由于 LLM 巨大的 GPU 内存开销和计算成本,在大多数应用中,机器学习工程师通常通过内部调整(如量化和对 CUDA 核的定制)来优化。然而,由于 LLM 通过迭代生成其输出,并且 LLM 推理通常涉及内存而不是计算,因此在很多实践中,优化系统级批处理可以使性能差异达到10倍甚至更多。
一种最近提出的优化方法是连续批处理(Continuous batching),也称为动态批处理或基于迭代级的批处理。其具有如下惊人的效果:
- 基于vLLM,使用连续批处理和连续批处理特定的内存优化,可以实现多达23倍的吞吐量提升;
- 对于 HuggingFace 本地生成推理,使用连续批处理,可以实现8倍的吞吐量提升;
- 基于 NVIDIA 的 FasterTransformer,使用优化过的模型实现,可以实现4倍的吞吐量提升。
本博客接下来将详细介绍相关技术的细节。
LLM推理
LLM 推理是一个迭代过程,在每个新前馈循环后获得一个额外的完成标记。例如,如果您提示一个句子"What is the capital of California:",它需要进行十次前馈循环才能得到完整的回答[“S”,“a”,“c”,“r”,“a”,“m”,“e”,“n”,“t”,“o”]。
如下图所示:
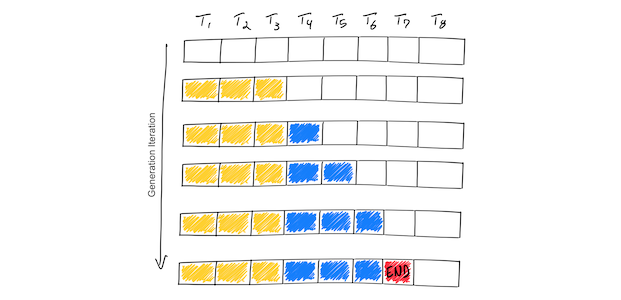
上图示例显示了一个支持最大序列长度为8个标记(T1,T2,…,T8)的假设模型。从 Prompt(黄色)开始,迭代过程逐个生成一个标记(蓝色)。一旦模型生成了一个结束序列标记(红色),生成循环停止。这个例子显示了仅包含一个输入序列的 Batch,因此 Batch 大小为1。
现在,我们已经了解了 LLM 推理的迭代过程,接下来我们来探讨一些不熟悉的事情:
- LLM 推理是内存 IO 限制,而不是计算限制。换句话说,目前加载 1MB 的数据到 GPU 所需的时间比 1MB 的数据在GPU上计算所需的时间长。这意味着 LLM 推理的吞吐量很大程度上取决于您能将多少批数据装入到高速GPU 内存中;
当作者提到LLM推断是内存-IO受限而不是计算受限时,意味着在LLM推断过程中,主要的瓶颈并不在于计算速度,而在于数据的传输速度,特别是从主内存加载数据到GPU内存的过程。
这对LLM推断的吞吐量有着重要的影响。具体来说,由于数据传输速度相对较慢,如果我们可以减少需要从主内存加载到GPU内存的次数,就能提高推断的效率,从而提高吞吐量。
GPU内存在这里起到了关键的作用。它是临时存储模型参数、输入数据和计算结果的地方。在LLM推断过程中,模型参数需要在GPU内存中保留,同时输入数据也需要被加载到GPU内存中才能进行计算。因此,GPU内存的大小限制了我们可以处理的数据量以及批次的大小。
总的来说,GPU内存的充足与否直接影响了LLM推断的性能和吞吐量。如果我们能够优化内存的使用,比如通过模型量化策略或其他方法减少内存占用,就能提升推断效率,从而实现更高的吞吐量。
- GPU 内存的消耗量随着基本模型大小和标记长度的增加而增加。如果我们将序列长度限制为 512,那么在一个批处理中,我们最多只能处理28个序列;一个序列长度为 2048 则批处理大小最多只能为7个序列。需要注意的是,这只是一个上限,因为中间计算结果没有留下存储的空间。
这意味着优化内存使用有很多余地。这就是为什么像 AutoGPTQ 这样的模型量化策略具有如此强大的力量的原因;如果您可以将内存使用量减半,您将能够为更大的批处理提供更多的空间。然而,并不是所有的策略都需要对模型权重进行修改。例如,FlashAttention 通过重新组织注意计算来减少内存IO,从而发现显著的性能提升。
模型量化策略:例如AutoGPTQ,它可以通过将模型权重从16位减少到8位表示,从而减少内存使用,为更大批处理提供了更多空间。
连续批处理是另一种内存优化技术,它不需要对模型权重进行修改。接下来,我们解释一下连续批处理如何工作,以及如何提高LLM生成过程的内存效率。
朴素批处理与静态批处理
我们称这种传统的批处理方法为静态批处理,因为批大小在推理完成之前保持不变。以下是LLM推理中静态批处理的示意图:
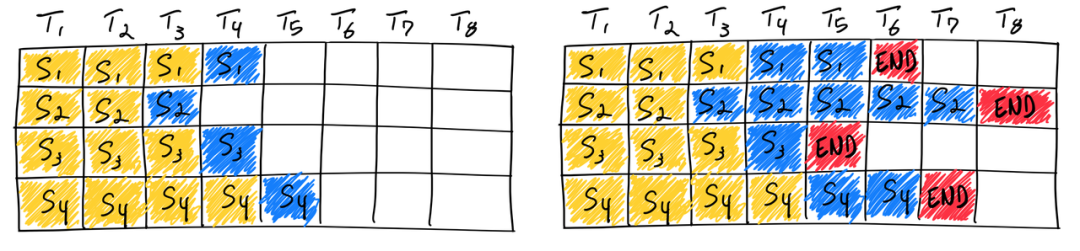
如上图所示,在第一遍迭代(左)中,每个序列从提示词(黄)中生成一个标记(蓝色)。经过几轮迭代(右)后,完成的序列具有不同的尺寸,因为每个序列在不同的迭代结束时产生不同的结束序列标记(红色)。尽管序列3在两次迭代后完成,但静态批处理意味着 GPU 将在批处理中的最后一个序列完成。
与传统深度学习模型不同,LLM 的批处理方法比较复杂,因为其推理是迭代性的。直观上,这是因为请求可能提前完成,但是释放其资源并添加可能处于不同完成状态的新请求是棘手的。这意味着,随着 GPU 在批次中不同序列的生成长度与最大生成长度不同而未充分利用。在上面的右图,这通过序列1、3和4的序列末标记后的白色方块来说明。
静态批处理不充分利用GPU的频率是多少?这取决于批次中序列的生成长度。例如,可以使用LLM推断来发射单个标记作为分类任务(有更好的方法可以做到这一点,但让我们以此为例)。在这种情况下,每个输出序列具有相同的大小(1个标记)。如果输入序列也具有相同的大小(例如,512个标记),则每个静态批次将实现最佳的GPU利用率。
另一方面,LLM 驱动的聊天机器人服务不能假定固定长度的输入序列,也不能假定固定长度的输出序列。在撰写本文时,专有模型提供的最大上下文长度超过8K个标记。使用静态批处理,生成输出的变化可能会导致GPU严重未充分利用。难怪OpenAI首席执行官Sam Altman称计算成本高得惊人。
如果没有对用户输入和模型输出的限制假设,未经优化的生产级 LLM 系统无法充分利用 GPU 并导致不必要的较高成本。
连续批处理
行业意识到这种批处理的低效性,并提出了更有效的解决方案。OSDI 2022 上发表的 Orca: A Distributed Serving System for Transformer-Based Generative Models 是第一篇解决这个问题的论文。它采用了迭代级调度,其中批大小根据每次迭代确定。结果是,一旦批中的一个序列完成生成,就可以在其位置插入一个新的序列,从而实现比静态批处理更高的GPU利用率。
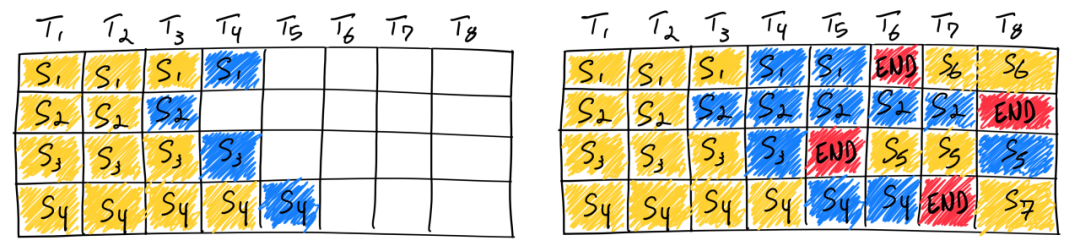
如上图所示,使用连续批处理完成七条序列。左图显示了单个迭代后的批,右图显示了多次迭代后的批。一旦一个序列产生结束序列标记,我们在其位置插入新的序列(即序列S5、S6和S7)。这实现了更高的 GPU 利用率,因为 GPU 不需要等待所有序列完成才开始新的一个。
现实情况比这个简化模型更复杂:因为预填充阶段需要计算,并且与生成阶段的计算模式不同,因此它不能很容易地与令牌的生成一起进行批量。连续批处理框架目前通过超参数来管理这个问题:等待已服务比和等待结束序列标记的请求比(waiting_served_ratio)。
目前,HuggingFace 已经将连续批处理作为他们的基于 Rust 和 Python 的文本生成推理服务器的生产版本。我们使用他们的实现来了解连续批处理在 benchmarks 中的性能特征。
实验验证
我们旨在了解连续批量处理与静态批处理在模拟实时推理工作负载上的表现。本质上,我们关心成本。我们将成本分解为吞吐量(Throughput)和延迟(Latency)这两个指标,因为成本直接取决于您在给定延迟下以多高效的方式提供服务的程度。
我们在一个 NVIDIA A100 GPU 上进行吞吐量(Throughput)和延迟(Latency)的基准测试。我们的 A100 有 40GB 的 GPU 内存。我们选择了 Meta的OPT-13B 模型,因为每个测试框架都与此模型配合良好。我们选择了 13B变体,因为它既不需要张量并行,又足够大以产生内存效率挑战。我们选择不使用张量并行,尽管静态批处理和连续批处理都可以使用张量并行。
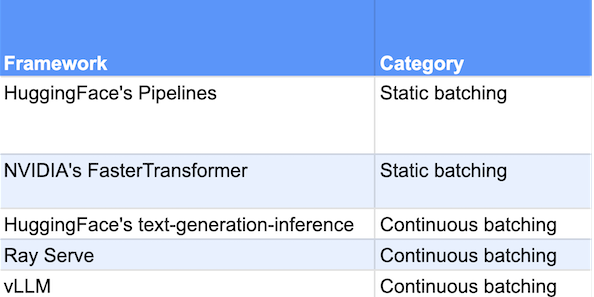
我们测试了两种静态批处理框架和三种连续批处理框架,他们分别是:
吞吐量测试结果
根据我们对静态批处理的了解,我们猜测在序列长度波动较大的每个批次中,连续批处理的表现会显著更好。为了证明这一点,我们针对每个框架分别运行我们的吞吐量基准测试4次,每次在具有更高序列长度波动的数据集上进行。
为了做到这一点,我们创建了一个包含 1000 个序列,每个序列具有 512 个输入标记的数据集。我们通过忽略端尾标记并设置最大标记配置来始终生成每个请求的序列长度。然后我们生成 1000 个生成长度,每个请求都来自一个由均值为 128 的指数分布产生的样本。我们使用指数分布,因为它是对像 ChatGPT 这样的应用程序中可能遇到的生成长度的一个好近似。为了改变每个运行的方差,我们仅选择小于或等于 32、128、512 和 1536 的样本。总输出序列长度最多为 512+32=544、512+128=640、512+512=1024 和 512+1536=2048。
然后我们使用一个简单的基准测试脚本向我们的模型服务器提交 HTTP 请求。基准测试脚本以突发方式提交所有请求,使计算饱和。
结果如下:
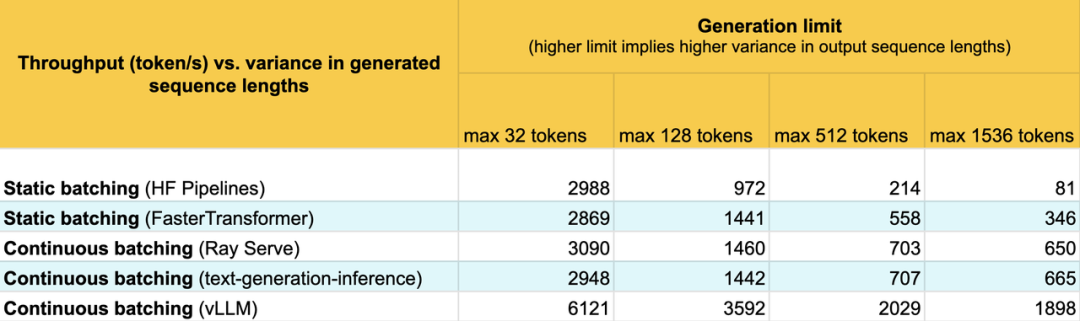
可以看到,静态批处理和朴素连续批处理在较低的序列长度波动下表现大约相同。然而,随着方差增加,静态批处理的性能显著下降,直到生成长度达到 1536 时,性能下降至 81 个字符/秒。FasterTransformers 在静态批处理方面的表现明显优于静态批处理,几乎与连续批处理保持同步,直到生成长度达到 1536。
令人印象深刻的在这里的是vLLM。对于每个数据集,vLLM的性能是朴素连续批处理的两倍以上。我们尚未分析vLLM 性能中优化贡献最大是什么,但我們怀疑 vLLM 动态预留空间的能力,而不是提前预留空间,使得 vLLM 可以显著增加批量大小。
我们将这些性能结果相对静态批处理的关系绘制出来:

需要注意的是,FasterTransformer 的4倍改进虽然令人印象深刻,但我们非常感兴趣在 NVIDIA 实现它时进行基准测试。然而,即使使用优化后的模型,连续批处理在静态批处理方面仍然具有显著的改进。如果您像 vLLM 一样采用连续批处理和迭代级调度来实现进一步的内存优化,性能差距就会变得非常巨大。
延时测试结果
类似地,我们在一个真实的用例上进行延迟-吞吐量权衡优化。我们对每个框架进行基准测试,并测量随着每个框架的累积分布函数(CDF)的变化,该函数如何随着每个框架的部署而变化。
与吞吐量基准测试相同,我们配置模型以始终生成指定数量的每个请求的标记。我们通过从1个标记到512个标记的均匀分布中采样长度来准备100个随机的提示。我们通过从均值为128且最大大小为1536的指数分布中采样100个输出长度来进行预测。这些数字之所以选择,是因为它们在现实世界中是合理的,并允许生成器充分利用我们模型的全部上下文长度(512+1536=2048)。
我们没有像在吞吐量基准测试中那样同时提交所有请求。而是通过预先延迟每个请求一定的时间来进行基准测试。我们通过泊松分布来确定每个请求提交后等待多长时间。泊松分布由λ和预期率(即每秒击中模型端点的查询数量)进行参数化。我们测量在 QPS 为1和 QPS 为4时的延迟,以了解随着负载的变化,延迟分布如何变化。
结果如下:

可以看到,在提高吞吐量的同时,连续批处理系统也改善了中位数延迟。这是因为连续批处理系统允许在有空间的情况下,将新的请求添加到现有的批次中。但是,其他百分位数呢?事实上,我们发现它们在所有百分位数上都改善了延迟:
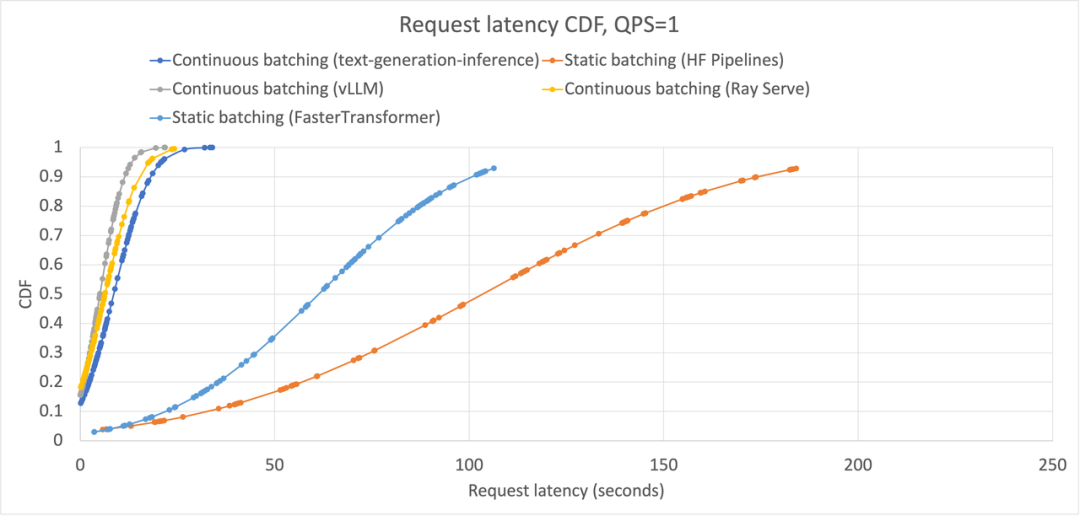
QPS=1时,每个框架的生成请求中累积分布函数(CDF)的形状都有所不同,这是由于连续批处理系统中的迭代级批调度导致的。所有连续批处理在 QPS=1 时表现约等于静态批处理;与静态批处理相比,FasterTransformers 的表现明显更好。
连续批处理改善所有百分位数的延迟的原因与改善 p50 的延迟原因相同:新的请求可以添加,而不管其他序列在生成批次中多远。然而,与静态批处理一样,连续批处理仍然受到 GPU 可用空间的限制。随着您的服务系统接收到的请求数量饱和,即平均批量大小更高,那么在收到新请求时,立即在 GPU 上注入新请求的机会就越少。我们可以看到,随着平均QPS增加到4,这一点变得更加明显:
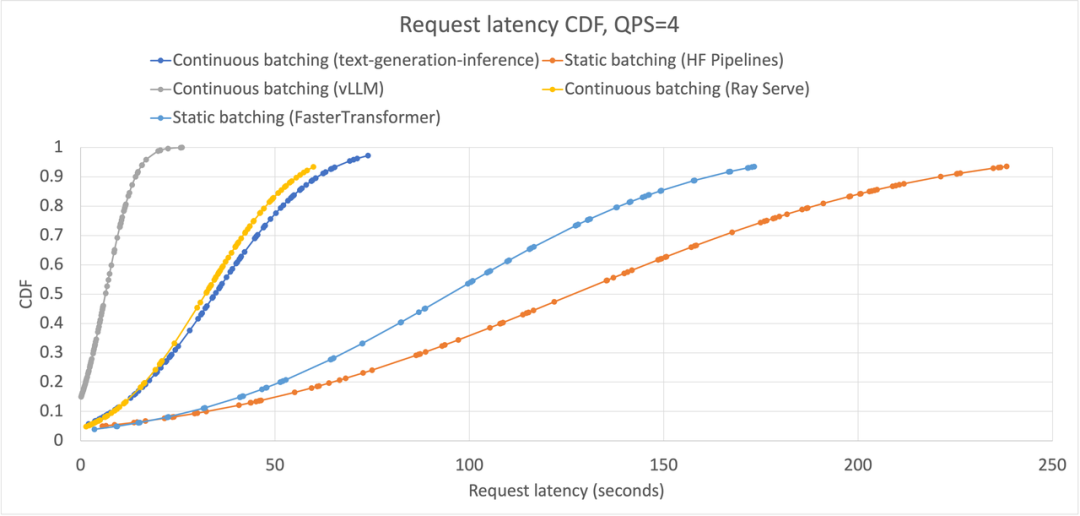
QPS=4 时,每个框架的生成请求中累积分布函数(CDF)的形状与 QPS=1 时的情况相似,FasterTransformer 的分布与静态批处理的分布相似。然而,与 QPS=1 相比,FasterTransformer 的曲线更接近于静态批处理,而 text-generation-inference 和 Ray Serve 的连续批处理实现与 FasterTransformer 的曲线相似,但明显不如 vLLM。
我们观察到,随着系统的饱和,FasterTransformer 变得更加接近于静态批处理,而 text-generation-inference 和 Ray Serve 的连续批处理实现正在朝着与 FasterTransformer 的曲线相似的方向发展。换句话说,随着系统的饱和,立即在 GPU 上注入新请求的机会更少,因此请求延迟上升。这与 vLLM 的曲线相吻合:在 QPS=1 和 QPS=4 之间,它的最大批量大约增加了 1500 个token。
总结
LLMs 具有令人惊叹的功能,我们相信其影响仍有很大的发掘空间。我们已经分享了如何使用一种新的服务技术:连续批处理,以及它如何超越静态批处理。它通过减少浪费安排新请求的机会来提高吞吐量,并能够立即将新请求注入计算流中来改善延迟。我们期待人们如何利用连续批处理,以及这个行业将从此走向何方。







