在本教程中,将使用Pytorch框架介绍深度学习,并通过一个简单案例进行实验,通过本教程,你将可以轻松地使用Pytorch框架构建深度学习模型。(我也刚刚接触Pytorch)
Pytorch 简介
Pytorch 是一个基于 Torch 的 Python 机器学习包,而 Torch 则是一个基于编程语言 Lua 的开源机器学习包。Pytorch 有两个主要的特点:
利用强大的 GPU 加速进行张量计算(如 NumPy)
用于构建和训练神经网络的自动微分机制
相比其它深度学习库,Pytorch 具有以下两点优势:
与 TensorFlow 等其它在运行模型之前必须先定义整个计算图的库不同,Pytorch 允许动态定义图。
Pytorch 也非常适合深度学习研究,提供了最大的灵活性和运行速度。
Tensors
Pytorch 张量与 NumPy 数组非常相似,而且它们可以在 GPU 上运行。这一点很重要,因为它有助于加速数值计算,从而可以将神经网络的速度提高 50 倍甚至更多。为了使用 Pytorch,你需要先访问其官网并安装 Pytorch。如果你正在使用 Conda,你可以通过运行以下简单命令来安装Pytorch:
1 conda install PyTorch torchvision -c PyTorch
为了定义 Pytorch 张量,首先需要导入 torch 包。PyTorch 允许你定义两种类型的张量,即 CPU 和 GPU 张量。在本教程中,假设你运行的是使用 CPU 进行深度学习运算的机器,但我也会向你展示如何在 GPU 中定义张量:
Pytorch 的默认张量类型是一个浮点型张量,定义为torch.FloatTensor。例如,你可以根据 Python 的 list 数据结构创建张量:
1 torch.FloatTensor([[20 , 30 , 40 ], [90 , 60 , 70 ]])
如果你使用的是支持 GPU 的机器,你可以通过以下方法定义张量:
1 torch.cuda.FloatTensor([[20 , 30 , 40 ], [90 , 60 , 70 ]])
你也可以使用 Pytorch 张量执行加法和减法等数学运算:
1 2 3 x = torch.FloatTensor([25 ]) y = torch.FloatTensor([30 ]) x + y
你还可以定义矩阵并执行矩阵运算。我们来看看如何定义一个矩阵然后将其转置:
1 2 3 matrix = torch.randn(4 , 5 ) matrix matrix.t()
Autograd 机制
Pytorch 使用了一种叫做自动微分的技术,它可以对函数的导数进行数值估计。自动微分在神经网络中计算反向传递(backward pass)。在训练过程中,神经网络的权重被随机初始化为接近零但不是零的数。反向传递是指从右到左调整权重的过程,而正向传递则是从左到右调整权重的过程。
torch.autograd是 Pytorch 中支持自动微分的库。这个包的核心类是torch.Tensor。如果你想要跟踪这个类的所有操作,请将.requires_grad设置为 True。如果要计算所有的梯度,请调用.backward()。这个张量的梯度将在.grad属性中积累。
如果你想要从计算历史中分离出一个张量,请调用.detach()函数。这也可以防止将来对张量的计算被跟踪。另一种防止历史跟踪的方法是用torch.no_grad()方法封装代码。
你可以将张量Tensor和函数Function类相连接,构建一个编码了完整计算历史的无环图。张量的.grad_fn属性会引用创建了这个张量的Function。如果你要计算导数,可以调用张量的.backward()。如果该张量包含一个元素,你不需要为backward()函数指定任何参数。如果张量包含多个元素,你需要指定一个规模(shape)相匹配的张量的梯度。
例如,你可以创建两个张量,将其中一个张量的requires_grad设定为 True,将另一个的设定为 False。接着你可以用这两个张量来执行加法和求和运算。然后你可以计算其中一个张量的梯度。
1 2 3 4 5 6 7 8 a = torch.tensor([3.0 , 2.0 ], requires_grad=True ) b = torch.tensor([4.0 , 7.0 ]) ab_sum = a + b ab_sum ab_res = (ab_sum*8 ).sum () ab_res.backward() ab_res a.grad
在b上调用.grad的返回值为空,因为你没有将它的requires_grad设置为 True。
nn 模块
这是在 Pytorch 中构建神经网络的模块。nn模块依赖于autograd来定义模型并对其进行微分处理。首先,定义训练一个神经网络的过程:
用一些可学习的参数(即权重)定义神经网络
在输入的数据集上进行迭代
通过网络处理输入
将预测结果和实际值进行比较,并测量误差
将梯度传播回网络的参数中
使用简单的更新规则更新网络的权重:weight = weight - learning_rate * gradient
现在,你可以使用nn模块创建一个双层的神经网络:
1 2 3 4 5 6 7 8 9 10 N, D_in, H, D_out = 64 , 1000 , 100 , 10 x = torch.randn(N, D_in) y = torch.randn(N, D_out) model = torch.nn.Sequential( torch.nn.Linear(D_in, H), torch.nn.ReLU(), torch.nn.Linear(H, D_out), ) loss_fn = torch.nn.MSELoss() learning_rate = 1e-4
在这里我们将解释一下上面用到的参数:
N 是批处理大小。批处理大小是观测数据的数量,观测之后权重将被更新。
D_in: 是输入的维度
H: 是隐藏层的维度
D_out: 是输出层的维度
torch.randn: 定义了指定维度的矩阵
torch.nn.Sequential :初始化了神经网络层的线性堆栈
torch.nn.Linear: 对输入数据应用了线性变换
torch.nn.ReLU: 在元素层级上应用了ReLU激活函数
torch.nn.MSELoss: 创建了一个标准来度量输入 x 和目标 y 中 n 个元素的均方误差
optim 模块
接下来,你要使用 optim 包来定义一个优化器,该优化器将为你更新权重。optim 包抽象出了优化算法的思想,并提供了常用优化算法(如 AdaGrad、RMSProp 和 Adam)的实现。我们将使用 Adam 优化器,它是最流行的优化器之一。
该优化器接受的第一个参数是张量,这些张量需要更新。在正向传递中,你要通过向模型传递 x 来计算出预测的 y。然后,计算并显示出损失。在运行反向传递之前,你要将使用优化器更新的所有变量的梯度设置为零。这样做的原因是,默认情况下,在调用.backward()方法时,梯度不会被重写。然后,你需要在优化器上调用step函数,该步骤会更新其参数。具体的实现代码如下所示:
1 2 3 4 5 6 7 8 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) for t in range (500 ): y_pred = model(x) loss = loss_fn(y_pred, y) print (t, loss.item()) optimizer.zero_grad() loss.backward() optimizer.step()
自定义的 nn 模块
有时你需要构建自己的自定义模块。这种情况下,你需要创建nn.Module的子类,然后定义一个接收输入张量并产生输出张量的 forward。使用nn.Module实现双层网络的方法如下图所示。这个模型与上面的模型非常相似,但不同之处在于你要使用torch.nn.Module创建神经网络。另一个区别是这个模型会使用 stochastic gradient descent optimizer 而不是 Adam。你可以使用下面的代码实现一个自定义的 nn 模块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import torchclass TwoLayerNet (torch.nn.Module): def __init__ (self, D_in, H, D_out ): super (TwoLayerNet, self ).__init__() self .linear1 = torch.nn.Linear(D_in, H) self .linear2 = torch.nn.Linear(H, D_out) def forward (self, x ): h_relu = self .linear1(x).clamp(min =0 ) y_pred = self .linear2(h_relu) return y_pred N, D_in, H, D_out = 64 , 1000 , 100 , 10 x = torch.randn(N, D_in) y = torch.randn(N, D_out) model = TwoLayerNet(D_in, H, D_out) criterion = torch.nn.MSELoss() optimizer = torch.optim.SGD(model.parameters(), lr=1e-4 ) for t in range (500 ): y_pred = model(x) loss = criterion(y_pred, y) print (t, loss.item()) optimizer.zero_grad() loss.backward() optimizer.step()
案例
上面介绍完一些Pytorch的基础之后,接下来,我们将通过一个完整地案例进一步加深对Pytorch的认识。
我们将按照下列目录进行实验:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 --- pytorchFashion | |--- __init__.py | |--- callback | |--- config | |--- dataset | |--- output | |--- test | |--- train | |--- io | |--- model | | |--- __init__.py | | |--- cnn | | | |--- __init__.py | | | |--- alexnet.py | |--- preprocessing | |--- utils
简单地对每个目录进行说明,其中:
callback: 我们自定义的callback
config: 整个实验的配置文件目录
dataset: 数据集目录
output:实验输出目录
test: 预测器目录
train:训练器目录
io: 数据交互目录
model: 模型目录
preprocessing: 数据预处理目录
utils: 常用工具目录
我们主要以常见的FashionMNIST数据集进行实验。
FashionMNIST
FashionMNIST 是一个替代 MNIST 手写数字集 的图像数据集。 它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。
FashionMNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。说白了就是手写数字没有衣服鞋子之类的更复杂。
数据案例如下所示:
备注 : 该数据集可以从地址 进行下载。
实际上,Pytorch模块中已经包含了下载以及处理FashionMNIST数据的脚本,我们只需运行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5 , 0.5 , 0.5 ), (0.5 , 0.5 , 0.5 ))]) train_dataset = datasets.FashionMNIST(root='./dataset/fashion' , train=True , download=False , transform=transform) test_dataset = datasets.FashionMNIST(root='./dataset/fashion' , train=False , download=False , transform=transform) trainIter = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True ) valIter = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False )
之后会在./dataset/fashion目录中生成一份数据集,之后,我们就可以使用torch.utils.data.DataLoader进行加载。
各个模块的代码可以从github 上获取,这里将不详细描述。
我们主要实现run.py脚本文件,详细代码可看源文件。在pytorchFashion同目录下新建一个run.py文件,并写入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import argparseimport torchimport numpy as npfrom torch.optim import Adamimport torchvision.transforms as transformsimport torchvision.datasets as datasetsfrom pytorchFashion.train.trainer import Trainerfrom pytorchFashion.utils.logginger import init_loggerfrom pytorchFashion.config import alexnet_config as configfrom pytorchFashion.train.losses import CrossEntropyfrom pytorchFashion.train.metrics import Accuracyfrom pytorchFashion.callback.lrscheduler import StepLrfrom pytorchFashion.io.data_loader import ImageDataIterfrom pytorchFashion.model.cnn.alexnet import AlexNetfrom pytorchFashion.callback.earlystopping import EarlyStoppingfrom pytorchFashion.callback.modelcheckpoint import ModelCheckpointfrom pytorchFashion.callback.trainingmonitor import TrainingMonitorfrom pytorchFashion.callback.writetensorboard import WriterTensorboardX
首先,我们加载所需模块,可以看到大部分都是我们自定义的模块。接下里,我们定义一个执行的主函数main(),如下:
1 2 3 4 5 6 7 8 9 10 11 12 def main (): checkpoint_dir = config.CHECKPOINT_PATH fig_path = config.FIG_PATH json_path = config.JSON_PATH logger = init_logger(log_name=config.ARCH, log_path=config.LOG_PATH) if args['seed' ] is not None : logger.info("seed is %d" %args['seed' ]) np.random.seed(args['seed' ]) torch.manual_seed(args['seed' ])
其中 :
checkpoint_dir:模型保存路径
fig_path:训练结果可视化保存路径
json_path:训练指标变化保存路径
另外,我们还初始化一个日志记录器logger,记录整个实验过程。以及一个固定的随机种子变量seed(保证结果可复现)。
接着,加载数据,即:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 logger.info('starting load train data from disk' ) transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5 , 0.5 , 0.5 ), (0.5 , 0.5 , 0.5 ))]) train_dataset = datasets.FashionMNIST(root='./dataset/fashion' , train=True , download=True , transform=transform) test_dataset = datasets.FashionMNIST(root='./dataset/fashion' , train=False , download=True , transform=transform) trainIter = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=config.BATCH_SIZE, shuffle=True ) valIter = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=config.BATCH_SIZE, shuffle=False )
其中,transform负责整个数据转换过程,需要注意的是transforms.ToTensor()将变量转化为张量时,默对每张图片像素除以256操作,所以,你会看到我们在进行归一化时,传入的各个通道均值位于0到1之间。
定义好数据之后,接下来,初始化模型和优化器,即:
1 2 3 4 5 6 7 logger.info("initializing model" ) model = SimpleNet(num_classes = config.NUM_CLASSES) optimizer = Adam(params = model.parameters(), lr = config.LEARNING_RATE, weight_decay=config.WEIGHT_DECAY, )
其中,SimpleNet是我们自定义的一个简单卷积神经网络,并且使用Adam优化器进行训练。
下面,初始化callback模块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 logger.info("initializing callbacks" ) write_summary = WriterTensorboardX(writer_dir=config.WRITER_PATH, logger = logger, enable=True ) model_checkpoint = ModelCheckpoint(checkpoint_dir=checkpoint_dir, mode= config.MODE, monitor=config.MONITOR, save_best_only= config.SAVE_BEST_ONLY, arch = config.ARCH, logger = logger) early_stop = EarlyStopping(mode = config.MODE, patience = config.PATIENCE, monitor = config.MONITOR) train_monitor = TrainingMonitor(fig_path = fig_path, json_path = json_path, arch = config.ARCH) lr_scheduler = StepLr(optimizer=optimizer,lr = config.LEARNING_RATE)
其中:
write_summary: 主要是负责将数据写入文件中,以便于使用tensorboard工具进行可视化。
model_checkpoint: 保存模型,这里默认是保存最佳模型,当然也可以指定epoch频率保存模型。
early_stop:当模型在训练过程中,如果模型持续一段时间不再学习,那么使用该功能可以自动停止训练模型。
train_monitor:模型训练过程中的监控器,主要记录各个指标变化情况。
lr_scheduler:学习率变化模式,我们知道一般刚开始训练模型时,应设置一个大的学习率,当模型不断接近最小值时,应设置一个小的学习率。
初始化模型训练器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 logger.info('training model....' ) trainer = Trainer(model = model, train_data = trainIter, val_data = valIter, optimizer = optimizer, criterion=CrossEntropy(), metric = Accuracy(topK=config.TOPK), logger = logger, config = config, model_checkpoint = model_checkpoint, training_monitor = train_monitor, early_stopping = early_stop, writer= write_summary, train_from_scratch=config.RESUME, lr_scheduler=lr_scheduler )
开始训练模型:
1 2 3 4 5 6 7 8 9 10 11 trainer.summary() trainer.train() if __name__ == '__main__' : ap = argparse.ArgumentParser(description='PyTorch model training' ) ap.add_argument('-s' ,'--seed' ,default=1024 ,type = int , help = 'seed for initializing training.' ) args = vars (ap.parse_args()) main()
以上,我们完成了整个训练模型脚本,接下来运行下列命令进行模型训练:
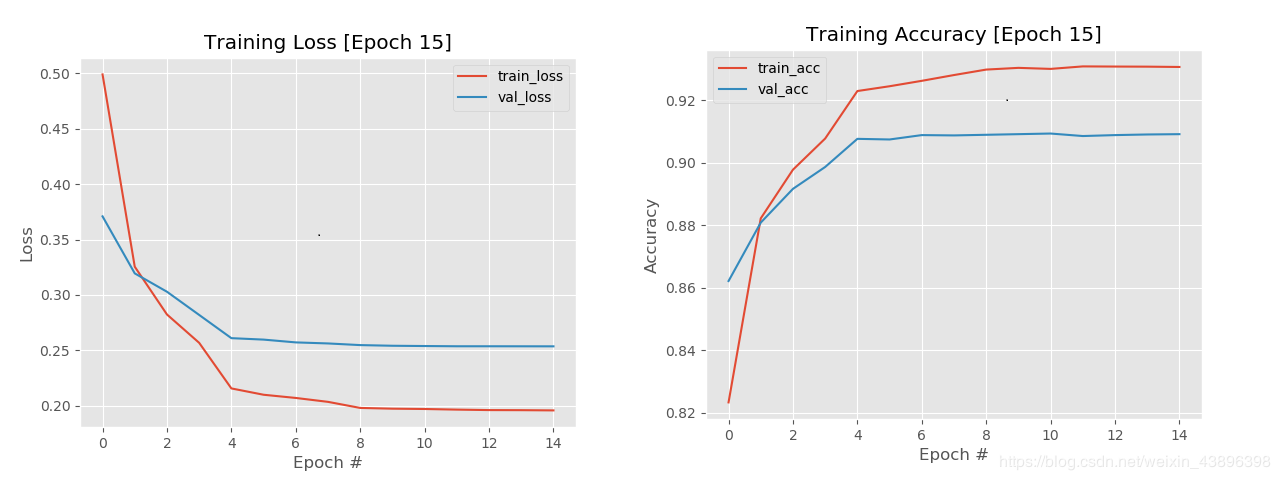
在训练结束之后,在output目录,你可以看到两个文件,分别记录了loss和accuracy的变化情况,即:
备注 :完整代码可从:github 下载