Dropout在RNN中的应用综述
这篇文章中,提供了Dropout的背景和概述,以及应用于使用LSTM / GRU递归神经网络的语言建模的参数分析。
Dropout
受性别在进化中的作用的启发,Hinton等人最先提出Dropout,即暂时从网络中移除神经网络中的单元。 Srivastava等人将Dropout应用于前馈神经网络和受限玻尔兹曼机,并注意到隐层0.5,输入层0.2的 dropout 率 适用于各种任务。
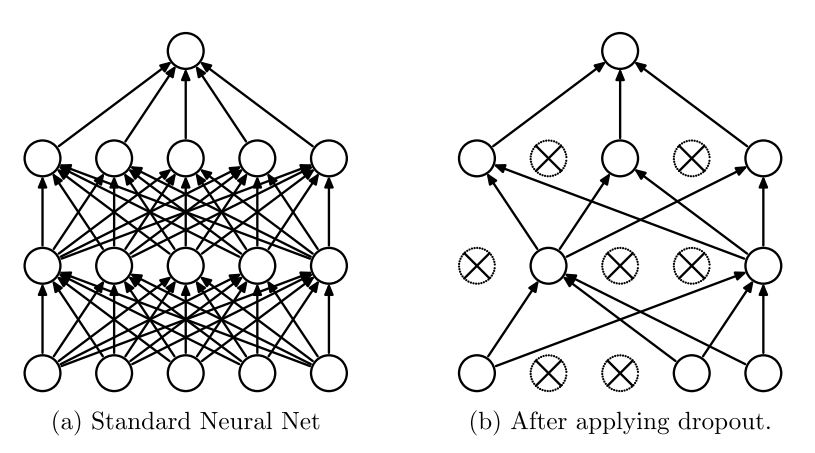
图1. a)标准神经网络,没有dropout。 b)应用了dropout的神经网络。
Srivastava等人的工作的核心概念是“在加入了dropout的神经网络在训练时,每个隐藏单元必须学会随机选择其他单元样本。这理应使每个隐藏的单元更加健壮,并驱使它自己学到有用的特征,而不依赖于其他隐藏的单元来纠正它的错误“。在标准神经网络中,每个参数通过梯度下降逐渐优化达到全局最小值。因此,隐藏单元可能会为了修正其他单元的错误而更新参数。这可能导致“共适应”,反过来会导致过拟合。而假设通过使其他隐藏单元的存在不可靠,dropout阻止了每个隐藏单元的共适应。
对于每个训练样本,重新调整网络并丢弃一组新的神经元 ...
知识抽取-实体及关系抽取
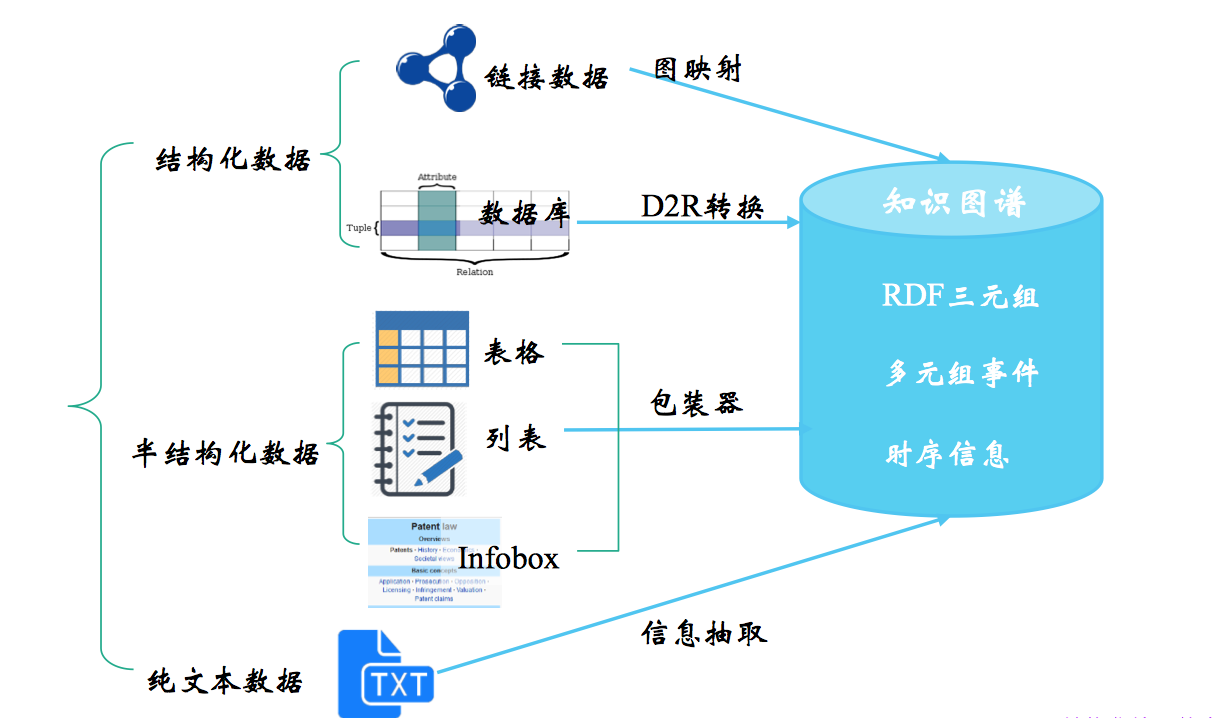
知识抽取涉及的“知识”通常是 清楚的、事实性的信息,这些信息来自不同的来源和结构,而对不同数据源进行的知识抽取的方法各有不同,从结构化数据中获取知识用 D2R,其难点在于复杂表数据的处理,包括嵌套表、多列、外键关联等,从链接数据中获取知识用图映射,难点在于数据对齐,从半结构化数据中获取知识用包装器,难点在于 wrapper 的自动生成、更新和维护,这一篇主要讲从文本中获取知识,也就是我们广义上说的信息抽取。
信息抽取三个最重要/最受关注的子任务:
实体抽取
也就是命名实体识别,包括实体的检测(find)和分类(classify)
关系抽取
通常我们说的三元组(triple) 抽取,一个谓词(predicate)带 2 个形参(argument),如 Founding-location(IBM,New York)
事件抽取
相当于一种多元关系的抽取
篇幅限制,这一篇主要整理实体抽取和关系抽取,下一篇再上事件抽取。
相关竞赛与数据集
信息抽取相关的会议/数据集有 MUC、ACE、KBP、SemEval 等。其中,ACE(Automated Content Extract ...

Kaggle竞赛-Home Credit Risk小结
Kaggle竞赛-Home Credit Default Risk小结
竞赛网址:kaggle home credit default risk
Home Credit
Home Credit(中文: 捷信消费金融有限公司)是中东欧/亚洲的一家消费金融提供商, 为客户提供金融服务.
比赛简介
业务背景
Home Credit希望能通过数据挖掘和机器学习算法来估计客户的贷款违约概率.
数据
(1) application_train/test 客户申请表
包含了目标变量(客户是否违约-0/1变量), 客户申请贷款信息(贷款类型, 贷款总额, 年金), 客户基本信息(性别, 年龄, 家庭, 学历, 职业, 行业, 居住地情况), 客户财务信息(年收入, 房/车情况), 申请时提供的资料等.
(2) bureau/bureau_balance 由其他金融机构提供给征信中心的客户信用记录历史(月数据)
包含了客户在征信中心的信用记录, 违约金额, 违约时间等. 以时间序列(按行)的形式进行记录.
(3) POS_CASH_balance 客户在Home Credit数据库中POS( ...

电商知识图谱
本文从需求分析和体系化构建的角度出发,阐述在电商这一特殊领域的知识图谱构建过程中,形成的一整套概念体系,还有在此过程中,通过算法、工程、产品、运营和外包团队投入大量精力,通过不断磨合逐渐完善的平台架构和审核流程。
1.背景
电商认知图谱从17年6月启动以来,通过不断从实践到体系化的摸索,逐渐形成了一套较为完善的电商数据认知体系。
在当前集团不断拓展业务边界的背景下,数据互联的需求越来越强烈,因为这是跨领域的搜索发现、导购和交互的基础,也是真正能让用户“逛起来”要具备的基础条件。但在此之前,我们需要对当前的问题做一个分析。
1.1 问题
更复杂的数据应用场景不仅是传统的电商,现在我们面临的是新零售、多语言、线上线下结合的复杂购物场景,所用到的数据也往往超出了以往的文本范围,这些数据往往都具有一些特点:
非结构化互联网的大量数据都是分散在各个来源而且基本是非结构化文本方式来表示,目前的类目体系从商品管理角度出发,做了长期而大量的工作,仍然只是覆盖了大量数据的冰山一角,这对于认知真正的用户需求当然是远远不够的。
充满噪声:不同于传统的文本分析,目前集团内的数据大部分是query、title ...
健康知识图谱
“The world is not made of strings , but is made of things.” 大千世界,万物相联。保险领域的知识图谱之路,该如何构建?本文将为你介绍健康知识图谱构建流程、整体框架和遇到的问题,并总结健康知识图谱在保险理赔领域应用场景和对应设计。
随着互联网和AI智能的发展,近年来我国的健康险业务迎来了飞速发展和变革。健康险,即健康保险,是保险业务的一个重要分支,有着广阔的发展前景,是本财年保险领域排兵布阵的重要战场。健康险是以被保险人的身体为保险标的,依据合同约定当被保险人遭遇疾病或意外伤害时,对被保险人的医疗费用或财产损失进行补偿或给付的一种保险。
为了支撑日益剧增的理赔单量的挑战,在不增加客服小二工作量的前提下,健康险理赔需要做到智能化、自动化和低风险化。因此,理赔天平团队在智能理赔、理赔机器智能问答和反骗赔等方面做出了相应尝试,而是以上各种尝试所依赖的底层基础技术。
健康知识图谱和Schema示例
健康知识图谱样例如图1所示,其中存储着用户、险种、疾病、医院等各类节点信息以及它们之间的关联信息。比如,用户张三投保了门诊保险金,当 ...
BiLSTM-CRF模型中CRF层的运行原理(4)
前面我们重点介绍了CRF的原理,损失函数以及分数的计算。本节将结合前面的相关内容,介绍基于PyTorch(1.0)框架实现BILSTM-CRF模型及一些需要注意的细节。
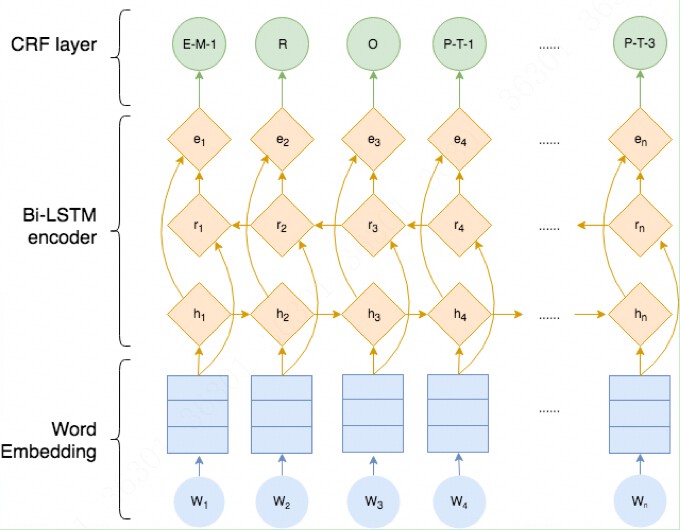
模型总览
整个模型结构如下所示,我们也将按照该结构进行实现代码。
由上图可知,整个BILSTM-CRF模型由BILSTM、CRF、损失函数和预测函数几部分组成。BILSTM的输出作为CRF的输入,损失函数定义在CRF中, 损失函数使用前向算法,预测函数使用Viterbi算法,下面逐一介绍。
1234567891011121314151617181920212223242526272829303132333435class BILSTM_CRF(nn.Module): def __init__(self, vocab_size, word_embedding_dim, word2id, hidden_size, bi_flag, num_layer, i ...

kaggle: Plant Seedlings Classification
kaggle上的比赛,从作物幼苗中区分出杂草,有效的解决方案意味着更好的作物产量及更好的环境管理。
奥胡斯大学信号处理组与丹麦南方大学合作,发布了一个数据集,其中包含不同生长阶段的 12 个种类大约 960 种植物的图像 ,
数据集下载地址:https://www.kaggle.com/c/plant-seedlings-classification
上述图像数据已公开发布。它包含带注释的 RGB 图像,分辨率约为每毫米 10 个像素。
采用基于 F1 分数的指标对分类结果进行评估。以下图像是描述数据集中所有 12 个类的示例:
我们主要按照一下5步骤完成图片分类任务:
step 1
机器学习的首要任务是分析数据集,然后进行算法实验。了解数据集的复杂性,这一步很重要,这最终将有助于算法的设计。
该数据的标签分布如下:
如上所述,该数据集包含 12 个类共 4750 个图像。但是,从上图可以看出,各类分布不平均,最大 个数为654 张,而最小个数为 221 张。下图清楚地表明数据是不平均的,因此,为了获得更好的结果,我们需要对原始数据进行类平衡处理。step 3 中我们将完成此任 ...
Kaggle的十大深度学习技巧
在各种Kaggle竞赛的排行榜上,都有不少刚刚进入深度学习领域的程序员,其中大部分有一个共同点:
都上过Fast.ai的课程。
这些免费、重实战的课程非常鼓励学生去参加Kaggle竞赛,检验自己的能力。当然,也向学生们传授了不少称霸Kaggle的深度学习技巧。
是什么秘诀让新手们在短期内快速掌握并能构建最先进的DL算法?一位名叫塞缪尔(Samuel Lynn-Evans)的法国学员总结了十条经验。
他这篇文章发表在FloydHub官方博客上,因为除了来自Fast.ai的技巧之外,他还用了FloydHub的免设置深度学习GPU云平台。
接下来,我们看看他从fast.ai学来的十大技艺:
1. 使用Fast.ai库
这一条最为简单直接。
1from fast.ai import *
Fast.ai库是一个新手友好型的深度学习工具箱,而且是目前复现最新算法的首要之选。
每当Fast.ai团队及AI研究者发现一篇有趣论文时,会在各种数据集上进行测试,并确定合适的调优方法。他们会把效果较好的模型实现加入到这个函数库中,用户可以快速载入这些模型。
于是,Fast.ai库成了一个功能强大的工具箱 ...
BiLSTM模型中CRF层的运行原理(3)
在前面的部分中,我们学习了BiLSTM-CRF模型的结构和CRF损失函数的细节。您可以通过各种开源框架(Keras,Chainer,TensorFlow等)实现您自己的BiLSTM-CRF模型。最重要的事情之一是在这些框架上自动计算模型的反向传播,因此您不需要自己实现反向传播来训练模型(即计算梯度和更新参数)。此外,一些框架已经实现了CRF层,因此只需添加一行代码就可以非常轻松地将CRF层与您自己的模型相结合。
在本节中,我们将探讨如何预测句子的标签序列。
1. 预测句子的标签序列
第1步:BiLSTM-CRF模型的emission score和transition score
假设句子xxx包含3个字符:x=[w0,w1,w2]x=[w_0, w_1, w_2]x=[w0,w1,w2]。此外,假设我们已经获得了BiLSTM模型的emission score和CRF层的transition score:
l1l_1l1
l2l_2l2
w0w_0w0
w01w_{01}w01
w02w_{02}w02
w1w_1w1
w11w_{11}w11
...
BiLSTM模型中CRF层的运行原理(2)
在上一节中,我们知道CRF层可以从训练数据集中自动学习到一些约束规则来保证预测标签的合法性。这些约束包括:
句子中第一个词总是以标签“B-“ 或 “O”开始,而不是“I-”
标签“B-label1I-label2 I-label3 I-…”,label1, label2, label3应该属于同一类实体。例如,“B-PersonI-Person” 是合理的序列, 但是“B-Person I-Organization” 是不合理标签序列.
标签序列“O I-label”是不合理的,实体标签的首个标签应该是 “B-“ ,而非 “I-“, 换句话说,有效的标签序列应该是“O B-label”。
这一节,我们将解释为什么CRF层会自动学习到这些约束规则。
1.CRF层
在CRF层损失函数中,有两种形式的score。这些scores是CRF层的关键概念。
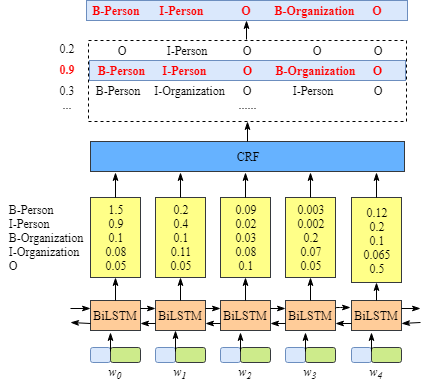
1.1 emission score
第一个是emission score,主要来自BiLSTM层的输出,如下图所示,比如,单元w0w_0w0标记为‘B-Person’的score为1.5:
为了方便起见,我们用数字来表示各个实体标签 ...

