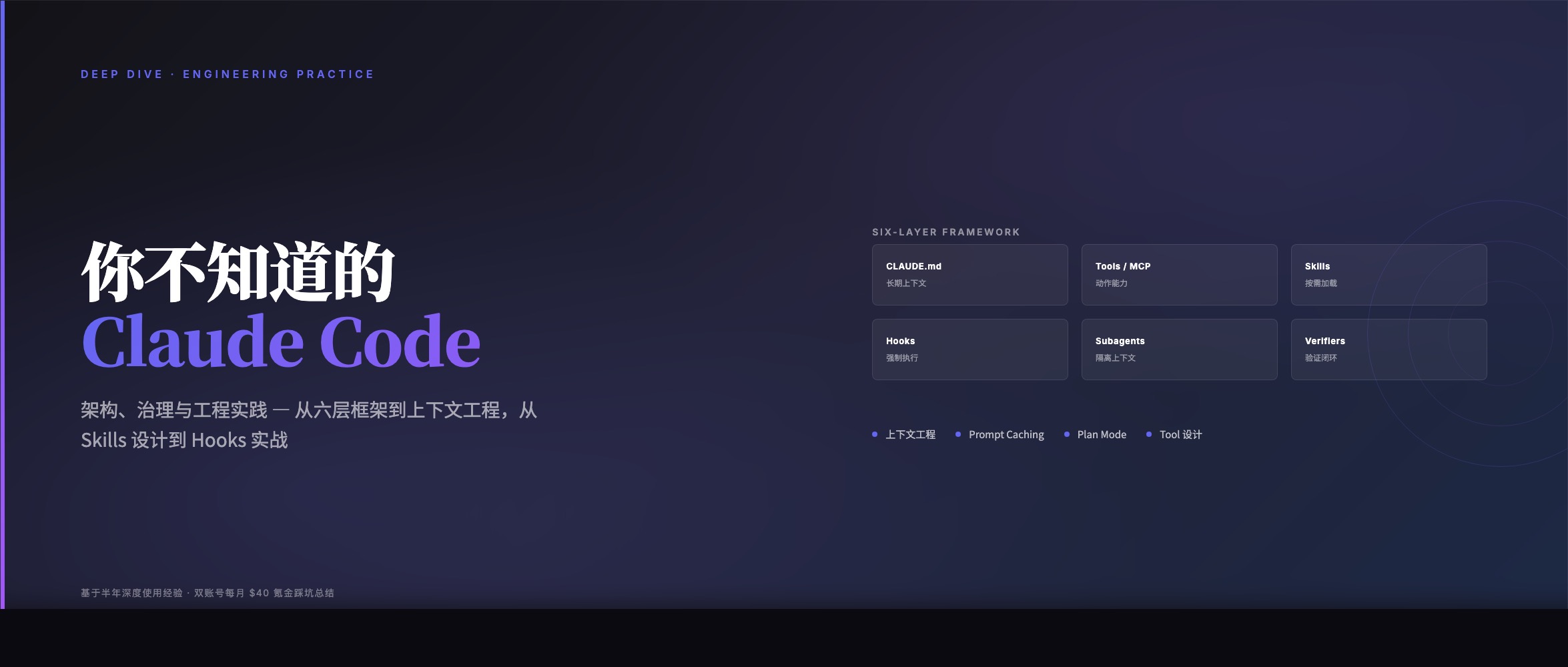
Arxiv今日论文 | 2026-01-19
本篇博文主要内容为 2026-01-19 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-19)
今日共更新404篇论文,其中:
自然语言处理共68篇(Computation and Language (cs.CL))
人工智能共101篇(Artificial Intelligence (cs.AI))
计算机视觉共64篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共105篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] How Long Is a Piece of String? A Brief Empiri ...
Arxiv今日论文 | 2026-01-16
本篇博文主要内容为 2026-01-16 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-16)
今日共更新514篇论文,其中:
自然语言处理共101篇(Computation and Language (cs.CL))
人工智能共168篇(Artificial Intelligence (cs.AI))
计算机视觉共80篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共117篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] MatchTIR: Fine-Grained Supervision for Tool- ...
Arxiv今日论文 | 2026-01-15
本篇博文主要内容为 2026-01-15 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-15)
今日共更新457篇论文,其中:
自然语言处理共93篇(Computation and Language (cs.CL))
人工智能共146篇(Artificial Intelligence (cs.AI))
计算机视觉共95篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共104篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Value-Aware Numerical Representations for Tra ...
Arxiv今日论文 | 2026-01-14
本篇博文主要内容为 2026-01-14 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-14)
今日共更新528篇论文,其中:
自然语言处理共91篇(Computation and Language (cs.CL))
人工智能共189篇(Artificial Intelligence (cs.AI))
计算机视觉共121篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共133篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Modeling LLM Agent Reviewer Dynamics in El ...
Arxiv今日论文 | 2026-01-13
本篇博文主要内容为 2026-01-13 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-13)
今日共更新1014篇论文,其中:
自然语言处理共190篇(Computation and Language (cs.CL))
人工智能共358篇(Artificial Intelligence (cs.AI))
计算机视觉共175篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共259篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Reference Games as a Testbed for the Align ...
Arxiv今日论文 | 2026-01-12
本篇博文主要内容为 2026-01-12 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-12)
今日共更新385篇论文,其中:
自然语言处理共82篇(Computation and Language (cs.CL))
人工智能共120篇(Artificial Intelligence (cs.AI))
计算机视觉共62篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共111篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] AdaFuse: Adaptive Ensemble Decoding with Test ...
Arxiv今日论文 | 2026-01-09
本篇博文主要内容为 2026-01-09 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-09)
今日共更新591篇论文,其中:
自然语言处理共136篇(Computation and Language (cs.CL))
人工智能共238篇(Artificial Intelligence (cs.AI))
计算机视觉共98篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共151篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] GDPO: Group reward-Decoupled Normalization P ...
Arxiv今日论文 | 2026-01-08
本篇博文主要内容为 2026-01-08 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-08)
今日共更新516篇论文,其中:
自然语言处理共131篇(Computation and Language (cs.CL))
人工智能共177篇(Artificial Intelligence (cs.AI))
计算机视觉共88篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共137篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] All That Glisters Is Not Gold: A Benchmark f ...
Arxiv今日论文 | 2026-01-07
本篇博文主要内容为 2026-01-07 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-07)
今日共更新474篇论文,其中:
自然语言处理共108篇(Computation and Language (cs.CL))
人工智能共154篇(Artificial Intelligence (cs.AI))
计算机视觉共80篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共105篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Automated Semantic Rules Detection (ASRD) fo ...
Arxiv今日论文 | 2026-01-06
本篇博文主要内容为 2026-01-06 从Arxiv.org论文网站获取的最新论文列表,自动更新,按照NLP、CV、ML、AI、IR五个大方向区分,若需要邮件定时接收,请在评论区留下你的邮箱号。
说明:每日论文数据从Arxiv.org获取,每天早上12:00左右定时自动更新。
友情提示: 如何您需要邮箱接收每日论文数据,请在评论处留下你的邮箱。
目录
概览
自然语言处理CL
人工智能AI
机器学习LG
计算机视觉CV
信息检索IR
概览 (2026-01-06)
今日共更新820篇论文,其中:
自然语言处理共109篇(Computation and Language (cs.CL))
人工智能共258篇(Artificial Intelligence (cs.AI))
计算机视觉共206篇(Computer Vision and Pattern Recognition (cs.CV))
机器学习共247篇(Machine Learning (cs.LG))
自然语言处理
[NLP-0] Robust Persona-Aware Toxicity Detection wit ...