Kaggle竞赛-Home Credit Default Risk小结
竞赛网址:kaggle home credit default risk
Home Credit
Home Credit(中文: 捷信消费金融有限公司)是中东欧/亚洲的一家消费金融提供商, 为客户提供金融服务.
比赛简介
业务背景
Home Credit希望能通过数据挖掘和机器学习算法来估计客户的贷款违约概率.
数据
- (1) application_train/test 客户申请表
包含了目标变量(客户是否违约-0/1变量), 客户申请贷款信息(贷款类型, 贷款总额, 年金), 客户基本信息(性别, 年龄, 家庭, 学历, 职业, 行业, 居住地情况), 客户财务信息(年收入, 房/车情况), 申请时提供的资料等.
- (2) bureau/bureau_balance 由其他金融机构提供给征信中心的客户信用记录历史(月数据)
包含了客户在征信中心的信用记录, 违约金额, 违约时间等. 以时间序列(按行)的形式进行记录.
- (3) POS_CASH_balance 客户在Home Credit数据库中POS(point of sales)和现金贷款历史(月数据)
包含了客户已付款和未付款的情况.
- (4) credit_card_balance 客户在Home Credit数据库中信用卡的snapshot历史(月数据)
包含了客户消费次数, 消费金额等情况.
- (5) previous_application 客户先前的申请记录
包含了客户所有历史申请记录(申请信息, 申请结果等).
- (6) installments_payments 客户先前信用卡的还款记录
包含了客户的还款情况(还款日期, 是否逾期, 还款金额, 是否欠款等).
结果评判标准
比赛最终要求提交每个ID的违约概率, 以此计算得到的AUC作为评判标准.
我的参赛方案
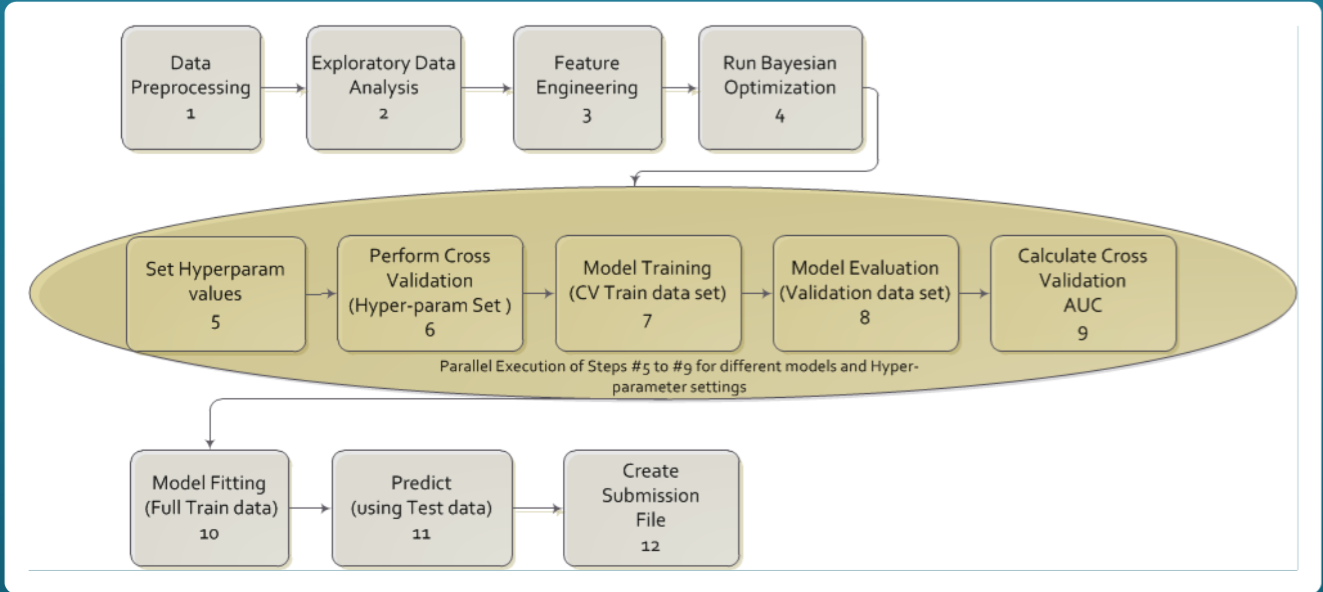
本次比赛的数据量不大, 训练集31万条, 测试集5万条, 但特征很多, 原始特征加起来超过200个, 而且分散在多个表. 所以首先要梳理清表的内容和表之间的关联, 从实际业务的角度来构造每个用户的特征. 整个Pipeline大致为: (1) 分析每张表的数据, 构建特征并保存; (2) 将所有表的特征通过Left Join到一起; (3) 构建表之间的交互特征; (4)训练模型. 下面简单介绍下我的参赛方案(130/7198).
特征工程:
- 原始特征:
包括了原始特征和通过简单操作(加减乘除/分箱)构造的新特征, 比如客户收入和贷款总额的比率, 客户家庭人均收入, 客户年龄段, 客户收入段等.
- 统计特征:
除了申请表之外, 其他的表包含的单个客户数据都是一个时间序列, 因此可以对这个时间序列进行聚合(aggregation)求汇总统计量(mean/median/std/max/min/sum)等; 也可以根据分类变量(职业/行业/学历/年龄段/申请是否通过)等对数值变量(收入/贷款额/年金)进行聚合汇总, 作为一个"相对参考"的特征, 然后对客户原始数值和该参考数值做差得到差值特征.
- 时序特征:
只对一个时间序列求汇总统计量还是会损失不少信息, 从业务角度看, 客户的前几次申请和信用情况也非常重要. 所以可以按照 (1) 固定时间窗: 离本次申请最近的30/60/90/120天内的信用情况; (2) 固定次数: 本次申请的前1/2/3/5/10次申请情况来构造新特征, 继续采用汇总统计量.
- 弱模型特征:
这部分特征思路源于先前Avito比赛中的kernel: LightGBM with Ridge Feature, 即采用较弱模型得到out-of-fold预测值作为训练集特征, 预测值作为测试集特征, 属于模型Stacking. 我训练了Ridge/Logistic Regression(将Ridge的输出放到sigmoid函数中)/Factorization Machine/Neural Nets, 以及来自Scirpus的kernel Pure GP with LogLoss中的GP特征, 分别将这些模型的oof放入训练集, prediction放入测试集, 和别的特征一起重新训练新的模型.
模型:
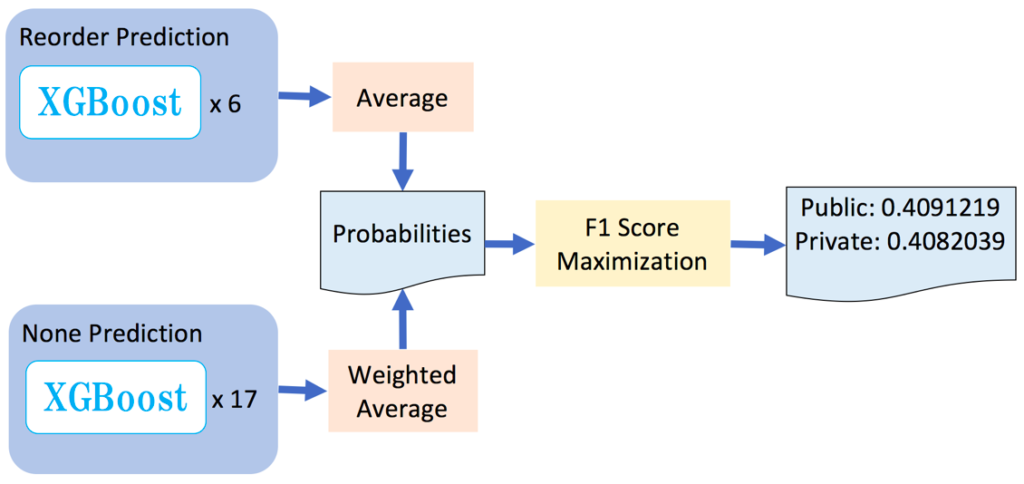
- LightGBM/XGBoost: 最终融合了7-8个模型, 模型之间的差别在于预处理(是否移除缺失值/缺失值是否填补)/特征(不同的特征选择结果)/超参(自己调试的/来自kernel的baye化/Neptune-ml), 各个模型的cv在0.795-0.805之间, public lb分数在0.799-0.803之间, private lb分数在0.796-0.798之间.
- Ridge/Logistic Regression/FM: 因为cv分数很低, 所以将这些模型的oof和submission放入了Boosting模型中作为stacking;
- FFNN: 参考kernel - 10 fold Ridge from Dromosys Features LB-0.768, 同样cv不是很高, 所以将其oof和submission放入了Boosting模型.
最终融合的public lb分数最高为0.80556, private最高分数为0.79813.
训练与验证:
所有的单模都按5折和10折交叉验证进行训练, 对所有折取平均后进行提交. 这次比赛的cv和public lb并不十分一致, 一个原因在于public lb只保留了3位小数, 另一个原因在于public lb只有20%的数据. 相信cv是kaggle的第一原则, 我发现最后private lb最高的居然是一个单模, 而我当时没有将这个单模选入融合模型中. 在查看log之后发现该单模的cv并不是最好的, 且和其他几个单模有很高的相关性, 所以我没有选择它. 后来我分析可能原因在于我只计算了cv的均值, 忽略了标准差, 导致这一低级失误.
Top参赛方案
(1) 第1名 (Home Aloan)
(2) 第2名 (ikiri_DS)
原贴: 2nd place solution ( team ikiri_DS )
特征工程: 包括降维(PCA/UMAP/T-SNE/LDA), GP特征, 利率特征等. 团队成员较多, 细节可参考原贴.
团队成员Shuo-Jan Chang的分享: HC - Brief solution from Shuo-Jen, Chang
模型/训练和验证: LightGBM(with dart), Catboost, DAE, CNN, RNN.
该团队做了一张很好看的模型结构示意图:
团队的其中一个亮点在于Giba的发现(原贴: Congratulations, Thanks and Finding!!!): 他观察数据后发现可以识别到user_id(根据例如DAYS_BIRTH, DAYS_DECISION等一些用户自身属性), 在训练集和测试集中有8549个user有2行记录, 132个user有3行记录, 如果之前的申请记录目标变量为1, 则下一次申请有90%的可能也是1.
(3) 第3名 (alijs & Evgeny)
特征工程: 成员Evgeny有在银行的工作经历, 因此构建特征主要从实际业务出发. 总共构建了1000个左右的特征, 选择了其中的250个, 特征选择通过cv来进行(纯手动), 模型训练速度很快, 所以短时间内就能完成特征选择. 对于bureau表和previous_application表, 作者没有根据当前ID进行聚合(接下来的解释暂时没有看懂, 原文为: I used data without aggregation by sk_id_curr and used target from main application (same for all data for one client). I was very weak model Predicts were averaged by sk_id_curr after. This approach performed better in main model compared to model with aggregated data with better individual score.), 希望之后可以问清楚具体细节. Evgeny还构建了可以预测EXT_SOURCES的模型, 预测值和残差值都是比较有用的特征(这个操作和Avito比赛中以商品价格预测值为特征是一样的), 他还尝试了预测收入, 但是没有用.
成员alijs主要构建了统计特征.
模型/训练和验证: 在不同的数据表上建立了不同的模型. alijs训练了50个左右不同的模型, 选择了7个互相之间最不相关的模型而不是根据cv. 最后构建了4层的stacking, 包含了LightGBM, Random Forest, ExtraTree, Linear Regression.
(4) 第4名 (Quad Machine)
原贴: 4th place sharing and tips about having a good teamwork experience
特征工程: 趋势特征, 在installment_payment/POS_CASH_balance/bureau表中最近的1/3/5/10条记录特征; 在使用bayes优化超参的时候将预测值保存下来作为oof; 在进行模型stacking之前进行了特征选择, 包括使用LightGBM的特征重要程度, Olivier的特征选择法(kernel见文末).
模型/训练和验证: 在不同的特征子集上训练模型, 总共训练了200个模型; 除此之外还进行后post-processing, 对于revolving贷款, 如果预测值超过0.4, 则乘以0.8, 因为revolving贷款在测试集中出现的较少, 这个比较trick, 作者认为这个方法不太会适用于别的场景.
团队成员Kain在讨论区回答了很多较为细节的问题, 请参考原贴. 下周该团队会把代码公布到github上.
(5) 第5名 (Kraków, Lublin i Zhabinka)
原贴: Overview of the 5th solution +0.004 to CV/Private LB of your model
特征工程: 构建了8000个特征, 最终基于Olivier的特征选择法保留了3000个. 将分类变量数值化(类似LabelEncoding); 各种统计groupby特征, 包括对时间窗进行groupby处理.
模型/训练和验证: 该团队在模型构建方面有不少特别之处, 包括:
- NN:提取不同数据表之间的交互特征
来自不同表格的信息交互很难通过人为判断进行提取, 因此尝试用NN构建用户画像, 将其转化为用户分类问题. 在每张数据表上(application表除外)都可以构建一个用户的向量(每个月的数据), 然后将这些向量合并到一起, 得到一个较为稀疏的用户画像. 然后构建如下NN: (1) 对每个向量进行normalization: 除以最大值; (2) 输入为96个向量, 每个月为一个向量; (3) 1维卷积层(Conv1D); (4) Bidirectional LSTM; (5) Dense层; (6) 输出.
这个模型cv为0.72, 加入stacking之后有0.001的提升.
- Nested模型
不同的groupby特征之间的关系很难理清. 例如5年前的违约记录肯定没有1个月前的违约记录来的重要. 因此构建了Nested模型. 以installment_payment表为例, 根据当前ID将application表中的目标变量加入到installment_payment表中, 然后训练一个LightGBM来预测每条记录对应的目标变量值, 可解释为"怎样的installment行为会对目标变量产生怎样的影响". 为此可以得到许多oof, 对这些oof按当前ID进行聚合可以作为新的特征.
接着作者还提到了对credit_card_balance表所做一些操作, 对cv有不小的提升, 但最后产生了过拟合, 因为贷款类型在训练集和测试集的分布差别较大.
- 利率/当前贷款的期限预测模型
这部分的理解需要一定金融知识, 待更新, 细节可见原贴.
- 银行系统打分模型
基于application/previous_application表构建了logit和probit模型, 对cv和public lb有一定的提升.
(6) 第7名 (A.Assklou _ Aguiar)
原贴: 7th solution - Not great things but small things in a great way.
特征工程: 提取了500个左右的新特征(groupby特征), 有4个特征对模型有0.04的提升: NEW_CREDIT_TO_ANNUITY_RATIO, EXT_SOURCE_3, INSTAL_DAYS_ENTRY_PAYMENT_MAX, DAYS_BIRTH.
模型/训练和验证: 采用了11个不同的LightGBM和2个NN, 最后用Linear Regression进行stacking, 所有的模型评判都以cv为准.
(7) 第8名 (七上八下)
特征工程: 将所有表根据当前ID和时间融合到一起; 根据还款逾期天数(DPD)进行分箱处理(30/60/90/120); 将credit_card_balance表与application表融合后的大量NA用0进行填充. 在组队完成后, 将所有的特征放到一起训练一个单模, 同时发现将在单个表上训练得到的oof作为特征对cv和public lb都有提升.
模型/训练和验证: 最好的单模都是LightGBM. 采用Stratified 10折验证, local cv和private lb的走势十分一致. 最终的模型stacking框架图在讨论区给出, 每个团队成员都在单张数据表上训练了LightGBM/XGBoost/Random Forest/Logistic Regression, 输出oof, 再加上每个成员的全部特征集上训练输出oof, 用LightGBM(regressor)和Random Forest进行stacking.
(8) 第9名 (International Fit Club)
原贴: #9 Solution
特征工程: 成员CoreyLevinson, 没有在所有历史数据上进行groupby特征提取, 而是在最近的数据上进行(最近3/6/9/12/18/24/30个月); 替换测试集存在而训练集中不存在的类别; 对一些二分变量进行求和(FLAG_DOCUMENT_, REG_CITY_等); 比率特征; 将一些分类变量聚合到一起再进行Encoding等.
成员Suchith Mahajan, 通过对日期信息进行一定处理得到"multiplier", 然后应用到数值变量上, 用于反应时间信息. 细节可见原贴.
模型/训练和验证: LightGBM(dart), Entity Embedded NN(参考自Porto Seguro比赛), XGBoost, MICE imputation Model. 最后构建了一个使用200个模型的6层stacking, 使用Logistic Regression作为最后的stacker.
(9) 第10名 (Best Friend Forever: CV)
特征工程: 利率特征, 现金贷款模型: 根据实际金融业务知识构建特征; 训练LightGBM来预测EXT_SOURCE_1和EXT_SOURCE_3, 因为EXT_SOURCE_有较多的缺失值.
模型/训练和验证: LightGBM等. 在stacking时根据cv来选择最终提交结果, 使得最后private lb的分数进入了金牌区.