
(转)对比学习(Contrastive Learning):研究进展精要
对比学习(Contrastive Learning)最近一年比较火,各路大神比如Hinton、Yann LeCun、Kaiming He及一流研究机构比如Facebook、Google、DeepMind,都投入其中并快速提出各种改进模型:Moco系列、SimCLR系列、BYOL、SwAV……,各种方法相互借鉴,又各有创新,俨然一场机器学习领域的军备竞赛。对比学习属于无监督或者自监督学习,但是目前多个模型的效果已超过了有监督模型,这样的结果很令人振奋。
我想,NLP领域的Bert模型,对于这波图像领域的对比学习热潮,是具有启发和推动作用的。我们知道,Bert预训练模型,通过MLM任务的自监督学习,充分挖掘了模型从海量无标注文本中学习通用知识的能力。而图像领域的预训练,往往是有监督的,就是用ImageNet来进行预训练,但是在下游任务中Fine-tuning的效果,跟Bert在NLP下游任务中带来的性能提升,是没法比的。
“但是,既然NLP这样做(自监督,无需标注数据)成功了,图像领域难道就不能成功吗?”我相信,追寻这个问题的答案,应该是促使很多人,从图像领域的有监督预训练,向自监督预训练 ...
An Analysis of Simple Data Augmentation for Named Entity Recognition
现有NLP的数据增强大致有两条思路:一个是加噪,另一个是回译,均为有监督方法。加噪即为在原数据的基础上通过替换词、删除词等方式创造和原数据相类似的新数据。回译则是将原有数据翻译为其他语言再翻译回原语言,由于语言逻辑顺序等的不同,回译的方法也往往能够得到和原数据差别较大的新数据。本文借鉴sentence-level的传统数据增强方法,探究了不同的数据增强方法对NER任务的影响,发现:在低资源条件下,数据增强效果增益比较明显,而在充分数据条件下,数据增强可能会带来噪声,导致指标下降。
论文地址: https://arxiv.org/pdf/2010.11683.pdf
论文源码地址: https://github.com/abdulmajee/coling2020-data-augmentation
方法
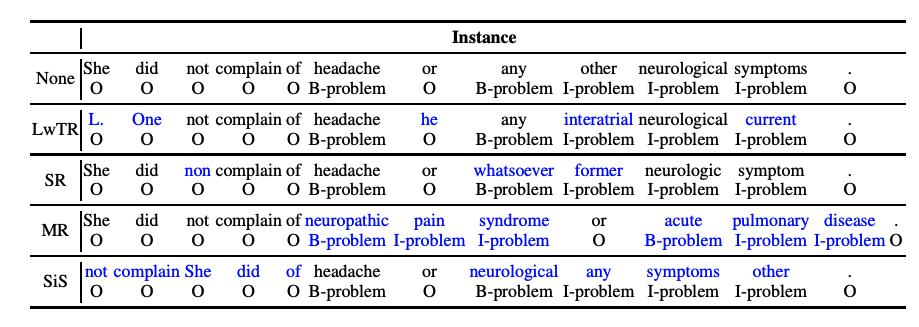
在本文中,作者借鉴了sentence-level的传统数据增强方法,将传统的文本增强方法应用于NER任务中,并进行全面分析与对比。主要有以下4种数据增强方法(如下图所示):
Label-wise token replacement (LwTR):即相同标签的token替换,通过一个 ...
FixMatch:Simplifying Semi-Supervised Learning with Consistency and Confidence
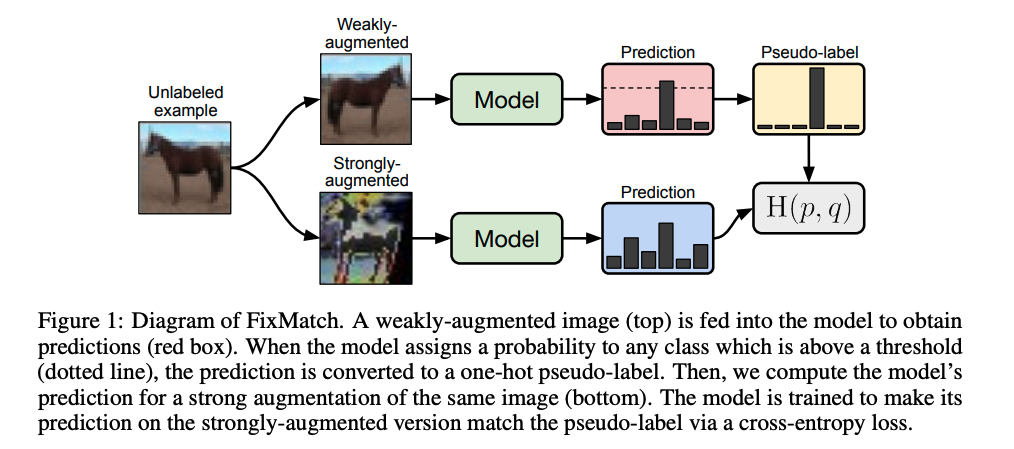
本篇博文我们主要关注半监督学习,在实际应用环境中,获得高质量的标注数据是比较耗时和昂贵的,往往都是小部分标注数据和大量的无标注数据,除了高效利用标注数据,还需要将大量的无标注数据发挥出价值。半监督学习(Semi-supervised learning,SSL)是一种学习方法,其使用少量标注的数据和大量未标注的数据进行学习,从而得到一个高质量模型。本文作者提出一种名为FixMatch的半监督学习算法,通过对每一张没有标注的图片进行弱增强和强增强,首先对弱增强产生的数据通过模型产生伪标签,当模型的预测得分高于一定的阈值时,伪标签作为该样本标签,并与强增强数据模型预测结果进行计算损失。实验结果表明,FixMatch在众多的半监督学习方法中达到了最好的效果。仅用了250张标注数据,在CIFAR-10数据集上达到了94.93%的准确率;仅用了40张标注数据,在CIFAR-10数据集上达到了88.61%的准确率(每个标签仅4张标注数据)。
论文地址: https://arxiv.org/abs/2001.07685
论文源码地址: https://github.com/google-resear ...
StructBERT-Incorporating Languages structures into pre-training for deep language understading
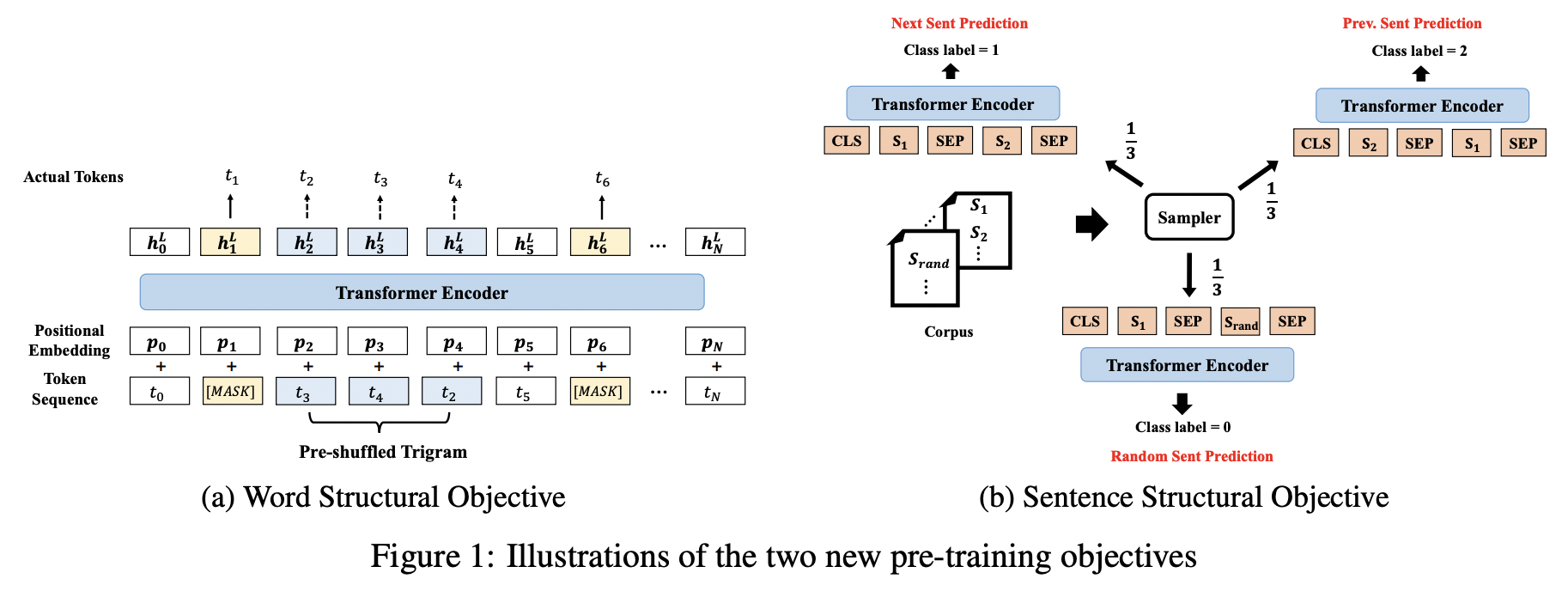
BERT的两个任务主要是MLM和NSP,虽然取得了先进的性能,但是作者认为其并未充分利用句子的语言结构。作者将语言结构信息引入到预训练任务中,提出了一种新型的上下文表示模型-StructBERT,本质上,StructBERT的模型架构和BERT一样,不同点在于新增了两个预训练目标来增强模型的预训练,即:Word Structural Objective和Sentence Structural Objective
论文地址: https://arxiv.org/pdf/1908.04577v3.pdf
论文源码地址: https://github.com/alibaba/AliceMind/tree/main/StructBERT
方法
本文作者提出的StructBERT模型结果如下所示:
具体来说,原模型还是BERT,主要在预训练任务上做了改进,主要有:WSO和SSO。
Word Structural Objective
BERT无法直接显式的对单词顺序和高阶依赖性建模。而将一句话中的单词打乱,一个好的语言模型应该能够通过重组单词顺序恢复句子的正确排列。为了能在StructBE ...

NLP领域有哪些国际顶级会议?
如今在人工智能时代,一项新技术的出现往往能够颠覆某个产品甚至是某个行业,从而诞生新的独角兽公司甚至是行业巨头企业,比如国内近几年计算机视觉领域火热的CV四小龙(商汤、旷视、依图、云从)。
而NLP领域,由于技术、商业应用场景等诸多因素的限制,目前还没有出现独角兽级别的公司。但这并不意味着NLP没有发展前景,正如比尔盖茨所言“NLP是人工智能皇冠上的明珠”,是一项非常值得人们all in的事业。
因此,作为NLP领域的从业者,必须要时刻关注学术界or大厂AI Lab最新的科研动态,了解技术发展的趋势,以便提早做好产品规划以及技术预研。
对于NLPer而言,了解科研动态最好的方法就是关注顶会论文,与NLP相关的比较有影响力的顶会主要有ACL、EMNLP、NAACL、COLING、ICLR、AAAI、CoNLL、NLPCC等。
其中,ACL、NAACL、EMNLP、COLING被称为是NLP领域的四大顶会。ACL、NAACL以及EMNLP均由ACL(Association of Computational Linguistics)主办,而COLING则由ICCL(International ...
On Layer Normalization in the Transformer Architecture
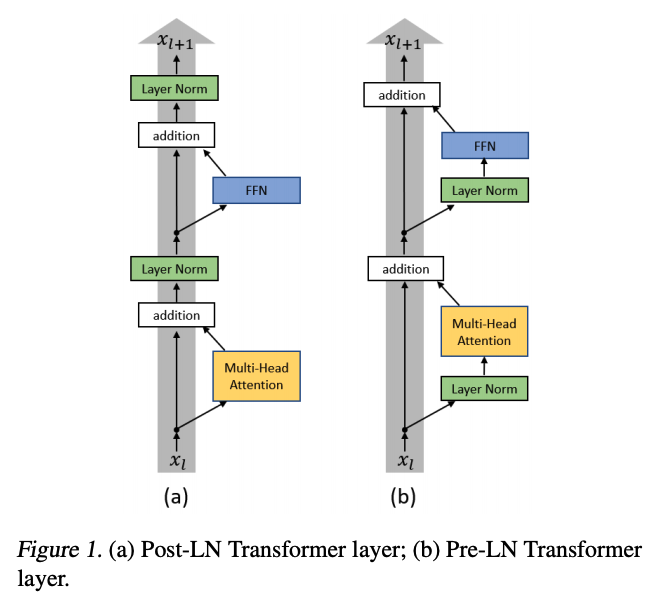
近年来,Transformer网络结构广泛应用于自然语言处理的各项任务,并且获得了非常好的效果。然而 Transformer 结构的优化非常困难,其具体表现有 warm-up 阶段超参数敏感、优化过程收敛速度慢等问题。本文作者从理论上详细分析了 Transformer 结构优化困难的原因,通过将 Layer Normalization 放到残差连接中的两个子层之前,并且在整个网络最后输出之前也增加一个 Layer Normalization 层来对梯度进行归一化,即 Pre-LN Transformer,可以让 Transformer 彻底摆脱 warm-up 阶段,并且大幅加快训练的收敛速度。
论文地址: https://www.microsoft.com/en-us/research/uploads/prod/2020/07/2002.04745.pdf
方法
在优化 Transformer 结构时,除了设置初始学习率与它的衰减策略,往往还需要在训练的初始阶段设置一个非常小(接近0)的学习率,让它经过一定的迭代轮数后逐渐增长到初始的学习率,这个过程也被称作 warm-up 阶段。 ...
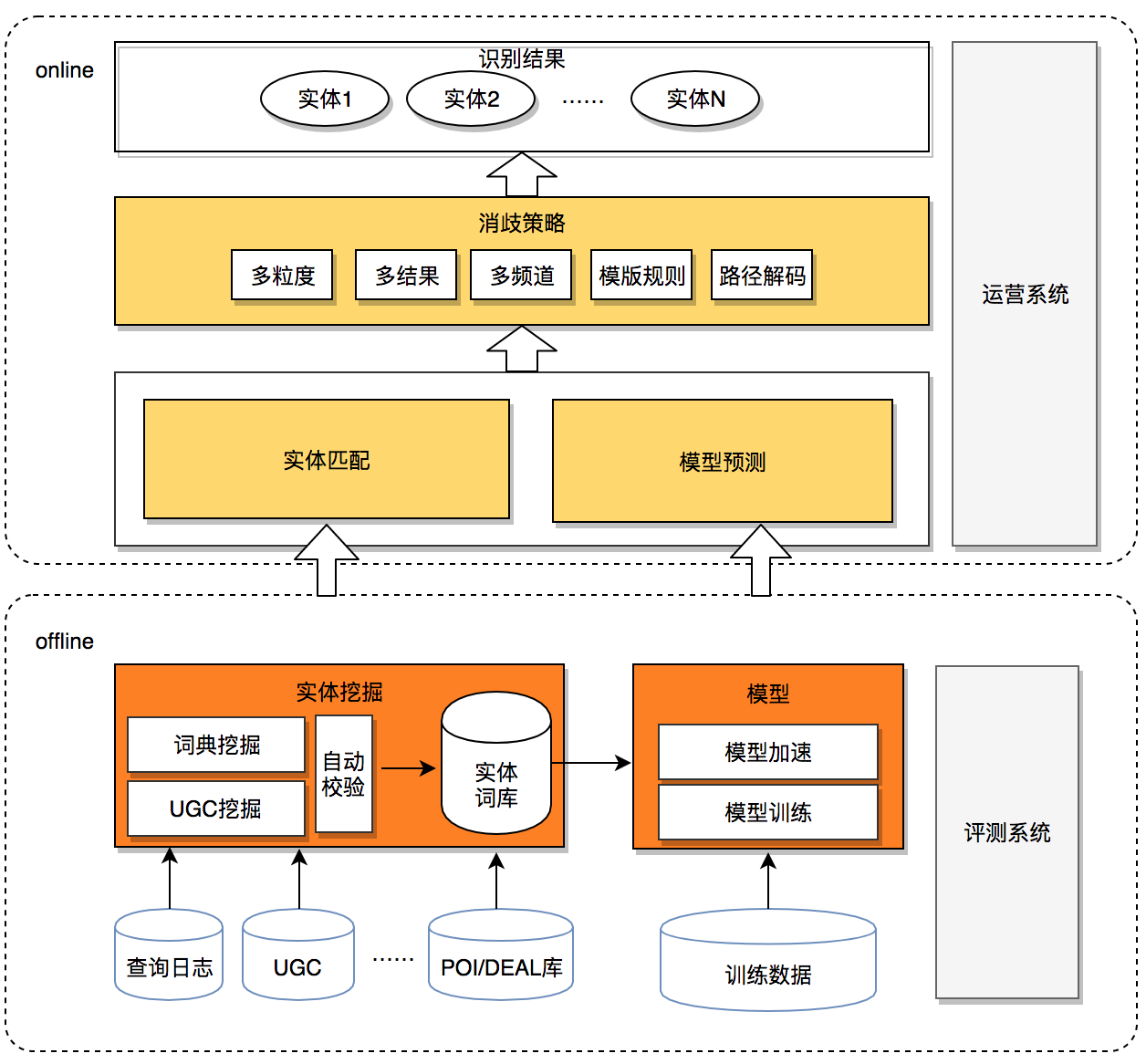
美团搜索中NER技术的探索与实践
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。NER是信息提取、问答系统、句法分析、机器翻译、面向Semantic Web的元数据标注等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要的地位。在美团搜索场景下,NER是深度查询理解(Deep
Query Understanding,简称 DQU)的底层基础信号,主要应用于搜索召回、用户意图识别、实体链接等环节,NER信号的质量,直接影响到用户的搜索体验。
背景
下面将简述一下实体识别在搜索召回中的应用。在O2O搜索中,对商家POI的描述是商家名称、地址、品类等多个互相之间相关性并不高的文本域。如果对O2O搜索引擎也采用全部文本域命中求交的方式,就可能会产生大量的误召回。我们的解决方法如下图1所示,让特定的查询只在特定的文本域做倒排检索,我们称之为“结构化召回”,可保证召回商家的强相关性。举例来说,对于“海底捞”这样的请求,有些商家地址会描述为“海底捞附近几百米”,若采用全文本域检索这些商家就 ...

MobileBERT-a Compact Task-Agnostic BERT for Resource-Limited Devices
在蒸馏之后对学生模型再进行微调,进一步提升能力。
随着NLP模型的大小增加到数千亿个参数,创建这些模型的更紧凑表示的重要性也随之增加。知识蒸馏成功地实现了这一点,在一个例子中,教师模型的性能的96%保留在了一个小7倍的模型中。然而,在设计教师模型时,知识的提炼仍然被认为是事后考虑的事情,这可能会降低效率,把潜在的性能改进留给学生。
此外,在最初的提炼后对小型学生模型进行微调,而不降低他们的表现是困难的,这要求我们对教师模型进行预训练和微调,让他们完成我们希望学生能够完成的任务。因此,与只训练教师模型相比,通过知识蒸馏训练学生模型将需要更多的训练,这在推理的时候限制了学生模型的优点。
如果在设计和训练教师模型的过程中,将知识的提炼放在首要位置和中心位置,会有什么可能呢?我们能否设计并成功地训练一个“假定”要被蒸馏的模型,蒸馏后的版本能否成功地在任何下游任务上进行微调?这是我们在本文中总结的MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices中提出的一些问题。据作者说目前还没有与任务无关的轻量级预训练模型 ...
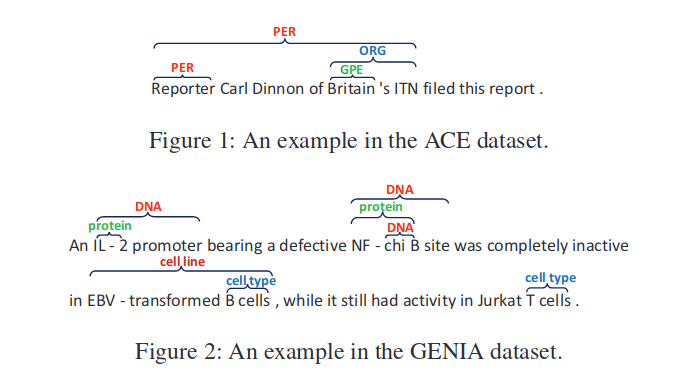
Boundary Enhanced Neural Span Classification for Nested Named Entity Recognition
命名实体识别任务(NER)是NLP领域的一个研究热点。大部分使用序列标记框架来解决该问题,但是序列标记框架通常难以检测出嵌套的实体。基于Span的方法可以很容易地检测出不同子序列中的嵌套实体,因此适用于解决嵌套NER问题。然而,现有的基于Span的方法有两个主要问题。第一,对所有子序列进行分类识别在计算上很昂贵,而且在推理上效率很低。第二,基于Span的方法主要集中在学习Span表示,但缺乏明确的边界监督。针对上述两个问题,本文提出了一种边界增强型neural span 分类模型。除了对Span进行分类之外,还加入一个额外的边界检测任务来预测那些作为实体边界的单词。并在多任务学习框架下进行联合训练,在附加边界监督的情况下增强了跨度表示。此外,边界检测模型能够生成高质量的候选跨度,大大降低了推理过程的时间复杂度。
本文主要解决嵌套NER问题,如下所示:
数据集中每一个单词不再只有一个标签,可能存在多种标签。本文提出的BENSC模型的主要思想为:在给定一个句子,首先,对word进行语义编码,其次利用多任务学习思想联合训练边界检测模型和Span分类模型。边界检测模型主要预测每个词是否实体的 ...

聊聊工业界中如何求解NER问题
NER是一个已经解决了的问题吗?或许,一切才刚刚开始。
例如,面对下面笔者在工作中遇到的12个关于NER的系列问题,你有什么好的trick呢?不着急,让我们通过本篇文章,逐一解答以下问题:
Q1、如何快速有效地提升NER性能(非模型迭代)?
Q2、如何在模型层面提升NER性能?
Q3、如何构建引入词汇信息(词向量)的NER?
Q4、如何解决NER实体span过长的问题?
Q5、如何客观看待BERT在NER中的作用?
Q6、如何冷启动NER任务?
Q7、如何有效解决低资源NER问题?
Q8、如何缓解NER标注数据的噪声问题?
Q9、如何克服NER中的类别不平衡问题?
Q10、如何对NER任务进行领域迁移?
Q11、如何让NER系统变得“透明”且健壮?
Q12、如何解决低耗时场景下的NER任务?
工业界中的NER问题为什么不易解决?
众所周知,命名实体识别(Named Entity Recognition,NER)是一项基础而又重要的NLP任务,往往作为信息抽取、问答对话、机器翻译等方向的或显式或隐式的基础任务。或许在很多人眼里,NER似乎只是一个书本概念,跟句法分析一样存在感不强。 ...

