
Adversarial validation
之前参加了kaggle的Toxic比赛,名次为Top1%(瞎打,忙于项目——提不上去的理由了,安慰自己)。回头看别人分享的kernel时,发现了Adversarial validation,本文也是直接copy fastml以及来自kaggle中一个kernel。
在比赛中,可能会遇到测试数据集与训练数据集分布明显不同。这时候,我们常用的k-折交叉验证可能达不到想要的效果,即训练集上的交叉验证结果可能与测试集上的结果相差甚远。
可能是由以下原因造成:
1.过细的学习训练数据集,即可能也把噪声数据学习到了。
2.训练数据集和测试数据集存在显著差异,即分布不同。
问题
对于第一个问题,我们可以使用一些正则化手段解决过拟合问题,那么对于第二个问题,我们该如何解决?如果你参加过像Kaggle这样的竞赛,你就会知道这些竞赛的模式。在比赛中,你可以下载到一个train数据集和test数据集。你需要在train数据上训练你的模型,在test数据上预测并且在上传到Kaggle平台上来得到你排名。
我们通常做法是将完整的train数据集划分为train和valid数据集。valid数据用于评估与模 ...
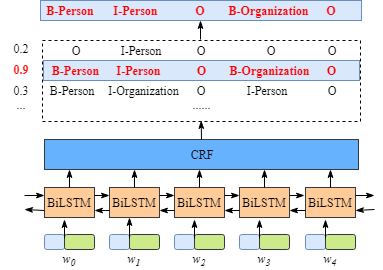
BiLSTM模型中CRF层的运行原理(1)
本文主要内容如下:
介绍: 在命名实体识别任务中,BiLSTM模型中CRF层的通用思想
实例: 通过实例来一步步展示CRF的工作原理
实现: CRF层的一步步实现过程
备注: 需要有的基础知识:你只需要知道什么是命名实体识别,如果你不懂神经网络,条件随机场(CRF)或者其它相关知识,不必担心,本文将向你展示CRF层是如何工作的。本文将尽可能的讲的通俗易懂。
1.介绍
基于神经网络的方法,在命名实体识别任务中非常流行和普遍。在文献[1]中,作者提出了BiLSTM-CRF模型用于实体识别任务中,在模型中用到了字嵌入和词嵌入。本文将向你展示CRF层是如何工作的。
如果你不知道BiLSTM和CRF是什么,你只需要记住他们分别是命名实体识别模型中的两个层。
1.1开始之前
我们假设我们的数据集中有两类实体——人名和地名,与之相对应在我们的训练数据集中,有五类标签:
B-Person
I-Person
B-Organization
I-Organization
O
假设句子xxx由5个字符组成,即x=(w0,w1,w2,w3,w4)x = (w_0,w_1,w_2,w_3,w_4)x=( ...
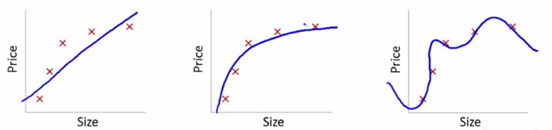
使用交叉验证提高模型预测能力
交叉验证是一种用来衡量和评估机器学习模型性能的技术,在模型训练过程,我们创建了训练集的多个分区,并在这些分区的不同子集上进行训练/测试。
本文我们主要介绍不同的交叉验证方法。
交叉验证经常用于给定的数据集训练、评估和最终选择机器学习模型,因为它有助于评估模型的结果在实践中如何推广到独立的数据集,最重要的是,交叉验证已经被证明产生比其他方法更低的偏差的模型。
模型无法保持稳定?
让我们通过以下几幅图来理解这个问题:
此处,我们试图找到size和price的关系,三个模型各自做了如下工作:
1.第一个模型使用了线性等式。对于训练数据集,该模型存在很大的误差。这样的模型效果往往不太好,这是欠拟合的一个例子。此模型不足以发掘数据背后的趋势。
2.第二个模型发现了price和size的正确关系,此模型误差低,拟合关系较强。
3.第三个模型对于训练数据集而言几乎是零误差。这是因为此模型把每一个数据点的偏差(包括噪声)都纳入了考虑的范围,也就是说,这个模型太过敏感了,甚至会捕抓到在当前训练数据集出现的一些随机模式。这是“过拟合”的一个例子,这个模型往往会造成在训练效果很好而在测试效果很差。
...
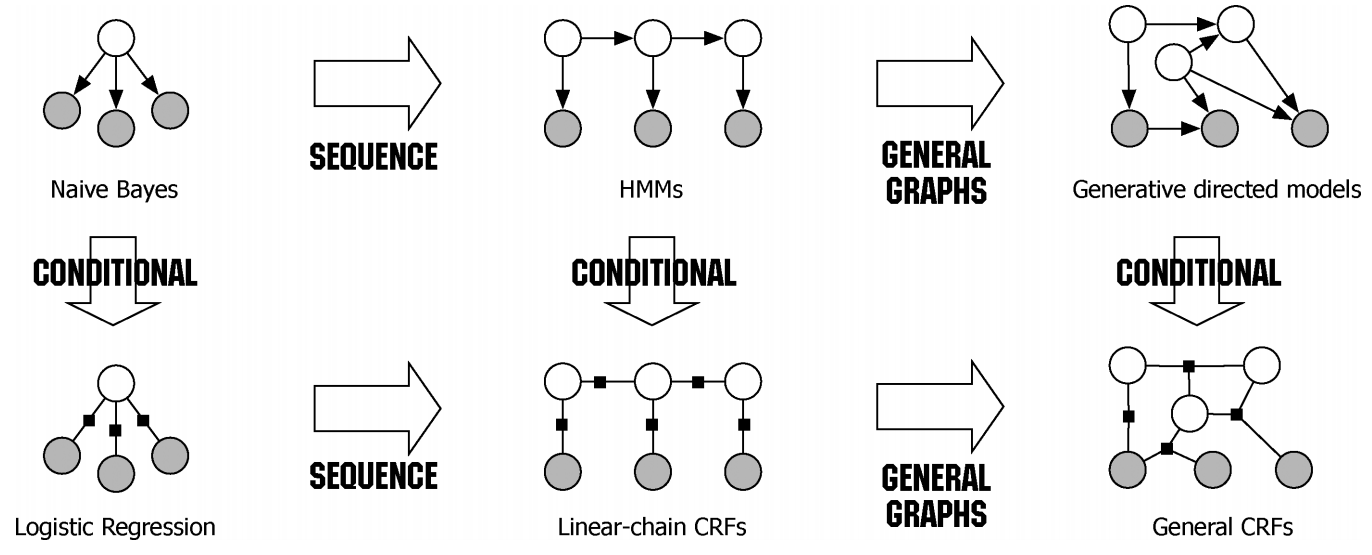
条件随机场-CRF
最近一段时间在研究NER相关项目,因此,打算对NER一些算法做一定总结,本文主要记录自己在学习CRF模型过程中的一些记录,大部分来自于网上各位大神的博客。
什么样的问题需要CRF模型
假设你有许多小明同学一天内不同时段的照片,从小明提裤子起床到脱裤子睡觉各个时间段都有(小明是照片控!)。现在的任务是对这些照片进行分类。比如有的照片是吃饭,那就给它打上吃饭的标签;有的照片是跑步时拍的,那就打上跑步的标签;有的照片是开会时拍的,那就打上开会的标签。问题来了,你准备怎么干?
一个简单直观的办法就是,不管这些照片之间的时间顺序,想办法训练出一个多元分类器。就是用一些打好标签的照片作为训练数据,训练出一个模型,直接根据照片的特征来分类。例如,如果照片是早上6:00拍的,且画面是黑暗的,那就给它打上睡觉的标签;如果照片上有车,那就给它打上开车的标签。
这样可行吗?
乍一看可以!但实际上,由于我们忽略了这些照片之间的时间顺序这一重要信息,我们的分类器会有缺陷的。举个例子,假如有一张小明闭着嘴的照片,怎么分类?显然难以直接判断,需要参考闭嘴之前的照片,如果之前的照片显示小明在吃饭,那这个闭嘴的照片很 ...

深度学习与计算机视觉(PB-13)—ImageNet数据集准备
前面几节内容中,我们都是对小数据集(相对于工业界而言)进行实验,使用CPU环境也可以完美地实现。接下来,我们将使用ImageNet数据集进行实验,该数据集比较大,需要在GPU环境下进行。在对ImageNet数据进行建模之前,我们首先来认识下ImageNet数据集以及对该数据集进行预处理。
ImageNet数据集介绍
ImageNet是一个计算机视觉系统识别项目,是目前世界上图像识别最大的数据库。是美国斯坦福的计算机科学家,模拟人类的识别系统建立的。能够从图片中识别物体。ImageNet是一个非常有前景的研究项目,未来用在机器人身上,就可以直接辨认物品和人了。超过1400万的图像URL被ImageNet手动注释,以指示图片中的对象;在至少一百万张图像中,还提供了边界框。ImageNet包含2万多个类别; 一个典型的类别,如“气球”或“草莓”,每个类包含数百张图像。
下载地址
ImageNet数据集可以直接从该地址中下载,当然你可以根据对应的任务选择相应的数据集下载即可。
备注:我花了好几天将官网的数据下载完,速度比较慢,如果你们有需要的,可以留言,我上传到百度网盘,分享给你们(很容易被 ...

一文揭秘!自底向上构建知识图谱全过程
知识图谱的构建技术主要有自顶向下和自底向上两种。其中自顶向下构建是指借助百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库里。而自底向上构建,则是借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的信息,加入到知识库中。
知识图谱,是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系,通过将数据粒度从document级别降到data级别,聚合大量知识,从而实现知识的快速响应和推理。
当下知识图谱已在工业领域得到了广泛应用,如搜索领域的Google搜索、百度搜索,社交领域的领英经济图谱,企业信息领域的天眼查企业图谱等。
在知识图谱技术发展初期,多数参与企业和科研机构主要采用自顶向下的方式构建基础知识库,如Freebase。随着自动知识抽取与加工技术的不断成熟,当前的知识图谱大多采用自底向上的方式构建,如Google的Knowledge Vault和微软的Satori知识库。
定义
俗话说:“看人先看脸。”在我们深入了解知识图谱之前,让我们先来看一下它长什么样子!
如图所示,你可以看到,如果两个节点之间存在关系,他们就会被一条无向 ...
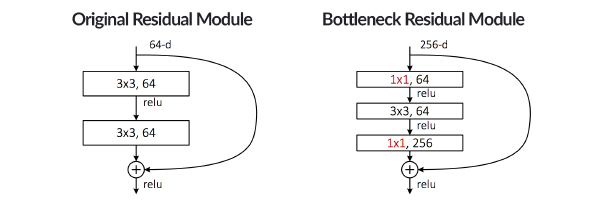
深度学习与计算机视觉(PB-12)-ResNet
在上一章中,我们讨论了GoogLeNet网络结构和Inception模块,这节中,我们将讨论由一个新的微结构模块组成的网络结构,即由residual微结构组成的网络结构——ResNet。
ResNet网络由residual模块串联而成,在原论文中,我们发现作者训练的ResNet网络深度达到了先前认为不可能的深度。在2014年,我们认为VGG16和VGG19网络结构已经非常深了。然而,通过ResNet网络结构,我们发现可以成功在ImageNet数据集上训练超过100层的网络和在CIFAR-10数据集上训练超过1000层的网络。
从论文《Identity Mappings in Deep Residual Networks》中,可知只有使用更高级的权值初始化算法(如Xavier等)以及identity mapping(恒等映射)才能实现这些深度,我们将在本章后面讨论相关内容。我们知道CNN能够提取low/mid/high-level的特征,网络的层数越多,意味着能够提取到不同level的特征越丰富。并且,越深的网络提取的特征越抽象,越具有语义信息。非常深的ResNet网络在ILSVRC ...
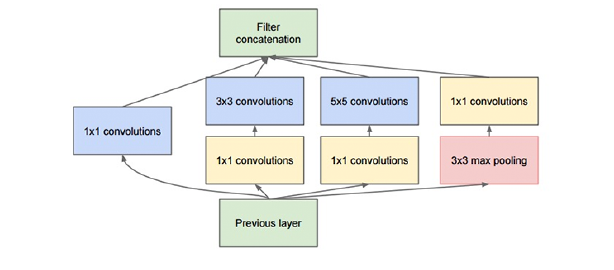
深度学习与计算机视觉(PB-11)-GoogLeNet
在本节中,我们将研究Szegedy等人在2014年的论文《Going Deeper With Convolutions》中提出的GoogLeNet架构。这篇论文之所以重要,主要是:
与AlexNet和VGGNet网络结构相比,模型非常小(整个权重文件大小约为28MB)。并且从论文中,我们可以看到作者使用Global Average Pooling代替了全连接层,一方面减小了模型的大小,另一方面加深了整个网络的深度。CNN中的大部分权重都来自于全连接FC层,如果删除FC层,那么模型权重个数会减少很多且可以节省计算的内存消耗。
Szegedy等人在构建整体网络结构时,利用了Network in Network(NIN)结构。在此之前的AlexNet、VGG等结构都是堆叠式神经网络,即其中一个网络层的输出直接输入到另一个网络层。原论文中,作者在搭建网络结构时,多次使用一个微结构——我们即将看到的Inception模块,该模块将输入分割成许多不同的分支,然后再重新连接成一个输出。
具体来说,Inception模块是对输入做了四个分支,分别用不同尺寸的filter进行卷积或者池化, ...
一文读懂如何用LSA、PSLA、LDA和lda2vec进行主题建模
本文是一篇关于主题建模及其相关技术的综述。文中介绍了四种最流行的技术,用于探讨主题建模,它们分别是:LSA、pLSA、LDA,以及最新的、基于深度学习的 lda2vec。
在自然语言理解任务中,我们可以通过一系列的层次来提取含义——从单词、句子、段落,再到文档。在文档层面,理解文本最有效的方式之一就是分析其主题。在文档集合中学习、识别和提取这些主题的过程被称为主题建模。
在本文中,我们将通过 4 种最流行的技术来探讨主题建模,它们分别是:LSA、pLSA、LDA,以及最新的、基于深度学习的 lda2vec。
概述
所有主题模型都基于相同的基本假设:
每个文档包含多个主题;
每个主题包含多个单词。
换句话说,主题模型围绕着以下观点构建:实际上,文档的语义由一些我们所忽视的隐变量或「潜」变量管理。因此,主题建模的目标就是揭示这些潜在变量——也就是主题,正是它们塑造了我们文档和语料库的含义。这篇博文将继续深入不同种类的主题模型,试图建立起读者对不同主题模型如何揭示这些潜在主题的认知。
LSA
潜在语义分析(LSA)是主题建模的基础技术之一。其核心思想是把我们所拥有的文档-术语矩阵分解成 ...
时间序列交叉验证
本文讨论了对时序数据使用传统交叉验证的一些缺陷。具体来说,我们解决了以下问题:
1.在不造成数据泄露的情况下,对时序数据进行分割
2.在独立测试集上使用嵌套交叉验证得到误差的无偏估计
3.对包含多个时序的数据集进行交叉验证
本文主要针对缺乏如何对包含多个时间序列的数据使用交叉验证的在线信息。
本文有助于任何拥有时间序列数据,尤其是多个独立的时间序列数据的人。这些方法是在医疗研究中被设计用于处理来自多个参与人员的医疗时序数据的。
交叉验证
交叉验证(CV)是一项很流行的技术,用于调节超参数,是一种具备鲁棒性的模型性能评价技术。两种最常见的交叉验证方式分别是:
1.k 折交叉验证
2.hold-out 交叉验证
由于文献中术语的不同,本文中我们将明确定义交叉验证步骤:
1.首先,将数据集分割为两个子集:训练集和测试集。如果有需要被调整的参数,我们将训练集分为训练子集和验证集。
2.模型在训练子集上进行训练,在验证集上将误差最小化的参数将最终被选择
3.最后,模型使用所选的参数在整个训练集上进行训练,并且记录测试集上的误差。
图 1: hold-out 交叉验证的例子。数据 ...

