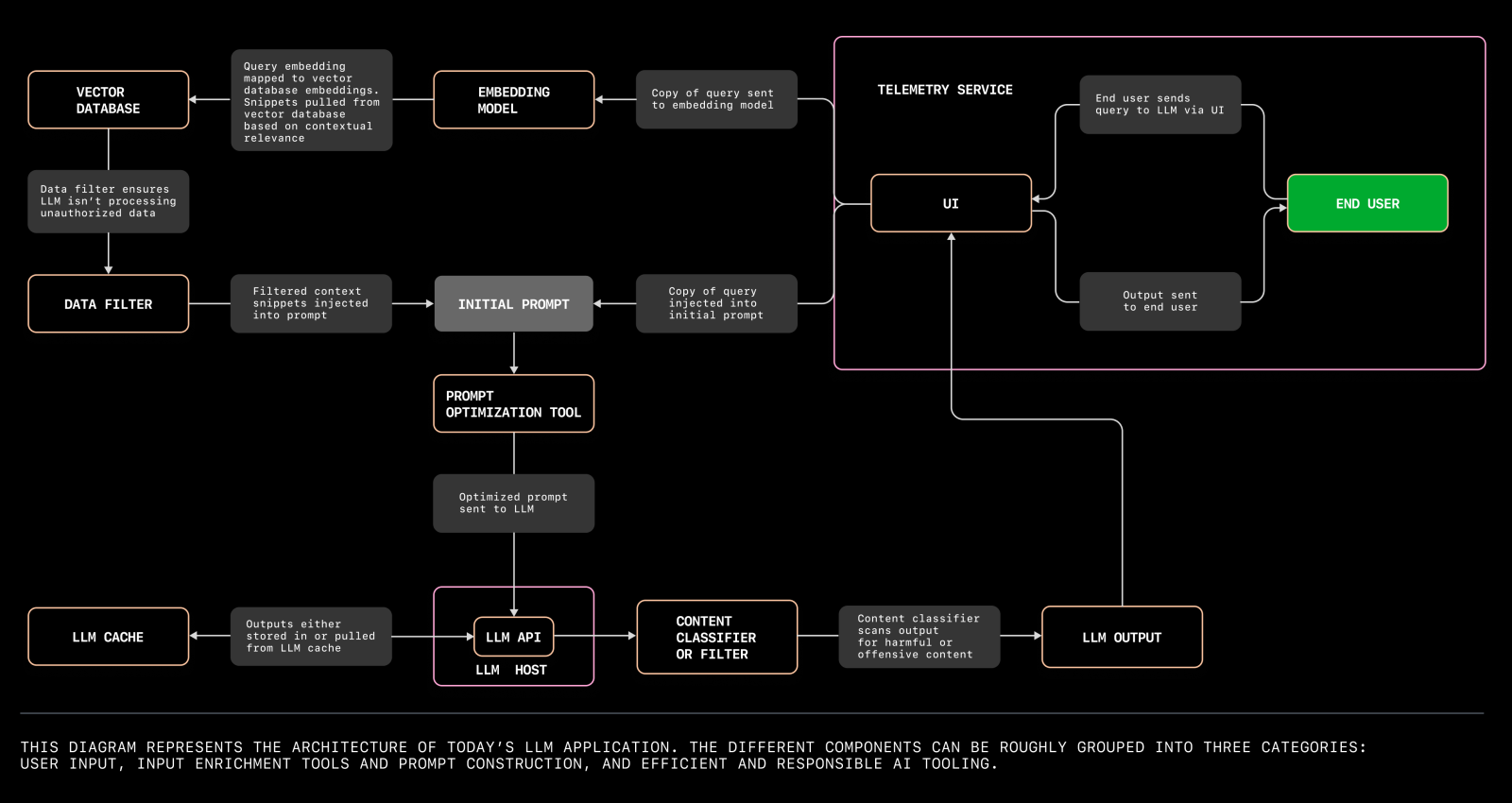
大语言模型应用架构
本文将介绍构建您首个大语言模型应用所需了解的一切,以及您今天就能开始探索的潜在问题领域。
我们旨在帮助您实验大语言模型 (Large Language Model),打造个人应用程序,并挖掘未被充分利用的问题空间。因此,我们特邀了 GitHub 的资深机器学习研究员 Alireza Goudarzi 和首席机器学习工程师 Albert Ziegler,共同探讨当前大语言模型应用的最新架构。
本文将深入讲解如何构建您个人的大语言模型应用的五个关键步骤,当前大语言模型应用的新兴架构,以及您可以立即开始探索的问题领域。
构建大语言模型应用的五个关键步骤
在使用大语言模型(LLM)或任何机器学习(ML)模型构建软件时,与传统软件开发有本质的不同。开发者不再仅仅是将源代码编译成二进制来运行命令,而是需要深入理解数据集、嵌入和参数权重,以产生一致且准确的输出。重要的是要认识到,LLM 的输出结果是基于概率的,并不像传统编程那样可预测。
现在,让我们梳理一下今天构建大语言模型应用程序的主要步骤:👇
1. 首先,专注解决一个问题。关键在于找到一个适中的问题:它需要足够具体,让你能快速迭代并取得进展 ...

OpenAI如何优化LLM的效果
精简版:
两个优化方向:上下文优化和 LLM优化
三种优化方法:Prompt Engineering → RAG → Fine-tuning
提示工程(Prompt Engineering) 是开始优化的最佳起点。它适合于早期的测试和学习,尤其是当与评估结合使用时,它为进一步的优化建立了基准。但提示工程并不适合于引入新信息,或者可靠地复刻一个复杂的风格或方法。
检索增强生成(RAG) 适合引入新的信息,以及通过控制内容来减少幻觉。RAG 可以认为是一种 Dynamic Prompt Engineering,或者注入额外的信息。HyDE 在某些应用中能提升效果,值得了解下。使用 Ragas 度量标准对 RAG 进行性能评估。
模型精调(Fine-tuning) 可以改进模型性能,降低指令的复杂度。但它不适合给模型添加新知识。
这三种优化方法不是互斥的,可以联合使用,多次迭代直至最优。
优化的两个方向
分享讲述了 LLM 优化时需要考虑的两个方向:上下文优化(Context Optimization) 和 LLM优化。
上下文优化: 模型需要知道什么信息才能 ...

How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition
SFT是目前最常见的调节模型效果的手段,然而它虽然看起来简单(准备好数据->启动),真正优化起效果来却困难重重,尤其是当我们有一堆能力项要优化时(推理能力、闲聊能力等),事情往往不会像我们预想的那样发展,单独调节能力和混合调节能力完全是两个难度。
论文地址: https://arxiv.org/pdf/2310.05492.pdf
数据(数学推理,翻译,代码,通用能力等),来解锁大模型多样化的能力。然而由于不同能力项的数据的来源、领域、分布,以及数据规模的不同,这些因素都将对模型性能产生剧烈的影响。因此,SFT的数据组成问题旨在探究模型能力与各种能力项数据之间的关系,包括不同能力项的数据量、数据配比、模型参数量和微调训练策略等,这对未来全面提升大模型的奠定了坚实的基础。
本文聚焦于SFT阶段的数学推理能力,代码生成能力,以及通用指令遵循能力,这三个能力的数据集及评测指标的介绍如下:
• GSM8K RFT [1] 是一个增强的数学推理数据集,它基于GSM8K数据集[4]并结合RFT策略整合了多条推理路径。训练集中包含7.5K个问题和110K个回答,我们所有实验数学的评测指标为G ...

实用的Prompts列表
本博文将记录从互联网收集的Prompts,主要是用于学习目的,感谢相关大佬的贡献。
note
可以试试把你的要求告诉GPT 插件 Prompt Perfect,让它帮你生成个prompt, 或者直接让gpt 按照你的要求生成。
如何让GPT-4帮你写prompt,可以参考该篇博文
GitHub 上有两个项目收集了超级多被破解的 GPTs Prompt: GPTs 和 chatgpt_system_prompt
翻译Prompt
12345678910111213141516171819202122232425262728293031323334353637383940414243444546你是一位精通简体中文的专业翻译,尤其擅长将专业学术论文翻译成浅显易懂的科普文章。请你帮我将以下英文段落翻译成中文,风格与中文科普读物相似。规则:- 翻译时要准确传达原文的事实和背景。- 即使上意译也要保留原始段落格式,以及保留术语,例如 FLAC,JPEG 等。保留公司缩写,例如 Microsoft, Amazon, OpenAI 等。- 人名不翻译- 同时要保留引用的论文,例如 [20] ...

微调语言大模型选LoRA还是全参数?基于LLaMA 2深度分析
本文对比了全参数微调和LoRA,并分析了这两种技术各自的优势和劣势。作者使用了三个真实用例来训练LLaMA 2模型,这提供了比较特定任务的性能、硬件要求和训练成本的基准。本文证明了使用LoRA需要在serving效率和模型质量之间做出权衡,而这取决于具体的任务。
此外,本文还提供了关于如何通过智能提示技术来稳定LoRA训练的深入见解,并进一步验证了采用较低的学习率可以增强最终模型检查点的可靠性。实验是基于经LoRA调整的脚本版本进行的。
最近几个月,开源语言大模型(LLM)之间展开了与OpenAI专有模型的竞争。提升开源LLM性能的一种常用策略是全参数微调,这种方法对模型的所有参数进行了优化。在之前的博客文章中,我们分析了这种全参数微调与GPT-4的提示工程和少样本提示的比较效果。
正如你所料,全参数微调是一项资源密集型任务,需要强大的计算能力来管理优化器状态和检查点。一些上下文信息:通常情况下,优化器状态和梯度所占的内存空间约为模型本身的12倍。即便是拥有70亿参数的最小LLaMA-2模型,也需要大量计算资源来进行微调。因此,该领域出现了所谓的"参数高效微调(也被称为pef ...

Fuyu-8B:A Multimodal Architecture for AI Agents
Transformer一作Ashish Vaswani所在的AI公司Adept,发布了Fuyu-8B,这是一个多模态模型的小版本,为其产品赋能。Fuyu-8B的特点包括:
(1)具有比其他多模态模型更简单的架构和训练程序;
(2)从头开始为数字助手设计,支持任意图像分辨率,能够回答关于图表和图形的问题,并在屏幕图像上进行精细的定位;
(3)响应速度快,对于大图像的响应时间不到100毫秒;
(4) 尽管针对特定用例进行了优化,但在标准的图像理解基准测试中表现良好。
方法
模型架构: Adept致力于为知识工作者构建一个普遍智能的助手。为了实现这一目标,模型需要能够理解用户的上下文并代表用户采取行动。Fuyu的架构是一个普通的Decoder-only变压器,没有图像编码器。图像块直接线性投影到变压器的第一层。
从Huggingface中可以看到如下:
1234567....... self.vision_embed_tokens = nn.Linear( config.patch_size * config.patch_size * config.num_ch ...

ar5iv
用latexml转换arXiv.org论文(Latex源码)显示为HTML5,然后在借助沉浸式翻译,效率提高很多。强烈推荐!
Github地址: github.com/dginev/ar5iv
Converted from TeX with LaTeXML.
Sources upto the end of November 2023. Not a live preview service.
For articles with multiple revisions, only a single version is made available.
When in doubt, always use the main arXiv.org article page.
Goal: incremental improvement until worthy of native arXiv adoption.
Sample: A Simple Proof of the Quadratic Formula (1910.06709)
View any arXiv article UR ...

如何让 GPT-4 帮你写 Prompt?
很多人苦于不知道如何写高质量的 Prompt,尤其是如果要用英文表达更是吃力,不容易表达准确。
可以试试让 ChatGPT 帮你写,尤其是 GPT-4,生成的质量还是不错的。
如果你只是简单要求它写一个英文 Prompt,它很可能只是把你的要求翻译一遍,这样效果可能不够理想。要让 Prompt 质量高,可以让 Prompt 遵循一个好的结构,并应用一些好的策略,例如思考链、慢思考等等。
以前 OpenAI 分享过:《GPT best practices》,里面就介绍了很多优秀实践,我也分享过一些参考的结构。
基于这些可以写一个 Prompt 来让它写 Prompt😄
首先给它设定一个角色:“Prompt Engineer,擅长写 GPT-4 能理解并输出高质量结果的”,让它明白它擅长写 Prompt,生成时生成高质量 Prompt 内容的概率能高一点点。
然后告诉它要求,例如要考虑 Cot、慢思考,提供样例。
再告诉它输出的格式应该遵循一个结构。
这样它就能生成还不错的 Prompt 内容。
但是要注意的是,这种方法类似于让 ChatGPT 写代码,如果你自己不能提供清晰的步骤,Ch ...

Efficient Memory Management for Large Language Model Serving with PagedAttention
GPT 和 PaLM 等大型语言模型(LLM)的出现催生出了开始对我们的工作和日常生活产生重大影响的新应用,比如编程助理和通用型聊天机器人。
许多云计算公司正竞相以托管服务的方式提供这些应用。但是,运行这些应用的成本非常高,需要大量硬件加速器,如 GPU。根据最近的估计,相比于传统的关键词查询方法,处理一个 LLM 请求的成本超过其 10 倍以上。考虑到成本如此之高,提高 LLM 服务系统的吞吐量(并由此降低单位请求的成本)就变得更为重要了。
论文地址: https://arxiv.org/abs/2309.06180
代码地址: https://github.com/vllm-project/vllm
文档地址: https://vllm.readthedocs.io/en/latest/
LLM 的核心是自回归 Transformer 模型。该模型可基于输入(prompt)和其之前输出的 token 序列生成词(token),一次生成一个。对于每次请求,这个成本高昂的过程都会重复,直到模型输出终止 token。这种按序列的生成过程会让工作负载受到内存限制,从而无法充分利用 G ...

Continuous Batching:一种提升 LLM 部署吞吐量的利器
由于 LLM 巨大的 GPU 内存开销和计算成本,在大多数应用中,机器学习工程师通常通过内部调整(如量化和对 CUDA 核的定制)来优化。然而,由于 LLM 通过迭代生成其输出,并且 LLM 推理通常涉及内存而不是计算,因此在很多实践中,优化系统级批处理可以使性能差异达到10倍甚至更多。
一种最近提出的优化方法是连续批处理(Continuous batching),也称为动态批处理或基于迭代级的批处理。其具有如下惊人的效果:
基于vLLM,使用连续批处理和连续批处理特定的内存优化,可以实现多达23倍的吞吐量提升;
对于 HuggingFace 本地生成推理,使用连续批处理,可以实现8倍的吞吐量提升;
基于 NVIDIA 的 FasterTransformer,使用优化过的模型实现,可以实现4倍的吞吐量提升。
本博客接下来将详细介绍相关技术的细节。
LLM推理
LLM 推理是一个迭代过程,在每个新前馈循环后获得一个额外的完成标记。例如,如果您提示一个句子"What is the capital of California:",它需要进行十次前馈循环才能得到完整的回 ...