
ChatGPT提示快速指南
How Prompt Engineering Works
Rules of Thumb and Examples
Rule #1 – Instructions at beginning and ### or “”" to separate instructions or context
Rule #2 – Be specific and detailed about the desired context, outcome, length, format, and style.
Rule #3 – Give examples of desired output format
Rule #4 – First try without examples, then try giving some examples.
Rule #5 – Fine-tune if Rule #4 doesn’t work
Rule #6 – Be specific. Omit needless words.
Rule #7 – Use leading words to nudge the ...

为什么现在大家都在用 MQA 和 GQA?
GPT,也就是 Transformer Decoder 结构做文本生成时有一个致命问题。先来看看 Encoder 推理是怎么做的,每个 timestep 都能看到所有 timestep ,推理时所有 timestep 一层层向后计算,一把过。于是内存相关开销就是O(N)O(N)O(N) , 而计算相关开销就是O(N2)O(N^2)O(N2) ,其中 N 为序列长度。
而 Decoder 推理时,最大不同在于自回归结构,可以看到图中每个 timestep 的输出都是下一 timestep 的输入,所以无法像 Encoder 一样一次过,每次都要 attend 之前的所有 timestep.
同样计算一下开销,计算开销是 1+(1+2)+(1+2+3)+...+(1+2+...+n)1+(1+2)+(1+2+3)+...+(1+2+...+n)1+(1+2)+(1+2+3)+...+(1+2+...+n) 也就是O(N3)O(N^3)O(N3) ,而内存开销则是 O(N2)O(N^2)O(N2).
大家用 ChatGPT 接口也会有类似感觉,Context 部分成本很低,也很快,因为它做 ...

构建高性能Prompt之路——结构化Prompt
我算是最早在国内提结构化、模板化编写大模型 Prompt 范式的人之一。2023 年 4 月在我自己的个人实践中发现这种结构化、模板化的方式对编写 prompt 十分友好,并且在大多数时候都表现不俗。2023 年 5 月份我将这种方法开源成 LangGPT 项目并在国内写文公开,受到了许多人的认可和喜爱,尤其在 GitHub、即刻、知乎等社区都有不小的反响。由于结构化 Prompt 的出色性能表现,很多朋友都开始在实践中应用这种方法写 Prompt ,其中不乏许多来自网易字节等互联网大厂的朋友。
虽然结构化 prompt 的思想目前已经广为传播并应用,但是缺乏全面系统的资料。虽然也有许多解读文章传播,但内容质量良莠不齐,并且知识也较为破碎。于是写作本文,希望能成为一篇较为系统的高质量的结构化 Prompt 论述文章,为学习 Prompt 编写的朋友提供一些参考借鉴。
什么是结构化 Prompt ?
结构化的思想很普遍,结构化内容也很普遍,我们日常写作的文章,看到的书籍都在使用标题、子标题、段落、句子等语法结构。结构化 Prompt 的思想通俗点来说就是像写文章一样写 Prompt。
为 ...

QLORA:Efficient Finetuning of Quantized LLMs
本文提出了一种高效微调方法QLoRA,通过量化减少显存使用,实现了在单个48G GPU上对65B模型进行微调,仅仅需要在单个GPU上训练24小时就能达到ChatGPT 99.3%的效果。QLoRA引入多项创新,在不牺牲效果的情况下,显著降低了显存占用量:
4-bit NormalFloat(NF4)数据类型
双重量化:Double Quantization
分页优化器:Paged Optimizer。
论文地址: https://arxiv.org/pdf/2305.14314.pdf
代码地址: https://github.com/artidoro/qlora
微调大型语言模型 (LLM) 是提高其性能的一种非常有效的方法。然而,微调非常大的模型非常昂贵; LLAMA 65B 参数模型的常规 16 位微调需要超过 780 GB 的 GPU 内存。虽然最近的量化方法可以减少LLM的内存占用,但这种技术只适用于推断,在训练过程中还是会出现因为资源问题导致训练失败。
本文提出QLoRA方法只要是使用一种新的高精度技术将预训练模型量化为int4,然后添加一小组可学习的低秩适配器权重 ...

问答系统使用 Embedding 召回的局限及解决方案
近期LangChain[1] + LLM 方案高速发展,降低了知识问答等下游应用的开发门槛。但随着业务深入,一些局限性也日渐显露,比如:LLM 意图识别准确性较低,交互链路长导致时间开销大;Embedding 不适合多词条聚合匹配等。本文结合实际案例,分析上述问题存在的根源,并提出基于传统 NLP 技术的解决思路。
背景
以 LLM 为基础的知识问答系统构建方法核心在于:
将用户问题和本地知识进行 Embedding,通过向量相似度(Vector Similarity)实现召回;
通过 LLM 对用户问题进行意图识别;并对原始答案加工整合。
2023 年初 ChatGPT 声名鹊起之时,下游生态链不是很完善,业界一般通过 OpenAI API 和 ChatGPT 直接交互,缺陷也很明显:
上层应用和模型基座绑死。切换模型基座时,上层逻辑不得不大量修改。在 LLM 蓬勃发展的当下,无论是处于成本、License、研究热点还是性能等各方面考虑,基座变更几乎不可避免。
处理环节不完善,开发成本高。比如:向量存储和搜索,LLM 提示词生成,数据链路(导入、分片、加工)等等。如果全部手撸, ...

在单个GPU上基于QLoRA微调LLaMA2模型
2023年7月18日,Meta发布了LLaMA2-最新版本大型语言模型(LLM)。LLaMA2训练使用了2万亿个Tokens,在许多基准测试中(包括推理、编码、熟练度和知识)测试效果优于其他LLM,包括。此次发布有不同的版本,参数大小为7B、13B和70B。这些模型可供商业和研究用途免费使用。
为了满足各种文本生成需求并对这些模型进行微调,我们将使用QLoRA (Efficient Finetuning of Quantized LLMs,这是一种高效的微调技术,它将预训练的LLM量化为仅4位,并添加了小的“低秩适配器”。这种独特的方法可以只使用单个GPU对LLM进行微调!并且PEFT库已支持QLoRA方法。
相关依赖
要成功微调LLaMA 2模型,您需要以下内容:
填写Meta的表格以请求访问下一个版本的Llama。事实上,使用Llama 2受Meta许可证的管理,您必须接受该许可证才能下载模型权重和分词器。
拥有Hugging Face账户(使用与Meta表单中相同的电子邮件地址)。
拥有Hugging Face令牌。
访问LLaMA 2可用模型(7B、13B或70B版本)的页面 ...
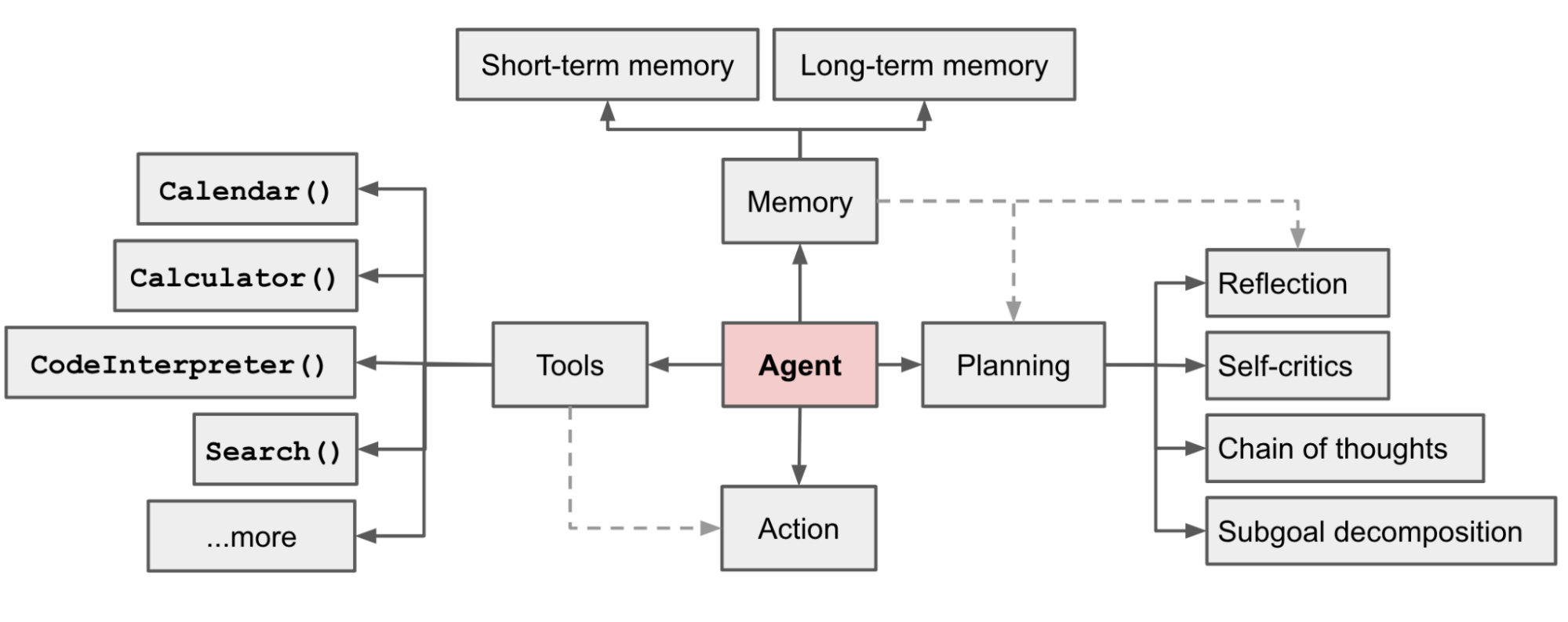
使用LLM构建AI Agents的正确姿势
以LLM(大语言模型)作为核心控制器构建智能体是一个很酷的概念。AutoGPT、GPT-Engineer和BabyAGI等几个概念验证演示都是鼓舞人心的示例。LLM的潜力不仅仅限于生成写得好的副本、故事、论文和程序;它可以被视为一个强大的通用问题解决器。
智能体系统概述
在 LLM 支持的自主智能体系统中,LLM 充当智能体的大脑,并由几个关键组件进行补充:
规划
子目标和分解:智能体将大型任务分解为更小的、可管理的子目标,从而能够有效处理复杂的任务。
反思和完善:智能体可以对过去的行为进行自我批评和自我反思,从错误中吸取教训,并针对未来的步骤进行完善,从而提高最终结果的质量。
反思和完善:智能体可以对过去的行为进行自我批评和自我反思,从错误中吸取教训,并针对未来的步骤进行完善,从而提高最终结果的质量。
记忆
短期记忆:认为所有的上下文学习都是利用模型的短期记忆来学习。
长期记忆:这为智能体提供了长时间保留和回忆(无限)信息的能力,通常是通过利用外部向量存储和快速检索。
工具使用
智能体学习调用外部 API 来获取模型权重中缺失的额外信息(通常在 ...
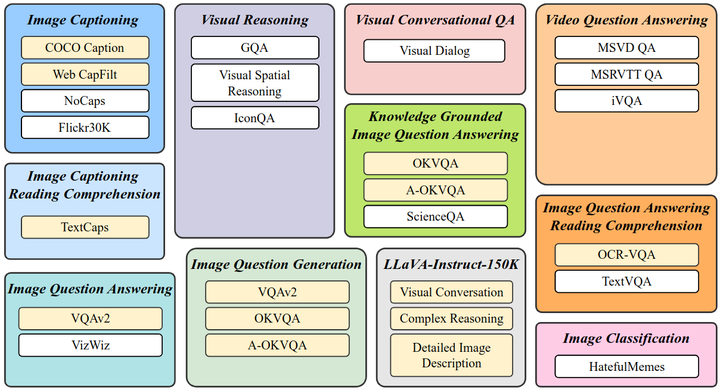
InstructBLIP:Towards General-purpose Vision-Language Models with Instruction Tuning
InstructBLIP 是 BLIP 作者团队在多模态领域的又一续作。现代的大语言模型在无监督预训练之后会经过进一步的指令微调 (Instruction-Tuning) 过程,但是这种范式在视觉语言模型上面探索得还比较少。InstructBLIP 这个工作介绍了如何把指令微调的范式做在 BLIP-2 模型上面。用指令微调方法的时候会额外有一条 instruction,如何借助这个 instruction 提取更有用的视觉特征是本文的亮点之一。InstructBLIP 的架构和 BLIP-2 相似,从预训练好的 BLIP-2 模型初始化,由图像编码器、LLM 和 Q-Former 组成。在指令微调期间只训练 Q-Former,冻结图像编码器和 LLM 的参数。作者将26个数据集转化成指令微调的格式,把它们分成13个 held-in 数据集用于指令微调,和13个 held-out 数据集用于 Zero-Shot 能力的评估。
论文地址: https://arxiv.org/pdf/2305.06500.pdf
指令微调
在 NLP 领域,指令微调技术 (Instruction-Tuni ...

ReAct:Synergizing Reasoning and Acting in Language Models
在本文中,我们介绍ReAct,这是一种将推理和行动与语言模型相结合以解决各种语言推理和决策制定任务的通用范式。采取动态的方式构建prompt,即根据将用户请求以及之前的观察向大模型请求,依据模型的推理思决策下一步的动作行为,在执行完指定动作后,将结果作为prompt的一部分,继续请求语言模型,直到任务完成。改方法在QA数据集HotpotQA、事实验证数据集Fever上,结合维基百科API,能够提高可解释性。另外,在交互决策数据集ALFWorld、WebShop数据集上效果比模仿学习和强化学成功率分别提升34%和10%。
论文地址: https://arxiv.org/pdf/2210.03629.pdf
代码地址: https://github.com/ysymyth/ReAct
ReAct是Reasoning and Acting(也有一说是Reason Act)缩写,意思是LLM可以根据逻辑推理(Reason),构建完整系列行动(Act),从而达成期望目标。LLM灵感来源是人类行为和推理之间的协同关系。人类根据这种协同关系学习新知识,做出决策,然后执行。LLM模型在逻辑推理上有 ...

Instruction Tuning 阶段性总结
ChatGPT 大火之后,在 2023 年 2 月 24 日,LLaMA 的出现让 instruction tuning 这个方向变得火热;3 月 18 日,Alpaca 让大家看到从成熟的模型 distill 小模型成为还不错的 ChatBot 的可能性,从而引发羊驼系模型寒武纪大爆发。但仅仅过去三个月,大家开始发现意识到用 ChatGPT 的数据训练 LLaMA 的各种问题。本文回顾在过去三个月内的 LLaMA 系模型的发展,讨论 Instruction Tuning 的下一步挑战。
1 - 起源
最开始三篇
InstructGPT: Training language models to follow instructions with human feedback
FLANv1: Finetuned Language Models Are Zero-Shot Learners
T0: Multitask Prompted Training Enables Zero-Shot Task Generalization
对比
InstructGPT 的目标是对齐,zero-sh ...

