按照文档中的说明开始编译模型
成功安装 MLC后,通过一下命令编译meta-llama/Llama-2-7b-chat-hf 模型:
1 | python3 -m mlc_llm.build \ |
此处记录了编译的参数。这将把模型放到 ./dist/ 文件夹中,名称为 Llama-2-7b-chat-hf-q4f16_1。
您可以使用python 客户端与编译后的模型进行交互:
1 | from mlc_chat import ChatModule, ChatConfig |
您可以在这里查看完整的测试代码。
CTranslate2
CTranslate2 是一个优化工具,可以使模型加速。CTranslate2 的文档中包含有关llama模型的具体说明。
要优化 llama v2,我们首先需要量化模型。如下:
1 | ct2-transformers-converter --model meta-llama/Llama-2-7b-hf --quantization int8 --output_dir llama-2-7b-ct2 --force |
运行代码如下:
1 | import time |
Text Generation Inference (TGI)
TGI 的许可证最近从 Apache 2.0 版改为限制性更强的版本。在商业应用中使用 TGI 时要小心。
Text generation inference通常被称为 “TGI”,无需任何优化即可轻松使用。执行命令如下:
1 | !/bin/bash |
然后,我们就可以用这条命令运行服务:
1 | bash start_server.sh --model-id "meta-llama/Llama-2-7b-hf" |
Quantization
量化工作非常困难。在接受bitsandbytes和gptq时有一个 -quantize 标志。从其他实验报告中可以看出bitsandbytes方法使得推理速度更慢。
要让 gptq 适用于 llama v2 模型,需要做大量工作,你必须install the text-generation-server ,这可能需要一段时间,而且非常容易出错。我必须仔细阅读 Makefile。然后,你必须下载权重:
1 | text-generation-server download-weights meta-llama/Llama-2-7b-hf |
您可以运行以下命令来执行量化(最后一个参数是权重的目标存储目录)。
1 | text-generation-server quantize "meta-llama/Llama-2-7b-hf" data/quantized/ |
不过,最流行的模型并不需要这一步骤,因为很可能已经有人对它们进行了量化并上传到了 Hub。
Pre-Quantized Models
或者,您也可以使用已经上传到 Hub 的预量化模型。TheBloke/Llama-2-7B-GPTQ 就是一个很好的例子。要使其正常工作,必须小心设置 GPTQ_BITS和 GPTQ_GROUPSIZE 环境变量,使其与配置相匹配。例如,此配置需要设置 GPTQ_BITS=4 和 GPTQ_GROUPSIZE=128,而这些变量已在上文所示的 start_server.sh 中设置。该PR 将最终解决这一问题。
要在 TGI 中使用TheBloke/Llama-2-7B-GPTQ,我可以使用相同的 bash 脚本,并添加以下参数:
1 | bash start_server.sh --model-id TheBloke/Llama-2-7B-GPTQ --quantize gptq |
HuggingFace Transformers
为了对 bitsandbytes 进行量化基准测试,我按照这篇博文编写了测试代码。我是这样加载模型进行量化的:
1 | model_id = "meta-llama/Llama-2-7b-hf" |
与 TGI 不同的是,我可以让 bitsandbytes 在这里正常工作,但与 TGI 一样,它在推理延迟方面没有为我加快任何速度。如基准测试表所示,在没有任何优化的情况下,我使用转换器得到了几乎相同的结果。
GPTQ
我还在没有推理服务的情况下使用AutoGPTQ 对模型进行了量化,以便与 TGI 进行比较。相关代码在这里。
结果非常糟糕 ~ 5 tok/秒,所以我决定不把它放在表中,因为我觉得这很不正常。
Text Generation WebUI
这些文档可用于快速尝试使用ExLlama 和 ggml。遗憾的是,我没能让 ggml正常工作。如果你真的很想使用 exllama,我建议你尝试在没有text generation UI 的情况下使用它,并查看 exllama 仓库,特别是 test_benchmark_inference.py。(我没有时间做这个,但如果我想认真使用 exllama,我会选择这条路线)。
从 text-generation-web-ui 仓库 的根目录运行以下命令,即可启动使用ExLlama优化过的推理服务:
1 | python3 download-model.py TheBloke/Llama-2-7B-GPTQ |
服务启动后,我使用这段代码进行了基准测试。
总的来说,我不太喜欢这个模块。它有点臃肿,因为它试图同时做太多事情(推理服务、Web UI 和其他优化)。尽管如此,它的文档还是不错的,使用起来也很方便。
我不认为有什么特别的理由要使用它,除非你想要一个端到端解决方案,而且还带有网络用户界面(这是很多人都想要的!)。
vLLM
vLLM 目前好像只适用于 CUDA 11.8(看后续版本更新),参考该链接方法配置。配置好 CUDA 并安装正确版本的 PyTorch 后,你需要从 git 安装 bleeding edge:
1 | pip install -U git+https://github.com/vllm-project/vllm.git |
在这些 Modal 文档中可以找到用于 vLLM 的好方法。令人惊讶的是,我在本地 A6000 上运行时的延迟比在 Modal Labs 托管的 V100 上运行时低得多。可能是我做错了什么。目前,vLLM 是需要分布式推理时(即模型无法在单个 GPU 上运行时)最快的解决方案。
vLLM 提供服务器,但我使用他们的工具在本地对模型进行了基准测试。基准测试代码可在此处找到:
1 | from vllm import SamplingParams, LLM |
当单个GPU无法装载下整个模型时,我们可以使用各种技术在多个 GPU 上拆分模型。
分布式推理
vLLM 支持张量并行,您可以通过向 LLM 构造函数传递 tensor_parallel_size 参数来启用张量并行。
我修改了这个用于 Llama v2 13b 的代码示例,以便在 4 个 GPU 上以张量并行方式运行 Llama v2 70b。以下是最重要改动的简化差异:
1 | def download_model_to_folder(): |
整个完整代码可参考 big-inference-vllm.py
为 HuggingFace 和 Weights & Biases 设置适当的秘密后,您就可以使用以下命令在 Modal 上运行这段代码了:
1 | modal run big-inference-vllm.py |
您至少需要 4 个 A100 GPU 才能正常运行 Llama v2 70b 服务。
尽管分布式推理对于单个 GPU 难以容纳的大型模型来说非常有趣,但当你以这种方式为小型模型提供服务时,有趣的事情还是发生了。下面,我测试了 Llama v2 7b 在 1、2 和 4 个 GPU 上的吞吐量。吞吐量是通过向 llm.generate 发送这 59 个提示来测量的。llm.generate 在 vLLM 文档中有所描述:
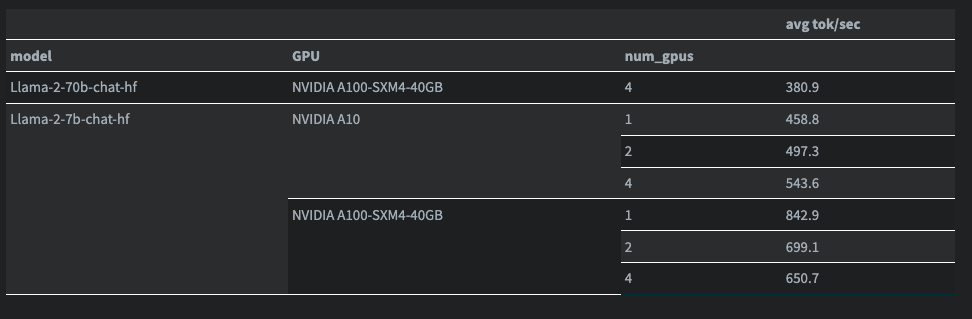
您可以在这里看到所有的运行日志。在我的实验中,70b 模型至少需要 4 个 A100 才能运行,因此该模型只有一行(Modal 只有 1、2 或 4 个 GPU 的实例)。