Arxiv今日论文 | 2026-01-06
本篇博文主要内容为 2026-01-06 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-06)
今日共更新820篇论文,其中:
自然语言处理共109篇(Computation and Language (cs.CL))
人工智能共258篇(Artificial Intelligence (cs.AI))
计算机视觉共206篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共247篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Robust Persona-Aware Toxicity Detection wit ...
Arxiv今日论文 | 2026-01-05
本篇博文主要内容为 2026-01-05 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-05)
今日共更新381篇论文,其中:
自然语言处理共49篇(Computation and Language (cs.CL))
人工智能共100篇(Artificial Intelligence (cs.AI))
计算机视觉共82篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共104篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Geometry of Reason : Spectral Signatures of V ...
Arxiv今日论文 | 2026-01-01
本篇博文主要内容为 2026-01-01 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-01)
今日共更新606篇论文,其中:
自然语言处理共87篇(Computation and Language (cs.CL))
人工智能共179篇(Artificial Intelligence (cs.AI))
计算机视觉共124篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共176篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Scaling Open-Ended Reasoning to Predict the ...
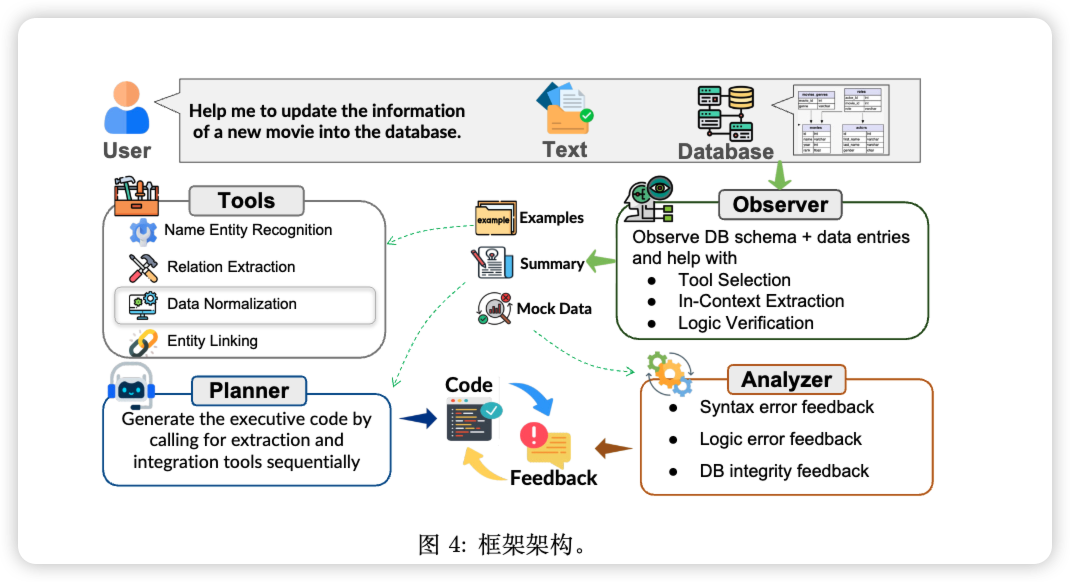
TEXT2DB:Integration-Aware Information Extraction with Large Language Model Agents
这篇来自伊利诺伊大学香槟分校(UIUC)顶级数据与自然语言处理实验室的论文,《TEXT2DB: Integration-Aware Information Extraction with Large Language Model Agents》,表面上看是在谈论一个技术问题,但实际上,它揭示了我们在与AI协作时一个长期被忽视却至关重要的瓶颈。
现在,让我们一起为这篇“硬核”的学术论文,搭建一座通往大众理解的“阶梯”。
AI不仅要会“读书”,更要会“归档”:一项研究正在教会AI如何成为你真正的数据库助理
想象一下,你刚雇佣了一位绝顶聪明的实习生。他阅读速度惊人,过目不忘,你让他去阅读成堆的行业报告、新闻稿和客户邮件,他总能精准地抓取出所有关键信息——新产品的发布日期、竞争对手的最新动态、重要人物的履历……
然而,当你让他把这些信息更新到公司的数据库里时,灾难发生了。他直接把一堆杂乱无章的笔记丢了过来:有的日期是“2025年11月2日”,有的则是“Nov. 2, 2025”;他把“CEO”的名字放进了“联系人”一栏;更糟糕的是,他为一个已经存在的客户创建了一条全新的记录,导致数据完全重复 ...
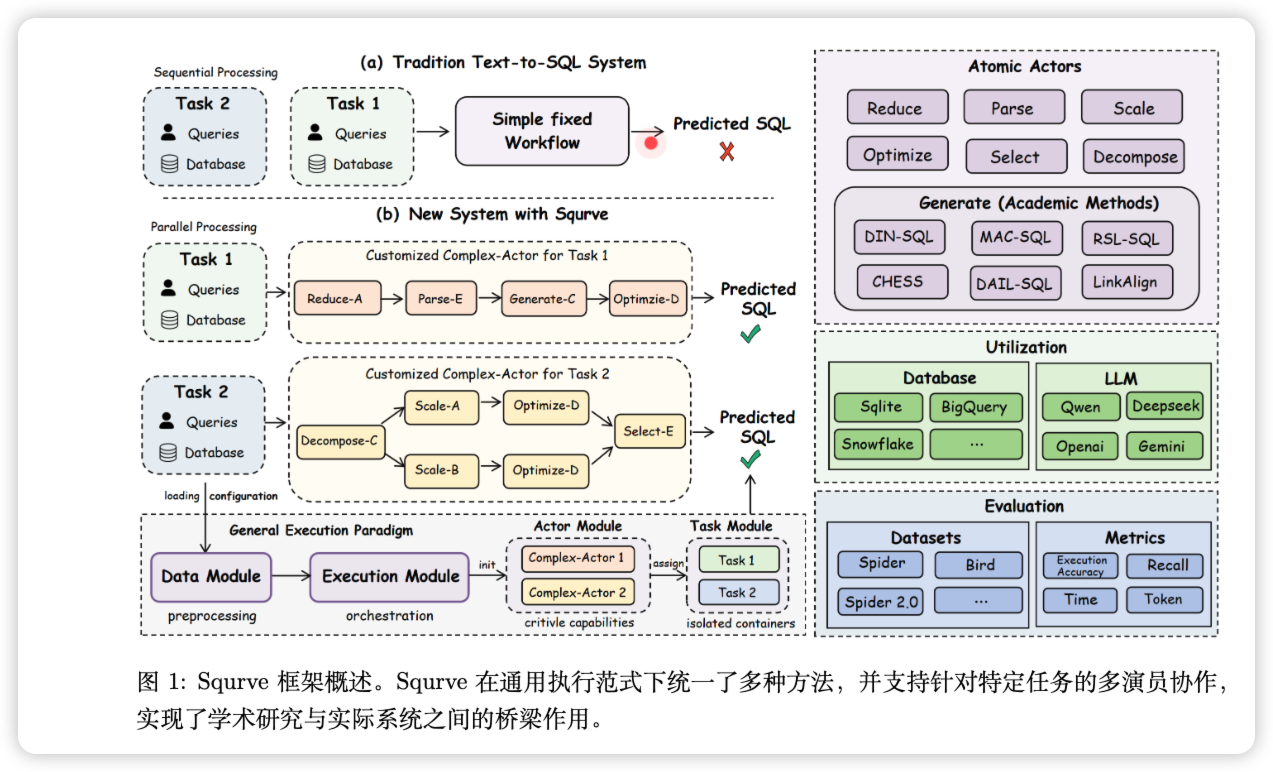
Squrve:A Unified and Modular Framework for Complex Real-World Text-to-SQL Tasks
为什么Text-to-SQL技术始终"差临门一脚"?
想象一下这个场景:你是一位市场分析师,老板走过来说:"帮我查一下上个季度华东地区销售额超过100万的客户,按成交金额倒序排列。"如果你懂SQL,可能几分钟就搞定了。但如果你不懂呢?
这正是"Text-to-SQL"技术想解决的问题——让普通人用自然语言就能和数据库对话,就像跟Siri聊天一样简单。
过去几年,这个领域的学术论文如雨后春笋般涌现。DIN-SQL、CHESS、MAC-SQL……一个个方法在学术评测榜单上你追我赶,准确率不断刷新。但奇怪的是,当企业真的想把这些"学术明星"部署到实际系统中时,却常常遭遇水土不服。
问题出在哪儿?来自中国人民大学、对外经贸大学和浙江工业大学的研究团队,最近发布了一个名为Squrve的框架,不仅指出了症结所在,还提供了一个极具实用价值的解决方案。
学术研究的"碎片化困境"
让我们先理解问题的根源。
学术界喜欢"专精"——每篇论文往往聚焦于Text-to-SQL流程中的某一个环节 ...

LangGraph 子图(Subgraph):概念总结与代码验证
本文面向已经了解 LangGraph 基本用法的读者,系统梳理“子图(Subgraph)”这一重要能力,并在官方示例基础上补充选型建议、最佳实践与运行验证指引,帮助你在真实项目中更好地拆分与复用复杂工作流。
主要内容
子图的设计意图:将一段可复用、可独立演进的工作流,作为“节点”嵌入父图,达到解耦与复用。
两种通信模式的差异与边界:共享状态模式 vs 不同状态模式,如何在接口、耦合度与可维护性间权衡。
如何编译与调用子图:作为节点直接接入,或通过 invoke 转换输入/输出。
如何在调试与可观测性上做得更好:通过带前缀的日志与 subgraphs=True 的流式事件观察调用链路。
两种通信模式速览
共享状态模式:父图与子图的状态模式中存在相同键(如 messages、foo),子图可直接读写共享键;适合“轻封装、高耦合”的复用场景(例如多智能体共享会话)。
不同状态模式:父图与子图没有共享键,需要在父图的节点函数中进行“输入映射 → 子图调用 → 输出映射”;适合“强封装、低耦合”的子系统(例如各 Agent 拥有私有记忆/上下文)。
何时使用子图
多智能体协作:将每个智 ...

Dify
68d4c704ab608d783d8a8a5d59eda75a87edb4142e54b5833dd4933ea86f97dfc57d4fccf0a24157a2245041e4c81ba0cab66c0cefce8e9167aaa5d4963ccad8f5454d1a12d66642fc27e7da97bacbbe738cf0161727b36d35eb66c63865f28dc90bf2f0c7f8fe85c485a71ca6c4f084c36a29f6f28e6a6b8d2201acdaf146d2738738c80cc37f917b7a13420b4afffad721fbb9ddc6ad49d2ba97ee44aad0aa665b019e6c15d9f5c2d187f1ac1ad6041e9b317af62117870b9ad064c0f4a1200c520ec53b5a018d6860fad37bb9ef426e58b251203159a3d5b63c65009faa6466380d127ae63ce72e64ce8a1d404e82d6d9bbc2ffcda4f28 ...
临时文件中转
68d4c704ab608d783d8a8a5d59eda75a4b54b9d740763213a70ec61ee61039f285f2ce797538bc4a5a6bc59a140b41cef1f3550d48f4fa7202ff3ee90b06ab906fe6b1097df534a7b201a4eda8ea6a5ac9c44941fb1a801a19e38013d1929558b00a2a668efa8c9fb5ac83edd7c186ea0f1e5f349a7144cf40af50e33e663bd16b6d20f7409065339647c8744b9679fc926d5f7662fa295d3c7bf93f4d4324acf725103207e683f2c8b5ad035ddca41b302456f36062c13ba017aa2f8f767784906bff4000044c3ee35d999dc7bb01cbba9dc76b56a70c6a1d5848751b72eefcd823bb3df8eeea1ee5d5986222021b7ebb6ae24ce6a9f4496 ...

26条Prompt参考
论文介绍了26条指导原则,目标是简化为不同规模的大语言模型制定问题的概念,检验它们的能力,并增强用户对于不同规模的模型在接受不同提示时的行为理解。研究者在LLaMA-1/2(7B、13B和70B)和GPT-3.5/4上进行了广泛实验,以验证这些原则在指令和提示设计上的有效性。
论文中指出:大语言模型如ChatGPT在多个领域和任务中展现出卓越的能力,但在普通用户设计最优指令或提示时,它们的应用和使用有时可能并不清晰。而他们的工作是为开发人员或普通用户揭示与LLMs询问和交互时时“神秘的黑盒”,并通过简单地策划更好的提示来进一步提高预训练LLMs的响应质量。研究团队提出了26条用于LLM提示的原则,接下来让我们一起来看看吧~
论文地址:https://arxiv.org/pdf/2312.16171.pdf
26条原则
不需要对LLM客气,因此无需使用诸如"请",“如果您不介意”,“谢谢您”,"我想要"等短语,直接切入主题。
在提示中融入预期的受众群体,例如,假设受众是该领域的专家。
将复杂的任务拆分为一系列简单的提示,在交互式对话中逐步进行 ...

使用LoRA(低秩自适应)微调LLM的实用技巧
增加数据量和模型的参数量是公认的提升神经网络性能最直接的方法。目前主流的大模型的参数量已扩展至千亿级别,「大模型」越来越大的趋势还将愈演愈烈。
这种趋势带来了多方面的算力挑战。想要微调参数量达千亿级别的大语言模型,不仅训练时间长,还需占用大量高性能的内存资源。
为了让大模型微调的成本「打下来」,微软的研究人员开发了低秩自适应(LoRA)技术。LoRA 的精妙之处在于,它相当于在原有大模型的基础上增加了一个可拆卸的插件,模型主体保持不变。LoRA 随插随用,轻巧方便。
对于高效微调出一个定制版的大语言模型来说,LoRA 是最为广泛运用的方法之一,同时也是最有效的方法之一。
如果你对开源 LLM 感兴趣,LoRA 是值得学习的基本技术,不容错过。
上个月,我分享了一篇有关 LoRA 实验的文章,主要基于我和同事在 Lightning AI 共同维护的开源 Lit-GPT 库,讨论了我从实验中得出的主要经验和教训。此外,我还将解答一些与 LoRA 技术相关的常见问题。如果你对于微调定制化的大语言模型感兴趣,我希望这些见解能够帮助你快速起步。
简而言之,我在这篇文章中讨论的主要要点包含:
虽 ...