从BERT面世的第二天,笔者就实现了BERT用于序列标注的工作,几乎是全网最早的用BERT做序列标注的工作,到今天离线场景下,BERT做序列标注已经成为一种普惠技术。从huggingface开源Transformers的几乎最早的时间开始跟进,复现组内早期基于Tensorflow做中文纠错的工作,之后模型侧的工作基本一直基于该框架完成。从BERT早期的一系列比较fancy的工作一直在跟进,到组内推广Transformers的使用,到如今PyTorch地位飙升,Transformers社区受众极广,BERT几乎是笔者过去很长一段时间经常讨论的话题。
但是,围绕BERT,最为诟病的一个问题:模型太重,inference时间太长,效果好,但是在线场景基本不能使用?
围绕该问题,学术界和工业界有太多的工作在做。这篇文章简单梳理一些具体的研究方向,同时围绕笔者个人比较感兴趣的一个方向,做一些评测和对比。
那么,具有有哪些研究方向呢?整体上,有两种观察视角。一种是train和inference,另一种是算法侧和工程侧,这里不做具体的区分。
- 模型大,是慢的一个重要原因,那就换小模型
- 模型大,通过模型设计,有些部分是可以快的
- 模型蒸馏
- 模型压缩剪枝
- 模型量化:混合精度
- 服务优化:CPU或者GPU推断,请求管理(批式或者流式),缓存
- 其他
每个方向都有大量的工作出现,这篇文章主要讨论偏向于工程侧的优化方式。基于huggingface的Transformers的实现,支持不同的模型加载方式native,onnx,jit,libtorch(c++),native c++(fastertransformer和其他c++版实现),tensorRT,tensorflow serving共七种方式。
统一的请求接口设计
为了测试不同的inference速度,并不限于模型类型,这里固定模型条件,统一为MaskedLM(bert-base-uncased)。假设脱离本文的主题设定,模型类型显然是影响inference速度的关键因素,这里分为两种条件,第一是不同的模型类型,比如TextCNN和BERT;第二是BERT的不同实现,比如Layer数量的不同,特殊Trick的使用等。
核心接口代码如下:
1 | #预处理:载入分词器 |
得益于Transformers的优雅的接口设计,可以利用两行代码加载分词器,类似的,可以用两行代码加载模型:
1 | from transformers import AutoModelForMaskedLM |
不同的inference方式
native
朴素的方式是直接加载pytorch_model.bin,config.json, vocab.txt,作为server端的模型。核心服务代码如下:
1 | import torch |
这种方式是平时pytorch用户使用最多的方式。
onnx
笔者第一次接触onnx是2018年做CV的时候,那个时候需要将一个PyTorch的模型转化为onnx,做android移动端的部署,大概在那个时候,不同框架之间的模型转化已经成为一个业界的实际需求。为了通过onnx加载模型,首先需要将native的模型转化为onnx的模型。模型转换代码如下:
1 | import torch.onnx |
这里转换的逻辑中,有一个细节。导入模型之后,需要通过构造一个dummy tensor才能够获取网络的结构,同时模型转换中提供了一些优化的方式。
核心服务代码如下:
1 | import onnxruntime |
jit
使用jit的方式,同样需要做模型转换,转换代码如下:
1 | with torch.no_grad(): |
核心服务代码如下:
1 | model = torch.jit.load(model_path) |
libtorch(c++)
采用libtorch(c++)加载的模型同jit,服务端的核心加载代码如下:
1 | #include "torch/script.h" |
这里值得一提的是,不同于python的server端,可以选择fastAPI,flask,gunicorn等,c++也有对应的server端,典型的比如crow。使用该种方式的一个问题是:要解决c++编译的各种依赖问题。
备注:其他三种方式暂未测试
评测结果
| 加载方式 | onnx | native | jit | libtorch(c++) | 备注 |
|---|---|---|---|---|---|
| 时间(相同请求次数) | 6.20s | 7.07s | 6.83s | libtorch(c++),限于各种依赖,笔者未测 | 笔者的结果 |
| 时间(相同请求次数) | 12.43s | 19.43s | 18.24s | 12.10s | 他人的结果 |
笔者个人的环境和他人的环境不相同,因此具体时间上不同,但是趋势是基本一致的。onnx和libtorch(c++)的方式都较快,NLP算法同学中,python用户居多,因此选择onnx是一种比较理想的方式。native是最慢的,也就是说最常用的方式恰恰是inference效率最低的方式。jit介于两者之间。
对于没有实测过的结果,这里给出一张他人的评测结果,如下:
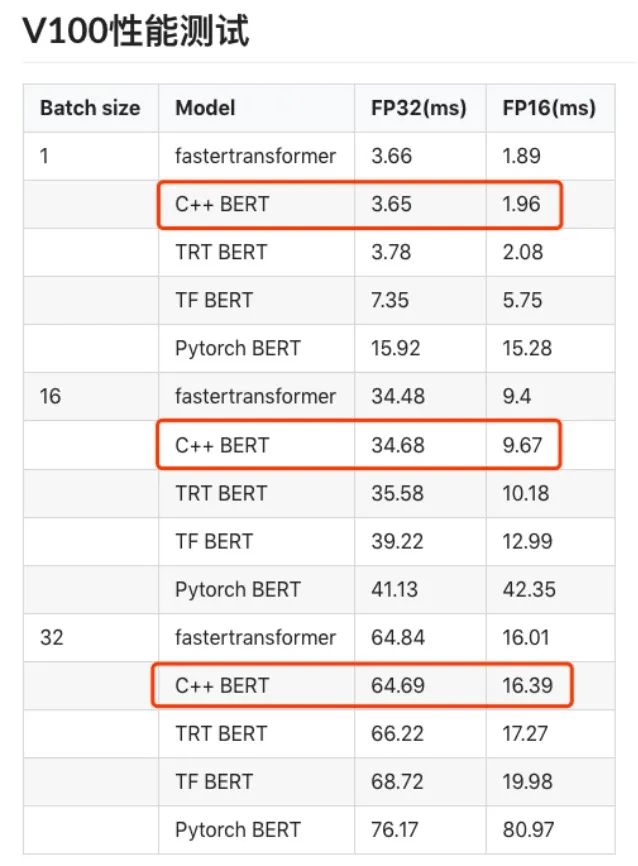
对比可知:说啥都没有用C++重写一遍来的快!笔者在之前做过一个表格数据处理的加速,向量指令,cache等多种技术都有尝试,最后发现,C++重写一遍核心逻辑,速度立刻显著提升。关于BERT的C++实现,可以参考字节的开源工作。
说了辣么多,咋整吧?只能具体情况具体分析了。从整体上看BERT的加速可以从多个方面开展。但是围绕这篇文章的主题,C++的加速方式效果最理想,但是成本也较高。onnx的方法目前来看,成本较低可执行。实际上,最近的天池的小布助手比赛中,Top选手也多采用了这种方案,但是采用tensorRT的方式也有,这篇文章没有做实测,可以作为一种备选的方案。此外,配合低精度,服务优化等方式。不论怎样,从一开始,结合对数据的理解,选择一个小的模型,使用最native的方式也许就可以满足inference的要求了。蒸馏和剪枝在技术上比较fancy,需要反复的迭代和优化。
转:The following article is from KBQA沉思录 Author zhpmatrix
参考资料:
- 转换pytorch的预训练模型到pb文件,用C++去加载
- 知乎的BERT加速工作,上述工作间接参考本工作,工作比较底层(C++/CUDA)
- 那一年,让我整个人升华的C++BERT项目
- BERT-cpp-inference
- Pytorch的C++前端和模型部署
- 直观认识torch.jit模块
- service-streamer,工程色彩比较浓重的工作
- 模型热更新小记
- 微软自家的demo,在该工作中,提供了一些性能测试工具,包括针对ort本身开发的profiler
- 一个更详细的demo
- 快手异构计算团队基于nvidia的fastertransformer进一步做了底层优化,具体包括:算法融合和重构,混合精度量化,内存管理优化,输入padding移除,GEMM配置优化
- 微信AI的工作,同样基于nvidia的fastertransformer进一步做底层优化,具体包括:kernel优化(softmax+layernorm),针对可变序列长度的内存分配算法,针对可变序列长度的batch调度器。
- fastertransformer的源码阅读