以往我们在构建模型并进行训练时,一般都是先建立placeholder,然后使用Seeion中的feed_dict机制将数据feed给模型进行训练或者预测。使用这种方式十分灵活,可以将所有数据读入内存中,然后按照batch进行feed;也可以建立一个generator,然后按照一个batch大小将数据读入。但是这种方式效率较低,难以满足高速计算的需求。Tensorflow开发者也建议停止使用这种方式进行数据交互操作。因此在后续的Tensorflow新版本中,我们看到了Dataset这种高效的数据处理模块。
创建Dataset
在Dataset模块中,每一个数据集代表一个数据来源:数据来源可能来自一个张量,一个文本文件,一个TFRecord文件,或者一个numpy等等。如果训练数据无法全部写入内存中,这时候我们可以使用一个迭代器(iterator)按顺序进行读取。
接下来,我们简单看看不同数据源的读取方式:
from_tensor_slice:该方法接受单个(或多个)Numpy(或张量)对象。如果输入的是多个对象,则需要保证多个对象之间的大小相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import tensorflow as tfimport numpy as nptf.enable_eager_execution() input_data = [1 ,2 ,3 ,4 ,5 ,8 ] dataset = tf.data.Dataset.from_tensor_slices(input_data) iterator = dataset.make_one_shot_iterator() x = iterator.get_next() print (x.numpy())dataset2 = tf.data.Dataset.from_tensor_slices((tf.range (30 ,45 ,3 ),np.arange(60 ,70 ,2 ))) iterator2 = dataset2.make_one_shot_iterator() x = iterator2.get_next() print (x[0 ].numpy(),x[1 ].numpy())```` 2. from_tensors:与from_tensor_slice一样,这个方法也接受单个(或多个)Numpy(或张量)对象。但这种方法不支持batch数据输出,而是一次性输出所有数据。因此,如果要输入的是多个对象,这种方法允许大小不一样。一般而言在数据集非常小或者模型需要一次所有数据的情况下,才使用该方法。```python dataset3 = tf.data.Dataset.from_tensors(tf.range (10 ,15 )) iterator3 = dataset3.make_one_shot_iterator() x = iterator3.get_next() print (x.numpy())dataset4 = tf.data.Dataset.from_tensors((tf.range (10 ),tf.range (5 ))) iterator4 = dataset4.make_one_shot_iterator() x = iterator4.get_next() print (x[0 ].numpy(),x[1 ].numpy())
from_generator:在该方法中,输入的是一个生成器函数。如果你希望在运行时生成数据(不存在原始数据),或者训练数据非常庞大(无法将其存储在磁盘中),这种方法非常有用。但是强烈建议不要使用这种方法来进行数据增强操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def generator (sequence_type ): if sequence_type ==1 : for i in range (5 ): yield 10 + i elif sequence_type ==2 : for i in range (5 ): yield (30 + 3 *i,60 +2 *i) elif sequence_type == 3 : for i in range (1 ,5 ): yield (i,' ' .join(['hi' ] * i).encode()) dataset5 = tf.data.Dataset.from_generator(generator,output_types=(tf.int32),args=([1 ])) iterator5 = dataset5.make_one_shot_iterator() x = iterator5.get_next() print (x.numpy())dataset6 = tf.data.Dataset.from_generator(generator,output_types=(tf.int32,tf.int32),args=([2 ])) iterator6 = dataset6.make_one_shot_iterator() x = iterator6.get_next() print (x[0 ].numpy(),x[1 ].numpy())dataset7 = tf.data.Dataset.from_generator(generator,output_types=(tf.int32,tf.string),args=([3 ])) iterator7 = dataset7.make_one_shot_iterator() x = iterator7.get_next() print (x[0 ].numpy(),x[1 ].numpy())
TextLineDataset:在实际项目用,训练数据集一般都是保存在磁盘中,比如自然语言任务中训练数据通常是以每行一条数据的形式存在文本文件中,这时候我们可以使用该方法读取数据:
1 2 3 4 5 6 input_files = 'nietzsche.txt' dataset8 = tf.data.TextLineDataset(input_files) iterator8 = dataset8.make_one_shot_iterator() x= iterator8.get_next() print (x.numpy())
TFRecordDataset:在图像相关任务中,一般是以TFRecord形式保存,这时候可以使用该方法进行读取,需要注意的是,每一个TFRecord都有自己不同的feature格式,因此需要一个parse函数来解析数据格式
1 2 3 4 5 6 7 def _parse_record (example ): pass input_file = 'data.tfrecords' dataset9 = tf.data.TFRecordDataset(input_file) dataset9 = dataset9.map (_parse_record) iterator9 = dataset9.make_one_shot_iterator() x= iterator8.get_next()
数据转换
一旦创建完Dataset之后,我们可以对数据进行多种转换操作,比如:
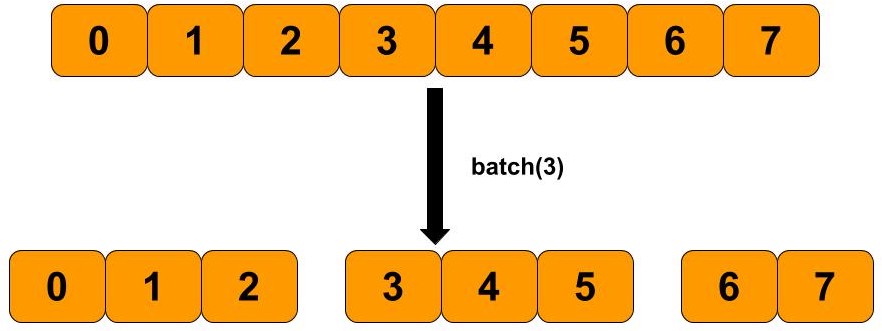
batch:按照指定大小对数据进行顺序划分。
1 2 dataset = tf.data.Dataset.from_tensor_slices(tf.range (5 )) dataset1 = dataset.batch(2 )
Repeat: 复制数据,即重复生成多份。
1 dataset2 = dataset.repeat(2 )
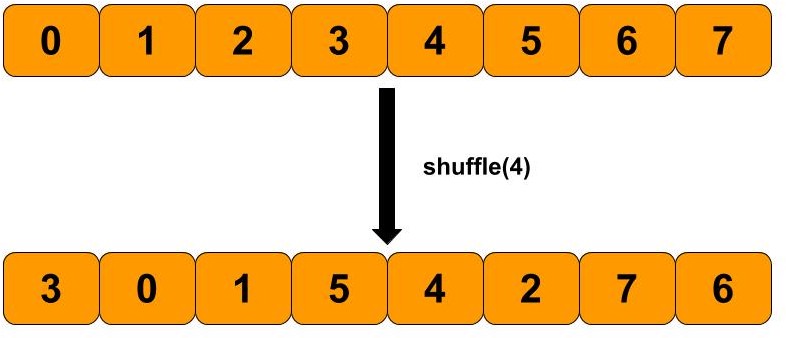
shuffle:对数据进行混洗,即打乱原始数据的顺序。
1 dataset3 = dataset.shuffle(4 )
Map:map变换中,主要对数据集中的每条数据进行指定的操作。
1 2 dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0 , 2.0 , 3.0 , 4.0 , 5.0 ]))dataset = dataset.map (lambda x: x + 1 )
Filter:过过滤掉一些不合理数据。
1 dataset4 = dataset.filter (lambda x:x>0 )