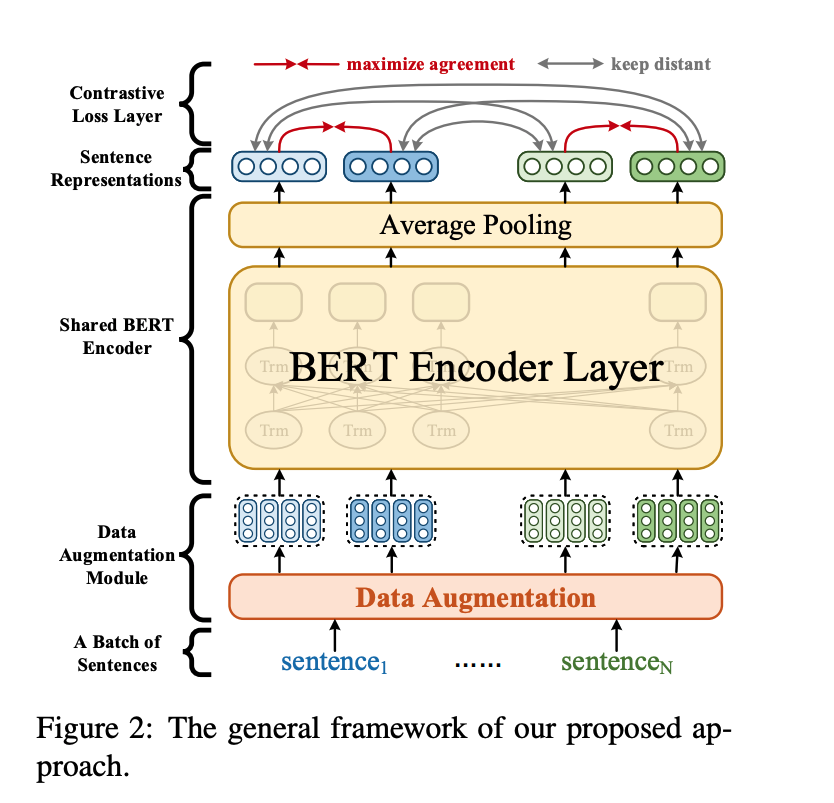
近年来,将外部词汇信息特征与预训练模型相融合是提高序列标注任务(如NER)效果的重要方法之一,比如FLAT、WC-LSTM等,但是,现有方法仅通过浅层模型表示和随机初始化的序列层融合词汇特征,并未与预训练模型如BERT进行融合。本文作者提出了用于中文序列标签的Lexicon增强BERT(LEBERT),通过一个Lexicon adapter层将外部词汇信息直接融合到BERT层中,与现有方法相比,LEBERT模型有助于在BERT的较低层进行深度词汇知识融合。实验结果表明,该模型在多个中文序列标注任务上取得了state-of-the-art结果。
介绍
常见一种将词汇信息与预训练模型相融合的方案是将预训练模型(如BERT)输出与词汇特征通过一个融合层(比如线性层)得到融合向量。如下图a所示:
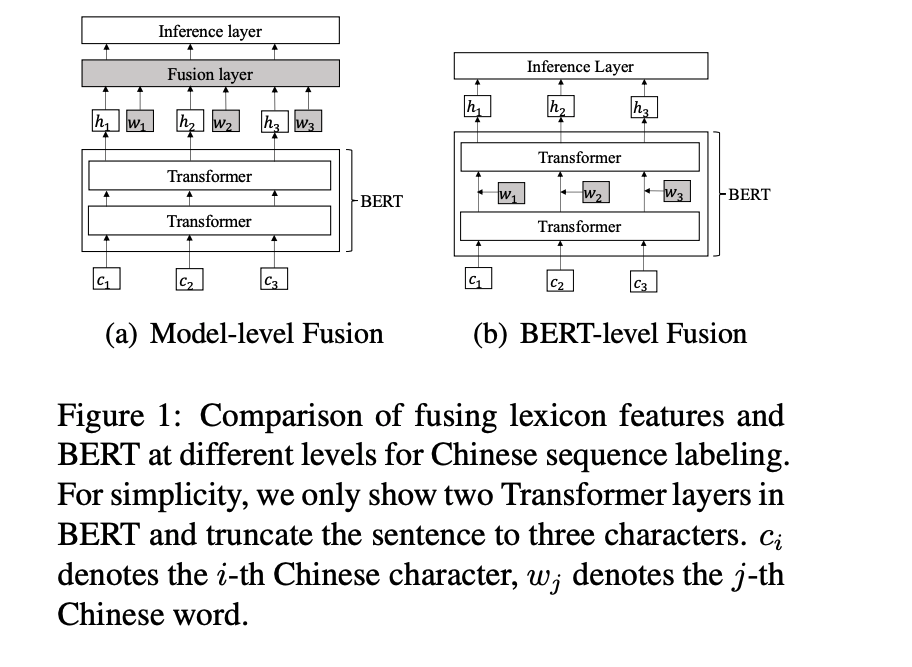
本文作者认为该方案并没有充分利用到预训练模型的表示能力,因为外部词汇信息未融合到预训练模型之中,于是提出了另一种融合方案,如上图b所示,相比较图a,该融合方案将外部词汇信息与BERT模型中的某个层中,这使得字信息与词汇能够通过BERT模型强大的表示能力进行更有效的融合。
方法
本文作者提出的LEBERT模型结构如下:
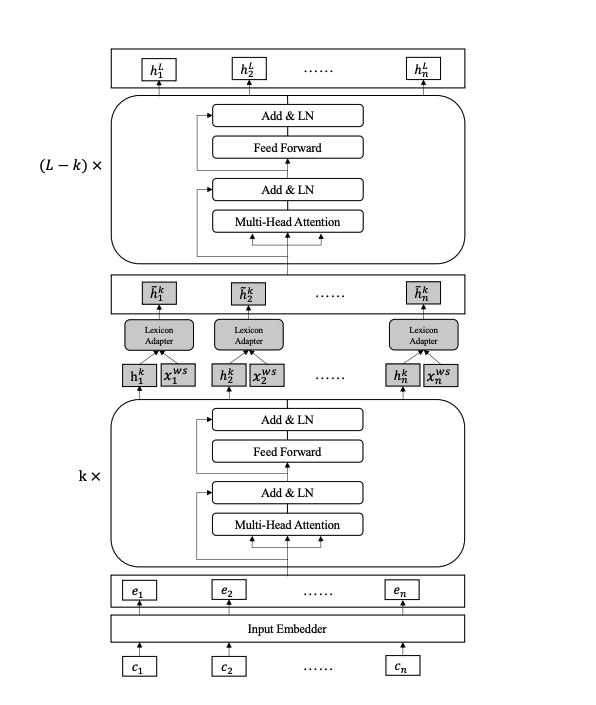
与BERT相比,LEBERT有两个主要区别:
-
LEBERT将字符和词典特征都作为输入,即将中文句子转换成一个Char-Words Pair Sequence。
-
在Transformer层之间应用一个Lexicon Adapter层连接,使得词汇信息能够有效地融合到BERT中。
Char-Words Pair Sequence
首先,对于给定的中文句子 ,利用词典 匹配出句子中包含的潜在词汇。然后,在匹配到的这些词汇中,每个字符和包含该字符的词汇组成词汇对,表示为,其中 表示句子中第i个字符, 表示包含字符的词汇组成的集合。例如,对于句子“美国人民“,根据词典信息,我们可以得到”美国“、”美国人“、”美国“、”国人“、“人民”这几个词,然后将这些词和对应的字组合起来,如下所示:
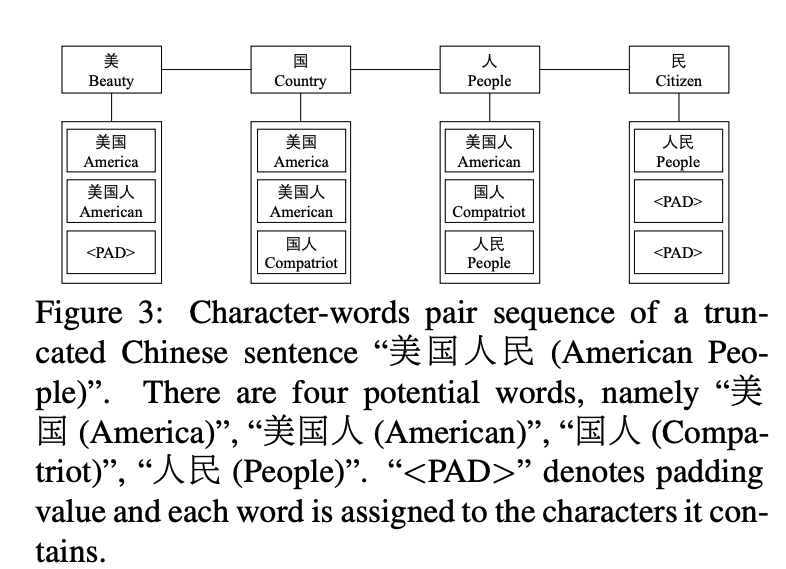
PAD表示padding操作,对不同长度词组进行补长成等长序列。
Lexicon Adapter
Lexicon Adapter层结构如下:
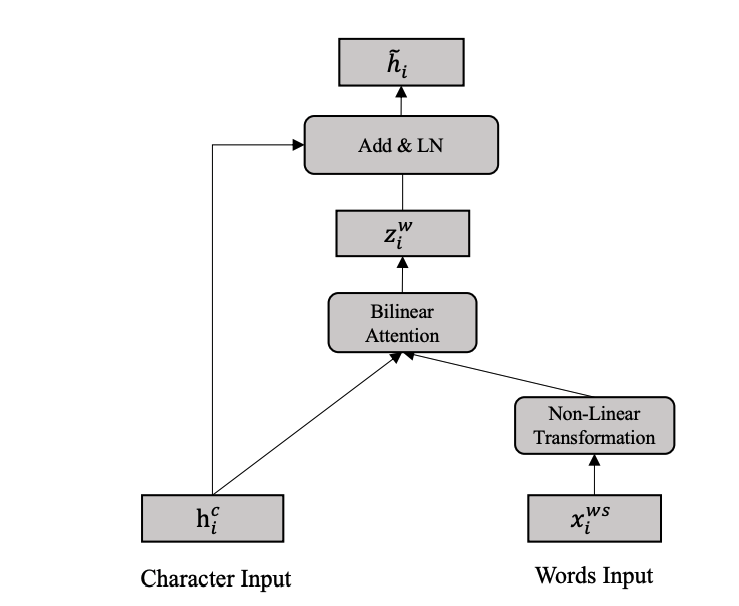
将输入数据构建成Char-Words Pair Sequence形式之后,句子中的每个位置包含了字符特征和词汇特征。为了把词汇特征融合到BERT当中,作者设计了Lexicon Adapter结构,Lexicon Adapter的输入为Char-Words Pair Sequence: 。Char-Words Pair Sequence中第i个位置的char-words pair表示为 ,其中 是第i个位置的字符特征,该特征是BERT中某个Transformer层的输出。 为第i个位置的字符对应的词汇的词向量,其中可通过预训练词向量得到,即:
其中表示预训练词向量,为词序列中的第j个词。
为了保证词向量和字符向量维度保持一致,作者对Char-Words Pair中的词向量使用非线性变换:

其中 , , 为字符特征的维度, 为词向量的维度。
对于Char-Words Pair Sequence中的第i个位置,进行维度变换后的词向量的集合为:
每个字符包含多个词,对于不同任务而言,每个词的贡献不一样,因此,为了从所有词汇列表中获得最相关的词,作者使用了注意力机制对的m个词向量进行融合。以 为query向量,与其对应的词向量集合 为value,使用双线性变换矩阵计算相似度得分得到:
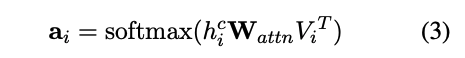
之后,利用相似度得分对进行加权求和得到融合后的词表示:
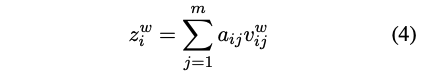
最后,把字符表示和融合后的词表示相加得到:
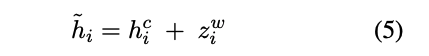
Lexicon Enhanced BERT
LEBERT可以看做是Lexicon Adapter和BERT的组合,其中Lexicon Adapter层应用到了BERT当中的某一个transformer层中。
对于给定的中文句子 ,将其构建成character-words pair sequence形式。其中BERT的输入为,假设第k层transforner输出为,且Lexicon Adapter 嵌入到第k层和第k+1层Transformer层之间,即将其中的每一个Char-Words Pair 利用Lexicon Adapter进行转换得到:
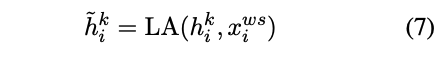
然后将融合词汇信息的特征向量输出入到余下的L-k个Transformer层中。
实验
为了探究LEBERT在序列标注任务上的有效性,本文在三个任务共10个数据集上实验:中文命名实体提取、中文分词和中文词性标注:
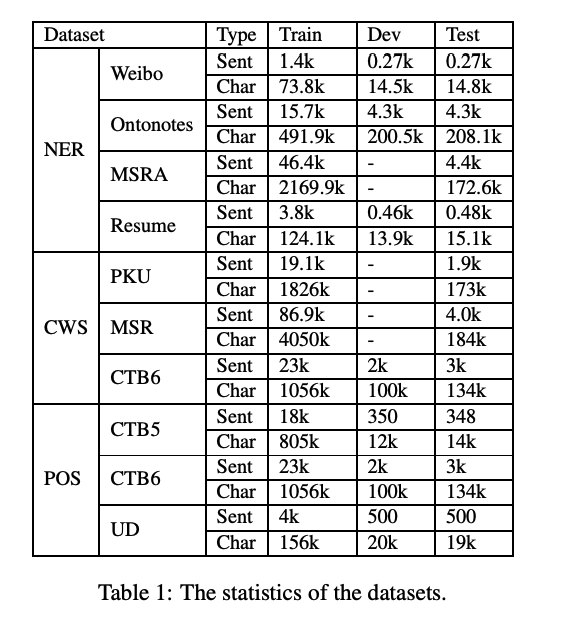
所有的实验都基于预训练好的BERT和词向量。
实验结果

首先来看看LEBERT在NER任务上的效果,从上图可以看到,LEBERT的性能超过目前最先进的词增强NER模型。
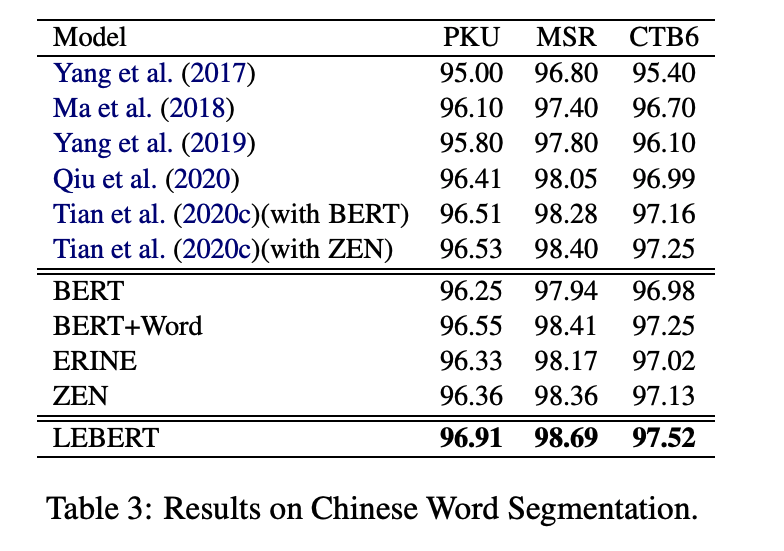

从上图中可以看到,LEBERT模型同样在中文分词任务、中文词性标注任务中达到了最优效果
Adaptation at Different Laye
对于Lexicon Adapter层的不同位置实验结果如下表所示:

从上图可以看出,LA层应用到浅层实现了更好的性能,这可能是因为浅层促进了预训练模型表示特征和词汇特征之间更多层次的相互作用。而在LA应用到多层中会损害性能,可能原因是多层集成导致过度拟合。
小结
本文中提出了一种新的方案来融合词汇特征和预训练模型表示,该方案通过一个Lexicon Adapter层应用于预训练模型中transformer层之间以融合词汇特征。与现有方法相比,LEBERT模型有助于在BERT的较低层进行深度词汇知识融合。实验结果表明,该模型在多个中文序列标注任务上取得了state-of-the-art结果。