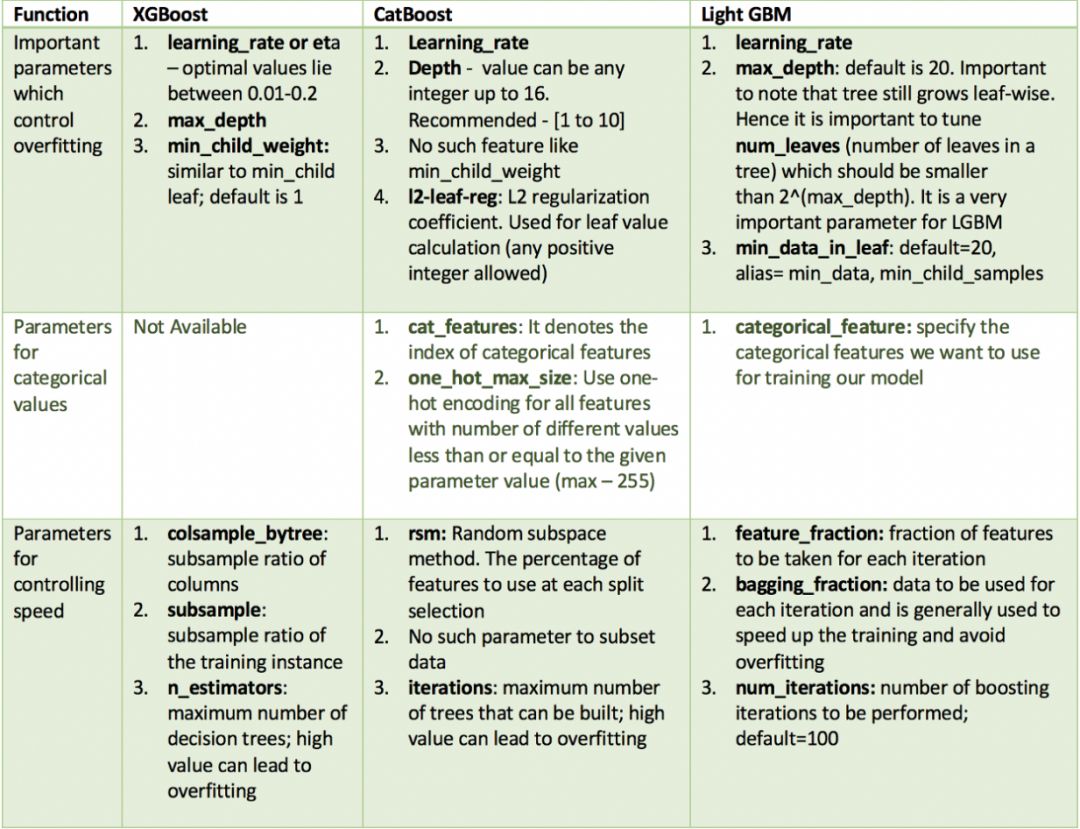
本文主要简单的说明下boosting algorithms家族中的一个算法成员,叫做Regularized Greedy Forests (RGF),在GBDT的基础上,RGF算法针对GBDT每次迭代只优化新建树以及过拟合的问题,提出了正则化的全局优化贪心搜索改进算法:
- 1.每次迭代直接对整个贪心森林进行学习
- 2.新增决策树后进行全局的参数优化
- 3.引入显式的针对决策树的正则项来防止过拟合。
非线性函数学习中,梯度提升算法是当前最有效的一种算法,每一迭代都依赖与上次迭代训练的结果,错误分类的数据被增大权重,因此下次训练时候会重点关注权重比较大的数据.
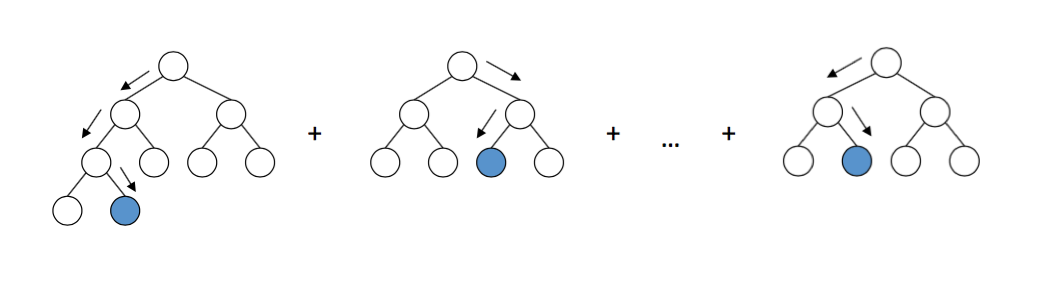
然而,GBDT算法将决策树基函数看成一个黑盒子,因而可以很方便的将决策树替换成其他算法,但是,在GBDT算法中,每一次的迭代中的唯一目标就是学习出n个节点决策树,从而将单颗树的学习与整个森林的学习分隔开.没有很好的利用到决策树本身的性质.新增的决策树只会改变本身参数的变化而没有改变老决策树的参数.
相反,在RGF算法中主要分为两部分:
- 固定节点权重,更改森林的结构使得损失函数下降的最快
- 固定森林的结构,更新节点权重使得损失函数最小化
搜索最优结构
RGF基于决策树的结构直接对决策树进行学习而不是只学习新增的决策树,每次迭代在固定所有点权重的前提下,对整个决策树森林的叶节点执行贪心搜索,不断循环评估找到使得损失函数下降最快的结构变化,并执行相应的结构变化操作获得最优的森林结构.具体实现中,主要是以下两种方式来执行:
- 分裂一个已有的叶节点
- 在森林中新建一个决策树分支
权重优化
更新每一个节点的权重值,使得损失函数最小化:
- 在训练过程中,损失函数跟权重更新间隔是作为参数进行传入,比如默认默认100次(k=100),更新一次所有叶节点的权重参数.
- 如果权重更新间隔非常大,即k很大,相当于只做一次所有叶节点的权重更新;若果k很小(k=1),相当于频繁的更新所有叶节点的权重参数,这样会减慢训练速度.
正则化
全局优化的梯度提升算法能够很明显加速boosting过程的收敛,但是如果没有对决策树做合适的正则化,这种全局优化更新的做法可能会造成很快的过拟合,RGF通过显式的树结构正则化来解决这个问题.
RGF算法中定义了三种不同的正则表达式:
- 叶节点模型的
L2正则化
这种方式中,选择只有叶节点的模型作为唯一的表示并且使用标准的L2正则化,如下所示:
$ \lambda \sum_{v} \frac{\alpha^2_{\alpha}}{2}$
其中$\lambda $是控制惩罚项的程度参数.
- 最小惩罚项正则化
这种方式中,将正则化的模型定义为树节点一些属性的某种形式的最小化惩罚项,比如:
$ \lambda \min_{\beta_)} {\sum_{v} \frac{\gamma^{d_v} \beta^2_{v}}{2} } $
其中为节点深度,为常数,当 时,更大的值对更深的节点惩罚更大,也就是对有着更加复杂决策树规则的节点惩罚更大.
- 最小惩罚项正则化增加条件约束
第三种正则化主要是在第二种的基础上增加一些条件约束,主要是增加了兄弟节点权重的约束,拥有同一个父节点的两个子节点的权重和为0.
树深度
GBDT需要控制树的深度参数来一定程度上控制过拟合,而RGF算法不需要定义树的深度参数,对于RGF算法,每棵树的深度是由叶子节点的最大数量跟惩罚项参数决定的.
模型大小
由于正则化贪心森林算法在模型和森林上执行充分的优化措施,因此和需要低学习率/收缩率以及更多子模型的Boosting算法相比,它可以使用更简单的模型获得良好的结果。
python应用
原论文作者使用C++实现了二分类跟回归的RGF算法,fukatani在此基础上实现了python的封装,并加入了多分类的功能(基于"one vs all"技术).
参数说明
主要看看RGF算法中比较重要的参数:
- max_leaf: 最大叶子节点个数,当整个模型中的叶子节点个数达到最大值限制时,将停止训练.max_leaf尽量取较大的值,这样可以得到一个较好的模型.当然越大训练速度越慢.
- LS: 平方损失,更多的是针对线性回归问题,
- Expo: 指数损失,
- Log:逻辑损失函数,主要是针对二分类问题,
- RGF: 使用叶节点模型的L2正则化(第一种)
- RGF Opt : 最小惩罚项正则化(第二种)
- RGF Sib: 带有约束的最小惩罚项正则化(第三种)
- reg_depth: 必须小于1,只用使用RGF Opt或RGF Sib采用这个参数,值越大对更深的节点惩罚更大
- l2: 控制l2惩罚程度参数,一般使用1,0.1,0.01可以产生较好的结果,如果使用指数损失(Expo)或者逻辑损失(Log),则需要设置更小的值,比如1e-10,1e-20
- sl2: 重置l2正则化参数,如果指定,则权重更新过程使用而树结构生长过程使用,如果未指定,则整个训练过程使用,对于某些数据集,效果更好.
- test_interval: 更新全局叶节点权重的间隔
- normalize: 如果为True,则训练目标会进行标准化处理
应用
首先,先安装模块:
1 | pip install rgf_python |
简单的实现代码:
1 | import pandas as pd |