
Language Models are Few-Shot Learners
最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调,在许多NLP任务和基准方面取得了实质性进展。虽然这种方法在体系结构中通常是任务无关的,但它仍然需要数千或上万个示例的特定于任务的微调数据集。相比之下,人类通常只能通过几个例子或简单的指令来执行一项新的语言任务,而当前的NLP系统在很大程度上仍难以做到这一点。在这里,论文展示了扩展语言模型可以极大地提高任务无关性、few-shot性能,有时甚至可以与以前最先进的微调方法相媲美。具体而言,论文训练了GPT-3,这是一个具有1750亿个参数的自回归语言模型,比以往任何非稀疏语言模型都多10倍,并在few-shot设置下测试了其性能。所有任务应用GPT-3模型时均不进行任何梯度更新或微调,而只是通过与模型的文本交互指定任务和少样本学习演示。GPT-3在许多NLP数据集上都取得了很好的性能,包括机器翻译、问答和完形填空任务,以及一些需要即时推理或领域适应的任务,例如解读单词、在句子中使用新单词或执行3位数算术。同时,论文还确定了一些GPT-3的zero-shot学习仍然困难的数据集,以及一些GPT-3面临与大型网络语料库培训相关的 ...

使用Anaconda管理Python环境
conda 最大的优势在于可以解决依赖,非常省心。例如,当你想安装支持 GPU 版本的 TensorFlow 时,一般需要先安装 TensorFlow,再安装 cuda 框架,最好安装 cudnn 神经网络加速工具。而使用 Conda 安装时,只需要 conda install tensorflow,一切自动搞定。下面主要记录开发过程中涉及的命令:
常用命令
查看安装了哪些包
1conda list
查看当前存在哪些虚拟环境
123conda env list conda info -e# 前面有个‘*’的代表当前环境
检查更新当前conda
1conda update conda
Python创建虚拟环境
conda create -n your_env_name python=x.x
anaconda命令创建python版本为x.x,名字为your_env_name的虚拟环境。your_env_name文件可以在Anaconda安装目录envs文件下找到。
12#conda create -n your_env_name python=x.xconda create -n ml ...
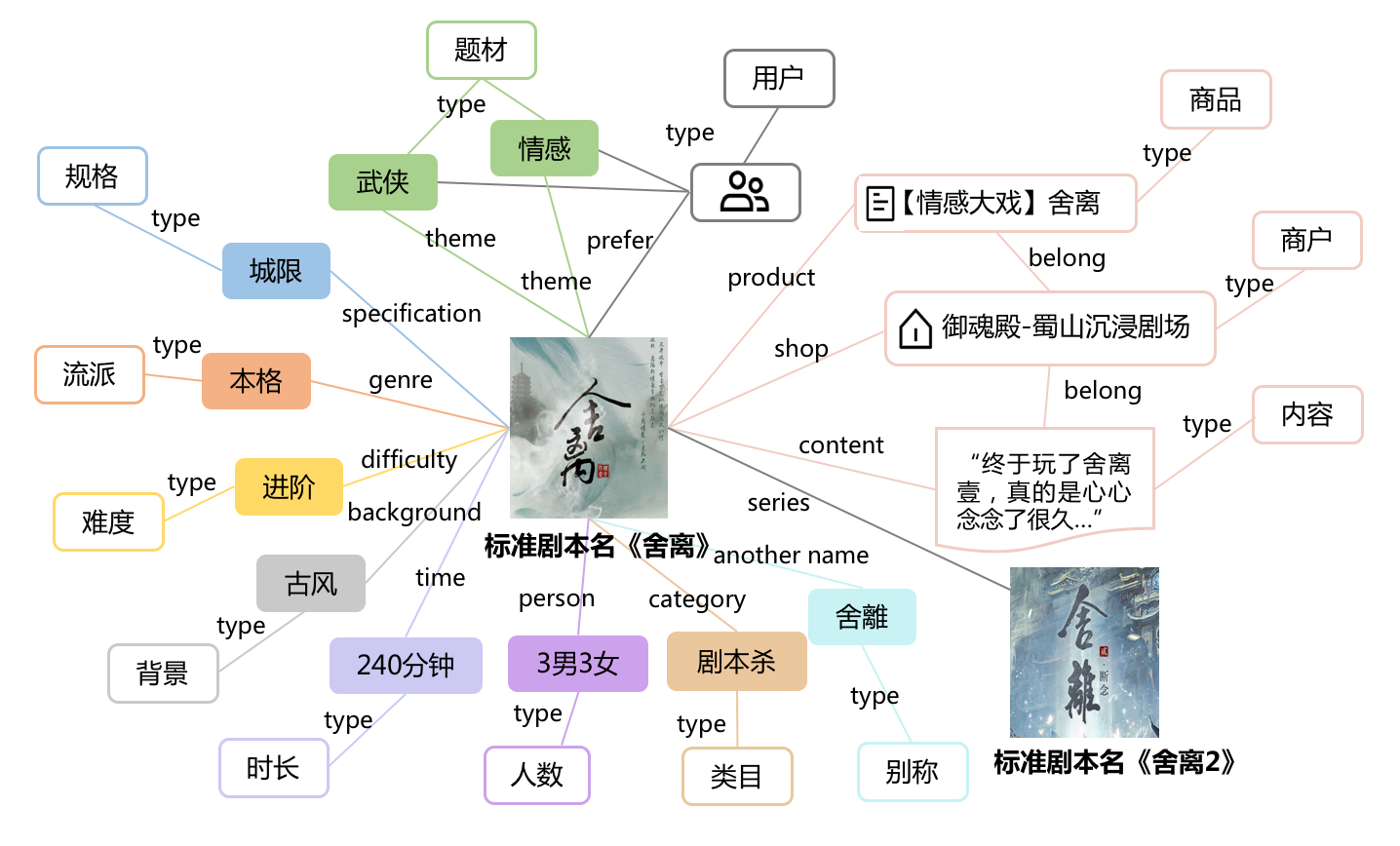
(转)美团基于知识图谱的剧本杀标准化建设与应用
剧本杀作为爆发式增长的新兴业务,在商家上单、用户选购、供需匹配等方面存在不足,供给标准化能为用户、商家、平台三方创造价值,助力业务增长。本文介绍了美团到店综合业务数据团队从0到1快速建设剧本杀供给标准化的过程及算法方案。我们将美团到店综合知识图谱(GENE,GEneral NEeds net)覆盖至剧本杀行业,构建剧本杀知识图谱实现供给标准化建设,包括剧本杀供给挖掘、标准剧本库构建、供给与标准剧本关联等环节,并在多个场景进行应用落地,希望给大家带来一些帮助或启发。
背景
剧本杀行业近年来呈爆发式增长态势,然而由于剧本杀是新兴行业,平台已有的类目体系和产品形态,越来越难以满足飞速增长的用户和商户需求,主要表现在下面三个方面:
平台类目缺失:平台缺少专门的“剧本杀”类目,中心化流量入口的缺失,导致用户决策路径混乱,难以建立统一的用户认知。
用户决策效率低:剧本杀的核心是剧本,由于缺乏标准的剧本库,也未建立标准剧本和供给的关联关系,导致剧本信息展示和供给管理的规范化程度低,影响了用户对剧本选择决策的效率。
商品上架繁琐:商品信息需要商户人工一一录入,没有可用的标准模板用以信息预填,导致商户 ...

Revisiting Self-Training for Few-Shot Learning of Language Model
本篇博文我们主要关注prompt模式在半监督学习场景下的应用,特别是针对少量标注和无标注数据。在实际应用环境中,获得高质量的标注数据是比较耗时和昂贵的,往往都是小部分标注数据和大量的无标注数据,半监督学习(Semi-supervised learning,SSL)是一种学习方法,其使用少量标注的数据和大量未标注的数据进行学习,从而得到一个高质量模型。之前prompt应用大部分都是在few-shot下的有监督训练,如LM-BFF,或者结合大量无标注数据下半监督训练,如PET。本文作者提出一种名为SFLM的方法,通过对没有标注的样本(prompt结构)进行弱增强和强增强,首先对弱增强产生的数据通过模型产生伪标签,当模型的预测得分高于一定的阈值时,伪标签作为该样本标签,并与强增强数据模型预测结果进行计算损失。实验结果表明,只依赖于少数领域内的未标注的数据情况下,SFLM在6个句子分类和6个句子对分类基准任务上达到了最好的效果。
论文地址: https://arxiv.org/pdf/2110.01256.pdf
论文源码地址: https://github.com/MatthewCYM/ ...
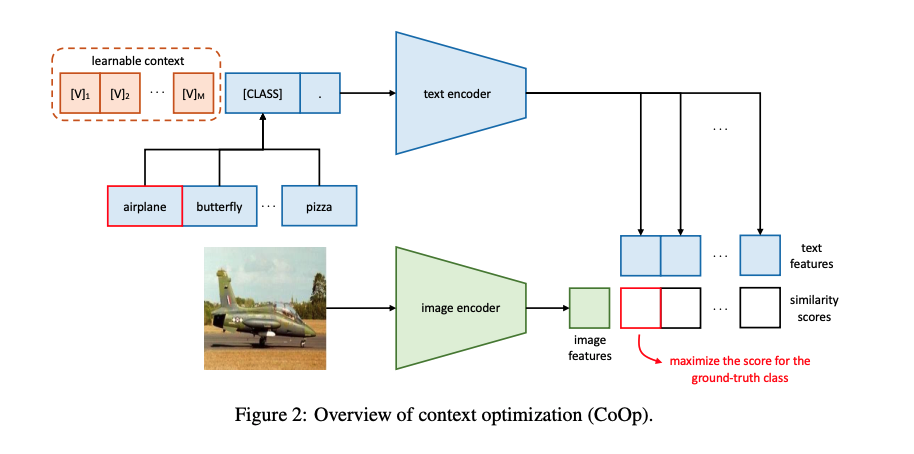
Learning to Prompt for Vision-Language Models
本篇博文我们主要关注prompt在视觉语言模型中的一个应用。我们知道一个好的prompt需要专业的领域知识以及大量实验进行优化,并且prompt的轻微变化可能会对性能产生巨大的影响。因此在实际应用时主要的挑战是如何对不同的下游任务构建特定的prompt。本文作者提出了一种context optimization(CoOP)的方法,通过构造soft prompt方式,即prompt参数化可学习,结合离散标签使用continuous representation建模上下文,并在保持预训练学习的参数固定的同时从数据中进行端到端学习优化,让网络学习更好的prompt。这样,与任务相关的prompt设计就可以完全自动化了。实验结果表明,CoOP在11个数据集上有效地将预训练的视觉语言模型转化为数据高效的视觉任务学习模型,只需少量样本微调就能击败手工设计的提示符,并且在使用更多样本微调时能够获得显著的性能提升。
论文地址: https://arxiv.org/abs/2109.01134
论文源码地址: https://github.com/KaiyangZhou/CoOp
方法
对于预训练 ...

(转)格局打开,带你解锁 prompt 的花式用法
今天我想要分享的是在工业实践中使用 prompt 的一些实践和心得体会。话不多说,我们直接开始。
初次关注到 prompt 是在去年GPT-3发布之后,我读到了一篇论文,It’ s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners ,了解我的小伙伴都会知道,虽然我是一个预训练语言模型的使用者,甚至生产者,但对于超大规模的语言模型,我一直持相对否定的态度,所以这篇文章的标题就相当吸引我,并且读下来之后,隐隐感觉,将文本理解任务转换为预训练的任务形式,再使用预训练语言模型,去做这个任务,这个思路简直太无懈可击了!利用它,我们可以更轻松地完成很多工作,又不必去面对例如样本类别均衡之类的数据分布上的困扰。
但当时却没有勇气直接应用起来。
到了今年,prompt 成为了一个相当火热的方向,在那篇 prompt 综述[1]出来了之后,我们知道,prompt 已经成气候了,它已经被很多工作验证是有用的了,也终于下定了决心,在我们的项目中尝试使用它,并看一下它到底有多么神奇。用过之后,不得不说,真香 ...
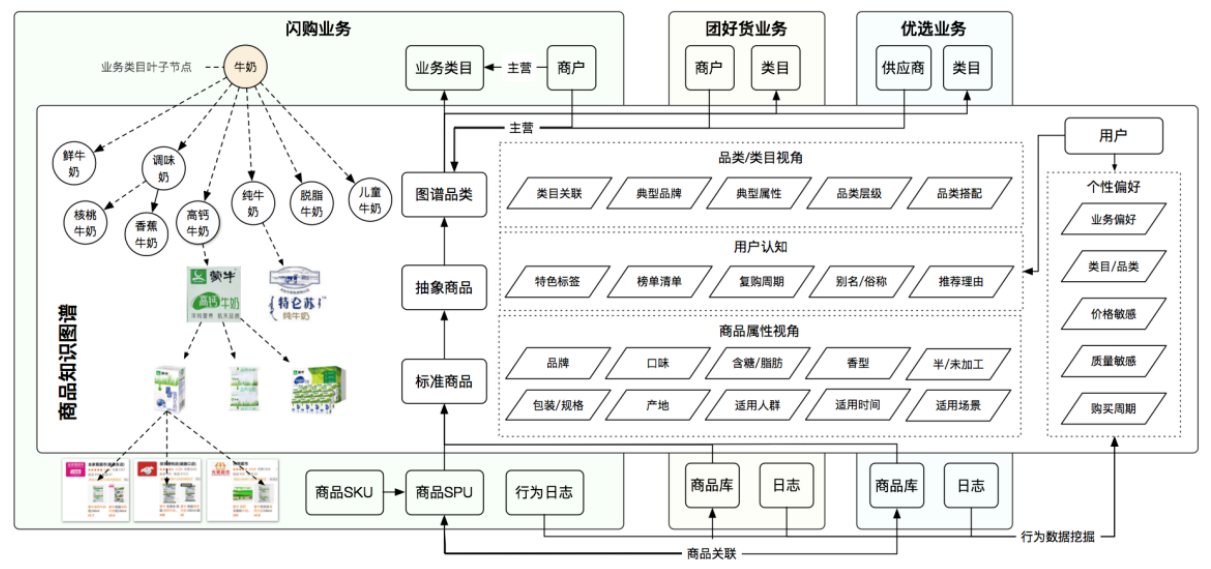
(转)美团商品知识图谱的构建及应用
在互联网新零售的大背景下,商品知识图谱作为新零售行业数字化的基石,提供了对于商品相关内容的立体化、智能化、常识化的理解,对上层业务的落地起到了至关重要的作用。相比于美团大脑中围绕商户的知识图谱而言,在新零售背景下的商品知识图谱需要应对更加分散、复杂的数据和业务场景,而这些不同的业务对于底层知识图谱都提出了各自不同的需求和挑战。美团作为互联网行业中新零售的新势力,业务上已覆盖了包括外卖、商超、生鲜、药品等在内的多个新零售领域,技术上在相关的知识图谱方面进行了深入探索。本文将对美团新零售背景下零售商品知识图谱的构建和应用进行介绍。
背景
近年来,人工智能正在快速地改变人们的生活,背后其实有两大技术驱动力:深度学习和知识图谱。我们将深度学习归纳为隐性的模型,它通常是面向某一个具体任务,比如说下围棋、识别猫、人脸识别、语音识别等等。通常而言,在很多任务上它能够取得很优秀的结果,同时它也有一些局限性,比如说它需要海量的训练数据,以及强大的计算能力,难以进行跨任务的迁移,并且不具有较好的可解释性。在另一方面,知识图谱作为显示模型,同样也是人工智能的一大技术驱动力,它能够广泛地适用于不同的任务。相比 ...
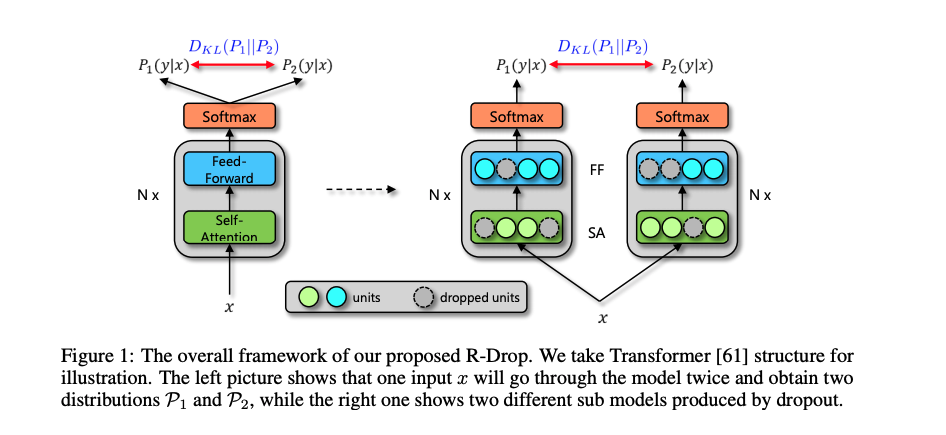
R-Drop-Regularized Dropout for Neural Networks
近年来,深度神经网络在各个领域都取得了令人瞩目的成功。在训练大规模的模型时,正则化技术是防止模型过拟合现象不可缺少的模块,同时具备提升模型的泛化(generalization)能力,其中,Dropout 是一个常见的正则化技术。本文作者在Dropout方法的基础上提出了一个正则方法R-Drop(Regularized Dropout),通过在一个batch中,每个数据样本经过两次带有 Dropout 的同一个模型,并使用 KL-divergence 约束两次的输出一致。实验结果表明,R-Drop在5个常用的包含 NLP 和 CV 的任务上(一共18个数据集)取得了不错的效果。
论文地址: https://arxiv.org/pdf/2106.14448.pdf
论文源码地址: https://github.com/dropreg/R-Drop
方法
本文作者提出的R-Drop模型结构如下所示:
具体来说,当给定训练数据D={xi,yi}(i=1)nD=\lbrace x_i,y_i \rbrace_{(i=1)}^nD={xi,yi}(i=1)n 后,对于每个训练样本 xi ...
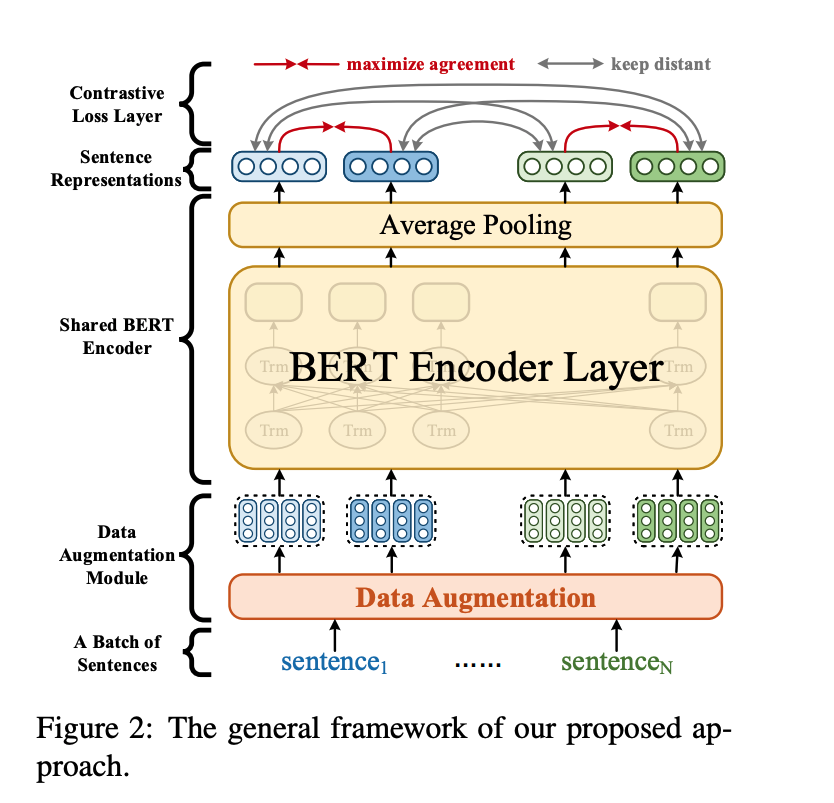
ConSERT-A Contrastive Framework for Self-Supervised Sentence Representation Transfer
尽管基于BERT的模型在诸多NLP任务中取得了不错的性能(通过有监督的Fine-tune),但其自身计算的句向量(不经过Fine-tune,而是直接通过对所有词向量求平均)往往被约束在一个很小的区域内,表现出很高的相似度(这种现象一般叫做"model Collapse"), 因而难以反映出两个句子的语义相似度。本文作者提出了一种基于对比学习的句子表示方法ConSERT (a Contrastive Framework for Self-Supervised SEntence Representation Transfer),通过在目标领域的无监督语料上微调,使模型生成的句子表示与下游任务的数据分布更加适配。实验结果表明,ConSERT在句子语义匹配任务上取得了state-of-the-art结果,并且在少样本场景下仍表现出较强的性能提升。
论文地址: https://arxiv.org/pdf/2105.11741.pdf
论文源码地址: https://github.com/yym6472/ConSERT
介绍
句向量表示学习在自然语言处理(NLP)领域占据重 ...
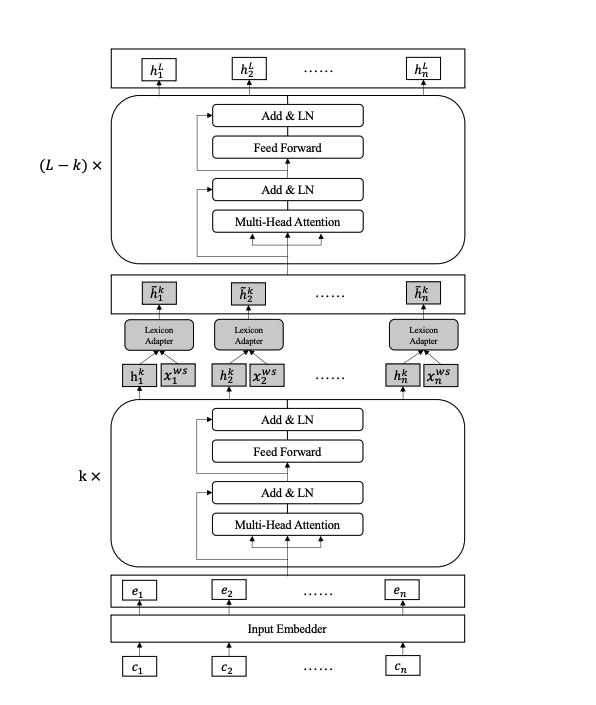
Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter
近年来,将外部词汇信息特征与预训练模型相融合是提高序列标注任务(如NER)效果的重要方法之一,比如FLAT、WC-LSTM等,但是,现有方法仅通过浅层模型表示和随机初始化的序列层融合词汇特征,并未与预训练模型如BERT进行融合。本文作者提出了用于中文序列标签的Lexicon增强BERT(LEBERT),通过一个Lexicon adapter层将外部词汇信息直接融合到BERT层中,与现有方法相比,LEBERT模型有助于在BERT的较低层进行深度词汇知识融合。实验结果表明,该模型在多个中文序列标注任务上取得了state-of-the-art结果。
论文地址: https://arxiv.org/pdf/2105.07148.pdf
论文源码地址: https://github.com/liuwei1206/LEBERT
介绍
常见一种将词汇信息与预训练模型相融合的方案是将预训练模型(如BERT)输出与词汇特征通过一个融合层(比如线性层)得到融合向量。如下图a所示:
本文作者认为该方案并没有充分利用到预训练模型的表示能力,因为外部词汇信息未融合到预训练模型之中,于是提出了另一种融合方案 ...

